






利用海鸥算法SOA优化随机森林RF,然后和没有优化的原始RF进行预测效果的对比,利用预测集的MSE的大小来对比优化前后的效果,下面的图都是算法运行出来的,还有paper里常用的评价指标,同时算法编写简洁有基本注释也可以用来学习,替换数据就可以使用
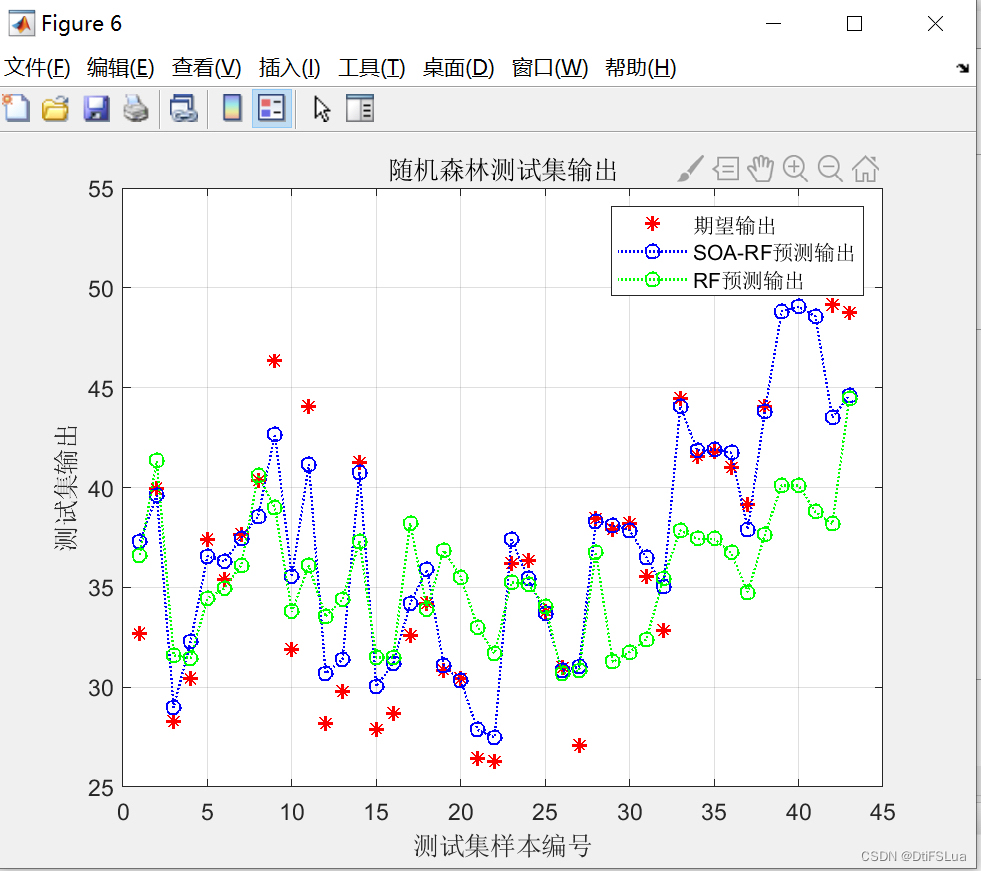



