







目录
Calibration校准曲线:就是将实际发生率和预测发生率绘制的散点图。是对Hosmer-Lemeshow拟合优度检验的结果可视化。
基本原理:
首先利用列线图预测每位研究对象的预测值,并将其按从低到高的顺序排列,根据四分位数将队列分为4组(或者根据其他分位数分组),然后分别计算每组研究对象的预测值和相应的实际值得均值,并将两者结合起来作图得到4个校准点,最后将这4个校准点连接起来得到预测校准曲线。
二分类资料
1. 单一模型校准曲线
lrm()函数拟合的logistic模型
使用rms包中的lrm()函数拟合logistic模型,然后使用calibrate()函数拟合校准曲线,并使用plot()绘图
案例:肺动脉栓塞模型
#载入数据
library(readxl)
data <- read_excel("data.xlsx")
data<-na.omit(data)
data<-as.data.frame(data)
#建立模型公式
form.bestglm<-as.formula(group~age+BMI+ToS+CA153+CDU+transfusion+stage)
form.all<-as.formula(group~.)
#打包
library(rms)
dd=datadist(data)
options(datadist="dd")
#建立logistic模型
fit.glm<- lrm(formula=form.bestglm,data=data,x=TRUE,y=TRUE) 进行校准曲线拟合
cal.glm<-calibrate(fit.glm,method = "boot",B=1000)method设置抽样的方法为bootstrap,B设置bootstrap的次数为1000。
绘制校准曲线
par(mar=c(5,5,2,1))
plot(cal.glm,
xlim = c(0,1),
ylim = c(0,1),
xlab = "Predicted Probability",
ylab="Observed Probability",
xaxs = "i",
yaxs = "i",
legend =FALSE,
subtitles = FALSE,#不显示副标题
cex=1.5,
cex.axis=1.5,
cex.lab=1.5)
abline(0,1,col="blue",lty=2,lwd=2) #绘制参考线
#调用cal.glm中的“calibrated.orig",即未校正的曲线,设置为实线,红色
lines(cal.glm[,c("predy","calibrated.orig")],type="l",lwd=2,col="red")
#调用cal.glm中的"calibrated.corrected",即校准的曲线,实线绿色
lines(cal.glm[,c("predy","calibrated.corrected")],type="l",lwd=2,col="green")
legend(x=0.55,y=0.35,
legend=c("Ideal","Apparent","Bias-corrected"),
lty = c(2,1,1),
lwd = c(2,1,1),
col = c("blue","red","green"),
bty="n",
cex=1.5)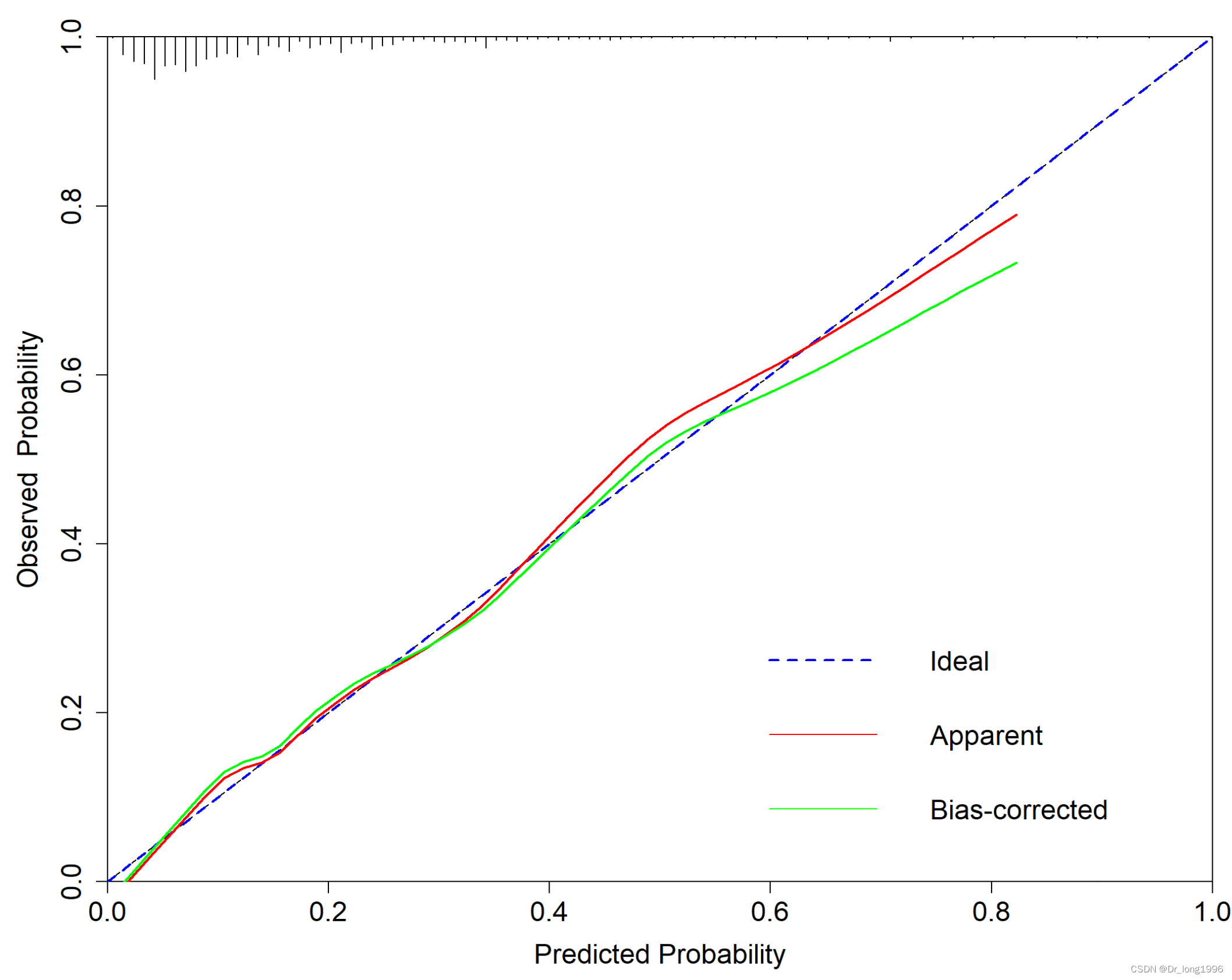
