









AI算法半路出家的过程其实是有点痛苦的,告别了曾经熟悉的领域,在陌生又熟悉的道路上摸索着前进,其中的焦虑、彷徨以及面对信息过载的不知所措,常常让人怀疑当初的选择。好在,硬核人生不会被小小的困难劝退,我们有很多路径可以到达彼岸。也特别感谢科技和网络的进步,让知识的获取不再是少数人的专利。前些天找到了一个比较牛的AI学习网站,老师的授课方式风趣幽默,通俗易懂,让学习的过程兴趣盎然,忍不住推荐给大家。
点击跳转到网站
————————————————
1. 背景介绍
随着技术的发展,人脸识别算法在嵌入式终端上的应用越来越广泛,但由于终端设备的算力和存储资源限制,对人脸检测和识别模型的要求倾向于轻量级+高精度。轻量级模型相对于又深又宽的大模型,具有参数量小、乘加数少的特点,但同时在预测精度上不能有太大的损失。
近年来,MobilenetV1,ShuffleNet和MobileNetV2等轻量级网络多用于移动终端的视觉识别任务,但是由于人脸结构的特殊性,这些网络在人脸识别任务上并没有获得满意的效果。针对这一问题,北京交通大学的Sheng Chen等人在论文《MobileFaceNets: Efficient CNNs for Accurate RealTime Face Verification on Mobile Devices》提出了一种专门针对人脸识别的轻量级网络MobileFaceNet。
如下图所示,在使用MobileNetV2等网络进行人脸识别时,平均池化层对FMap-end的Corner Unit和Center Unit给予了同样的权重,但实际上,对于人脸识别来说,中心单元的重要程度显然比角单元重要。因此,需要对网络进行有针对性的优化。论文中,最重要的一个优化就是使用Global Depthwise Convolution (GDConv,全局逐深度卷积层)代替Global Average Pooling (GAP,全局平均池化层),因为GDConv的weights即相当于实现不同位置的重要性权重系数。
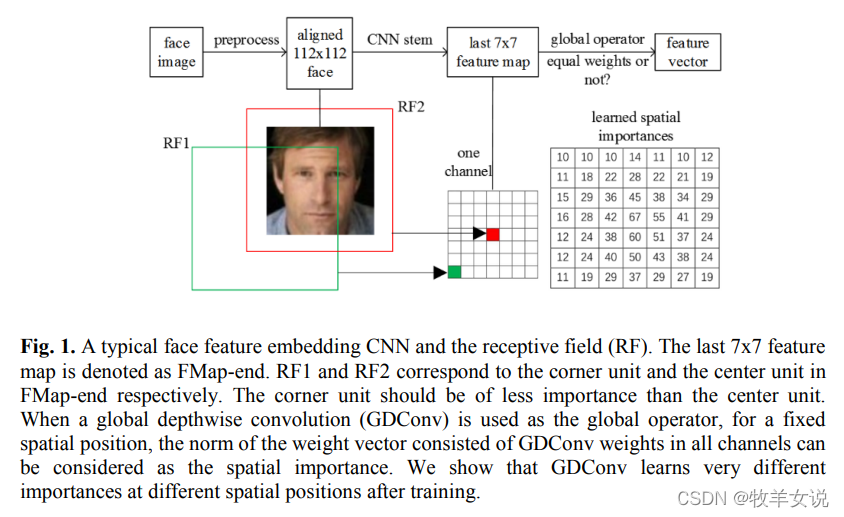
2. 模型结构
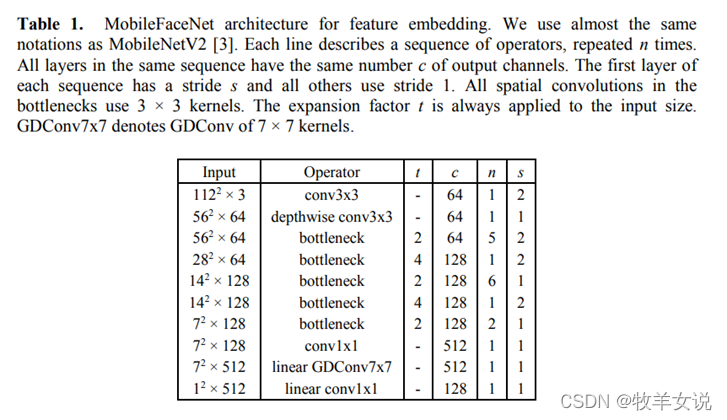
MobileFaceNet的模型结构大致如下:
(1) 采用类似于MobileNetV2的网络结构;
(2) 使用全局逐深度卷积层(GDConv)替代全局平均池化层,以满足最后一层特征图不同位置具有的不同重要程度(相当于实现加权平均的效果);
全局逐深度卷积层的输出为:
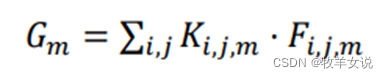
其中,F为输入特征图,大小为W*H*M,K为GDConv的kernel,大小为W*H*M,G为输出,大小为1*1*M。G的第m个channel只有一个元素Gm,(i, j)表示F和K的空间位置,m为channel index。
GDConv的计算量为:W*H*M。
(3) 使用PReLU激活层代替ReLU;
(4) 比MobileNetV2更小的扩展因子;
(5) Fast down sampling。
作为对比,下面分别贴出MobileNetV2和MobileFaceNet的网络结构图:

