










【推荐系统与图神经网络相结合】图表示学习在协同过滤推荐系统上的应用
文章目录
1. 前言
本文将图表示学习在协同过滤推荐系统的进展,分为四个方法依次进行介绍。它们分别是:NGCF[1]、LightGCN[2]、UltraGCN[3]和SVD-GCN[4]。值得注意的是,它们可以看作是对NGCF不同版本的改进。
2. NGCF
一般来说,在可学习的协同过滤(CF)模型中有两个关键组件:1)嵌入,它将用户和物品转换为向量化表示,2)交互建模,它基于嵌入重建历史交互。例如,矩阵分解(MF)直接将用户/物品ID嵌入为向量,并利用内积去建模用户-物品交互;协同深度学习通过整合从丰富边信息中学习到的深度表示来扩展MF嵌入函数;神经协同滤波模型用非线性神经网络代替内积的MF交互函数;基于翻译的CF模型采用欧氏距离度量作为交互函数等。
尽管上述方法效果不错,但这些方法并不足以产生令人满意的CF嵌入。关键原因是嵌入函数缺乏对关键协作信号的显式编码,这可能隐藏在用户-物品交互中,以揭示用户(或物品)之间的行为相似性。更具体地说,大多数现有的方法只使用描述性特征(如ID和属性)来构建嵌入函数,而不考虑用户-物品交互,这仅用于定义模型训练的目标函数。正因此,当嵌入不足以捕获CF时,该方法必须依赖于交互函数来弥补次优的嵌入表示不足。
虽然将用户-物品交互集成到嵌入函数中很有用,但做好并不容易。特别是,在实际应用中,交互的规模很容易达到数百万次,甚至更大,这使得提取所需的协作信号变得困难。这正是NGCF想解决的问题:去显式地建模用户和物品之间的高阶连接性来改善嵌入的表示,其模型架构如图所示。
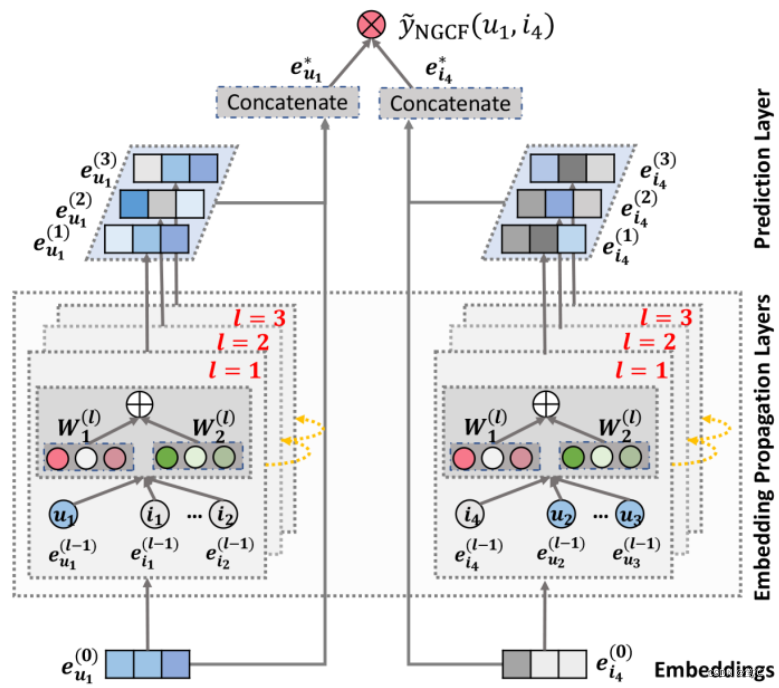
2.1 方法
通过堆叠
l
l
l个嵌入传播层,用户(物品)能够接收从其
l
l
l阶邻居传播的消息。如上图所示,在第1步中,用户
u
u
u或者物品
i
i
i的表示被递归地表示为:
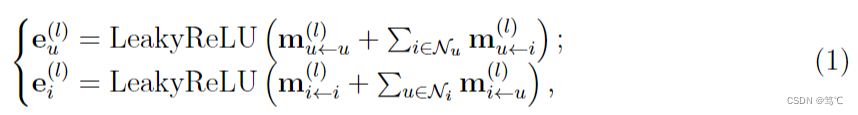
其中所传播的消息定义如下,
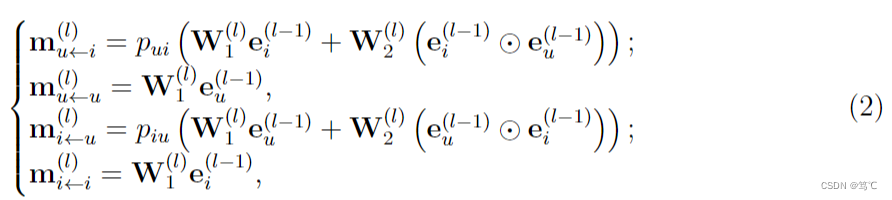
其中使用系数
p
i
j
p_{i j}
pij来控制边缘上每次传播的衰减因子,定义如下,

这里,
N
i
\mathcal{N}_{i}
Ni指代节点
i
i
i的邻居集合。
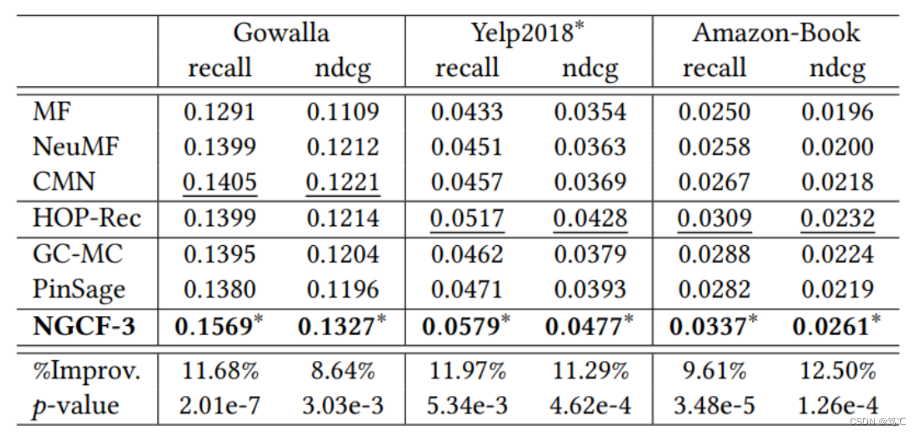
2.2 实验
3. LightGCN
