







文章目录
前言
在深度学习模型的压缩和加速过程中,剪枝是一种极其重要且常用的技术。通过剪枝,可以有效地减少模型的参数数量和计算开销,从而提升推理速度和降低存储需求,同时,剪枝还能在保持模型性能的前提下,实现更高的计算效率和资源利用率,是优化深度学习模型不可或缺的关键手段。
视频效果
YOLOv10轻量化|基于L1正则化的结构化通道剪枝【附代码】
文章概述
本文介绍了如何训练自己的YOLOv10模型,并对其进行剪枝优化。具体步骤包括解析命令行参数以指定模型路径、剪枝策略和比例,定义剪枝函数和结构以找出可剪枝层并进行修剪,保存更新后的剪枝模型。接着,对剪枝后的模型进行fine-tune训练,最后对比剪枝前后的模型效果,分析参数量、计算量和FPS等指标的变化,评估剪枝优化的效果。
必要环境
-
配置yolov10环境 可参考往期博客
地址:搭建YOLOv10环境 训练+推理+模型评估
-
安装torch-pruning 0.2.7版本,安装命令如下
pip install torch-pruning==0.2.7
一、训练原始模型
运行方法如下
python 1_yolov10-train.py --weights yolov10n.pt --data data.yaml --epoch 200 --batch 32 --workers 8
运行效果:
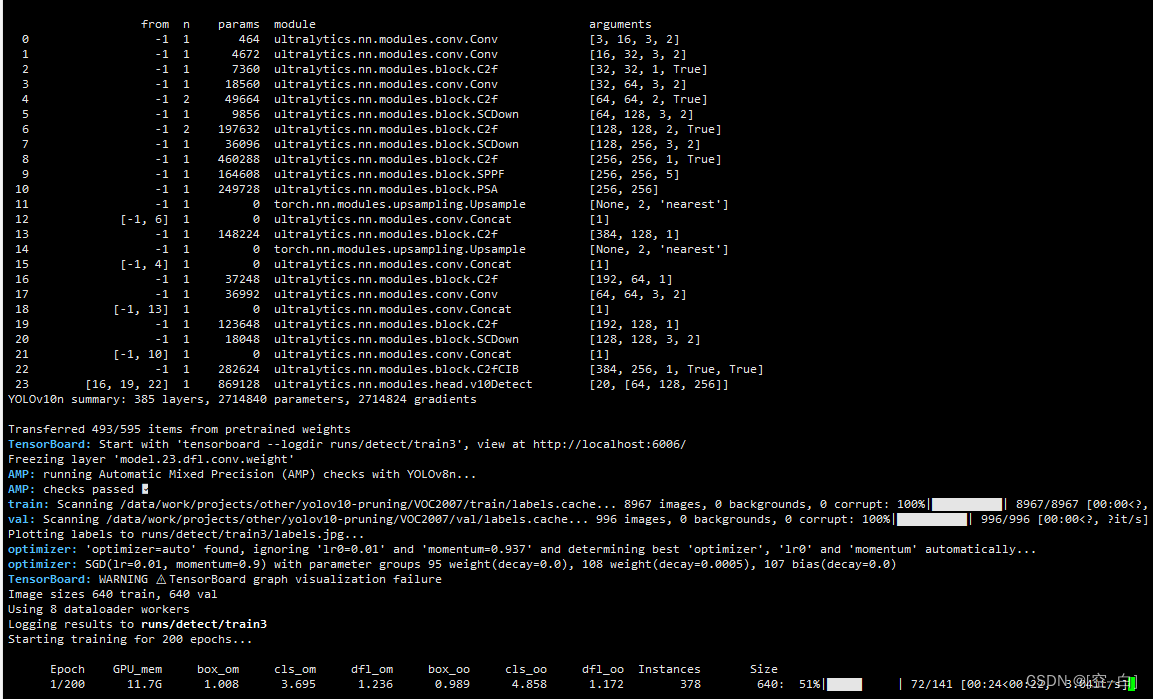
正常训练时会打印模型在yaml文件中定义的网络结构
二、模型剪枝
1、 对训练好的原始模型将进行修剪
运行命令如下
python 2_yolov10-pruning.py --model_path yolov10n.pt --prune_type l1 --prune_ratio 0.55
运行效果:

