









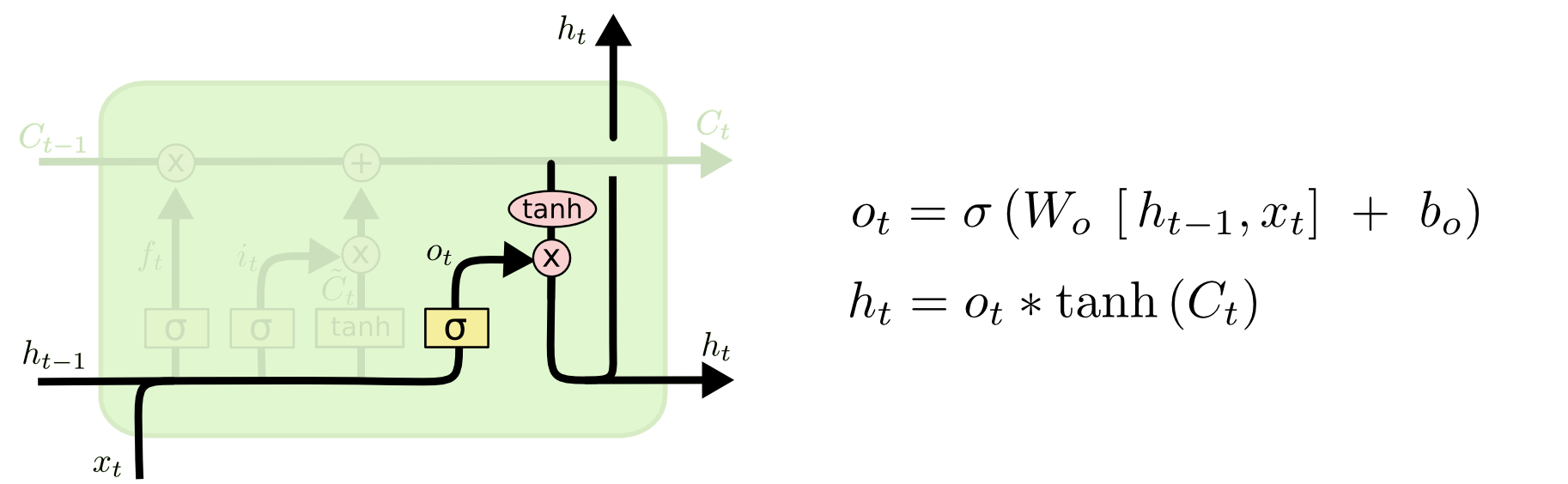
理解encoder_outputs, state_h, state_c = encoder(encoder_inputs)的三个输出:
https://huhuhang.com/post/machine-learning/lstm-return-sequences-state
inputs = tf.keras.layers.Input(shape=(3, 1))
lstm = tf.keras.layers.LSTM(1, return_state=True)(inputs)
model = tf.keras.models.Model(inputs=inputs, outputs=lstm)
model.predict(data)

全代码:
#!/user/bin/env python3
# -*- coding: utf-8 -*-
# setup
import numpy as np
import tensorflow as tf
from tensorflow import keras
# download dataset
# !!curl -O http://www.manythings.org/anki/fra-eng.zip
# !!unzip fra-eng.zip
# configuration
batch_size = 64 # Batch size for training.
epochs = 100 # Number of epochs to train for.
latent_dim = 256 # Latent dimensionality of the encoding space.
num_samples = 10000 # Number of samples to train on.
# Path to the data txt file on disk.
data_path = "fra.txt"
# Prepare the data
# Vectorize the data
# 空集
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()
# 读取文本
with open(data_path, "r", encoding="utf-8") as f:
lines = f.read().split("\n") # 每行
# for line in lines[: min(num_samples, len(lines) - 1)]: # 训练num_samples个数据或训练集中全部数据
for line in lines[: 100]:
input_text, target_text, _ = line.split("\t") # 每行有input_text, target_text,用制表符隔开