尽管NGCF已经取得了很有效的结果,但LightGCN认为NGCF的设计相当沉重和繁琐,其中许多操作都是毫无理由地从GCN中直接继承来的。因此,它们对CF任务并不一定有用。具体来说,GCN最初提出用于属性图上的节点分类,其中每个节点都有丰富的属性作为输入特征;而在CF的用户-物品交互图中,每个节点(用户或物品)只由一个热ID描述,该ID除了作为标识符外,没有具体的语义。在这种情况下,将ID嵌入作为输入,执行多层非线性特征转换,这是现代神经网络成功的关键——不会带来任何好处,但消极地增加了模型训练的难度。
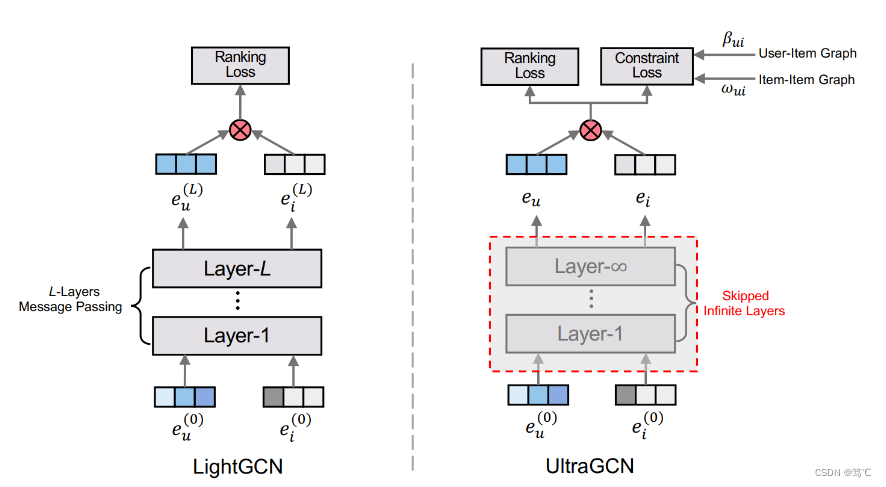
为了验证以上的想法,LightGCN对NGCF进行了广泛的消融研究。通过严格的控制实验(在相同的数据分割和评估协议上),得出结论,从GCN中继承来的两个操作,特征转换和非线性激活,对NGCF的有效性没有贡献。更令人惊讶的是,移除它们会显著提高准确性。这反映了在图神经网络中添加对目标任务无用的操作的问题,这不仅没有带来任何好处,而且降低了模型的有效性。受这些发现的启发,LightGCN模型出现,其中包括GCN中最重要的组件,邻域聚合,用于协同过滤。具体来说,在将每个用户(物品)与一个ID嵌入关联起来之后,再将嵌入传播到用户-物品交互图上,以细化它们。然后,将在不同传播层上学习到的嵌入与加权和相结合,得到用于预测的最终嵌入。整个模型简单而优雅,不仅易于训练,而且具有更好的性能,LightGCN的模型架构如下图所示。
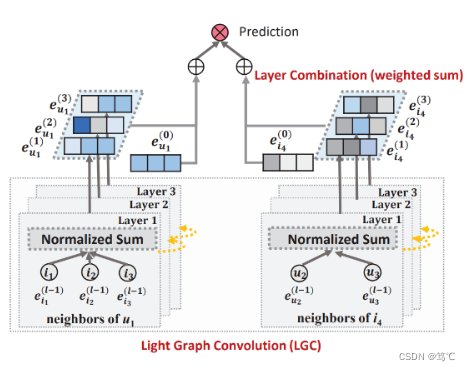
3.1 方法
因此,在LightGCN中,采用的是简单加权和聚合器,而不再使用特征变换和非线性激活。LightGCN中的图卷积运算定义为:
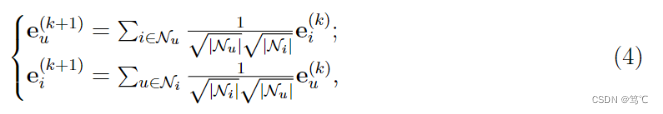
其中对称归一化项
1
∣
N
u
∣
∣
N
i
∣
\frac{1}{\sqrt{\left|\mathcal{N}_{u}\right|} \sqrt{\left|\mathcal{N}_{i}\right|}}
∣Nu∣∣Ni∣1遵循标准GCN的设计,它避免了嵌入规模随图卷积运算的增加;这里也可以应用其他选择,如L1范数,而经验发现这种对称归一化具有良好的性能。最终表示通过将每一层输出加权整合来获得,
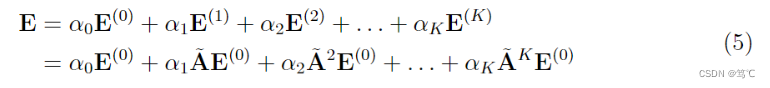
其中,
A
~
=
D
−
1
2
A
D
−
1
2
\tilde{\mathbf{A}}=\mathbf{D}^{-\frac{1}{2}} \mathbf{A D}^{-\frac{1}{2}}
A~=D−21AD−21 是对称归一化矩阵。
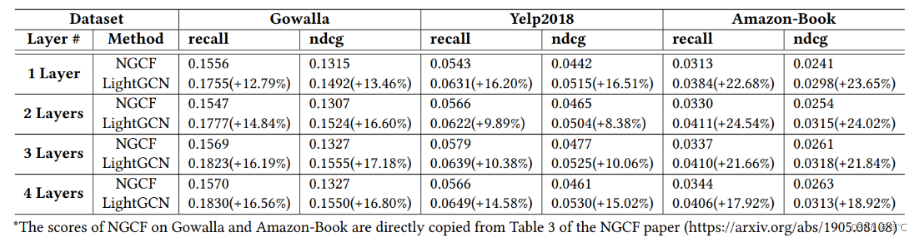
3.2 实验