横坐标为预测值,纵坐标为实际值,45°Ideal线为参考线,Apparent线表示预测值与实际值的拟合情况,Bias-corrected实线表示校正之后的预测值与实际值的拟合情况。
若Bias-corrected线或Apparent线越接近Ideal线,说明预测值与实际值的一致性越好。
glm()函数拟合的logistic模型
a.Score()函数
拟合logistic模型
library(riskRegression)
fit.glm = glm(formula=form.bestglm,data=data,family=binomial())进行校准曲线拟合(跟ROC一样)
xb <-Score(object=list(fit.glm),
formula=group~1,
plots=c("calibration","ROC"),
metrics = c("auc", "brier"),
B=1000,M=50,
data=data)绘制校准曲线:
plotCalibration(x=xb,
xlab="Predictd Risk",
ylab = "Observed Frequency",
col="black",
brier.in.legend=FALSE,
auc.in.legend=FALSE)不显示brier的得分和AUC的值
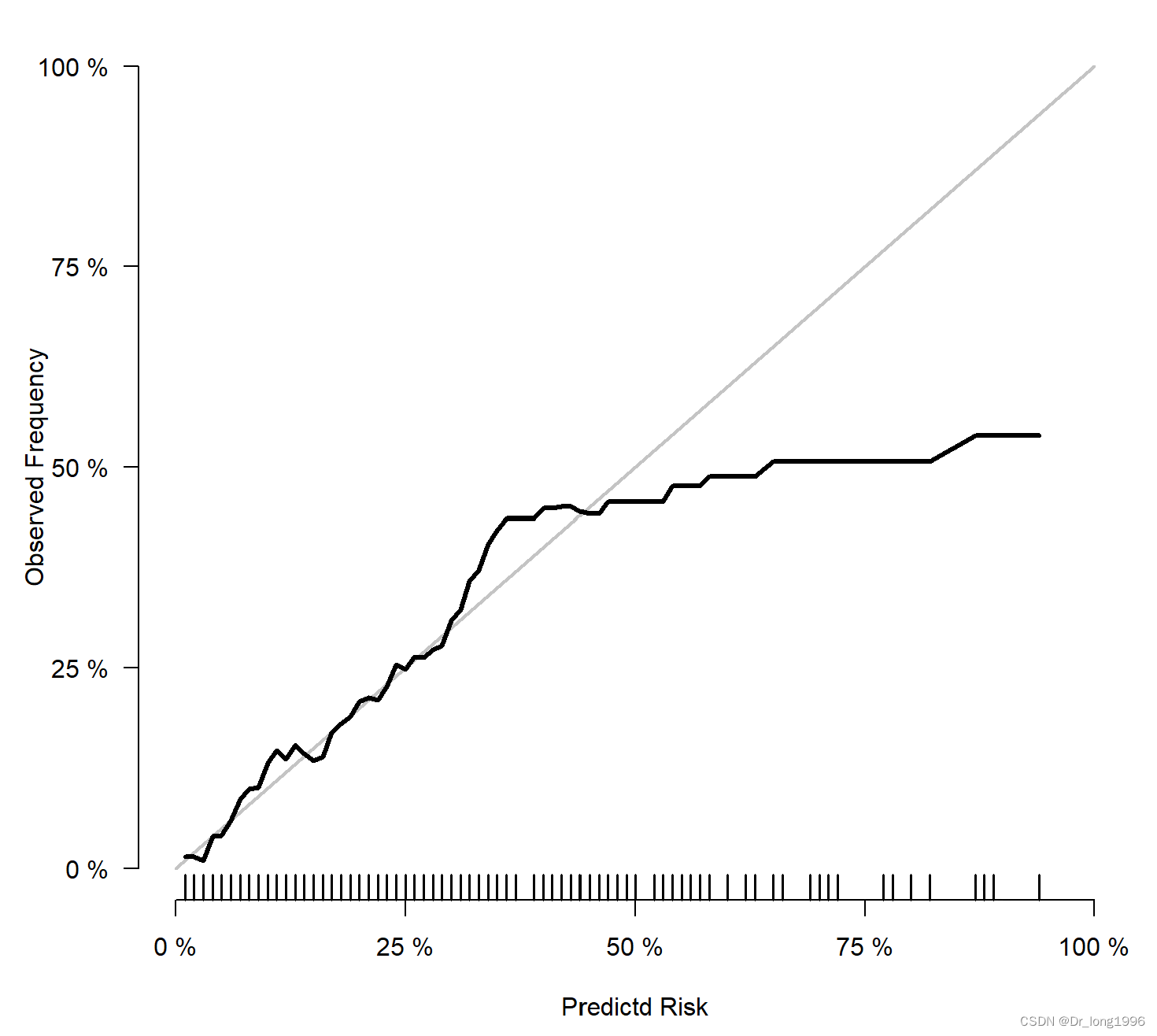
横坐标为预测值,纵坐标为实际值,灰色斜线为参考线,黑色的曲线为预测值与实际值的拟合情况。若黑色线越靠近参考线,说明预测值与实际值的一致性好。
对X轴进行分段处理,绘制频率图
plotCalibration(x=xb,
ylab = "Frequency",
bars=TRUE,
q=7,
show.frequencies=TRUE)bars表示绘制条图,q=7表示x轴的风险大小分成为7段;show=T表示显示频率

纵观七个频段风险,可以发现预测值与实际值之间较为接近,说明预测值和实际值的一致性好。
B.val.prob()函数
fit.glm = glm(formula=form.bestglm,data=data,family=binomial())
pred.logit<-predict(fit.glm)
phat <- 1/(1+exp(-pred.logit))利用predict()函数预测模型fit.glm的线性预测值,然后将其转化为概率值phat。
绘制校准曲线
val.prob(p=phat,y=data$group,m=150,cex=1)p指定概率预测值,y指定实际的分类情况,选项m指定亚组的样本大小,通常设置为总样本大小的1/3或1/4

Ideal为参考线,logistics calibration线也是参考线,Nonparamtric线表示模型拟合情况,Grouped observation为分组估计值,三角形的数目的多少与代码中选项m的大小有关。
该结果还展示了一些统计指标:
Dxy 预测值与实际值的相关性大小,此处为0.613,提示相关性尚可。
C(ROC) C指数,也是ROC曲线下面积 C=(1+Dxy)/2,为0.806。
R2 为模型的复决定系数。
D discrimination index,区分指数,越大越好。
U unreliability index 不可靠指数,越小越好。
Q quality index,越大越好
Brier 预测值与实际值的均方误差,brier越小,校准效果越好
Intercept 截距,Slope 斜率。