# We use "tab" as the "start sequence" character
# for the targets, and "\n" as "end sequence" character.
target_text = "\t" + target_text + "\n"
# 得到文本集
input_texts.append(input_text)
target_texts.append(target_text)
# 得到字符集
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
# vocabulary, max_seq_len
input_characters = sorted(list(input_characters)) # dictionary的key,key‘s index为value
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters) # vocabulary
num_decoder_tokens = len(target_characters)
max_encoder_seq_length = max([len(txt) for txt in input_texts]) # max_seq_len of 源语言
max_decoder_seq_length = max([len(txt) for txt in target_texts]) # max_seq_len of 目标语言
print("Number of samples:", len(input_texts))
print("Number of unique input tokens:", num_encoder_tokens)
print("Number of unique output tokens:", num_decoder_tokens)
print("Max sequence length for inputs:", max_encoder_seq_length)
print("Max sequence length for outputs:", max_decoder_seq_length)
# build encoding dictionary
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])
# 初始化encoder和decoder的训练数据的input和target矩阵
# encoder's input
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens), dtype="float32"
) # shape = (len(input_texts), max_encoder_seq_length, num_encoder_tokens) i.e. (total_samples_num, max_seq_len, vocabulary)
# decoder's input
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens), dtype="float32"
)
# decoder's target
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens), dtype="float32"
)
# 得到上述三个矩阵的one-hot encoding矩阵,根据每个字符在dictionary的index,将index列的数赋值为1
# (i, t, char) i.e. (ith sample text, t_th char in this sample, index of this char in the dictionary)
# 注意zip的使用和enumerate的使用
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.0
# 若是sample长度小于max_seq_len,那么后面的字符(从t+1开始到max_seq_len结束)都按空格算
encoder_input_data[i, t + 1 :, input_token_index[" "]] = 1.0
for t, char in enumerate(target_text):
# decoder_target_data is ahead of decoder_input_data by one timestep
''' 比如t = 0,1,2,3,4,那么decoder_input_data有t = 0, 1, 2, 3, 4,decoder_target_data有t = 0, 1, 2, 3,
其余都按空格算'''
decoder_input_data[i, t, target_token_index[char]] = 1.0
if t > 0:
# decoder_target_data will be ahead by one timestep
# and will not include the start character.
decoder_target_data[i, t - 1, target_token_index[char]] = 1.0
decoder_input_data[i, t + 1 :, target_token_index[" "]] = 1.0
decoder_target_data[i, t:, target_token_index[" "]] = 1.0
# Build the model
# Define an input sequence and process it.
''''None' elements represent dimensions where the shape is not known.
batch_size不用包括在shape中,函数最终的输出会在张量第一维度默认加上值为None的batch size信息.'''
# 定义encoder的输入层,LSTM层
encoder_inputs = keras.Input(shape=(None, num_encoder_tokens))
encoder = keras.layers.LSTM(latent_dim, return_state=True)
# 使用encoder的LSTM层,得到最终h,c状态向量
encoder_outputs, state_h, state_c = encoder(encoder_inputs) # define function using layer and input (output_after_layer = layer(input))
# We discard `encoder_outputs` and only keep the final states.
encoder_states = [state_h, state_c]
# Set up the decoder
# 定义输入层
decoder_inputs = keras.Input(shape=(None, num_decoder_tokens))
# We set up our decoder to return full output sequences,
# and to return internal states as well. We don't use the
# return states in the training model, but we will use them in inference.
# 定义lstm层
decoder_lstm = keras.layers.LSTM(latent_dim, return_sequences=True, return_state=True)
# 使用lstm层,initial_state = encoder_states = [state_h, state_c]
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states) # using `encoder_states` as initial state.
# 定义dense层
decoder_dense = keras.layers.Dense(num_decoder_tokens, activation="softmax")
# 使用dense层
ecoder_outputs = decoder_dense(decoder_outputs)
# 定义总模型,声明输入输出:Define the model that will turn `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = keras.Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.summary()
# train the model
model.compile(
optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"]
)
model.fit(
[encoder_input_data, decoder_input_data],
decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2,
)
# Save model
model.save("s2s")
# Run inference (sampling)
''' 1. encode input and retrieve initial decoder state
2. run one step of decoder with this initial state and a "start of sequence" token as target.
Output will be the next target token.
