







Doc2X:PDF转换与翻译领域的佼佼者
借助 Doc2X,您可以快速完成 PDF转Docx、Markdown、Latex 等格式转换,同时体验 表格识别、公式编辑、双语对照翻译 等贴心功能!
Doc2X: A Leader in PDF Conversion and Translation
With Doc2X, quickly convert PDF to Docx, Markdown, or LaTeX, and enjoy features like table recognition, formula editing, and bilingual translation for added convenience!
👉 了解更多 Doc2X 功能 | Learn More About Doc2X
原文链接:https://arxiv.org/pdf/2408.16984
Beyond Preferences in AI Alignment
超越偏好在AI对齐中的应用
Tan Zhi-Xuan
陈志轩
MIT
Micah Carroll
米卡·卡罗尔
UC Berkeley
加州大学伯克利分校
Matija Franklin
马蒂亚·富兰克林
University College London
伦敦大学学院
Hal Ashton
哈尔·阿什顿
University of Cambridge
剑桥大学
Abstract
摘要
The dominant practice of AI alignment assumes (1) that preferences are an adequate representation of human values, (2) that human rationality can be understood in terms of maximizing the satisfaction of preferences, and (3) that AI systems should be aligned with the preferences of one or more humans to ensure that they behave safely and in accordance with our values. Whether implicitly followed or explicitly endorsed, these commitments constitute what we term a preferentist approach to AI alignment. In this paper, we characterize and challenge the preferentist approach, describing conceptual and technical alternatives that are ripe for further research. We first survey the limits of rational choice theory as a descriptive model, explaining how preferences fail to capture the thick semantic content of human values, and how utility representations neglect the possible incommensurability of those values. We then critique the normativity of expected utility theory (EUT) for humans and AI, drawing upon arguments showing how rational agents need not comply with EUT, while highlighting how EUT is silent on which preferences are normatively acceptable. Finally, we argue that these limitations motivate a reframing of the targets of AI alignment: Instead of alignment with the preferences of a human user, developer, or humanity-writ-large, AI systems should be aligned with normative standards appropriate to their social roles, such as the role of a general-purpose assistant. Furthermore, these standards should be negotiated and agreed upon by all relevant stakeholders. On this alternative conception of alignment, a multiplicity of AI systems will be able to serve diverse ends, aligned with normative standards that promote mutual benefit and limit harm despite our plural and divergent values.
AI对齐的主导实践假设(1)偏好是人类价值观的充分表示,(2)人类理性可以通过最大化偏好满足来理解,以及(3)AI系统应与一个或多个人的偏好对齐,以确保其行为安全并符合我们的价值观。无论是隐含遵循还是明确认可,这些承诺构成了我们所谓的AI对齐的偏好主义方法。本文中,我们描述并挑战了偏好主义方法,提出了概念和技术上的替代方案,这些方案已成熟,值得进一步研究。我们首先调查了理性选择理论作为描述模型的局限性,解释了偏好如何未能捕捉到人类价值观的丰富语义内容,以及效用表示如何忽视了这些价值观的可能不可通约性。然后,我们批判了预期效用理论(EUT)对人类和AI的规范性,借鉴了理性代理不必遵守EUT的论点,同时强调了EUT在哪些偏好具有规范性可接受性方面保持沉默。最后,我们认为这些局限性促使AI对齐目标的重构:与其与人类用户、开发者或全人类的偏好对齐,AI系统应与其社会角色相适应的规范标准对齐,例如通用助理的角色。此外,这些标准应由所有相关利益相关者协商和达成一致。在这种对齐的替代概念中,多种AI系统将能够服务于多样化的目的,与促进互利和限制伤害的规范标准对齐,尽管我们的价值观多样且分歧。
1 Introduction
1 引言
Recent progress in the capabilities of AI systems, as well as their increasing adoption in society, has led a growing number of researchers to worry about the impact of AI systems that are misaligned with human values. The roots of this concern vary, with some focused on the existential risks that may come with increasingly powerful autonomous systems (Carlsmith, 2022), while others take a broader view of the dangers and opportunities presented by potentially transformative AI technologies (Prunkl and Whittlestone, 2020; Lazar and Nelson, 2023). To address these challenges, AI alignment has emerged as a field, focused on the technical project of ensuring an AI system acts reliably in accordance with the values of one or more humans.
