






 本文探讨了在ECS(Entity Component System)中存储状态机的挑战,包括性能开销、内存管理和代码可读性问题。通过分析基于标签的方法,指出其在原型和稀疏集存储中的不足,并提出了一种利用状态间互斥性的解决方案,通过使用链接列表和组件结合来改善状态机的实现。此外,文章还提到了ECS存储的最新进展,如使用位集和多存储方式来优化状态切换和内存利用率。
本文探讨了在ECS(Entity Component System)中存储状态机的挑战,包括性能开销、内存管理和代码可读性问题。通过分析基于标签的方法,指出其在原型和稀疏集存储中的不足,并提出了一种利用状态间互斥性的解决方案,通过使用链接列表和组件结合来改善状态机的实现。此外,文章还提到了ECS存储的最新进展,如使用位集和多存储方式来优化状态切换和内存利用率。
翻译自:Why Storing State Machines in ECS is a bad idea.
翻译工具: DeepL
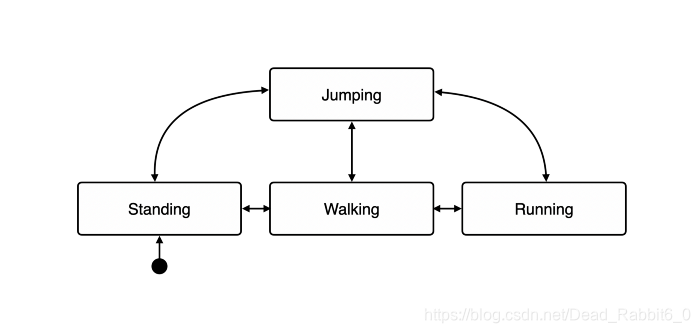
如果你正在使用ECS来开发游戏,那么你有可能在某些时候不得不问自己是否要将状态机存储在ECS中。我已经这样做了,结果发现这比预期的要难得多,原因不止一个。
在这篇文章中,我将介绍我遇到的挑战,为什么在ECS中存储状态机还是很好的,以及我想出了哪些解决方案来解决这些问题。
首先我们来看看在使用状态机时常见的一些功能和操作
- 将一个实体的状态替换为另一个状态
- 让实体参与多个状态机
- 获取一个状态的当前实体
- 获取实体/状态机的当前状态
- 获取状态机的当前实体
- 更改属于状态机的状态列表
- 获取状态机中所有状态的列表
一个状态机的实现不仅要能够为这些提供高效的实现,还应该让代码具有可读性,同时尽量减少状态机变化时的重构量
在进入细节之前,我想特别强调一下可读、可维护的代码的重要性。只关注某一特定解决方案的性能是很有诱惑力的。正如本篇文章将展示的那样,状态机引入了许多设计挑战,如果不加以解决,就会成为技术债务的来源。
有一种直观的方式可以在ECS中实现状态机。让我们来看看它,看看它在上述列表中的得分情况。
A tag per state
ECS中的标签是一个没有数据的组件,我们可以为每个状态创建一个单一的标签。在查询给定状态的所有实体时,这种方法的表现一般都很好,因为找到给定组件/标签的所有实体是ECS实现通常所擅长的。
那其他的操作呢?首先,要改变状态,我们必须增加一个标签,并删除另一个标签。在伪代码中,这就是将实体的状态从 "行走 "改为 "奔跑 "的样子。
e.add<Running>()
e.remove<Walking>()
尽管这段代码乍一看很简单,但这里有几个真正的问题。第一个问题是,为了移除Walking,应用程序首先必须知道实体实际上处于Walking状态,这只是特定状态机潜在的许多状态之一。那么如何解决这个问题呢?在不增加更多复杂性的情况下,其实并没有一个好的方法。一种方法是将当前状态存储在另一个组件中。
Movement& m = e.get<Movement>();
if (m == MovementStateWalking) {
e.remove<Walking>();
} else if ( /* test other states ... */) {
}
m = MovementStateRunning;
e.add<Running>()
另一种方法是写一个测试状态的实用函数,用它来代替状态机组件:
MovementState get_movement(entity e) {
if (e.has<Walking>()) return MovementStateWalking;
if (e.has<Running>()) return MovementStateRunning;
/* test other states ... */
}
这两种方法都不是特别吸引人,而且给使用状态机的代码部分增加了可维护性和性能问题。每次状态机发生变化时,相应的实用程序也必须更新。
当一个应用程序需要获取特定状态机的当前状态时,也会出现同样的问题。这将再次依赖于一个组件来存储当前状态,或者依赖于一个状态机的特定函数。
如果不创建额外的实用程序,也无法获得特定状态机的实体列表。例如,一个应用程序可以为状态机中的所有状态创建一个查询,每当状态机发生变化时,这个查询就必须更新。
query<Sitting, Standing, Walking, Running, ...>();
根据使用何种ECS,这样的查询可能会随着更多的状态被添加到查询中而最终变慢。另一种方法将再次依赖于每个状态机的组件。
我们也来看看存储方面的影响。有许多不同的方法来实现ECS,其中两种流行的方法是 原型(archetypes) 和 稀疏集(sparse sets)。基于标签的方法会给这两种存储实现带来很大的压力。我们来看看为什么。
Archetypes
一个原型实现将具有相同组件集的实体一起存储在一个表中。在不深入了解细节的情况下,这提供了高缓存效率的组件迭代,因为多个组件总是可以作为连续的数组进行迭代。然而,这也是有代价的。
