







前言
上一章我们已经学习掌握了计算机视觉中的人脸检测【课程总结】Day14:MTCNN过程的深入理解,接下来的我们将学习了解计算机视觉中:语义分割和图像分割。
语义分割
定义
语义分割,是将图像中的每个像素都分类为特定的语义类别,如"人"、“车”、"建筑"等。

访问https://segment-anything.com/demo#也可在线体验语义分割。
特点
语义分割是进行 class 级别分割
实现策略
- 输入:
- 一张图像
- 过程:
- 把每个像素都做一个
N+1分类即可
- 把每个像素都做一个
- 输出:
- mask 图像
算法原理
编解码器encoder-decoder模型
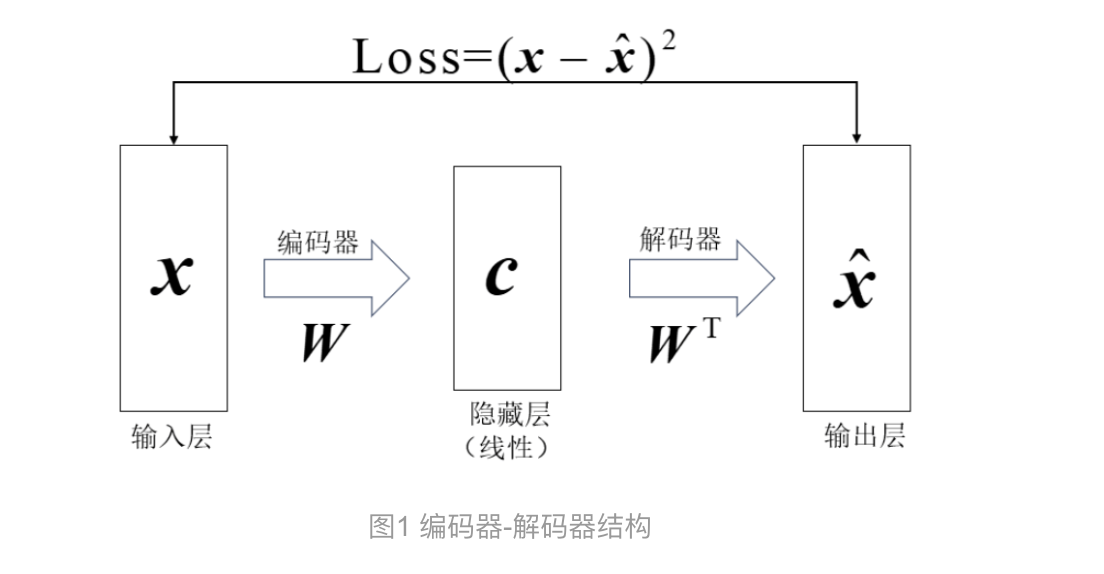
- 编码器Encoder:
- 把一个实体 entitiy 编码为一个抽象的中间表达(向量vector)
- 把原始数据进一步做数字化处理,变成一个语义化的表达
- 解码器Decoder:
- 根据编码器得到的中间表达,解码出相应的结果
- 中间表达Context vector:
- 连接Encoder和Decoder模型
类比人脑的思考过程:
Encoder类似于人脑的归纳总结的过程,而Decoder类似于人脑的演绎推理过程。
U-net模型
背景
U-Net 是一种语义分割神经网络模型,它最初由德国的 Olaf Ronneberger 等人在 2015 年提出,原本是为了解决生物医学图像分割问题而产生的。因为它的效果很好,所以后来被广泛应用于语义分割的各个方向:比如卫星图像分割等等。
由于模型使用了编码-解码"的网络结构,所以我们接下来对该模型进行学习了解。
论文地址:https://arxiv.org/abs/1505.04597
U-Net结构解析
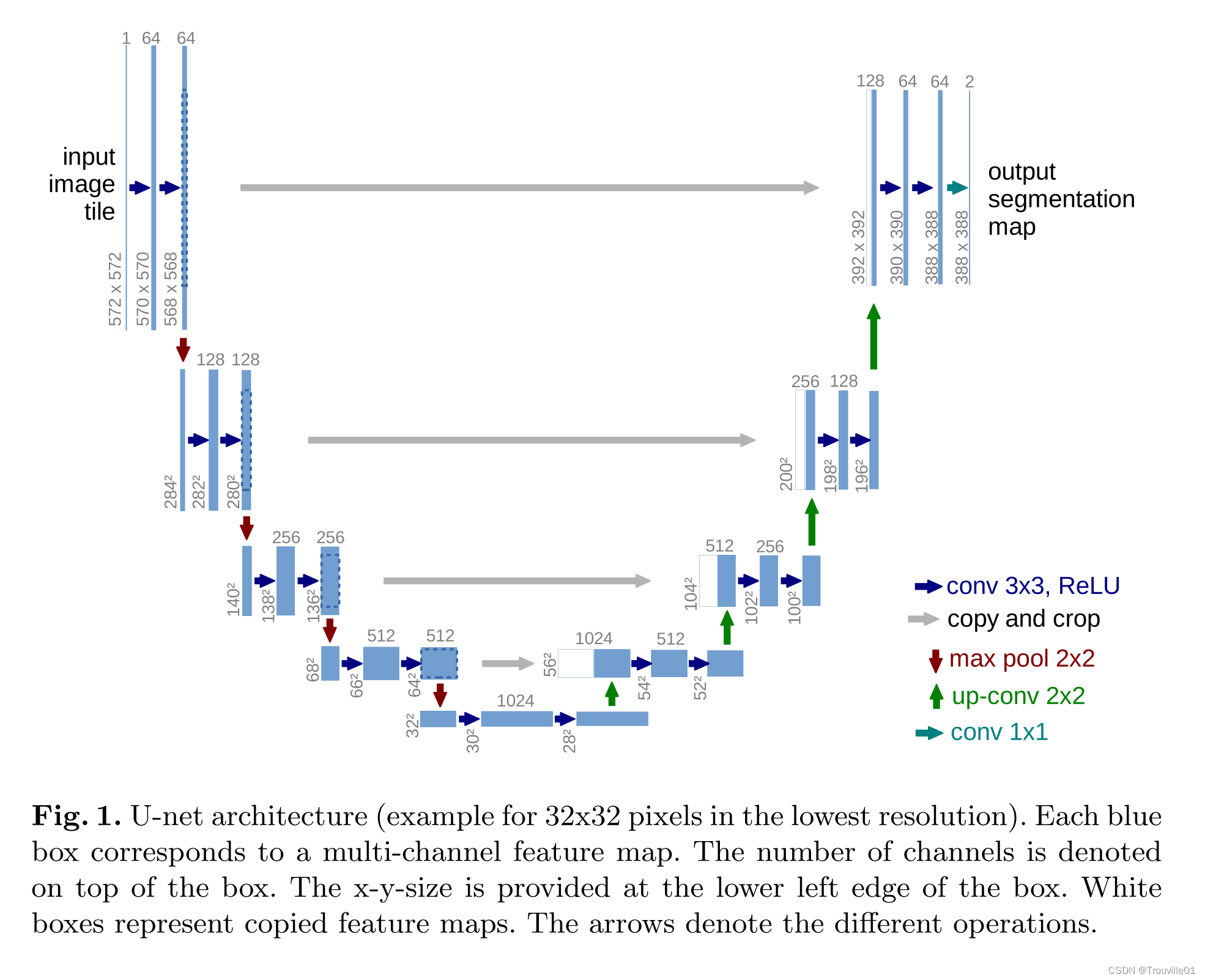
图示说明:
- 蓝/白色框表示 feature map
- 572 * 572是尺寸大小
- 64是通道数
- 蓝色箭头(conv 3×3)表示 3x3 卷积,用于特征提取;
- 灰色箭头(copy and crop:)表示 skip-connection(跳跃连接),用于特征融合;
- 红色箭头(max pool 2×2)表示最大池化,用于降低维度;
- 绿色箭头(up-conv 2×2)表示上采样,用于恢复维度;
- 天蓝色箭头(conv 1×1)表示 1x1 卷积,用于输出结果。
模型解析:
- 该模型主要由两个部分组成
- 左边是编码器(文章里称作收缩路径,contracting path)
- 右边是解码器(文章里称作膨胀路径,expansive path)
- 功能:输入一个
图片,得到这个图片的语义分割结果。
收缩路径Encoder
收缩路径主要是由卷积操作和池化(下采样)操作组成。
-
卷积层:
卷积结构统一为 3x3 的卷积核,padding 为 0 ,striding 为 1,所以由公式 n o u t = n i n + 2 × p − k s + 1 n_{out} = \frac{n_{in} + 2 \times p - k}{s} + 1 nout=snin+2×p−k+1,得到 n o u t = n i n − 2 n_{out} = n_{in} - 2 nout=nin−2,所以1~5层卷积是由3个33卷积组成,每通过一个33卷积尺寸都减少2。 -
池化层:
池化层的核大小为k=2,padding=0,striding=2,所以通过池化层后尺寸减少一半。