近年来,人工智能系统能力的进步及其在社会中的日益普及,导致越来越多的研究人员担心与人类价值观不一致的人工智能系统的影响。这种担忧的根源各不相同,一些人关注的是随着越来越强大的自主系统可能带来的存在风险(Carlsmith, 2022),而另一些人则更广泛地看待潜在变革性人工智能技术所带来的危险和机遇(Prunkl 和 Whittlestone, 2020; Lazar 和 Nelson, 2023)。为了应对这些挑战,人工智能对齐已成为一个领域,专注于确保人工智能系统可靠地按照一个或多个人的价值观行事的技术项目。
Yet terms like “human values” are notoriously imprecise, and it is unclear how to operationalize “values” in a sufficiently precise way that a machine could be aligned with them. One prominent approach is to define “values” in terms of human preferences, drawing upon the traditions of rational choice theory (Mishra, 2014), statistical decision theory (Berger, 2013), and their subsequent influence upon automated decision-making and reinforcement learning in AI (Sutton and Barto, 2018). Whether explicitly adopted, or implicitly assumed in the guise of “reward” or “utility”, this preference-based approach dominates both the theory and practice of AI alignment. However, as proponents of this approach note themselves, aligning AI with human preferences faces numerous technical and philosophical challenges, including the problems of social choice, anti-social preferences, preference change, and the difficulty of inferring preferences from human behavior (Russell, 2019). In this paper, we argue that to truly address such challenges, it is necessary to go beyond formulations of AI alignment that treat human preferences as ontologically, epistemologically, or normatively basic. Borrowing a term from the philosophy of welfare (Baber, 2011), we identify these formulations as part of a broadly preferentist approach to AI alignment, which we characterize in terms of four theses about the role of preferences in both descriptive and normative accounts of (human-aligned) decision-making:
然而,诸如“人类价值观”这样的术语是出了名的不精确,目前尚不清楚如何以足够精确的方式将“价值观”操作化,以便机器能够与之对齐。一种突出的方法是根据人类偏好来定义“价值观”,借鉴理性选择理论(Mishra, 2014)、统计决策理论(Berger, 2013)及其随后对自动化决策和人工智能中的强化学习的影响(Sutton and Barto, 2018)。无论是在理论中明确采用,还是在实践中以“奖励”或“效用”的形式隐含假设,这种基于偏好的方法在人工智能对齐的理论和实践中占据主导地位。然而,正如这一方法的支持者自己所指出的,将人工智能与人类偏好对齐面临着众多技术和哲学挑战,包括社会选择问题、反社会偏好、偏好变化以及从人类行为中推断偏好的困难(Russell, 2019)。在本文中,我们认为,要真正解决这些挑战,有必要超越将人类偏好视为本体论、认识论或规范性基础的人工智能对齐表述。借用福利哲学中的一个术语(Baber, 2011),我们将这些表述识别为广泛偏好主义人工智能对齐方法的一部分,我们根据关于偏好在描述性和规范性(人机对齐)决策制定中的作用的四个论点来描述这一方法:
Rational Choice Theory as a Descriptive Framework. Human behavior and decision-making is well-modeled as approximately maximizing the satisfaction of preferences, which can be represented as a utility or reward function.
理性选择理论作为描述性框架。人类行为和决策制定可以很好地建模为近似最大化偏好的满足,这些偏好可以表示为效用或奖励函数。
Expected Utility Theory as a Normative Standard. Rational agency can be characterized as the maximization of expected utility. Moreover, AI systems should be designed and analyzed according to this normative standard.
期望效用理论作为规范性标准。理性代理可以被描述为最大化期望效用。此外,人工智能系统应根据这一规范性标准进行设计和分析。
Single-Principal Alignment as Preference Matching. For an AI system to be aligned to a single human principal, it should act so as to maximize the satisfaction of the preferences of that human.
单一主体对齐作为偏好匹配。为了使人工智能系统与单个人类主体对齐,它应该采取行动以最大化该人类的偏好满意度。
Multi-Principal Alignment as Preference Aggregation. For AI systems to be aligned to multiple human principals, they should act so as to maximize the satisfaction of their aggregate preferences.
