






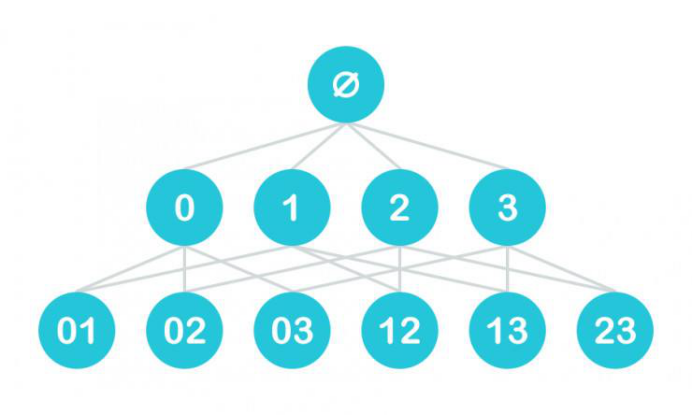
数据挖掘最早使用的方法是关联分析,主要应用于零售业。其中最有名的是售货 篮分析,帮助售货商制定销售策略。数据挖掘是从海量的数据里寻找有价值的信息和数据。数据挖掘中常用的算法有:关联规则分析法(解决事件之间的关联问题)、决策树分类法(对数据 和信息进行归纳和分类)、遗传算法(基于生物进化论及分子遗传学理论提出 的)、神经网络算法(模拟人的神经元功能)等。 随着信息时代的到来,数据挖掘在金融、医疗、通信等方面得到了广泛的应用。
关联规则挖掘是一种基于规则的机器学习算法,该算法可以在大数据库中发现感兴趣的关系。它的目的是利用一些度量指标来分辨数据库中存在的强规则。也即是说关联规则挖掘是用于知识发现,而非预测,所以是属于无监督的机器学习方法。
关联规则挖掘可以让我们从数据集中发现项与项(item与item)之间的关系,它在我们的生活中有很多应用场景,“购物篮分析”就是一个常见的场景,这个场景可以从消费者交易记录中发掘商品与商品之间的关联关系,进而通过商品捆绑销售或者相关推荐的方式带来更多的销售量。
在我查询资料的过程中,大多数文章全都在讲关联规则概念、基本原理、算法、指标等等,说直白点都是从学术文章抄出来的,没有真正的说明关联规则在现实场景中的应用的意义和作用,也没有介绍行业中能够挖掘关联分析的软件。
l 应用场景及案例
(1) 购物篮分析
著名的“啤酒尿布”案例,通过分析历史用户的支付订单记录,挖掘出比如中年男人会同时购买啤酒和尿布两种商品,后续可以在商品陈列、打折促销组合、交叉营销发送优惠券等场景中应用。

(2) 穿衣搭配推荐
穿衣搭配是服饰鞋包导购中非常重要的课题,基于搭配专家和达人生成的搭配组合数据,百万级别的商品的文本和图像数据,以及用户的行为数据。期待能从以上行为、文本和图像数据中挖掘穿衣搭配模型,为用户提供个性化、优质的、专业的穿衣搭配方案,预测给定商品的搭配商品集合。
2. 社会民生
(1) 情绪指标的关联关系挖掘和预测
生猪是畜牧业的第一大产业,其价格波动的社会反响非常敏感。生猪价格变动的主要原因在于受市场供求关系的影响。然而专家和媒体对于生猪市场前景的判断、疫情的报道,是否会对养殖户和消费者的情绪有所影响?情绪上的变化是否会对这些人群的行为产生一定影响,从而影响生猪市场的供求关系?互联网作为网民发声的第⼀平台,在网民情绪的捕捉上具有天然的优势。可以基于海量提供的数据,挖掘出互联网情绪指标与生猪价格之间的关联关系,从而形成基于互联网数据的生猪价格预测模型,挖掘互联网情绪指标与生猪价格之间的关联关系和预测。
(2) 气象关联分析
在社会经济生活中,不少行业,如农业、交通业、建筑业、旅游业、销售业、保险业等,无一例外与天气的变化息息相关。随着各行各业对气象信息的需求越来越大,社会各方对气象数据服务的个性化和精细化要求也在不断提升,如何开发气象数据在不同领域的应用,更好的支持大众创业、万众创新,服务民计民生,是气象大数据面临的迫切需求。
为了更深入地挖掘气象资源的价值,可以基于多年积累的地面历史气象数据,及气象数据与其他各行各业数据的有效结合,挖掘气象要素之间、以及气象与其它事物之间的相互关系。
(1) 交通事故成因分析
随着时代发展,便捷交通对社会产⽣巨大贡献的同时,各类交通事故也严重地影响了人们生命财产安全和社会经济发展。为了更深人挖掘交通事故的潜在诱因,带动公众关注交通安全,贵阳市交通管理局开放了交通事故数据及多维度参考数据,希望通过对事故类型、事故人员、事故车辆、事故天气、驾照信息、驾驶⼈员犯罪记录数据以及其他和交通事故有关的数据进行深度挖掘,形成交通事故成因分析方案。
3. 金融行业
(1) 银行客户交叉销售分析
某商业银行试图通过对个人客户购买本银行金融产品的数据进行分析,从而发现交叉销售的机会。
(2) 银行营销方案推荐
关联规则挖掘技术已经被广泛应用在金融行业企业中,它可以成功预测银行客户需求。⼀旦获得了这些信息,银行就可以改善自身营销。如各银行在自己的ATM机上就捆绑了顾客可能感兴趣的本行产品信息,供使用本行ATM机的用户了解。如果数据库中显示,某个高信用限额的客户更换了地址,这个客户很有可能新近购买了⼀栋更大的住宅,因此会有可能需要更高信用限额,更高端的新信用卡,或者需要⼀个住房改善贷款,这些产品都可以通过信用卡账单邮寄给客户。当客户打电话咨询的时候,数据库可以有力地帮助电话销售代表。销售代表的电脑屏幕上可以显示出客户的特点,同时也可以显示出顾客会对什么产品感兴趣。
4. 文娱体育
(1) 影视演员组合
通过对历史影视作品的收视、票房数据进行挖掘,可以了解哪些演员一起合作的概率更高,而哪些演员一起合作,可以有更高票房或收视效果,从而在新的影视作品中作为参考
(2) 球员最优组合
与影视作品的导、编、演组合类似,棒球、足球、篮球、曲棍球等团体性体育运动,也涉及团体成员基于历史数据的最优组合挖掘;而且在体育行业,还可以应用于比赛前的准备工作项目、比赛场地等因素,对比赛结果的影响挖掘
l 关联分析工具
1.关河因果
这是一款基于关联规则做因果分析的数据分析软件,虽然是以因果分析为导向,不过在这个产品的框架中也包含了关联分析的内容,以及挖掘关联规则的技术。基于图计算进行关联规则的深度发现,通过精准的规则进行因果分析。能够对大规模图数据进行规则的自动发现。
2.豌豆DM
豌豆是一款可进行关联挖掘平台, 它可对接入数据进行可视化数据预处理和数据建模,并基于庞大的数据算法进行图形化数据探索,帮助用户深度分析数据的规律, 挖掘数据的价值。
3、WEKA
WEKA 的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),同时 weka 也是新西兰的一种鸟名,而 WEKA 的主要开发者也来自新西兰。WEKA 作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行关联规则的发现。如果想自己实现数据挖掘算法的话,可以看一看 weka 的接口文档。
















 9007
9007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