扩展路径Decoder
扩展路径经过Decoder恢复原始尺寸,该过程由卷积、上采样和跳级结构组成。
上采样的方法主要是:插值法和反卷积
插值法:
假设我们有一个 2×2 的输入图像,我们希望将其上采样为 4×4。
# 输入图像:
[[1, 2],
[3, 4]]
# 方法:每个像素复制到其相邻的四个位置
# 输出图像(最近邻插值):
[[1, 1, 2, 2],
[1, 1, 2, 2],
[3, 3, 4, 4],
[3, 3, 4, 4]]
反卷积:
假设我们有一个 2×2 的输入图像,我们希望将其上采样为 4×4。
# 输入图像:
[[1, 2],
[3, 4]]
# 反卷积核:
[[1, 1],
[1, 1]]
# 方法:
# 1.将卷积核放在输入特征图的每个像素上。
# 2.将卷积核的每个值与对应的输入像素相乘并累加到输出图像的相应位置。
# 处理输入图像(0,0)=1时:
[[1, 1, 0, 0],
[1, 1, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]]
# 处理输入图像(0,1)=2时:
[[1, 3, 2, 0],
[1, 3, 2, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]]
# 处理输入图像(1,0)=3时:
[[1, 3, 2, 0],
[4, 6, 2, 0],
[3, 3, 0, 0],
[0, 0, 0, 0]]
# 输出特征图(反卷积):
[[1, 3, 2, 0],
[4, 10, 6, 0],
[3, 7, 4, 0],
[0, 0, 0, 0]]
代码实践
数据集下载
下载链接:https://pan.baidu.com/s/1ZY2Q-9CBfe2ZpT90RgmPXw?pwd=pkwe
数据打包
import numpy as np
import torch
from torch import optim
from torchvision.transforms import transforms
from torch import nn
import torch.utils.data as data
from torch.utils.data import DataLoader
import PIL.Image as Image
import os
from matplotlib import pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 读取数据的路径
def make_dataset(root):
imgs = []
# 计算共有多少张原始图片
n = len(os.listdir(root))//2
for i in range(n):
# 找到00i.png的路径
img = os.path.join(root, '%03d.png'%i)
# 找到00i_mask.png的路径
mask = os.path.join(root, '%03d_mask.png'%i)
# 添加至列表
imgs.append((img, mask))
return imgs
class LiverDataset(data.Dataset):
def __init__(self, root, transform=None, target_transform=None):
imgs = make_dataset(root)
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