多主体对齐作为偏好聚合。为了使人工智能系统与多个人类主体对齐,它们应该采取行动以最大化其聚合偏好的满意度。
These four theses represent a cluster of views, not a unified theory of AI alignment. Still, the ideas they represent are tightly linked, and most approaches to AI alignment assume two or more of the theses. For example, inverse reinforcement learning (Ng and Russell, 2000; Hadfield-Menell et al., 2016), reinforcement learning from human feedback (Akrour et al., 2014; Christiano et al., 2017; Ouyang et al., 2022), and direct preference optimization (Rafailov et al., 2024; Hejna et al., 2024) all assume that human preferences are well-modeled by a reward or utility function, which can then be optimized to produce aligned behavior. Similarly, worries about deceptive alignment (Hubinger et al., 2019) and goal misgeneralization (Di Langosco et al., 2022) are typically characterized as a mismatch between a learned utility function and the human-intended utility function; the solution is thus to ensure that the utility functions (and the preferences they represent) are closely matched.
这四个论点代表了一组观点,而不是一个统一的AI对齐理论。尽管如此,它们所代表的思想紧密相连,大多数AI对齐方法都假设了其中两个或更多的论点。例如,逆强化学习(Ng和Russell,2000;Hadfield-Menell等人,2016)、从人类反馈中进行强化学习(Akrour等人,2014;Christiano等人,2017;Ouyang等人,2022)以及直接偏好优化(Rafailov等人,2024;Hejna等人,2024)都假设人类偏好可以通过奖励或效用函数很好地建模,然后可以对其进行优化以产生对齐行为。同样,关于欺骗性对齐(Hubinger等人,2019)和目标错误泛化(Di Langosco等人,2022)的担忧通常被描述为学习到的效用函数与人类意图效用函数之间的不匹配;因此,解决方案是确保效用函数(及其所代表的偏好)紧密匹配。
Of course, preferentism in AI alignment is not without its critics. There has been considerable discussion as to whether its component theses are warranted (Shah, 2018; Eckersley, 2018; Hadfield-Menell and Hadfield, 2018; Wentworth, 2019, 2023; Gabriel, 2020; Vamplew et al., 2022; Korinek and Balwit, 2022; Garrabrant, 2022; Thornley, 2023), echoing similar debates in economics, decision theory, and philosophy. Nonetheless, it is apparent that the dominant practice of AI alignment has yet to absorb the thrust of these debates. Consequently, we believe it is worthwhile to identify the descriptive and normative commitments of preferentist approaches, to state clearly their limitations, and to describe conceptual and technical alternatives that are ripe for further research (Table 1).
当然,AI对齐中的优先主义并非没有批评者。关于其组成部分的论点是否合理,已经进行了大量的讨论(Shah, 2018; Eckersley, 2018; Hadfield-Menell and Hadfield, 2018; Wentworth, 2019, 2023; Gabriel, 2020; Vamplew et al., 2022; Korinek and Balwit, 2022; Garrabrant, 2022; Thornley, 2023),这与经济学、决策理论和哲学中的类似辩论相呼应。尽管如此,显而易见的是,AI对齐的主流实践尚未吸收这些辩论的核心内容。因此,我们认为有必要识别优先主义方法的描述性和规范性承诺,明确其局限性,并描述那些适合进一步研究的概念和技术替代方案(表1)。
1.1 Overview
1.1 概述
The rest of this paper is organized as follows: In Section 2, we examine rational choice theory as a descriptive account of human decision-making. Drawing upon the tradition of revealed preferences in economics, rational choice theory is often taken for granted by AI researchers seeking to learn human preferences from behavior. In doing so, they assume that human behavior can be modeled as the (approximate) maximization of expected utility, that human preferences can be represented as utility or reward functions, and that preferences are an adequate representation of human values. We challenge each of these assumptions, offering alternatives that better account for resource-limited human cognition, incommensurable values, and the constructed nature of our preferences.
