






1 INTRODUCTION
基本就是笑GCN无谋,GAT少智(算不了大图)
贡献:提出了SCARA这个算大规模graph的近线性的算法
2 PRELIMINARIES AND RELATED WORKS
Post-Propagation Model.
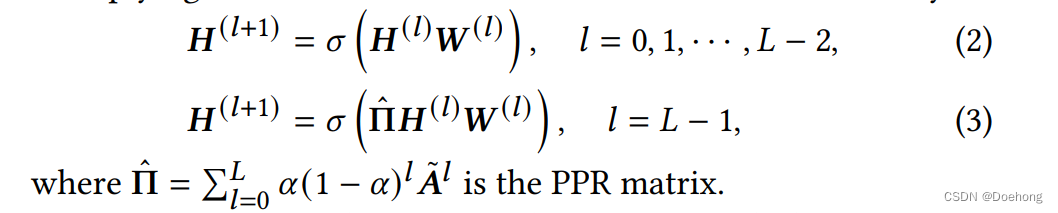
前面的层只有不同特征之间的交互,只有最后一层才会在不同节点之间传播feature。APPNP等中应用。
Pre-Propagation Model.
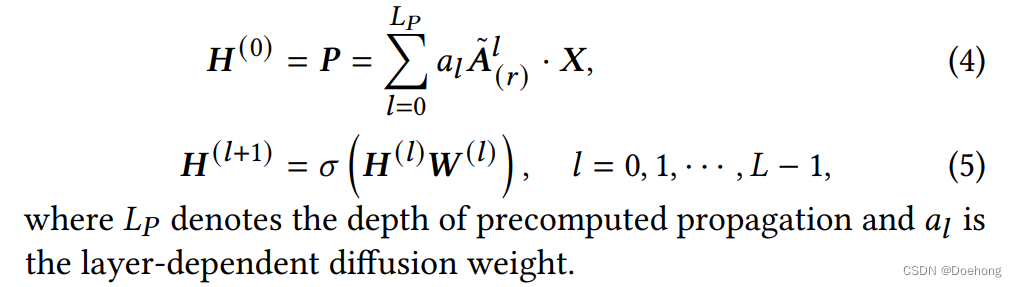
SGC等算法中采用。第一层传播,后面的层不再传播。
3 SCARA FRAMEWORK
3.1 Overview
对于大规模图的计算,最大的成本之一在传播阶段。这篇论文采用了第二种先传播方式。传播公式如下。我的理解整个论文主要就是在Pre-Propagation里面,用了一个新的高效方式来计算P。主要思想是用一个快速的PPR计算方式计算出一部分feature的PPR传播结果,然后作为基,用这些基去近似其他的feature的PPR传播结果。
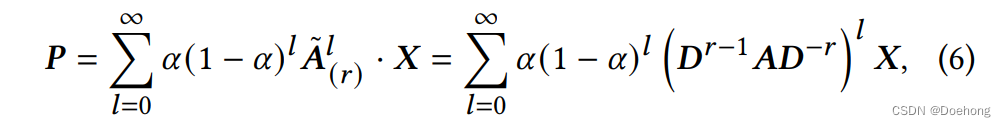
3.2 Feature-Push

对特征进行类似PPR的传播。这里是对不同节点每个相同维度的特征进行PPR传播,这里对大残差值的用push方式,对小的用蒙特卡洛采样的方式。在本论文中这个是用来计算基PPR和残差PPR的。是个比较新的PPR算法,是17年kdd的篇成果。
3.3 Feature-Reuse
这一节就是这篇文章的主要新颖的思路。利用一些基去近似其他的特征PPR传播结果。我的理解是这依赖与朴素的思想。如果两个特征具有一定程度的相似性,那么他们传播的结果可能也很相似。本文的近似思路比较朴素。就是多项式近似。下面以论文中一个例子解释:
假设b是一个基𝒃 = (0.5, 0.5),需要计算的PPR 𝒙 = (0.4, 0.6)。显然可以讲需要计算得到x进行分解
𝒙 = (0.4, 0.4) + (0, 0.2)。x = 0.8𝝅 (𝒃)+(0, 0.2)。(0, 0.2)为残差,b为基,这个𝝅 (.)在我理解中就是b这个基进行了PPR值的计算之后的结果,这个最终结果,表示在b这个特征上,不同节点的一个相似程度。就是基于这个思路设计了如下算法2