x_path, y_path = self.imgs[index]
img_x = Image.open(x_path)
img_y = Image.open(y_path)
if self.transform is not None:
img_x = self.transform(img_x)
if self.target_transform is not None:
img_y = self.target_transform(img_y)
return img_x, img_y
def __len__(self):
return len(self.imgs)
筹备训练
# 数据预处理
x_transforms = transforms.Compose([
transforms.ToTensor(), # 转为Tensor
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 标准化
])
# mask只需转为Tensor
y_transforms = transforms.ToTensor()
# 数据加载
batch_size = 4
liver_dataset = LiverDataset('data/liver/train', transform=x_transforms, target_transform=y_transforms)
dataloaders = DataLoader(liver_dataset, batch_size=batch_size, shuffle=True)
transform.Compose():将多个transforms组合起来
transform.ToTensor():将PIL Image或者numpy.ndarray转为torch.FloatTensor
transform.Normalize():将张量归一化
定义模型
# U_Net模型中的双卷积网络结构
class DoubleConv(nn.Module):
def __init__(self, in_ch, out_ch):
super(DoubleConv, self).__init__()
self.conv = nn.Sequential(
# 此处包含padding,为了使输出图像与输入图像大小相同
nn.Conv2d(in_ch, out_ch, kernel_size=3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, kernel_size=3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, input):
return self.conv(input)
class Unet(nn.Module):
def __init__(self, in_ch, out_ch):
super(Unet, self).__init__()
# 编码器部分
# 特征图大小不变
self.conv1 = DoubleConv(in_ch, 64)
# 特征图大小长宽减半
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.conv2 = DoubleConv(64, 128)
self.pool2 = nn.MaxPool2d(2)
self.conv3 = DoubleConv(128, 256)
self.pool3 = nn.MaxPool2d(2)