本文的其余部分组织如下:在第2节中,我们将考察理性选择理论作为人类决策的描述性解释。借鉴经济学中显示偏好的传统,理性选择理论通常被寻求从行为中学习人类偏好的AI研究人员视为理所当然。在这样做时,他们假设人类行为可以被建模为预期效用的(近似)最大化,人类偏好可以被表示为效用或奖励函数,并且偏好是人类价值的充分表示。我们挑战这些假设,提出更好的替代方案,以更好地解释资源有限的人类认知、不可通约的价值以及我们偏好的构建性质。
Developing upon these ideas, in Section 3 we turn to expected utility theory (EUT) as a normative standard of rationality. Even while recognizing that humans often do not comply with this standard, alignment researchers have traditionally assumed that sufficiently advanced AI systems will do so, and hence that solutions to AI alignment must be compatible with EUT. In parallel with recent critiques of this view (Thornley, 2023, 2024; Bales, 2023; Petersen, 2023), we argue that EUT is both unnecessary and insufficient for rational agency, and hence limited as both a design strategy and analytical lens. Instead of adhering to utility theory, we can design tool-like AI systems with locally coherent preferences that are not representable as a utility function. We can also go beyond EUT, building systems that reason about preferences in accordance with deeper normative principles.
基于这些观点,在第3节中,我们将预期效用理论(EUT)作为理性规范的标准。尽管认识到人类往往不遵守这一标准,对齐研究者传统上假设足够先进的AI系统将遵守这一标准,因此AI对齐的解决方案必须与EUT兼容。与最近对这一观点的批评(Thornley, 2023, 2024; Bales, 2023; Petersen, 2023)并行,我们认为EUT对于理性代理既不必要也不充分,因此在设计策略和分析视角上都具有局限性。与其遵循效用理论,我们可以设计具有局部一致偏好的工具型AI系统,这些偏好不能表示为效用函数。我们还可以超越EUT,构建根据更深层次规范原则推理偏好的系统。
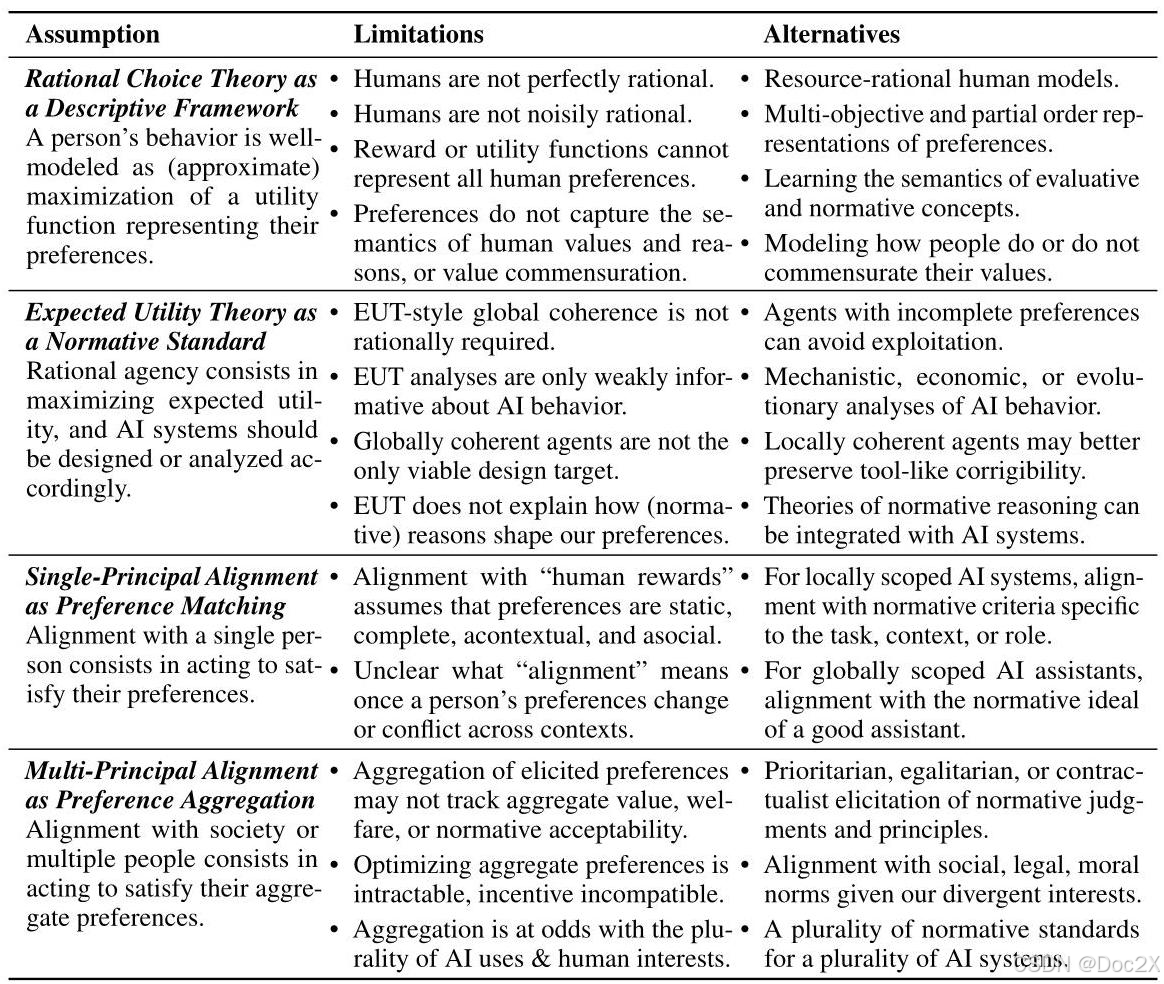
Table 1: Four theses that characterize the preferentist approach to AI alignment, along with a summary of their limitations and alternatives.