为了进一步减少计算开销,112x112的输入大小可进一步减小为112x96或96x96。为了减少参数量,将线性GDConv层之后的1x1卷积层去掉,生成MobileFaceNet-M。在MobileFaceNet-M基础上,进一步将GDConv层之前的1x1卷积层去掉,生成最小网络MobileFaceNet-S。
3. 模型参数量和乘加数
按照以上描述的模型结构,MobileFaceNet模型参数量有0.99M,乘加数MAdds为221M。进一步优化后的模型MobileFaceNet-M和MobileFaceNet-S则具有更少的参数量和乘加数。
下表给出了MobileFaceNet及其变体与已有模型在数据集LFW和AgeDB-30上的精度、参数量以及推理速度的对比。

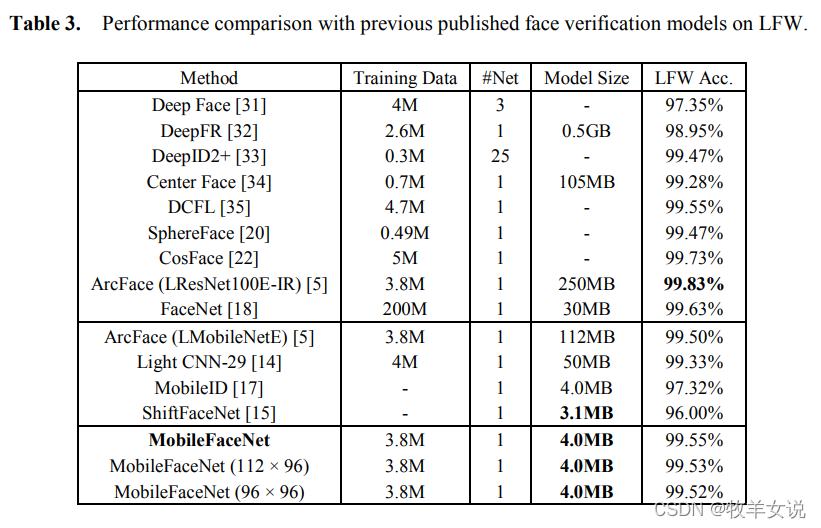
论文中,作者为了验证模型的极端性能,将MobileFaceNet、MobileFaceNet(112x96)、MobileFaceNet(96x96)基于干净的MS-Celeb-M训练集,并使用ArcFace loss进行训练,下表给出了MobileFaceNet及其变体与之前已有人脸识别模型在LFW上的表现对比:

















 6144
6144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