运行成功后会输出剪枝后的网络结构,以及剪枝前后模型的参数量对比
2、 关键代码讲解
1.命令行参数
import argparse
def parse_args():
# 创建参数解析器
parser = argparse.ArgumentParser(description="Prune a YOLOv10 model to reduce its size and complexity.")
# 添加参数 --model_path,指定模型路径
parser.add_argument("--model_path", type=str,
default=r"yolov10n.pt",
help="File path to the YOLOv10 model to be pruned. Default is 'yolov10n.pt'.")
# 添加参数 --prune_type,指定剪枝策略
parser.add_argument("--prune_type", type=str, default="l1", choices=["l1", "l2", "random"],
help="Pruning strategy to use. Options are: 'l1' for L1-norm pruning, 'l2' for L2-norm pruning, and 'random' for random pruning. Default is 'l1'.")
# 添加参数 --prune_ratio,指定剪枝比例
parser.add_argument("--prune_ratio", type=float, default=0.55, help="Ratio of the model to prune. Must be a float between 0 and 1. Default is 0.55.")
# 解析参数
args = parser.parse_args()
return args
参数详解:
- –model_path: 指定需要剪枝的模型路径
- –prune_type: 指定剪枝策略,可选方案为 l1, l2, random,默认使用 l1策略
- –prune_ratio: 指定剪枝比例,默认值为0.55,表示对定义的卷积层减掉55%的通道数
2. 定义剪枝函数
def prune_model(model, prune_type, prune_ratio, input_tensor):
strategy = {
'l1': tp.strategy.L1Strategy(),
'l2': tp.strategy.L2Strategy(),
'random': tp.strategy.RandomStrategy()
}.get(prune_type, tp.strategy.RandomStrategy())
dependency_graph = tp.DependencyGraph().build_dependency(model, example_inputs=input_tensor)
included_layers = get_included_layers(model)
original_params = tp.utils.count_params(model)
pruning_plans = [
dependency_graph.get_pruning_plan(m, tp.prune_conv, idxs=strategy(m.weight, amount=prune_ratio))
for m in model.modules() if isinstance(m, nn.Conv2d) and m in included_layers
]
关键步骤详解:
-
策略选择 依据 prune_type 参数,选择适合的剪枝策略,如果 prune_type 并非预定义的值,则默认采用L1策略来进行剪枝操作
-
构建依赖图 调用 tp.DependencyGraph().build_dependency 函数,构建模型的依赖关系图,以便在后续步骤中能够顺利进行剪枝操作
-
获取包含的层 通过 get_included_layers 函数,识别并获取需要进行剪枝的层,这些层主要包括模型中的 nn.Conv2d 层
-
计算原始参数数量 利用 tp.utils.count_params 函数,计算并记录模型在剪枝前的参数总量,以便后续进行对比和评估
-
制定剪枝计划 针对每一个需要剪枝的 nn.Conv2d 层,使用相应的剪枝策略来计算应该剪枝的索引,并根据这些索引生成详细的剪枝计划
3. 定义需要修剪的修剪结构
从指定模型中, 找出所有可以进行剪枝操作的层, 并将它们添加到 included_layers 列表中
def get_included_layers(model):
included_layers = [] # 用于存储所包含的层
# 遍历模型中的每一层
for layer in model.model:
if isinstance(layer, Conv): # 检查是否为卷积层
included_layers.append(layer.conv) # 将卷积层添加到列表中
...
elif isinstance(layer, v10Detect): # 检查是否为v10Detect层
included_layers.extend([
layer.cv2[i][j].conv
for i in range(3)
for j in range(2)
])
...
# 省略其他层处理逻辑
return included_layers
关键模块详解:
- model: 传入yolov10模型。函数将遍历这个模型中的所有层,以识别哪些部分可以进行剪枝操作
- included_layers: 用于存储那些能够进行剪枝的层,函数会将这些层逐一识别并添加到这个列表中
- 定义模型中不同类型的层。函数会根据每个层的具体类型采取相应的处理方法,并将可以剪枝的部分添加到 included_layers 列表中
4. 保存更新后的模型
剪枝操作完成后,我们需要将剪枝后的模型保存,以便后续使用
def save_pruned_model(model, prune_type):
param_dict = {
'model': model,
}
torch.save(param_dict, f'prune_model_{prune_type}.pt')
参数详解:
- model:传入剪枝后的模型
- prune_type:定义剪枝类型,用于命名保存的模型文件
5. 主函数
定义主函数,整合上述各个步骤,实现完整的剪枝流程
def main():
args = parse_args()
# 加载模型
yolov10 = YOLOv10(args.model_path)
# 使模型参数可训练
for para in model.parameters():
para.requires_grad = True
# 执行剪枝
pruned_model, original_params = prune_model(model, args.prune_type, args.prune_ratio, input_tensor)
# 保存更新后的模型
save_pruned_model(pruned_model, args.prune_type)
pruned_params = tp.utils.count_params(model)
pruned_model(input_tensor)
percentage_reduction = ((original_params - pruned_params) / original_params) * 100
logger.info(
f"Params: {original_params * 4 / 1024 / 1024:.2f} MB => {pruned_params * 4 / 1024 / 1024:.2f} MB (Reduction: {percentage_reduction:.2f}%)")
关键模块解读:
- parse_args():解析命令行参数。
- YOLOv10(args.model_path):加载YOLOv10模型
- prune_model():执行剪枝操作
- save_pruned_model():保存剪枝后的模型
- 计算剪枝前后参数的变化,并打印模型信息和参数减少的百分比
三、剪枝后的训练
运行命令如下
python 3_yolov10-finetune.py --finetune --epochs 200 --batch_size 32
运行效果:
 可以看到剪枝后训练不会打印模型在yaml文件中定义的网络结构
可以看到剪枝后训练不会打印模型在yaml文件中定义的网络结构
四、剪枝前后效果对比
剪枝前:

Params:10.36MB GFLOPs:8.43G MACs:4G FPS稳定在35-45帧之间 各别时候不稳定会蹦到50-60或20-30左右
剪枝后:

Params:5.19MB GFLOPs:4.02G MACs:4G FPS稳定在45-55帧之间 各别时候不稳定会蹦到60或20-30左右
整体来看剪枝后参数量、计算量、复杂度都降低了,提升了推理速度,但与此同时模型精度也会有一定程度的下降
总结
本期博客就到这里啦,喜欢的小伙伴们可以点点关注,感谢!


















 2818
2818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