表1:四个论题,它们表征了AI对齐的偏好主义方法,并总结了它们的局限性和替代方案。
After interrogating these descriptive and normative foundations, in Section 4 we consider what this implies for aligning AI with a single human principal. Since reward functions may not capture even a single human’s values, the practice of reward learning is unsuitable beyond narrow tasks and contexts where people are willing to commensurate their values. Furthermore, since preferences are dynamic and contextual, they cannot serve as the alignment target for broadly-scoped AI systems. Rather, alignment with an individual person should be reconceived as alignment with the normative ideal of an assistant. More generally, AI systems should not be aligned with preferences, but with the normative standards appropriate to their social roles and functions (Kasirzadeh and Gabriel, 2023).
在审视这些描述性和规范性基础之后,在第4节中,我们考虑这对将AI与单一人类主体对齐意味着什么。由于奖励函数可能无法捕捉到单个人的价值观,奖励学习的实践在狭窄任务和人们愿意协调其价值观的上下文之外是不合适的。此外,由于偏好是动态和情境性的,它们不能作为广泛范围AI系统的对齐目标。相反,与个人的对齐应重新构想为与助手的规范理想对齐。更一般地,AI系统不应与偏好对齐,而应与适合其社会角色和功能的规范标准对齐(Kasirzadeh和Gabriel, 2023)。
If normative standards are to serve as alignment targets, whose judgments do we consider in determining these (oft-contested) standards? We take up this final topic in Section 5, critiquing naive preference aggregation as an approach to aligning AI with multiple human principals (Fickinger et al., 2020). Despite increasing recognition that this approach is inadequate (Critch and Krueger, 2020; Gabriel, 2020; Korinek and Balwit, 2022), applied alignment techniques typically aggregate preferences across multiple individuals, overlooking the contested and plural nature of human values, while conflating norm-specific judgments with all-things-considered preferences. As alternatives, we argue that contractualist and agreement-based approaches can better handle value contestation while respecting the individuality of persons and the plurality of uses we have for AI. This motivates a reframing of the aims of AI alignment as they have often been conceived: Our task is not to align a single powerful AI system with the preferences of humanity writ large, but to align a multiplicity of AI systems with the norms we agree that each system should abide by (Zhi-Xuan, 2022).
如果规范标准要作为对齐目标,我们在确定这些(通常有争议的)标准时应该考虑谁的判断?我们在第5节中讨论了这一最终主题,批评了将朴素偏好聚合作为使AI与多个人类主体对齐的方法(Fickinger et al., 2020)。尽管越来越多的人认识到这种方法是不充分的(Critch and Krueger, 2020; Gabriel, 2020; Korinek and Balwit, 2022),但应用对齐技术通常会聚合多个个体的偏好,忽视了人类价值的争议性和多样性,同时将特定规范的判断与全面考虑的偏好混为一谈。作为替代方案,我们认为契约主义和基于共识的方法可以更好地处理价值争议,同时尊重个人的独特性和我们对AI的多种用途。这促使我们重新构想AI对齐的目标,正如它们通常被设想的那样:我们的任务不是将一个单一的强大AI系统与整个人类的偏好对齐,而是将多个AI系统与我们认为每个系统应遵守的规范对齐(Zhi-Xuan, 2022)。
A note on methodology: Whereas most philosophy papers tend to be narrow in scope, this paper is intentionally broad; it covers a wide range of connected topics, and hence makes arguments that are relatively brief. Our aim is not provide a decisive argument for any particular thesis, but to provide a critical review of the role of preferences in AI alignment, while developing a research agenda for alternative approaches that is accessible to an interdisciplinary audience.