4. UltraGCN
GCN的核心在于其聚合邻域信息的信息传递机制。然而,消息传递在训练过程中很大程度上减慢了GCN的收敛速度,特别是对于大规模的推荐系统,这阻碍了它们的广泛采用。LightGCN尝试通过移除\textbf{特征转换和非线性激活}两个部件来简化协同过滤。LightGCN以两个嵌入的点积作为最终的logit来捕获用户 u u u对物品 i i i的偏好。以第 l l l层为例,可以得到:
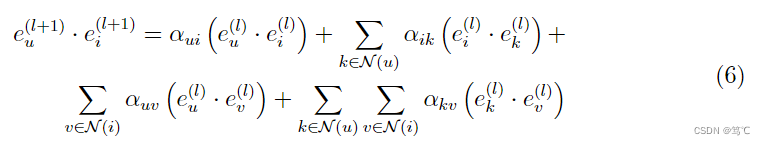
其中,
α
u
i
,
α
i
k
,
α
u
v
,
α
k
,
v
\alpha_{u i}, \alpha_{i k}, \alpha_{u v}, \alpha_{k, v}
αui,αik,αuv,αk,v可推导如下:
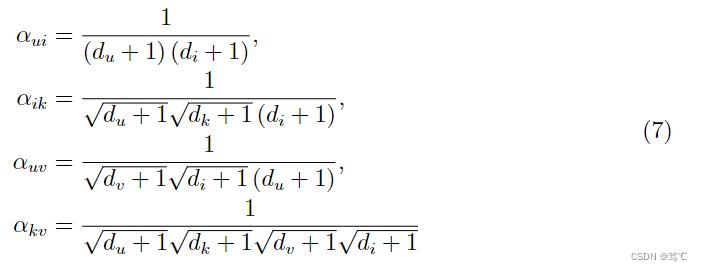
因此,可以观察到,当训练带有消息传递层的基于GCN的模型时,可以捕获到多种不同类型的协作信号,包括用户-物品关系(u-i和k-v)、物品-物品关系(i-k)、用户-用户关系(u-v)。这也揭示了为什么基于GCN的模型对CF是有效的。
然而,UltraGCN的作者发现分配给各种类型的关系的边权值并不适用于CF任务。基于实证分析,确定了基于GCN的模型中消息传递层的三个关键限制:
- 限制1:权重用于建模用户-物品、物品-物品和用户-用户关系分配不合理。
- 限制2:递归地传递的消息会将不同类型的关系组合到建模中。虽然这样的协作信号应该是有益的,但上述的消息传递公式未能捕捉到它们不同的重要性。同时,如式(\ref{eq6})中所述,堆叠多层信息传递可能会引入错误信息、有噪声或模糊的关系,这在很大程度上影响训练的效率和有效性。需要灵活地调整各种关系的相对重要性。
- 限制3:堆叠更多的消息传递层应该会捕获更高阶的协作信号,但实际上,LightGCN的性能在第2层或第3层时便开始下降,有部分原因归因于消息传递的过度平滑问题。由于图卷积是拉普拉斯平滑的一种特殊形式,执行过多的消息传递层将使具有相同程度的节点往往具有完全相同的嵌入。根据[5]中的定理1,可以推导出消息传递的无限幂,其极限如下:
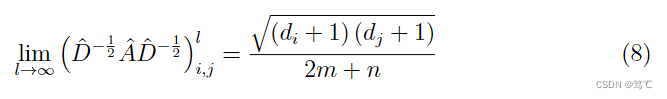
其中, n n n和 m m m分别为图中节点和边的总数。
4.1 方法
基于此,UltraGCN进一步提出了一个更加简化的GCNs范式,它跳过了无限层的消息传递,以获得有效的推荐。UltraGCN不是显式的消息传递,而是通过约束损失直接近似无限层图卷积的极限。同时,UltraGCN允许更适当的边缘权值分配和灵活地调整不同类型的关系之间的相对重要性。这最终产生了一个简单而有效的UltraGCN模型,它易于实现和高效的训练,其模型架构如上图所示。