self.conv4 = DoubleConv(256, 512)
self.pool4 = nn.MaxPool2d(2)
# 瓶颈层
self.conv5 = DoubleConv(512, 1024)
# 解码器部分
self.up6 = nn.ConvTranspose2d(1024, 512, kernel_size=2, stride=2)
self.conv6 = DoubleConv(1024, 512)
self.up7 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)
self.conv7 = DoubleConv(512, 256)
self.up8 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.conv8 = DoubleConv(256, 128)
self.up9 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.conv9 = DoubleConv(128, 64)
self.conv10 = nn.Conv2d(64, out_ch, kernel_size=1)
def forward(self, x):
c1 = self.conv1(x)
p1 = self.pool1(c1)
c2 = self.conv2(p1)
p2 = self.pool2(c2)
c3 = self.conv3(p2)
p3 = self.pool3(c3)
c4 = self.conv4(p3)
p4 = self.pool4(c4)
c5 = self.conv5(p4)
up_6 = self.up6(c5)
# 通道维拼接 [N, C, H, W]
merge6 = torch.cat([up_6, c4], dim=1)
c6 = self.conv6(merge6)
up_7 = self.up7(c6)
merge7 = torch.cat([up_7, c3], dim=1)
c7 = self.conv7(merge7)
up_8 = self.up8(c7)
merge8 = torch.cat([up_8, c2], dim=1)
c8 = self.conv8(merge8)
up_9 = self.up9(c8)
merge9 = torch.cat([up_9, c1], dim=1)
c9 = self.conv9(merge9)
c10 = self.conv10(c9)
out = torch.sigmoid(c10)
return out
定义损失函数
# 输入图像有3个通道,标签图像有1个通道
net = Unet(3, 1).to(device)
# 类似逻辑回归,用一个输出来实现2分类
loss = torch.nn.BCELoss()
optimizer = optim.Adam(net.parameters())
定义训练过程
def train_model(model, loss, optimizer, dataloaders, num_epochs=20):
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs-1))
print('-'*10)
dt_size = len(dataloaders.dataset)
epoch_loss = 0
step = 0
for x, y in dataloaders:
step += 1