关于方法论的说明:虽然大多数哲学论文往往范围较窄,但本文有意涵盖广泛;它涉及一系列相关主题,因此提出的论点相对简短。我们的目标不是为任何特定论点提供决定性的论证,而是对偏好在对齐AI中的作用进行批判性评述,同时为替代方法制定一个研究议程,使其易于跨学科的受众理解。
2 Beyond rational choice theory when modeling humans
2 在人类建模时超越理性选择理论
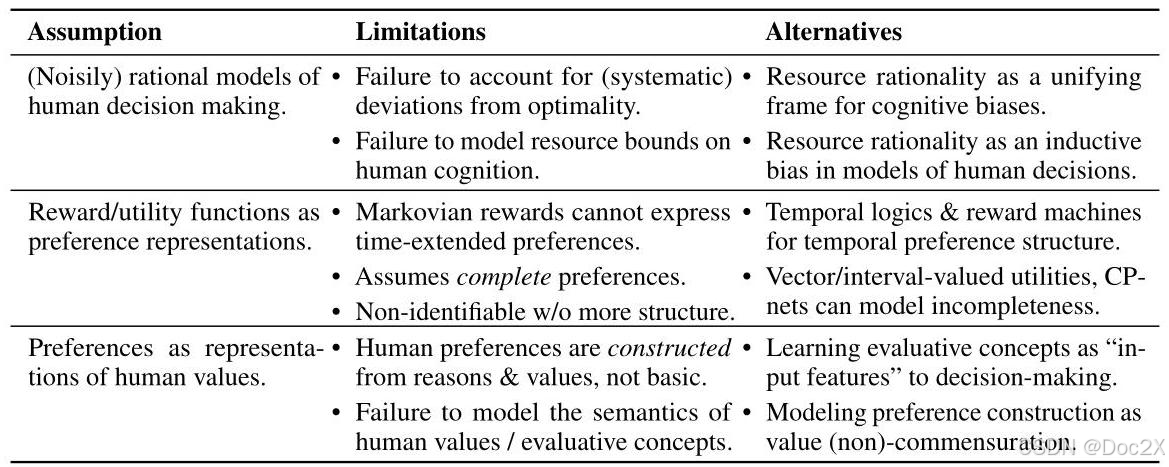
Table 2: Assumptions, limitations, and alternatives to rational choice theory as a descriptive framework for modeling human preferences, values, and decision making.
表2:作为描述性框架的理性选择理论的假设、局限性和替代方案,用于建模人类偏好、价值观和决策。
The central tenet of rational choice theory is the assumption that humans act so as to maximize the satisfaction of their preferences, and that both individual and aggregate human behavior can be understood in these terms. As far as theoretical presuppositions go, this assumption has been wildly successful, forming the bedrock of modern economics as a discipline, and influencing a great variety of fields concerned with analyzing human behavior, including sociology (Boudon, 2003), law (Ulen, 1999), and cognitive science (Chater and Oaksford, 1999; Jara-Ettinger et al., 2020).
理性选择理论的核心原则是假设人类行为旨在最大化其偏好的满足,并且个体和集体的人类行为都可以用这些术语来理解。就理论前提而言,这一假设取得了巨大的成功,成为现代经济学学科的基石,并影响了大量分析人类行为的领域,包括社会学(Boudon, 2003)、法律(Ulen, 1999)和认知科学(Chater 和 Oaksford, 1999; Jara-Ettinger 等, 2020)。
Revealed preferences and their representation as utility functions. In its most standard form, rational choice theory assumes that human preferences can be represented as a scalar-valued utility function defined over outcomes - that is, in terms of a quantity that can be maximized - and that human choice can be modeled as selecting actions so as to maximize the expected value of this function. The promise this offers is that we can directly derive what a person prefers from what they choose, and furthermore represent how much they prefer it as a scalar value. Such preferences are called revealed preferences, because they are supposedly revealed through what a person chooses. This methodology is bolstered by numerous representation theorems (Savage, 1972; Bolker, 1967; Jeffrey, 1991) showing that any preference ordering over outcomes that obeys certain “rationality axioms” can be represented in terms of a utility function, such as the famous von Neumann-Morgenstern (VNM) utility theorem (von Neumann and Morgenstern, 1944).