Emax 预测值与实际值的最大绝对差值。
Eavg 预测值与实际值的平均差值。
E90 预测值与实际值差值的90%分位数
S:z, S:p 为Z检验的z值和p值。P=0.927说明,拟合效果较好
分亚组检验calibration校准曲线
#连续型变量
v2.glm<-val.prob(p=phat,y=data$group,group=data$BMI,g.group=2)
v2.glm
plot(v2.glm,
lwd=2,
cex=0.62,
cex.axis=1.5,
cex.lab=1.5)
#分类变量
v3.glm<-val.prob(p=phat,y=data$group,group=data$CDU)
v3.glm
plot(v3.glm,
cex=0.62,
cex.axis=1.5,
cex.lab=1.5)group设置一个分组变量,连续型变量需要设置g.group=n,指定需要分组的数量,会根据分位数进行分组。
2.多模型校准曲线
lrm()拟合的logistic回归
拟合logistic模型
fit.glm<- lrm(formula=form.bestglm,data=data,x=TRUE,y=TRUE)
cal.glm<-calibrate(fit.glm,method = "boot",B=1000)
fit1.glm<- lrm(formula=form.all,data=data,x=TRUE,y=TRUE)
cal1.glm<-calibrate(fit1.glm,method = "boot",B=1000)绘制calibration多模型曲线
plot(1,type = "n",
xlim = c(0,1),
ylim = c(0,1),
xaxs = "i",
yaxs = "i",
xlab = "Predicted Probability",
ylab="Observed Probability",
legend =FALSE,
subtitles = FALSE,
cex=1.5,
cex.axis=1.5,
cex.lab=1.5)
abline(0,1,col="black",lty=2,lwd=2)
lines(cal.glm[,c("predy","calibrated.orig")],lty=2,lwd=2,col="green")
lines(cal.glm[,c("predy","calibrated.corrected")],type="l",lwd=2,col="green")
lines(cal1.glm[,c("predy","calibrated.orig")],lty=2,lwd=2,col="blue")
lines(cal1.glm[,c("predy","calibrated.corrected")],type="l",lwd=2,col="blue")
legend(0.01,0.95,
c("Model Bestglm calibrated.orig",
"Model Bestglm Bias-corrected",
"Model All calibrated.orig",
"Model All Bias-corrected"),
lty = c(2,1,2,1),
lwd = c(2,2,2,2),
col = c("green","green","blue","blue"),
bty="n",