4. Repeat with the current target token and current states'''
''' 得到encoder的最终状态,作为decoder的初始状态。t = 0时,输入[start],预测第一个字符,得到预测的概率分布,从中抽样得到第一个字符,记录下来。
抽样函数可以是:确定性抽样(取概率值最大的),随机抽样,temperature-cotrolled 随机抽样。
t = 1时,将从t = 0时刻预测的概率分布中抽样得到的第一个字符作为输入,预测第二个字符的概率分布,抽样得到第二个字符,记录下来。
重复...
一旦抽样到[end]终止符,就停止重复,并返回记录下的字符串'''
# Define sampling models
# Restore the model and construct the encoder and decoder.
model = keras.models.load_model("s2s") # load trained model
encoder_inputs = model.input[0] # input_1
encoder_outputs, state_h_enc, state_c_enc = model.layers[2].output # lstm_1
encoder_states = [state_h_enc, state_c_enc]
encoder_model = keras.Model(encoder_inputs, encoder_states)
# 定义输入层,可以直接从model(trained model)拿,也可以新定义
decoder_inputs = model.input[1] # input_2
decoder_state_input_h = keras.Input(shape=(latent_dim,), name="input_3")
decoder_state_input_c = keras.Input(shape=(latent_dim,), name="input_4")
# 定义decoder_states_inputs,每个时刻LSTM的状态输入
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
# 定义LSTM层和使用LSTM层的函数
decoder_lstm = model.layers[3] # lstm_2
# We don't use the return states in the training model, but we will use them in inference.
decoder_outputs, state_h_dec, state_c_dec = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs
)
# 得到这一时刻的LSTM状态(会作为下一时刻的状态输入)
decoder_states = [state_h_dec, state_c_dec]
# 定义dense层
decoder_dense = model.layers[4]
# 使用dense层
decoder_outputs = decoder_dense(decoder_outputs)
# 定义总模型,声明输入输出
''' decoder_inputs, dim = 57, 输入的字符向量
decoder_states_inputs, 上一状态的h和c向量作为下一状态的状态输入,长度都为dim = 256
decoder_outputs,dense层输出,dim = 57, 预测的字符向量概率矩阵,我们要从中抽样出预测的字符
decoder_states, dim = 256, 将作为下一状态的decoder_states_inputs, '''
decoder_model = keras.Model(
[decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states
)
# Reverse-lookup token index to decode sequences back to something readable:
# 之前的dictionary为了encode token(char) to index,我们用dictionary called input_token_index, dict.item() = (char, index)
# 为了decode index to token,我们用dictionary called reverse_input_char_index,dict.item() = (index,char)
# build decoding dictionary
reverse_input_char_index = dict((i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict((i, char) for char, i in target_token_index.items())
def decode_sequence(input_seq):
# Encode the input as state vectors.
states_value = encoder_model.predict(input_seq) # Model类的方法predict
# Generate empty target sequence of length 1.
target_seq = np.zeros((1, 1, num_decoder_tokens))
# Populate the first character of target sequence with the start character.
target_seq[0, 0, target_token_index["\t"]] = 1.0
# Sampling loop for a batch of sequences
# (to simplify, here we assume a batch of size 1).
stop_condition = False
decoded_sentence = ""
while not stop_condition:
output_tokens, h, c = decoder_model.predict([target_seq] + states_value)
# Sample a token
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# Exit condition: either hit max length
# or find stop character.
if sampled_char == "\n" or len(decoded_sentence) > max_decoder_seq_length:
stop_condition = True
# Update the target sequence (of length 1).
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.0
# Update states
states_value = [h, c]
return decoded_sentence
# test: use the model
# You can now generate decoded sentences as such:
for seq_index in range(20):
# Take one sequence (part of the training set)
# for trying out decoding.
input_seq = encoder_input_data[seq_index : seq_index + 1]
decoded_sentence = decode_sequence(input_seq)
print("-")
print("Input sentence:", input_texts[seq_index])
print("Decoded sentence:", decoded_sentence)
reference:
https://keras.io/examples/nlp/lstm_seq2seq/
https://www.bilibili.com/video/BV12f4y12777














 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