显示偏好及其作为效用函数的表示。在最标准的形式中,理性选择理论假设人类偏好可以表示为一个定义在结果上的标量值效用函数——即,以可以最大化的数量来表示——并且人类选择可以建模为选择行动以最大化此函数的期望值。这提供的前景是,我们可以直接从一个人的选择中推导出他们的偏好,并且进一步将他们偏好的程度表示为一个标量值。这种偏好被称为显示偏好,因为它们据称是通过一个人的选择揭示出来的。这种方法得到了众多表示定理的支持(Savage, 1972; Bolker, 1967; Jeffrey, 1991),这些定理表明,任何服从某些“理性公理”的结果偏好排序都可以用效用函数来表示,例如著名的冯·诺依曼-摩根斯坦(VNM)效用定理(von Neumann 和 Morgenstern, 1944)。
Rational choice theory in machine learning. In keeping with rational choice theory, many machine learning and AI systems also assume that human preferences can be derived from human choices in a more or less direct manner, and furthermore represent those preferences in terms of scalar utilities or rewards. This is most pronounced in the fields of inverse reinforcement learning (Ng and Russell, 2000; Abbeel and Ng, 2004; Hadfield-Menell et al., 2016) and reinforcement learning from human feedback (Christiano et al., 2017; Zhu et al., 2023), which explicitly assume that the behavior of a human can be described as (approximately) maximizing a sum of scalar rewards over time, and then try to infer a reward function that explains the observed behavior. Similar assumptions can be found in the field of recommender systems (Thorburn et al., 2022), with many papers modeling recommendation as the problem of showing items to users that they are most likely to engage with, which is presumed to be the item they find the most rewarding (Li et al., 2010; Hill et al., 2017; McInerney et al., 2018).
机器学习中的理性选择理论。根据理性选择理论,许多机器学习和人工智能系统也假设人类偏好可以通过人类选择以或多或少直接的方式推导出来,并且进一步以标量效用或奖励的形式表示这些偏好。这在逆强化学习(Ng 和 Russell, 2000; Abbeel 和 Ng, 2004; Hadfield-Menell 等, 2016)和从人类反馈中进行强化学习(Christiano 等, 2017; Zhu 等, 2023)领域最为明显,这些领域明确假设人类的行为可以描述为(近似地)随着时间的推移最大化标量奖励的总和,然后尝试推断出一个解释观察到的行为的奖励函数。类似的假设也可以在推荐系统领域找到(Thorburn 等, 2022),许多论文将推荐建模为向用户展示他们最有可能与之互动的项目的问题,这被认为是他们认为最有回报的项目(Li 等, 2010; Hill 等, 2017; McInerney 等, 2018)。
Boltzmann models of noisily-rational choice. While these preference-based models of human behavior are rooted in rational choice theory, it is worth noting that they are slightly more complex than “maximize expected utility” might imply. In particular, they allow for the fact that humans may not always maximize utility, and hence are models of noisy or approximately rational choice. In machine learning and AI alignment, the most common of such choice models is called Boltzmann rationality (after the Boltzmann distribution in statistical mechanics), which assumes that the probability of a choice c c c is proportional to the exponential of the expected utility of taking that choice:
噪声理性选择的玻尔兹曼模型。虽然这些基于偏好的行为模型根植于理性选择理论,但值得注意的是,它们比“最大化预期效用”所暗示的要稍微复杂一些。特别是,它们允许人类并不总是最大化效用的事实,因此是噪声或近似理性选择的模型。在机器学习和人工智能对齐中,最常见的此类选择模型被称为玻尔兹曼理性(以统计力学中的玻尔兹曼分布命名),该模型假设选择 c c c 的概率与采取该选择的预期效用的指数成正比:
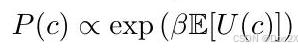
—— 更多内容请到Doc2X翻译查看——
—— For more content, please visit Doc2X for translations ——


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