-
一方面,为了近似无限层图卷积的极限并平衡化权重分配,经过一些简化,可以推导出以下收敛状态,
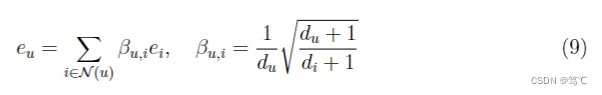
换句话说,如果每个节点都满足这个公式,则达到消息传递的收敛状态。
由于目标是为了直接近似于这种收敛状态,而不是执行显式的消息传递。为此,一个简单的方法是最小化方程(9)两边的差异。在UltraGCN中,是将嵌入归一化到单位向量,然后最大化这两项的点积,
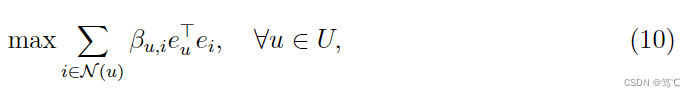
这相当于使 e u e_{u} eu和 e i e_{i} ei间的余弦相似度最大化。为了便于优化,进一步结合sigmod激活函数和负对数似然,并使用Word2Vec中的负采样策略(一种简单且有效的方法来解决过度平滑问题)。最终可以得到以下约束损失:
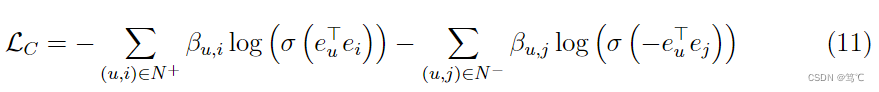
其中, N + N^{+} N+和 N − N^{-} N−表示正样本对(用户 u u u和物品 i i i有交互)和随机抽样的负样本对(用户 u u u和物品 i i i无交互)。约束损失 L C \mathcal{L}_{C} LC使UltraGCN能够直接近似于无限层消息传递的极限,以捕获用户-物品交互二部图中的任意高阶协同信号,同时通过负采样有效地避免了过平滑问题。 -
另一方面,UltraGCN还引入了物品-物品图上的学习,并引入自监督信号来提升性能,
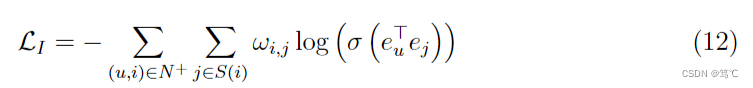
其中, S ( i ) S(i) S(i)表示与物品 i i i最相似的k个物品的集合。
协同过滤推荐的主要目标损失是,
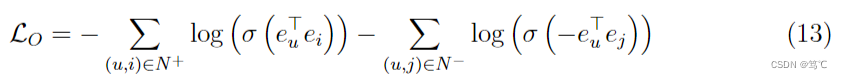
其中, N + N^{+} N+和 N − N^{-} N−表示正样本对(用户 u u u和物品 i i i有交互)和随机抽样的负样本对(用户 u u u和物品 i i i无交互)。
因此,UltraGCN的总目标损失函数是三个目标损失的整合,

其中, λ \lambda λ和 γ \gamma γ别是调整用户-物品关系和物品-物品关系的相对重要性的超参数。
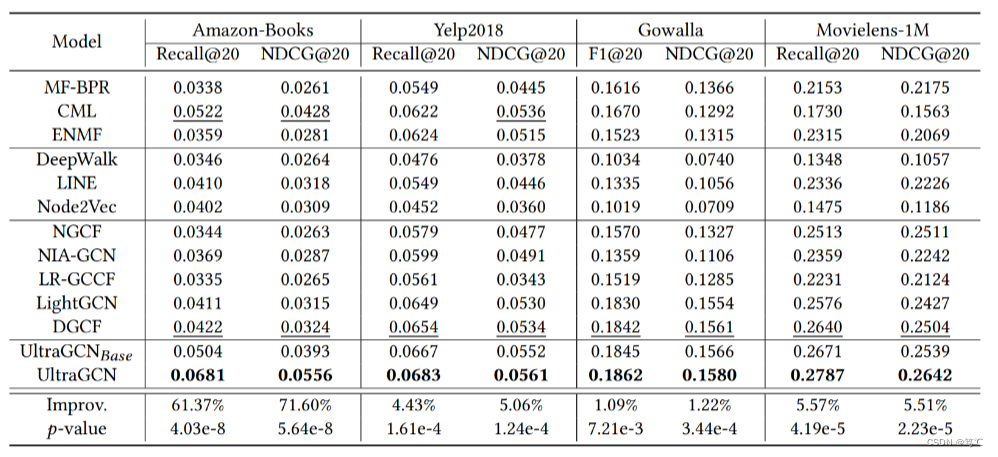
4.2 实验
5. SVD-GCN
