







文章目录
如果安装的是标准的 Docker(例如
docker.io,
Docker version 24.0.7),而没有安装
nvidia-docker,但仍然能在容器中使用 CUDA,有以下几种可能:
1. CUDA 已经在宿主机上安装并正确配置
即使你没有安装 nvidia-docker,如果宿主机上已经安装了 NVIDIA 驱动程序,并且容器的运行时被配置为支持 CUDA,某些容器仍然可以直接访问宿主机的 GPU 和 CUDA。
这种情况下,可能是你使用了 NVIDIA 提供的 nvidia-container-runtime,或者直接通过 Docker 的 --device 选项映射了 GPU 设备。
-
设备映射:你可以通过
--device=/dev/nvidia0或类似选项手动将 GPU 设备映射到容器里。例如:docker run -it --device=/dev/nvidia0 --device=/dev/nvidiactl --device=/dev/nvidia-uvm my-cuda-container -
环境变量:一些容器(如 NVIDIA 提供的 CUDA 容器镜像)可以自动检测并使用宿主机上的 GPU,前提是你已经在宿主机上安装并配置了正确的 NVIDIA 驱动。
2. 使用了 nvidia-container-runtime
即使你没有安装 nvidia-docker,如果你在 Docker 配置中指定了 nvidia-container-runtime,那么 Docker 容器依然能够访问 GPU。例如,在宿主机的 Docker 配置文件(/etc/docker/daemon.json)中配置了 nvidia-container-runtime 作为默认运行时。
(我的是这样,确实配置了)
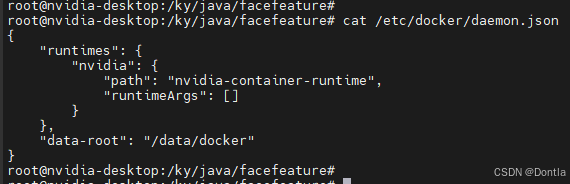
nvidia-container-runtime 是 NVIDIA 提供的容器运行时,它允许 Docker 容器通过 GPU 访问 CUDA 和其他 NVIDIA 资源,即使你没有安装 nvidia-docker。你可以通过以下步骤确认是否配置了该运行时:
-
检查 Docker 配置文件(
/etc/docker/daemon.json):{ "runtimes": { "nvidia": { "path": "/usr/bin/nvidia-container-runtime" } } } -
如果该文件存在并且配置了
nvidia-container-runtime,那么 Docker 会使用该运行时来启动容器并访问 GPU。
3. 容器镜像已包含 CUDA
如果你使用的是一个基于 CUDA 的官方容器镜像,例如 nvidia/cuda 或其他与 NVIDIA GPU 兼容的镜像,这些镜像通常已经集成了 CUDA 环境,并且会自动检测宿主机的 NVIDIA 驱动和 GPU 资源。在这种情况下,如果宿主机配置正确,容器能够正常使用 CUDA。
(确实是这样,我用的是英伟达提供的容器镜像:https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-pytorch,并且在容器run的时候加上了--runtime nvidia参数)
4. CUDA 和 NVIDIA 驱动的兼容性
即使没有 nvidia-docker,只要宿主机上的 NVIDIA 驱动和 CUDA 工具包兼容,并且容器没有完全隔离 GPU 资源,容器依然可以直接访问 GPU。通常,使用 NVIDIA GPU 的应用依赖于驱动(例如 libcuda)来访问 GPU 资源,而这些可以在没有 nvidia-docker 的情况下通过 Docker 配置来共享。
总结
即使你安装的是标准的 Docker(没有 nvidia-docker),如果宿主机配置了 NVIDIA 驱动并且容器镜像支持 CUDA,容器仍然可以调用 GPU 加速。最常见的原因包括:
- 宿主机上安装了 NVIDIA 驱动,并且通过设备映射或正确的运行时配置(例如
nvidia-container-runtime)使得容器能够访问 GPU。 - 使用了支持 CUDA 的容器镜像,并且宿主机的 CUDA 环境已配置好。
如果你没有显式安装 nvidia-docker,你可以检查 Docker 配置文件和运行时设置,看看是否已经启用了 nvidia-container-runtime。


















 1660
1660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











