






论文地址:《Bidirectional LSTM-CRF Models for Sequence Tagging》
论文阅读
研究背景
序列标记包括部分语音标记(POS)、分块和命名实体识别(NER),一直是一项经典的NLP任务。现有的序列标记模型大多是线性统计模型,其中包括隐马尔可夫模型(HMM)、最大熵马尔可夫模型(MEMMs)和条件随机场(CRF)。以及基于卷积网络的模型被提出来解决序列标记问题。本文首次将BI-LSTM-CRF模型应用于NLP基准序列标记数据集。
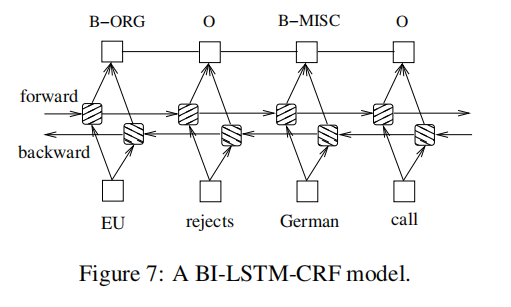
BI-LSTM-CRF 网络
将一个双向的LSTM网络和一个CRF网络结合起来,形成了一个BI-LSTM-CRF网络。除了LSTM-CRF模型中过去使用的输入特征和句子级标签信息外,BI-LSTM-CRF模型还可以使用未来的输入特征。这些额外的特征可以提高标记的准确性。
训练流程
对于每个batch,首先运行双向LSTM-CRF模型正向传递,其中包括LSTM的正向状态和向后状态的正向传递。得到了在所有位置上的所有标签的输出分数(发射矩阵)。然后,我们运行CRF层向前和向后传递来计算网络输出和状态转换边缘的梯度(转移矩阵)。在此之后,我们可以将错误从输出反向传播到输入,其中包括LSTM的正向状态和反向状态的反向传递。最后,更新了网络参数。

实验
(1) 数据:在三个NLP标记任务中使用的数据集为,Penn TreeBank (PTB) 词性标注,
CoNLL 2000 分块,和 CoNLL 2003 命名实体识别。
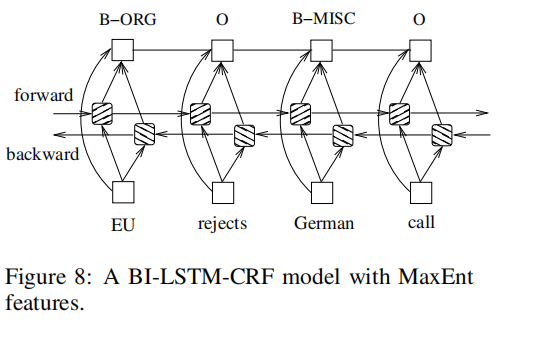
(2)特征:为三个数据集提取相同类型的特征。这些特性可以分组为拼写特性和上下文特性。
(3) 拼写特征:

(4)上下文特征: 使用unigram 特征 和bi-grams 特征。
(5)特征连接技巧:把拼写和上下文特征当作单词特征来处理。也就是说,网络的输入包括单词、拼写和上下文特征。然而,我们发现从拼写和上下文特征到输出的直接连接加速了训练,它们导致了非常相似的标记精度。在特征和输出之间建立完全的连接,以避免潜在的特征冲突。
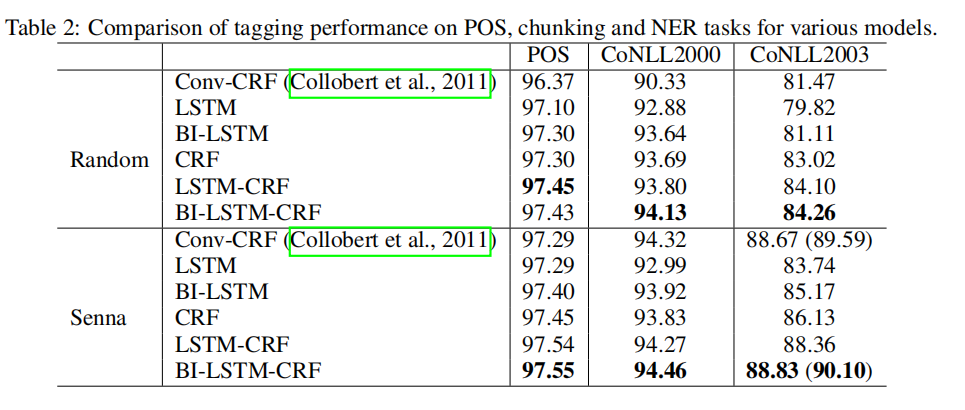
结果对比
结论
观察结果相比,BI-LSTM-CRF模型是鲁棒性的,并且它对单词嵌入的依赖性更小。它可以不需要使用单词嵌入来实现精确的标记精度。















 340
340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