cex=0.5) #"o"为加边框plot()函数中,1,type=“n”,表示绘制一幅空白的图。

各线都接近参考线,说明预测值与实际值的一致性较好。
glm()拟合的logistic回归
fit.glm = glm(formula=form.bestglm,data=data,family=binomial())
fit1.glm = glm(formula=form.all,data=data,family=binomial())
xb2 <-Score(object=list("Model Bestglm"=fit.glm,
"Model All"=fit1.glm),
formula=group~1,
plots=c("calibration","ROC"),
metrics = c("auc", "brier"),
B=1000,M=50,
data=data)
plotCalibration(xb2,
xlab="Predictd Risk",
ylab = "Observed Frequency",
brier.in.legend=FALSE,
auc.in.legend=FALSE)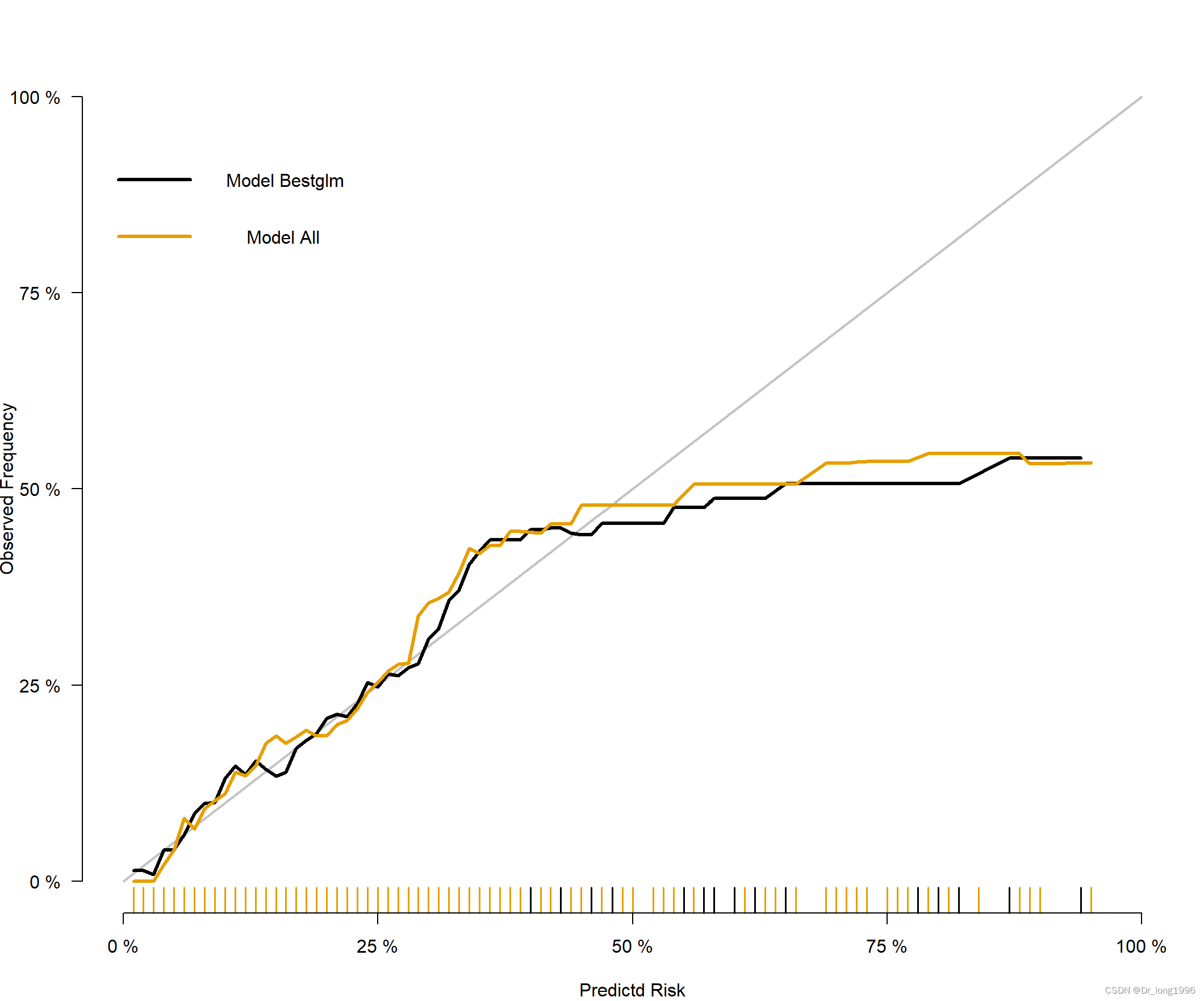
生存资料
rms包中的cph()函数拟合的cox比例风险模型,使用calibration()函数拟合校准曲线;
使用survival包中的coxph()拟合的Cox模型,使用riskRegression包中的Score()函数拟合校准曲线。
案例:胰腺癌病人术后的生存情况。结局为死亡,纳入的因素包括患者年龄,性别,有无放化疗,病变部位,胰胆管浸润程度,有无腹膜转移,肿瘤的TNM分期。
pancer<-read.csv("pancer.csv",header = TRUE,sep = ",")
str(pancer)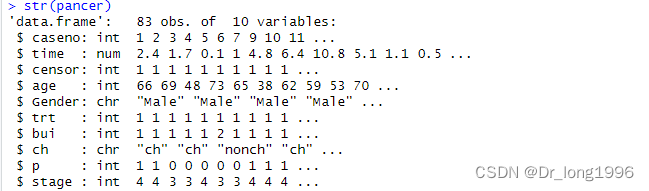
caseno表示编号;
time表示随访事件,单位为月
censor表示随访结局,1表示死亡,0表示删失;
trt表示注中是否放疗,1表示放疗,2表示没有;
bui表示病变部位,1表示胰头部,2表示头部以外;
ch表示胰胆管浸润程度;
p表示腹膜是否转移,1有,0没有;
stage表示分期,3表示III期,4表示IV期。
单模型单时点校准曲线
rms包cph()函数拟合的生存模型
form.cox<-as.formula(Surv(time,censor==1)~age+Gender+trt+bui+ch+p+stage)
library(rms)
fit.cox <- cph(formula = form.cox,data=pancer,x=TRUE,y=TRUE,surv=TRUE,time.inc = 3)time.inc=3表示进行3个月的模型拟合。
拟合calibration:
cal.cox <- calibrate(fit.cox,
cmethod='KM',
method='boot',
u=3,
m=40,
B=1000)cmethod指定生存预测方法,通常为“KM”。 u需要与模型中的time.inc保持一致。选项m约等于样本量除以3左右,需要不断调试。
绘制3个月的校准曲线:
par(mar=c(5,5,2,1))
plot(cal.cox,
lwd=2,
lty=1,
errbar.col="blue",
xlim=c(0,1),ylim=c(0,1),
xaxs = "i",