inputs = x.to(device)
labels = y.to(device)
optimizer.zero_grad()
outputs = model(inputs)
l = loss(outputs, labels)
l.backward()
optimizer.step()
epoch_loss += l.item()
if step % 200 == 0:
print('%d/%d, train_loss:%0.3f' % (step, (dt_size-1)//dataloaders.batch_size+1, l.item()))
print('epoch %d loss:%0.3f' % (epoch, epoch_loss))
return model
开展训练
model = train_model(net, loss, optimizer, dataloaders)
运行结果:

预测并显示结果
liver_val = LiverDataset('data/liver/val', transform=x_transforms, target_transform=y_transforms)
liver_val = DataLoader(liver_val, batch_size=1)
model.eval()
with torch.no_grad():
for i, data in enumerate(liver_val): # 修正这里
# 左边真实,右边预测
x, z = data
x = x.to(device) # 确保数据在正确的设备上
y = model(x) # 直接使用 x
img_y = torch.squeeze(y.cpu()).numpy()
z = torch.squeeze(z).numpy()
plt.subplot(1, 2, 1)
plt.imshow(z, cmap='gray') # 如果是灰度图,加上 cmap='gray'
plt.axis('off') # 关闭坐标轴
plt.subplot(1, 2, 2)
plt.imshow(img_y, cmap='gray') # 如果是灰度图,加上 cmap='gray'
plt.axis('off') # 关闭坐标轴
plt.pause(0.01)
# 确保 img_y 在 0-255 范围内
img_y = (img_y * 255).astype('uint8')
filename = 'data/liver/predict/' + 'new_%d.png' % i
Image.fromarray(img_y).convert('L').save(filename)
运行结果:
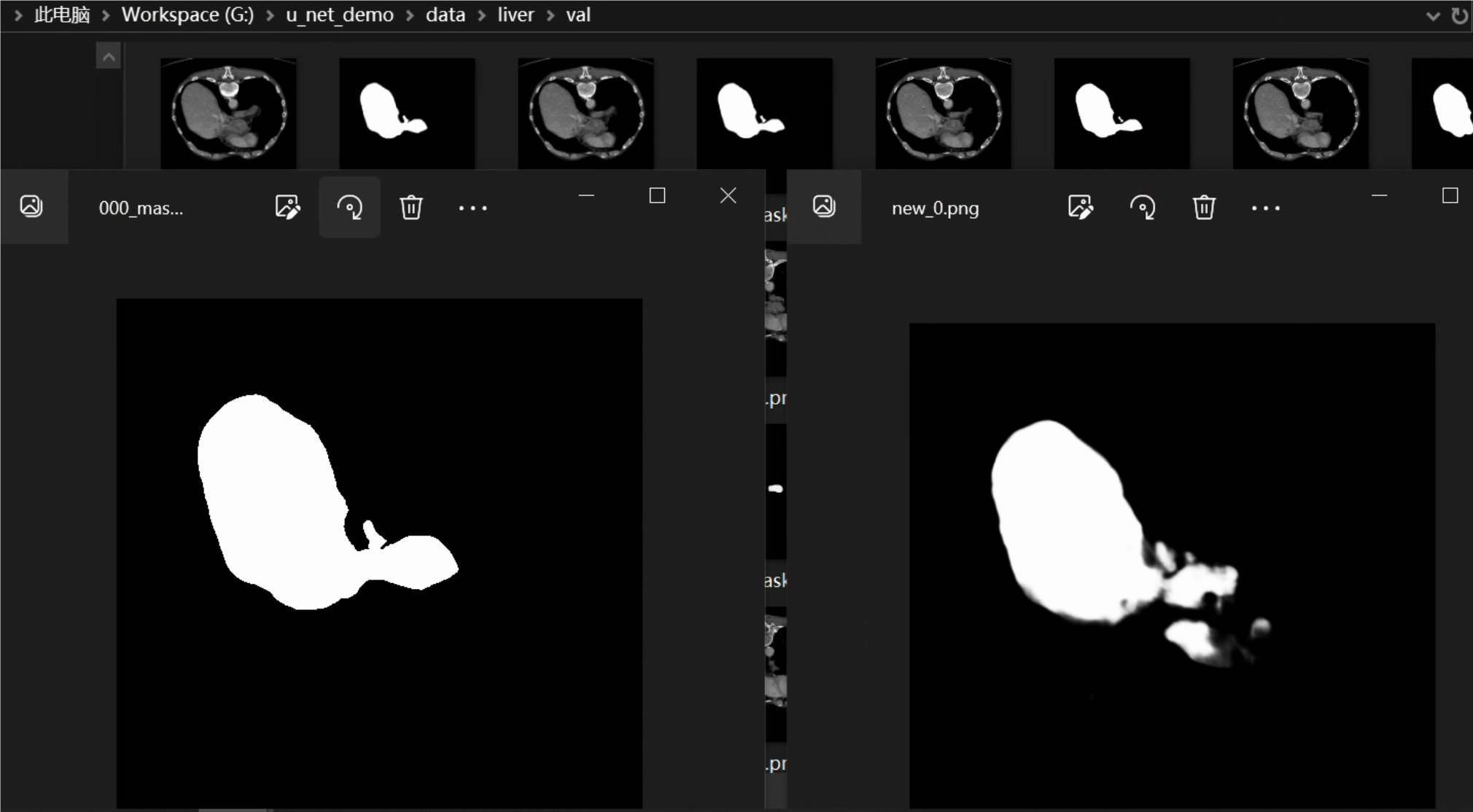
对比验证集目录val目录和predict预测结果目录下的图片,可以发现预测结果与真实结果基本一致。
补充知识
膨胀卷积 和 空洞卷积
定义:
膨胀卷积(Dilated Convolution)和空洞卷积(Atrous Convolution)是同一个概念的不同称呼。它们的主要目的是在不增加参数数量的情况下扩大卷积核的感受野,从而捕捉更大范围的上下文信息。通过在卷积核中插入“空洞”,可以在保持特征图尺寸的同时增加感受野。
提出背景
在一些任务中,尤其是语义分割,需要同时提取多尺度的特征。传统的卷积层在处理不同尺度的特征时可能会受到限制,而空洞卷积可以通过调整空洞率灵活地提取不同尺度的信息。
主要作用:
- 感受野:通过增加空洞率(dilation rate),可以扩大感受野,使模型能够获取更大范围的信息。