随着图卷积网络(GCNs)的巨大成功,它们已被广泛地应用于推荐系统中,并显示出了良好的性能。然而,大多数基于GCN的方法严格坚持通用的GCN学习范式,并存在两个限制:(1)由于计算成本高和训练收敛速度慢,可伸缩性有限;(2)臭名昭著的过平滑问题降低了堆叠图卷积层的性能。SVD-GCN认为上述限制是由于缺乏对基于GCN的方法的深刻理解。为此,SVD-GCN首先研究了是什么设计使GCN对推荐有效。通过简化LightGCN,展示了基于GCN的方法和低秩方法,如奇异值分解(SVD)和矩阵分解(MF)之间的密切联系,其中堆叠图卷积层是通过强调(抑制)具有较大(较小)奇异值的分量来学习低秩表示。基于这一观察结果,SVD-GCN将一个灵活的截断的SVD代替了基于GCN的方法的核心设计,并提出了一个简化的GCN学习范式,称为SVD-GCN,它只利用k-个最大的奇异向量进行推荐。为了缓解过度平滑的问题,SVD-GCN还提出了一个重整化的技巧来调整奇异值间隙,从而获得了显著的性能提升。
5.1 方法
- 1)通过一系列的理论证明,说明了GCN和SVD之间的联系。
首先,LightGCN中用户和物品最终的表示为,
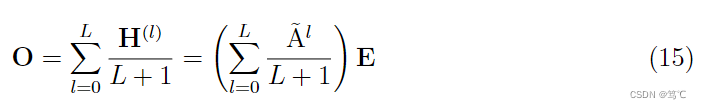
即最后用户和物品的表示是通过聚合每层输出的表示来得到(mean pooling)。
而 A ~ l \tilde{\mathrm{A}}^{l} A~l又可以表示为,
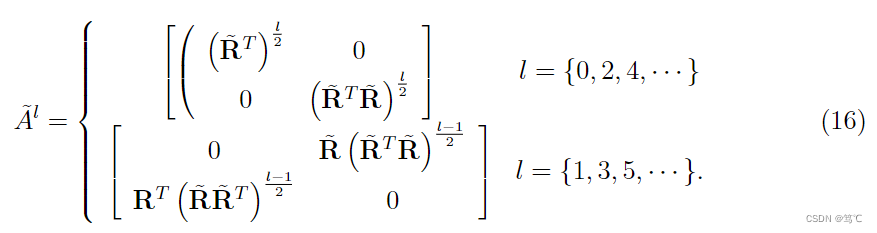
其中 R ~ = D U − 1 2 R D I − 1 2 \tilde{\mathbf{R}} =\mathbf{D}_{U}^{-\frac{1}{2}} \mathbf{R D}_{I}^{-\frac{1}{2}} R~=DU−21RDI−21,于是可以替换式(15)为,
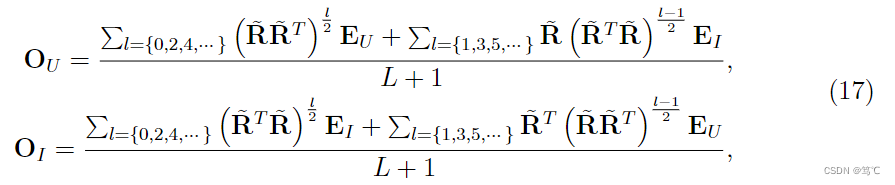
然后,对 R ~ \tilde{\mathbf{R}} R~进行SVD分解,得到 R ~ = P d i a g ( σ k ) Q \tilde{\mathbf{R}} = \mathbf{P} d i a g\left(\sigma_{k}\right) \mathbf{Q} R~=Pdiag(σk)Q。进而可以得到以下推导,
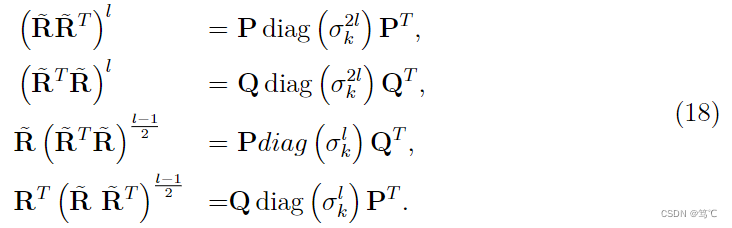
进而,又可以重写式(17)为,
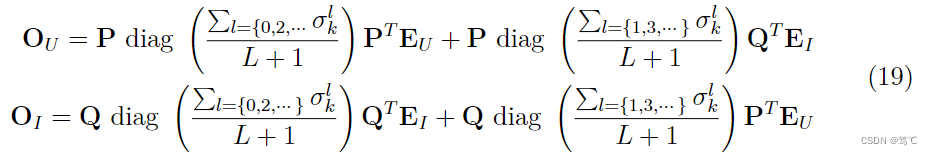
最后,可以得到用户 u u u的最终表示,同理物品 i i i的表示也可以这样获得,以SVD分解的形式展示,
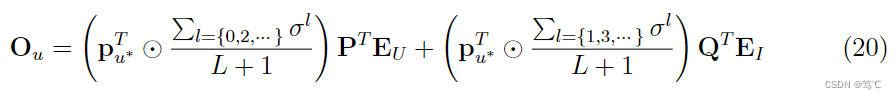