yaxs = "i",
xlab="Nomogram-Predicted Probabilityof 3-month OS",
ylab="Actual 3-month OS (proportion)",
col="red",
subtitles=F,
cex=1.5,
cex.axis=1.5,
cex.lab=1.5)
lines(cal.cox[,c("mean.predicted","KM")],type="b",lwd=2,col="red")
abline(0,1,lty=3,lwd=2,col="black")errbar.col设置误差线颜色。

图中横坐标为3个月生存情况的预测值,纵坐标为3个月生存情况的实际值。黑色的虚线为参考线,红色线表示模型拟合的预测值与实际值的一致性情况,竖线为标准误差,红色线越接近参考线,表示预测值与实际值的一致性越高。
6个月的结果如下:将模型time.inc=6,绘图u=6,x,y轴的名称改为6个月
fit2.cox <- cph(formula = form.cox,data=pancer,x=TRUE,y=TRUE,surv=TRUE,time.inc =6 )
cal2.cox <- calibrate(fit2.cox,
cmethod='KM',
method='boot',
u=6,
m=25,
B=1000)
par(mar=c(5,5,2,1))
plot(cal2.cox,
lwd=2,
lty=1,
errbar.col="blue",
xlim=c(0,1),ylim=c(0,1),
xaxs = "i",
yaxs = "i",
xlab="Nomogram-Predicted Probabilityof 6-month OS",
ylab="Actual 6-month OS (proportion)",
col="red",
subtitles=F,
cex=1.5,
cex.axis=1.5,
cex.lab=1.5)
lines(cal2.cox[,c("mean.predicted","KM")],type="b",lwd=2,col="red")
abline(0,1,lty=3,lwd=2,col="black")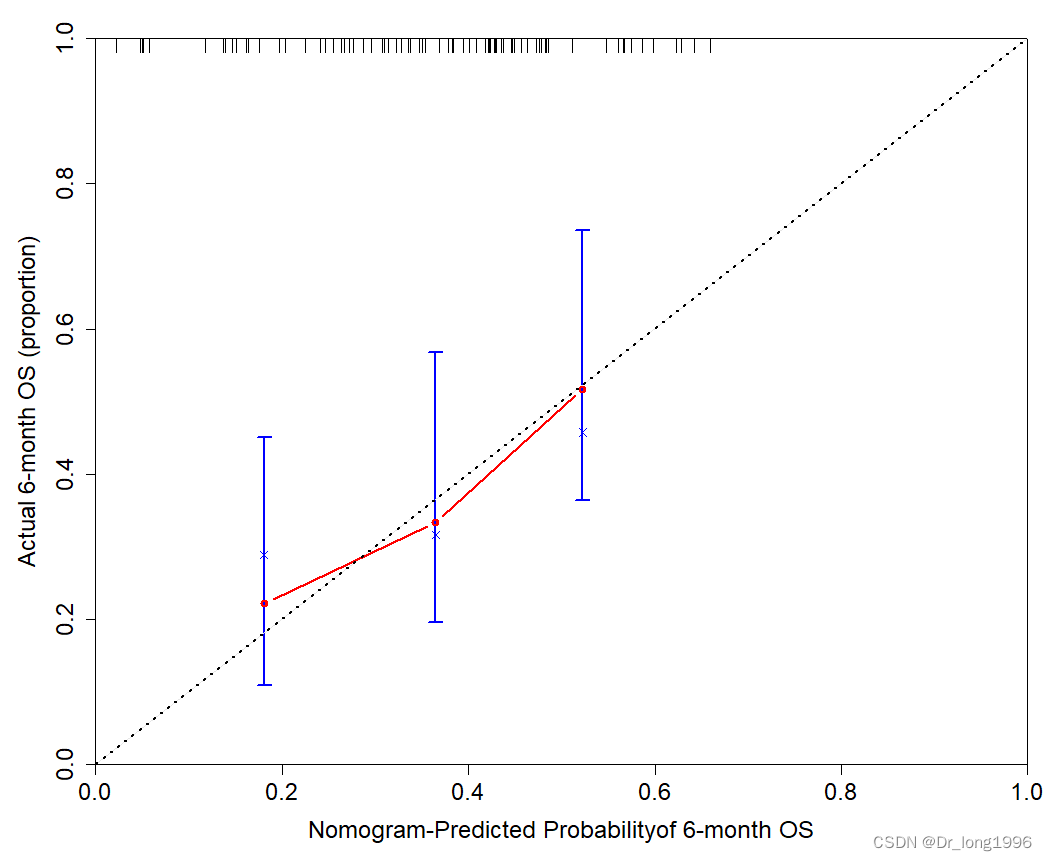
survival包coxph()函数拟合的生存模型
建立生存模型
library(riskRegression)
library(survival)
form.cox<-as.formula(Surv(time,censor==1)~age+Gender+trt+bui+ch+p+stage)
fit3.cox=coxph(formula = form.cox,data=pancer,x=TRUE)calibration校准曲线模型
xs=Score(object=list("Cox Model"=fit3.cox),
times = c(3,6),
formula=Surv(time,censor)~1,
plots=c("calibration","ROC"),
metrics = c("auc", "brier"),
B=1000,M=50,
data=pancer)绘制校准曲线
3个月时:
plotCalibration(x=xs,
times=3,
xlab="Predictd Risk",
ylab = "Observed Frequency",
col="black",