为了使具有相同组件集的实体保持在一起,当添加或删除组件时,实体需要在表之间移动。这也适用于标记。因此,频繁地添加/删除与状态相关联的标签会变得非常昂贵,因为一个实体的所有组件需要为每个状态转换复制(事实上,由于存储的特殊性,这需要为每个组件复制两份)。
另一个挑战是,当一个实体参与多个正交状态机时,每一个状态的组合都会引起组合表的爆炸,这就增加了碎片化,根据ECS的实现,也会拖慢代码的其他部分。
这对状态机来说,简直是个大难题。
那…
Sparse Sets 稀疏集
(译者注:C++ 的 EnTT 框架是基于 sparse sets 结构的 - “一个基于稀疏集的、速度极快的实体组件系统,自带策略 可根据用户需求调整性能和内存使用量”)
在基于稀疏集的ECS中,每个组件和标签都有自己的稀疏集,其中包含有该特定组件的实体。对单个稀疏集的添加和删除通常是快速的,所以稀疏集不会出现原型存储的问题。不过还有其他问题。
出现的第一个问题是,由于每个状态都存储在一个单独的稀疏集中,稀疏集的数量可能会增长得非常快,因为游戏可能会有数百个甚至数千个单独的状态。这就导致了一些问题,因为稀疏ECS中的一些操作(如实体删除或访问)需要迭代ECS世界中的所有稀疏集,以测试一个实体是否是稀疏集的成员。对于数百个稀疏集,这种操作可能会变得非常昂贵。
An additional problem is memory utilization. Sparse ECS implementations typically use a so-called “paged sparse set” that allocates memory in pages. While this typically acts as a memory-conserving strategy (without paging a sparse set would have to allocate an array the size of the largest entity id), in the case of state machines this still can cause significant overhead.
另外一个问题是内存利用率。稀疏ECS的实现通常使用所谓的 “分页稀疏集”,以页为单位分配内存。虽然这通常作为一种内存节约策略(如果没有分页,稀疏集将不得不分配一个最大实体id大小的数组),但在状态机的情况下,这仍然会造成巨大的开销。
To put some numbers on this, let’s consider a game with 10.000 entities that has a total of 100 states. Many of those entities will get recycled and used for different purposes, so we can assume that over time entity ids are more or less randomly distributed across state machines. Let’s also assume a page size of 4096 entities, which typically provides an optimal balance between not creating too many pages, and not allocating too much memory.
我们假设有10000个entities,总共有100个状态。其中许多实体会被回收并用于不同的目的,所以我们可以假设随着时间的推移,实体id或多或少地随机分布在状态机上。我们还假设页面大小为4096个实体,这通常在不创建太多页面和不分配太多内存之间提供了一个最佳平衡。
In this scenario we would have on average 100 entities stored per sparse set (only counting the states). Because the ids of the entities are randomly distributed, each sparse set will have at least allocated 3 pages, which adds up to space for 12288 entities in total, per sparse set. We have 100 sparse sets, so the total amount of memory for this setup is more than 100x larger than what we would strictly need for 10.000 entities! This is cringy, especially when considering that many of these states are mutually exclusive.