其中, σ \sigma σ 是一个包含所有奇异值的向量, p u ∗ T \mathbf{p}_{u^{*}}^{T} pu∗T是第 u u u行向量, ⊙ \odot ⊙表示向量的点积。可以看到, P T E U \mathbf{P}^{T} \mathbf{E}_{U} PTEU和 Q T E I \mathbf{Q}^{T} \mathbf{E}_{I} QTEI是针对不同用户或物品的通用部分(也就是这是公共的,不具有区分功能),而使用户或者物品具有不同表示的原因在于括号中的部分。
因此,通过以上的分析,我们可以发现GCN和SVD之间的联系,即可以通过SVD来表示GCN。 - 2)通过以上的理论分析和实验证明,作者最后发现上述式(\ref{eq20})的
P
T
E
U
\mathbf{P}^{T} \mathbf{E}_{U}
PTEU和
Q
T
E
I
\mathbf{Q}^{T} \mathbf{E}_{I}
QTEI 是冗余的。因此作者进行了简化和改进,并通过引入一个可学习的特征转化矩阵
W
\mathbf{W}
W,如下:
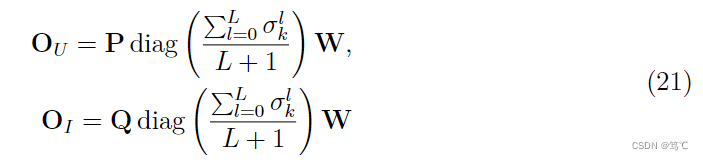
- 3)另外,作者还进行了其他的改进(比如重整化的技巧来调整奇异值间隙等),另外提出了五种变体,

5.2 实验
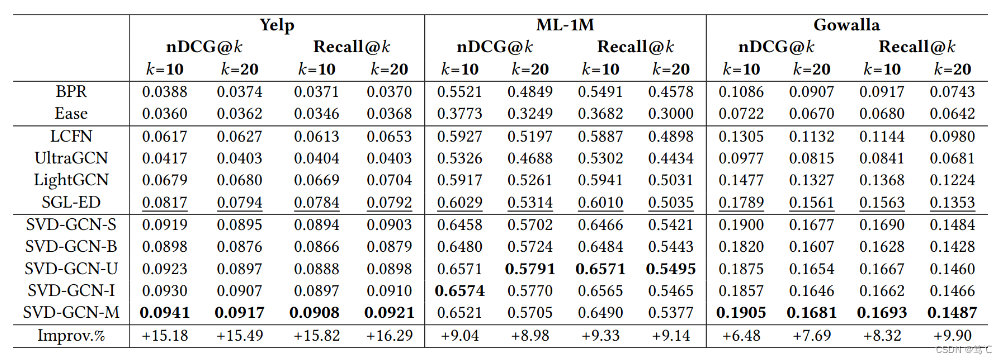
6. 总结
推荐系统作为人工智能最重要的实际应用之一,几乎存在于我们日常生活的每个角落。协同过滤推荐(Collaborative Filtering recommendation)作为电子商务推荐系统的一种主要算法,是在信息过滤和信息系统中正迅速成为一项很受欢迎的技术。近年来,随着图神经网络的发展,在推荐系统中利用图表示学习技术越来越引起了学术界和工业界的兴趣。图表示学习的引入也大大地加速了协同过滤推荐的发展,提升了推荐系统的性能。另外还有一些基于自监督去学习推荐图上的信息来进一步提高协同过滤推荐的性能[6, 7]。
7. 参考文献
- [1] X. Wang, X. He, M. Wang, F. Feng, and T. Chua, “Neural graph collaborative filtering,” in Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2019, Paris, France, July 21-25, 2019, B. Piwowarski, M. Chevalier, É. Gaussier, Y. Maarek, J. Nie, and F. Scholer, Eds. ACM, 2019, pp. 165–174. [Online]. Available: https://doi.org/10.1145/3331184.3331267