- 计算效率:与增加卷积核大小相比,膨胀卷积在计算上更高效,因为它不需要增加参数数量。
- 保持特征图的尺寸:膨胀卷积可以在不改变输入特征图的尺寸的情况下进行。
示例代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义一个简单的卷积神经网络,包含膨胀卷积
class DilatedConvNet(nn.Module):
def __init__(self):
super(DilatedConvNet, self).__init__()
# 使用膨胀卷积,dilation=2
self.dilated_conv = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=2, dilation=2)
def forward(self, x):
return self.dilated_conv(x)
# 创建模型和输入数据
model = DilatedConvNet()
input_data = torch.randn(1, 1, 5, 5) # Batch size = 1, Channels = 1, Height = 5, Width = 5
# 前向传播
output = model(input_data)
print("Input shape:", input_data.shape)
print("Output shape:", output.shape)
nn.Conv2d的dilation参数设置为 2,这意味着卷积核的空洞率为 2。卷积核在计算时会在每个元素之间插入一个空洞。
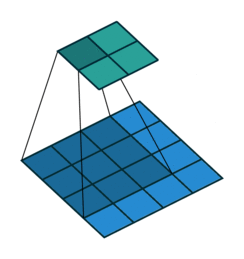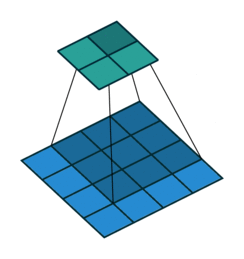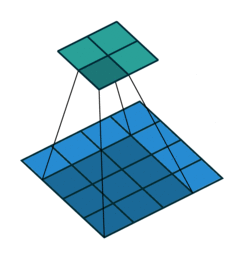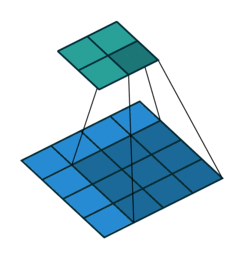
kernel_size=3, stride=1, padding=0
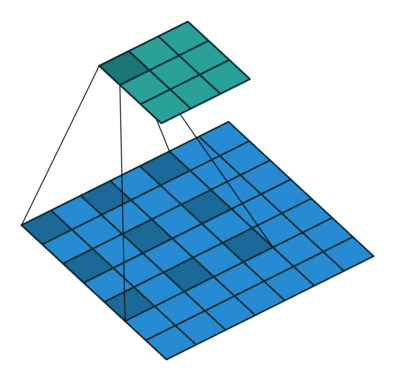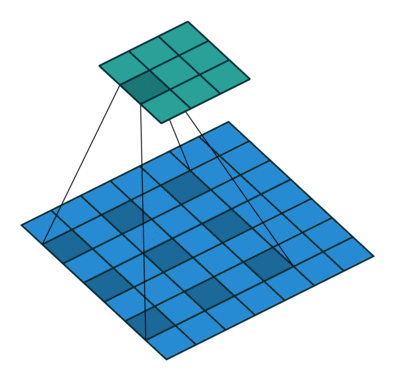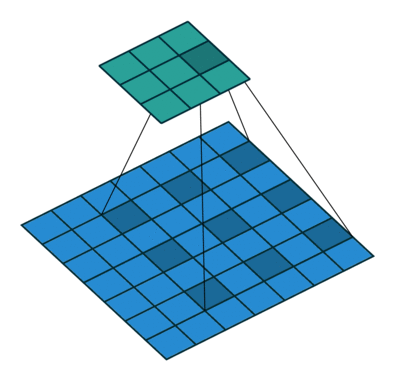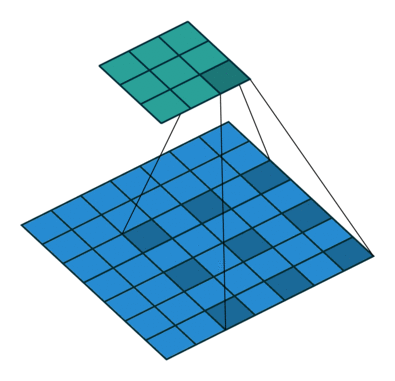
kernel_size=3, stride=1, padding=2, dilation=2
- 二者的卷积核大小都是一样的(滑窗的实际大小是一样的),但空洞卷积的滑窗(kernel)元素之间是存在一些间隙的,这些间隙在空洞卷积中成为膨胀因子(dilated ratio)。
- 如果 dilated ratio=1 时,空洞卷积就是普通卷积。
内容小结
- 语义分割,是将图像中的每个像素都分类为特定的语义类别
- U-Net 是一种语义分割神经网络模型
- U-Net 由两个部分组成:编码器和解码器
- 编码器(收缩路径)主要是由卷积操作和池化(下采样)操作组成。
- 解码器(扩张路径)主要是由卷积操作和反卷积操作组成。
- 在语义分割时,有时需要同时提取多尺度的特征,而空洞卷积可以通过调整空洞率灵活地提取不同尺度的信息。















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