在这种情况下,我们平均每个稀疏集将存储100个实体(只计算状态)。因为实体的id是随机分布的,所以每个稀疏集至少会有3页的分配,这样每个稀疏集总共有12288个实体的空间。我们有100个稀疏集,所以这个设置的总内存量比我们严格意义上的10.000个实体所需要的内存量大了100多倍!这太小气了,尤其是当我们的实体的ID是随机分布的时候。这是很恶心的,特别是考虑到许多状态是相互排斥的。
With 4-byte entity identifiers that would amount to around 5MB memory utilization which at face value is not the end of the world, but the fact that data is stored in a very sparse way would destroy cache efficiency as randomly testing for states (which would happen a lot) would ensure that data won’t stay in L1/L2 caches for long.
如果使用4字节的实体标识符,这将相当于5MB左右的内存利用率,从表面上看,这并不是世界末日,但事实上,数据以非常稀疏的方式存储会破坏缓存效率,因为随机测试状态(会发生很多)将确保数据不会在L1/L2缓存中停留很长时间。
To conclude, even though initially the tag based approach seems intuitive, it requires the application to write utility code for each state machine, and all operations except getting the entities for a current state incur overhead that in most cases scales linearly with the number of states. Both archetype storages and sparse set storages struggle with this approach (though to be fair archetypes are a non-starter, whereas sparse sets are merely inefficient).
总之,尽管最初基于标签的方法看起来很直观,但它要求应用程序为每个状态机编写实用代码,除了获取当前状态的实体外,所有的操作都会产生开销,在大多数情况下,这些开销与状态的数量呈线性扩展。原型存储和稀疏集存储都在这种方法中挣扎(不过公平地说,原型是不可能的,而稀疏集只是效率低下)。
This is not great.
It is not all bad news though. Archetype and sparse storages are advancing at a rapid pace, and some of the storage issues I mention are being addressed as we speak. Those improvements however still do not address the more fundamental “designy” problems that we saw earlier. I believe that those design issues are at least as important as the storage/performance ones, and are much more likely to make the lives of the average game developer miserable.
不过这也不全是坏消息。Archetype和稀疏存储正在快速推进,我提到的一些存储问题在我们说话的时候就已经得到了解决。然而这些改进仍然没有解决我们之前看到的更基本的 "设计 "问题。我相信,这些设计问题至少和存储/性能问题一样重要,而且更有可能让普通游戏开发者的生活变得痛苦。
We could of course cop out and argue that the state machine logic should not be implemented in ECS at all. This is a valid argument on paper, but in practice having multiple systems for dealing with iterating and running logic over entities is all but guaranteed to introduce code smell.
当然,我们可以逃避,认为状态机逻辑根本不应该在ECS中实现。这在纸面上是一个有效的论点,但在实践中,有多个系统来处理实体上的迭代和运行逻辑,几乎可以保证会引入代码的味道。
So I decided to take a look at whether all of these problems are solvable, and it turns out they are.
于是我决定看看这些问题是否都能解决,结果发现是可以解决的。
Why Storing State Machines in ECS is not a bad idea.
The solution I’ll describe is the one I implemented in Flecs, which is an archetype-based ECS. The used approach is however not only applicable to an archetype solution, and could be implemented in any ECS.
我将描述的解决方案是我在Flecs中实现的,它是一个基于原型的ECS。然而,所使用的方法不仅适用于原型解决方案,也可以在任何ECS中实现。
State machines have a unique property that none of our previous solutions took advantage of: states are mutually exclusive. This property can heavily be exploited with the creative use of a few data structures.
状态机有一个独特的属性,我们之前的解决方案都没有利用到这个属性:状态是相互排斥的。通过创造性地使用一些数据结构,可以大量地利用这一特性。
For starters, we want to avoid having to move the entity between archetypes. This means that as a result we have to be able to store entities with any state in a single archetype. Let’s first consider the simplest approach, which is to create a single component per state machine that contains an integer with the state for an entity, as mentioned earlier.