brier.in.legend=FALSE,
auc.in.legend=FALSE)
6个月:
plotCalibration(x=xs,
times=6,
xlab="Predictd Risk",
ylab = "Observed Frequency",
col="black",
brier.in.legend=FALSE,
auc.in.legend=FALSE)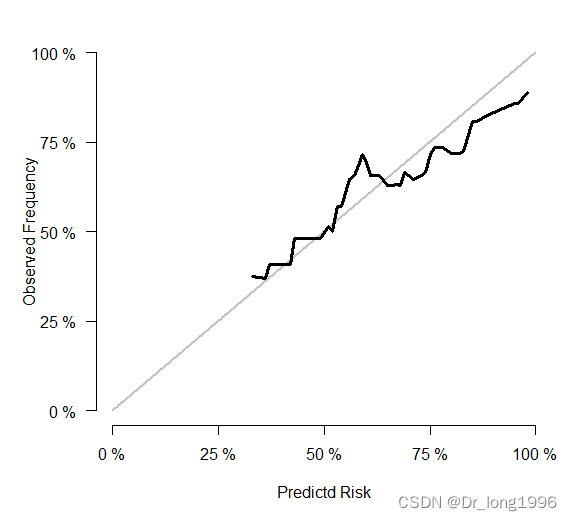
横坐标是3个月和6个月的死亡情况,而非生存情况,区别于calibration()函数的结果。
对结局进行分段处理:
#3个月
plotCalibration(x=xs,
times = 3,
ylab = "Risk or Frequency",
bars=TRUE,
q=7,
show.frequencies=TRUE)
#6个月
plotCalibration(x=xs,
times = 6,
ylab = "Risk or Frequency",
bars=TRUE,
q=7,
show.frequencies=TRUE)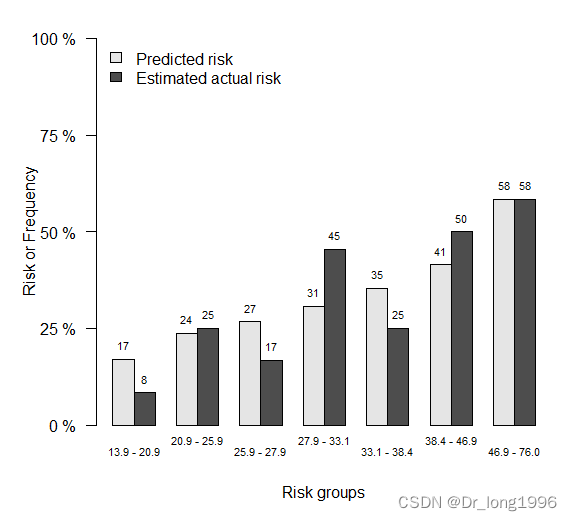
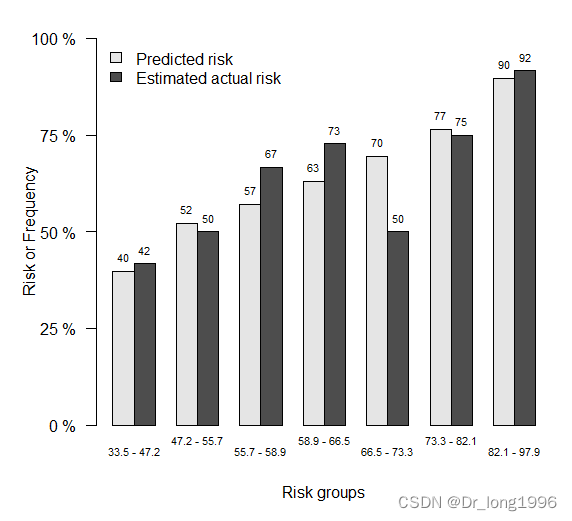
单模型多时点校准曲线
将刚才的3个月和6个月绘制在一张图中,只能使用rms包中的cph()函数创建生存模型:
先构建生存模型和calibration模型:
form.cox<-as.formula(Surv(time,censor==1)~age+Gender+trt+bui+ch+p+stage)
library(rms)
#3月份
fit.cox <- cph(formula = form.cox,data=pancer,x=TRUE,y=TRUE,surv=TRUE,time.inc = 3)
cal.cox <- calibrate(fit.cox,
cmethod='KM',
method='boot',
u=3,
m=40,
B=1000)
#6月份
fit2.cox <- cph(formula = form.cox,data=pancer,x=TRUE,y=TRUE,surv=TRUE,time.inc =6 )
cal2.cox <- calibrate(fit2.cox,
cmethod='KM',
method='boot',
u=6,
m=25,
B=1000)定义一个plot_error函数用于绘制误差线
plot_error <- function(x, y, sd, len = 1, col = "black") {
len <- len * 0.05
arrows(x0 = x, y0 = y, x1 = x, y1 = y - sd*y, col = col, angle = 90, length = len)
arrows(x0 = x, y0 = y, x1 = x, y1 = y + sd*y, col = col, angle = 90, length = len)
}绘制空白图
par(mar=c(5,5,2,1))
#创建一个空白的图,type=“n“表示不绘制任何点或曲线。
plot(x=1,type = "n",
xlim = c(0,1),
ylim = c(0,1),
xaxs = "i",
yaxs = "i",
xlab = "Predicted Probability",