整个算法2比较清晰。显示选基2-8行,可以看出选基标注就是找一个尽量和所有feature都相似的基(即你要去估计一个人的长相,那肯定要拿该地区平均长相去为基作为近似,上下浮动着调)这里找n_B个基。
然后按照上述方式去迭代近似,14行的while循环,但是这样最终还会有一个小的残差。这个残差还是会用算法一去计算,我的理解是因为这个比较小,所以push和采样都不会重复多少次,因此这个过程也很快。好算法总体结束。
3.4 Complexity Analysis
详情自己查看论文
4 EXPERIMENTAL EVALUATION
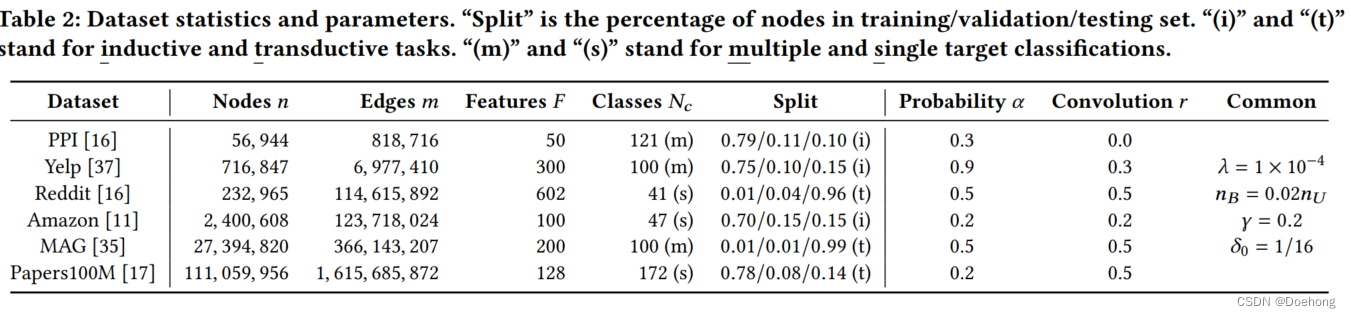
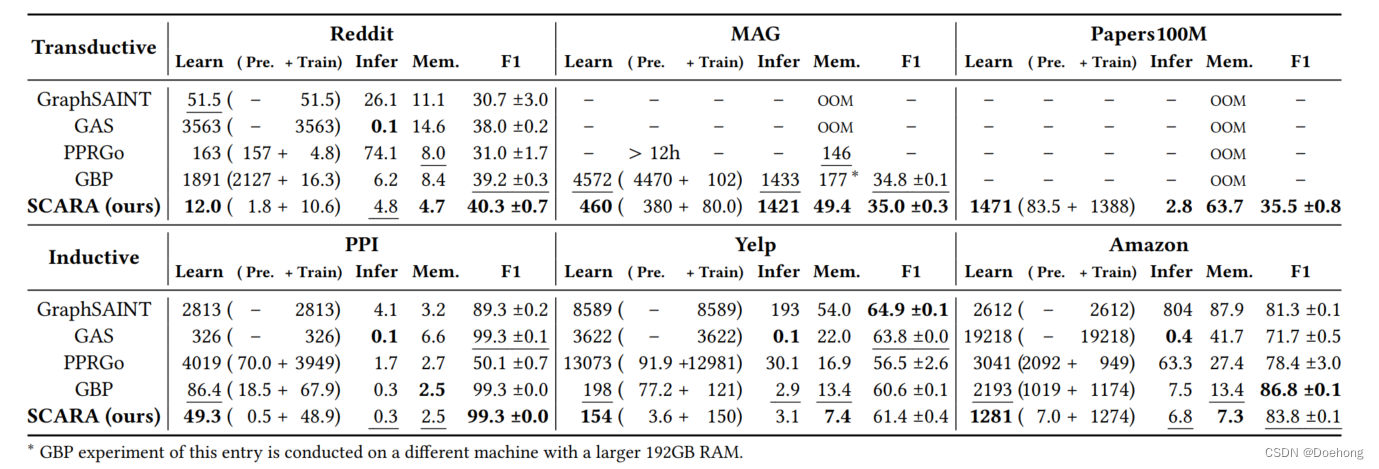
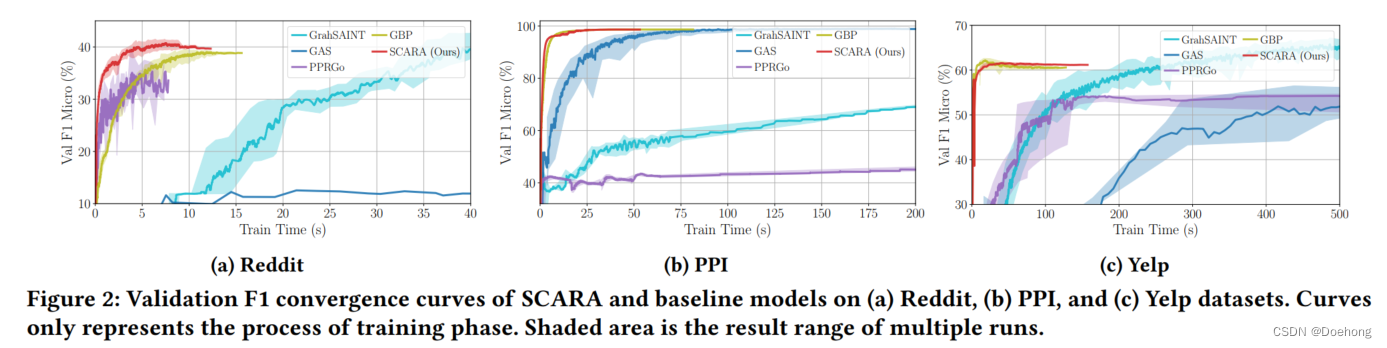
实验基本来说不用看,不好也不会写上去

















 3198
3198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