首先,我们要避免在原型之间移动实体。这意味着作为结果,我们必须能够在单一原型中存储具有任何状态的实体。让我们首先考虑最简单的方法,即如前文所述,为每个状态机创建一个包含实体状态的整数的组件。
This would allow us to quickly change the state (just overwriting an integer value), which has the neat benefit that an entity cannot be in more than one state at the same time. It would also let us iterate all states for a state machine (just iterate its component) and get the current state for an entity efficiently. Not bad for a start.
这将允许我们快速改变状态(只是覆盖一个整数值),这有一个整洁的好处,一个实体不能同时处于多个状态。它还可以让我们迭代一个状态机的所有状态(只需迭代它的组件),并高效地得到一个实体的当前状态。不失为一个好的开始。
What this approach does not let us do is iterate all entities for a state efficiently. We would have to manually skip the entities that do not belong to the state we are looking for. This would likely lead to “god” systems that handle every state, or code that does inefficient dispatching. We need something better than that.
这种方法不能让我们做到的是高效地迭代一个状态的所有实体。我们将不得不手动跳过那些不属于我们正在寻找的状态的实体。这很可能会导致处理每个状态的 "神 "系统,或者是做低效调度的代码。我们需要比这更好的东西。
The solution here is to use a linked list per state that is stored adjacent to the state machine component array with the state identifiers. To iterate an entity for a specific state, one simply has to find the head for the corresponding linked list, and follow the nodes. While this is not as fast as regular component iteration, it is still a very rapid way to query, and also does not significantly increase the overhead of changing a state (a linked list remove+insert).
这里的解决方案是使用每个状态的链接列表,该列表与状态机组件数组相邻存储,并带有状态标识符。要迭代一个特定状态的实体,只需要找到对应链接列表的头部,然后按照节点进行迭代。虽然这样做的速度不如常规的组件迭代,但仍然是一种非常快速的查询方式,而且也不会明显增加改变状态的开销(链接列表删除+插入)。
The linked list itself can be stored efficiently as another adjacent array of integers, where the integer points to the next node in the array. Because states are mutually exclusive, the lists for different states can be nicely “braided” together in a single array which can be stored alongside the regular component array.
链接列表本身可以有效地存储为另一个相邻的整数数组,其中整数指向数组中的下一个节点。因为状态是互斥的,所以不同状态的列表可以很好地 "编织 "在一个数组中,这个数组可以和常规的组件数组一起存储。
The only thing left is to define a way to tell the ECS storage which tags belong to which state machine. For that I added a few small extensions to the API that allow an application to add a “switch” to an entity, which contains the list of state identifiers, and a “case” which is the state itself. Adding a switch adds the state machine component. Adding a case replaces the state for an entity.
剩下的唯一事情就是定义一种方法来告诉ECS存储哪些标签属于哪个状态机。为此,我给API添加了一些小的扩展,允许应用程序给实体添加一个 “switch”,其中包含状态标识符列表,以及一个 “case”,即状态本身。添加一个switch会添加状态机组件。添加一个case会替换一个实体的状态。
In code it looks like this:
// Declare cases
auto Standing = flecs::entity(world, "Standing");
auto Walking = flecs::entity(world, "Walking");
auto Running = flecs::entity(world, "Running");
// Declare switch
auto Movement = flecs::type(world, "Movement",
"Standing, Walking, Running");
// Create entity with Walking
auto e = flecs::entity(world)
.add_switch(Movement)
.add_case(Walking);
// Add case Running, replace Walking
e.add_case(Running);
This has the additional benefit that the ECS store is now aware of the states that belong to a state machine, which comes in handy for the development of tools.
News & noteworthy
Both archetype & sparse set ECS implementations have come up with ways to get around some of the previously described edge cases where performance starts to degrade.
原型和稀疏集ECS的实现都有办法绕过之前描述的一些性能开始下降的边缘情况。
Some archetype implementations are implementing a storage variant that separates an archetype from a table. In this approach a table only stores the (data) components of an entity, whereas the archetype stores the components + tags. Multiple archetypes can point to the same table. With this in place, an application can add & remove tags (and thus states) in constant time, which is a massive improvement over having to copy all components. The idea was first proposed by the author of Bevy, and currently both Bevy ECS and Flecs are working towards this solution.