ylab="Observed Probability",
legend =FALSE,
subtitles = FALSE,
cex=1.5,
cex.axis=1.5,
cex.lab=1.5)
x1<-cal.cox[,c("mean.predicted")] #x1表示模型中的预测值
y1<-cal.cox[,c("KM")] #y1为km
sd1<-cal.cox[,c("std.err")] #模型中的标准误传递给sd1
绘制calibration曲线
points(x1,y1,
type = "o",
pch = 2,
col = "seagreen",
lty = 1,
lwd = 2)type=“o"表示实线通过所有点。pch表示散点的形状,lty设置线段类型。

plot_error(x1,y1,
sd=sd1,
col="seagreen")
绘制6个月的曲线
x2<-cal2.cox[,c("mean.predicted")]
y2<-cal2.cox[,c("KM")]
sd2<-cal2.cox[,c("std.err")]
points(x2,y2,
type = "o",
pch = 1,
col = "red",
lty = 1,
lwd = 2)
plot_error(x2,y2,
sd=sd2,
col="red")
abline(0,1,lty=3,lwd=2,col="black")
legend(0.01,0.95,
legend=c("3-Month OS","6-Month OS"),
lty = c(1,1),
lwd = c(2,2),
pch = c(1,2),
col = c("seagreen","red"),
horiz = TRUE,
bty="n",
cex=1.5)
多模型同时点校准曲线
cph()函数
构建模型
form.cox<-as.formula(Surv(time,censor==1)~age+Gender+trt+bui+ch+p+stage)
form.reduce<-as.formula(Surv(time,censor==1)~age+trt+bui+ch+p+stage)
library(rms)
fit.cox <- cph(formula = form.cox,data=pancer,x=TRUE,y=TRUE,surv=TRUE,time.inc = 3)
fit.reduce<- cph(formula = form.reduce,x=T,y=T,data=pancer,surv=T,time.inc = 3)
cal.cox <- calibrate(fit.cox,
cmethod='KM',
method='boot',
u=3,
m=40,
B=1000)
cal.reduce <- calibrate(fit.reduce,
cmethod='KM',
method='boot',
u=3,
m=40,
B=1000)
方法类似于单模型多时间点的校准曲线:分别提取出模型中的预测值,实际值以及标准误,然后使用
plot(x=1,type = "n",
xlim = c(0,1),
ylim = c(0,1),
xaxs = "i",
yaxs = "i",
xlab = "Predicted Probability",
ylab="Observed Probability",
legend =FALSE,