- [2] X. He, K. Deng, X. Wang, Y. Li, Y. Zhang, and M. Wang, “Lightgcn:
Simplifying and powering graph convolution network for recommendation,” in Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, J. X. Huang, Y. Chang, X. Cheng, J. Kamps, V. Murdock,
J. Wen, and Y. Liu, Eds. ACM, 2020, pp. 639–648. [Online]. Available: https://doi.org/10.1145/3397271.3401063 - [3] K. Mao, J. Zhu, X. Xiao, B. Lu, Z. Wang, and X. He, “Ultragcn: Ultra simplification of graph convolutional networks for recommendation,” in CIKM ’21: The 30th ACM International Conference on Information and Knowledge Management, Virtual Event, Queensland, Australia, November 1 - 5, 2021, G. Demartini, G. Zuccon, J. S. 11 Culpepper, Z. Huang, and H. Tong, Eds. ACM, 2021, pp. 1253–1262. [Online]. Available: https://doi.org/10.1145/3459637.3482291
- [4] S. Peng, K. Sugiyama, and T. Mine, “SVD-GCN: A simplified graph convolution paradigm for recommendation,” in Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, October 17-21, 2022, M. A. Hasan and L. Xiong, Eds. ACM, 2022, pp. 1625–1634. [Online]. Available: https://doi.org/10.1145/3511808.3557462
- [5] M. Chen, Z. Wei, Z. Huang, B. Ding, and Y. Li, “Simple and deep graph convolutional networks,” in Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, ser. Proceedings of Machine Learning Research, vol. 119. PMLR, 2020, pp. 1725–1735. [Online]. Available: http://proceedings.mlr.press/v119/chen20v.html
- [6] J. Wu, X. Wang, F. Feng, X. He, L. Chen, J. Lian, and X. Xie, “Self-supervised graph learning for recommendation,” in SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, F. Diaz, C. Shah, T. Suel, P. Castells, R. Jones, and T. Sakai, Eds. ACM, 2021, pp. 726–735. [Online]. Available: https://doi.org/10.1145/3404835.3462862
- [7] S. Liu, I. Ounis, and C. Macdonald, “An mlp-based algorithm for efficient contrastive graph recommendations,” in SIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15, 2022, E. Amigó, P. Castells, J. Gonzalo, B. Carterette, J. S. Culpepper, and G. Kazai, Eds. ACM, 2022, pp. 2431–2436. [Online]. Available: https://doi.org/10.1145/3477495.3531874

















 4139
4139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