一些原型实现正在实现一种存储变体,将原型与表分开。在这种方法中,表只存储一个实体的(数据)组件,而原型则存储组件+标签。多个原型可以指向同一个表。有了这一点,一个应用程序就可以不断地添加和删除标签(从而添加和删除状态),这比必须复制所有的组件是一个巨大的改进。这个想法最早是由Bevy的作者提出来的,目前Bevy ECS和Flecs都在朝着这个方案努力。
An additional improvement that has been finding its way into archetype implementations (Unity DOTS & Flecs) is the usage of bitset arrays to indicate whether a component is “enabled” or not. This provides the ability to quickly turn on or off components by flipping a bit, without actually having to move the entity between tables. The tradeoff is that iteration is a bit slower as queries have to find contiguous sets of enabled bits, but this can be implemented efficiently. The approach could be applied to state machines, where each state gets its own bitset array.
另一个一直在原型实现(Unity DOTS和Flecs)中发现的改进是使用位集数组来指示一个组件是否 “启用”。这提供了通过翻转位来快速打开或关闭组件的能力,而无需实际在表之间移动实体。这样做的代价是,由于查询必须找到连续的启用位集,所以迭代速度会慢一些,但这可以有效地实现。这种方法可以应用于状态机,每个状态都会得到自己的位集数组。
Sparse set implementations have also been improving towards approaches that do not rely on iterating all sparse sets for delete/visit operations. One such approach is to “borrow” the idea of an archetype where the archetype itself only stores the list of component identifiers. When archetypes are organized in a graph, changing archetypes and finding the total set of components can be done in a single cheap O(1) operation. Alternative solutions are also being worked on, as the author of EnTT is also working on an approach that achieves similar benefits.
稀疏集的实现也一直在朝着不依赖迭代所有稀疏集进行删除/访问操作的方法改进。其中一种方法是 "借用 "原型的思想,原型本身只存储组件标识符的列表。当原型组织在一个图中时,改变原型和查找组件的总集可以在一个廉价的O(1)操作中完成。其他的解决方案也在研究中,EnTT的作者也在研究一种能实现类似好处的方法。
An optimization that a sparse set ECS could make to reduce memory overhead (at the cost of increasing allocations) is freeing up pages when they become empty. I would probably not do this unless I’m strapped for memory, but is likely to provide a significant decrease in memory utilization.
稀疏集ECS为减少内存开销(以增加分配为代价)可以做的一个优化是当页面变空时释放页面。我可能不会这样做,除非我的内存很紧张,但很可能会提供内存利用率的显著下降。
Last but not least, there are a number of ECS frameworks that have adopted a multi-storage approach where an application can choose to store components either in a sparse set or in a table (or table-like way). For archetype solutions storing states in sparse sets can reduce the performance overhead of switching states, but still suffers from some of the other problems outlined above.
最后但并非最不重要的是,有一些ECS框架采用了多存储方式,应用程序可以选择将组件存储在稀疏集或表格(或类似表格的方式)中。对于原型解决方案来说,将状态存储在稀疏集中可以减少切换状态的性能开销,但仍然存在上述其他一些问题。
And that’s it! I hope this gave you some ideas on the issues with “naive” state machine implementations, and, if you’re building your own ECS, how you can address them. For anyone who’s interested in implementing one, the implementation of the braided linked list can be found here: https://github.com/SanderMertens/flecs/blob/master/src/switch_list.c
就这样吧! 我希望这能让你对 "天真的 "状态机实现的问题有一些想法,如果你正在构建自己的ECS,你可以如何解决这些问题。对于任何有兴趣实现的人来说,辫子链接列表的实现可以在这里找到:https://github.com/SanderMertens/flecs/blob/master/src/switch_list.c。
If you’d like to know more about the specifics of the implementation, feel free to join the discussion on Discord!
如果你想了解更多关于实施的具体细节,欢迎加入Discord的讨论!

















 1367
1367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