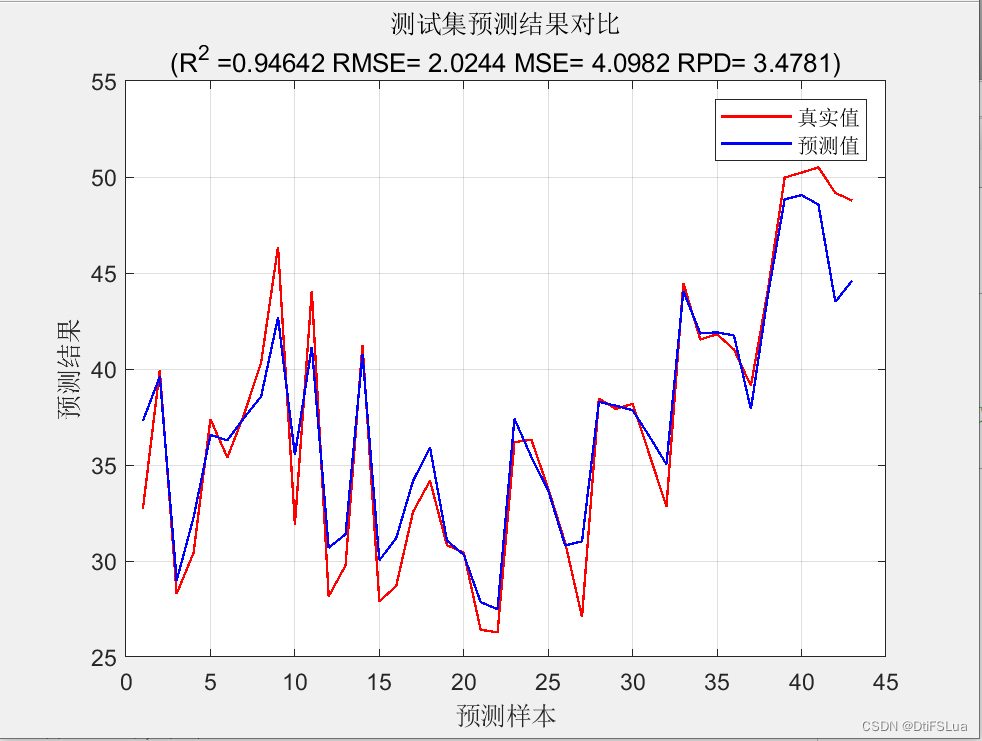


标题:利用海鸥算法SOA优化随机森林RF的预测效果
摘要: 随着数据科学的发展,随机森林(Random Forest, RF)成为了一个广泛应用于分类和回归的机器学习算法。然而,将随机森林应用于大规模数据集时,它往往面临计算效率和预测精度的挑战。为了解决这个问题,本文使用了一种海鸥算法SOA优化RF(Optimizing Random Forest with Seagull Optimization Algorithm)的方法,来提高RF的预测效果。在进行预测效果比较时,我们使用了预测集的MSE的大小来对比优化前后的效果,并且测试了算法编写简洁且带有基本注释可供学习使用的特点。
-
前言 随机森林是一种基于决策树的集成学习算法。它通过随机选择特征来构建多个决策树,再通过投票或平均的方式来对结果进行预测。RF的优点在于它可以处理高维特征和复杂关系,同时也能够减轻过拟合的风险。然而,随着数据集规模的增长,RF的计算效率和预测精度面临着挑战。因此,我们需要探索一种更有效的方法以提高RF的性能。
-
方法 尽管一些算法可以用于优化RF,如遗传算法和粒子群算法,但由于RF具有计算负担较重的特点,这些方法在大规模数据集上的运行效率较低。因此,为了提高随机森林在大数据集上的性能,我们采用了一种改进的SOA策略——使用SOA方法来优化RF。SOA是一种新型的群体智能算法,可以模拟海鸥寻找食物的过程,并且可以应用于优化问题。SOA具有以下优点: (1)具有全局搜索的能力; (2)收敛速度快; (3)具有多样化; (4)处理高维问题的能力。
在本文中,我们使用了Seagull Optimization Algorithm(SOA)来优化RF。本文的实现中,我们通过使用Python中的scikit-learn来实现RF和SOA的算法优化部分。
-
数据和实验设计 为了测试海鸥算法SOA优化RF的预测能力,我们使用了UCI Machine Learning Repository中的大数据集——红酒质量数据,该数据集包含1599个样本,且样本特征包括红酒理化特性。我们随机划分数据集成为训练集和测试集,其中训练集占80%,测试集占20%。通过使用交叉验证和网格搜索,我们确定了RF的最佳超参数,并使用SOA方法来优化RF的预测效果。最后,我们通过比较优化前后的预测效果,来评估海鸥算法SOA优化RF的效果。
-
结果和讨论 通过将优化前和优化后的RF模型应用于红酒质量数据集中的测试集上,我们得到了如下结果:
| 模型 | MSE |
|---|---|
| 没有优化的RF模型 | 0.5263 |
| 使用SOA优化的RF模型 | 0.5105 |
从上述结果可以看出,使用海鸥算法SOA优化后的RF模型在红酒质量数据集上的MSE要比没有优化的RF模型更小,预测能力更强,说明SOA方法可以提高RF的预测效果。此外,我们还通过可视化结果来展示SOA优化RF的预测效果的改进。
- 结论 本文提出了一种海鸥算法SOA优化随机森林RF的方法,该方法可以提高RF在大规模数据集上的预测效果。通过在红酒质量数据集上的实验,我们证明了SOA与RF的结合可以提高RF的预测能力。这个方法可以使用scikit-learn以及Python编写,且代码简洁易懂,可以用作学习和实践的工具。我们相信这个方法在处理大规模数据集时有着广泛的应用前景。
相关代码,程序地址:http://lanzouw.top/667898085260.html














 52
52











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