subtitles = FALSE,
cex=1.5,
cex.axis=1.5,
cex.lab=1.5)
x1<-cal.cox[,c("mean.predicted")]
y1<-cal.cox[,c("KM")]
sd1<-cal.cox[,c("std.err")]
points(x1,y1,
type = "o",
pch = 2,
col = "seagreen",
lty = 1,
lwd = 2)
plot_error(x1,y1,
sd=sd1,
col="seagreen")
x2<-cal.reduce[,c("mean.predicted")]
y2<-cal.reduce[,c("KM")]
sd2<-cal.reduce[,c("std.err")]
points(x2,y2,
type = "o",
pch = 1,
col = "red",
lty = 1,
lwd = 2)
plot_error(x2,y2,
sd=sd2,
col="red")
abline(0,1,lty=3,lwd=2,col="black")
legend(0.01,0.95,
c("cal.cox:3-Month OS","cal.reduce:3-Month OS"),
lty = c(1,1),
lwd = c(2,2),
pch = c(1,2),
col = c("seagreen","red"),
horiz = FALSE,
bty="n",
cex=1.5)
coxph()函数
创建模型
form.cox<-as.formula(Surv(time,censor==1)~age+Gender+trt+bui+ch+p+stage)
form.reduce<-as.formula(Surv(time,censor==1)~age+trt+bui+ch+p+stage)
fs1=coxph(formula = form.cox,data=pancer,x=TRUE)
fs2=coxph(formula = form.reduce,data=pancer,x=TRUE)
xs2=Score(object=list("Model All"=fs1,"Model Reduce"=fs2),
formula=Surv(time,censor)~1,
times = c(3,6),
plots=c("calibration","ROC"),
metrics = c("auc", "brier"),
B=1000,M=50,
data=pancer)xs2已经包括了两个模型,所以在绘图中不需要特别强调两个模型,只需要输入xs2
plotCalibration(x=xs2,
times=3,
xlab="Predictd Risk",
ylab = "Observed Frequency",
brier.in.legend=FALSE,
auc.in.legend=FALSE)
3个月的calibration校准曲线,如果要计算6个月,只需要将times设置为6,如下:
plotCalibration(x=xs2,
times=6,
xlab="Predictd Risk",
ylab = "Observed Frequency",
brier.in.legend=FALSE,
auc.in.legend=FALSE)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









