







NVIDIA Triton系列07-image_client 用户端参数
B站:肆十二-的个人空间-肆十二-个人主页-哔哩哔哩视频 (bilibili.com)
博客:肆十二-CSDN博客
作为服务器的最重要任务,就是要接受来自不同终端所提出的各种请求,然后根据要求执行对应的计算,再将计算结果返回给终端。
当 Triton 推理服务器运行起来之后,就进入等待请求的状态,因此我们所要提出的请求内容,就必须在用户端软件里透过参数去调整请求的内容,这部分在 Triton 相关使用文件中并没有提供充分的说明,因此本文的重点就在于用 Python 版的 image_client.py 来说明相关参数的内容,其他用户端的参数基本上与这个端类似,可以类比使用。
本文的实验内容,是将 Triton 服务器安装在 IP 为 192.168.0.10 的 Jetson AGX Orin 上,将 Triton 用户端装在 IP 为 192.168.0.20 的树莓派上,读者可以根据已有的设备资源自行调配。
在开始进行实验之前,请先确认以下两个部分的环境:
在服务器设备上启动 Triton 服务器,并处于等待请求的状态:
如果还没启动的话,请直接执行以下指令:
# 根据实际的模型仓根目录位置设定TRITON_MODEL_REPO路径$ export TRITON_MODEL_REPO= H O M E / t r i t o n / s e r v e r / d o c s / e x a m p l e s / m o d e l r e p o s i t o r y 执行 T r i t o n 服务器 {HOME}/triton/server/docs/examples/model_repository执行Triton服务器 HOME/triton/server/docs/examples/modelrepository执行Triton服务器 docker run --rm --net=host -v ${TRITON_MODEL_REPO}:/models nvcr.io/nvidia/tritonserver:22.09-py3 tritonserver --model-repository=/models
在用户端设备下载 Python 的用户端范例,并提供若干张要检测的图片:
先执行以下指令,确认Triton服务器已经正常启动,并且从用户端设备可以访问:
$ curl -v 192.168.0.10:8000/v2/health/ready
只要后面出现的信息中有“HTTP/1.1 200 OK”部分,就表示一切正常。
如果还没安装 Triton 的 Python 用户端环境,并且还未下载用户端范例的话,请执行以下指令:
$ cd H O M E / t r i t o n {HOME}/triton HOME/triton git clone https://github.com/triton-inference-server/client$ cd client/src/python/examples# 安装 Triton 的 Python用户端环境$ pip3 install tritonclient[all] attrdict -i https://pypi.tuna.tsinghua.edu.cn/simple
最后记得在用户端设备上提供几张图片,并且放置在指定文件夹(例如~/images)内,准备好整个实验环境,就可以开始下面的说明。
现在执行以下指令,看一下 image_client 这个终端的参数列表:
$ python3 image_client.py
会出现以下的信息:

接下来就来说明这些参数的用途与用法。
用“-u”参数对远程服务器提出请求:
如果用户端与服务器端并不在同一台机器上的时候,就可以用这个参数对远程 Triton 服务器提出推理请求,请执行以下指令:
$ python3 image_client.py -m inception_graphdef -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images/mug.jpg
由于 Triton 的跨节点请求主要透过 HTTP/REST 协议处理,需要透过 8000 端口进行传输,因此在“-u”后面需要接上“IP:8000”就能正常使用。
请自行检查回馈的计算结果是否正确!
2. 用“-m”参数去指推理模型:
从“python3 image_client.py”所产生信息的最后部分,可以看出用“-m”参数去指定推理模型是必须的选项,但是可以指定哪些推理模型呢?就得从 Triton 服务器的启动信息中去寻找答案。
下图是本范例是目前启动的 Triton 推理服务器所支持的模型列表:
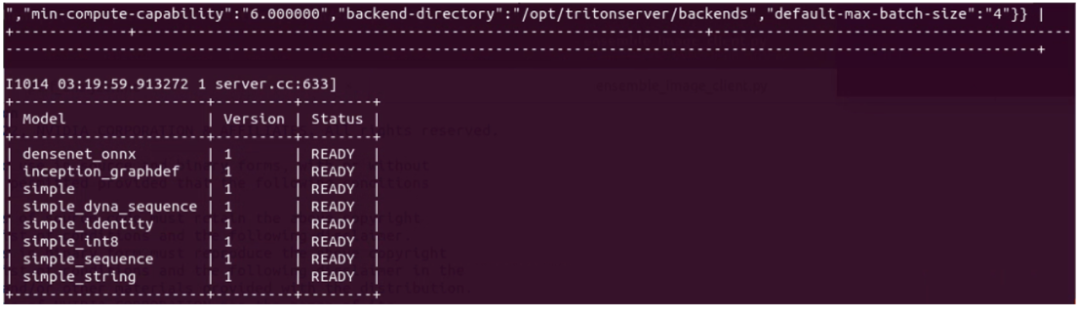
这里显示有的 8 个推理模型,就是启动服务器时使用“–model-repository=”参数指定的模型仓内容,因此客户端使用“-m”参数指定的模型,必须是在这个表所列的内容之列,例如“-m densenet_onnx”、“-m inception_graphdef”等等。
现在执行以下两道指令,分别看看使用不同模型所得到的结果有什么差异:
$ python3 image_client.py -m densenet_onnx -u 192.168.0.10:8000 -s INCEPTION H O M E / i m a g e s / m u g . j p g {HOME}/images/mug.jpg HOME/images/mug.jpg python3 image_client.py -m inception_graphdef -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images/mug.jpg
使用 densenet_onnx 模型与 inception_graphdef 模型所返回的结果,分别如下:

虽然两个模型所得到的检测结果一致,但是二者所得到的置信度表达方式并不相同,而且标签编号并不一样(504 与 505)。
这个参数后面还可以使用“-x”去指定“版本号”,不过目前所使用的所有模型都只有一个版本,因此不需要使用这个参数。
3. 使用“-s”参数指定图像缩放方式:
有些神经网络算法在执行推理之前,需要对图像进行特定形式的缩放(scaling)处理,因此需要先用这个参数指定缩放的方式,如果没有指定正确的模式,会导致推理结果的错误。目前这个参数支持{NONE, INSPECTION, VGG}三个选项,预设值为“NONE”。
在本实验 Triton 推理服务器所支持的 densenet_onnx 与 inception_graphdef 模型,都需要选择 INSPECTION 缩放方式,因此执行指令中需要用“-s INSPECTION”去指定,否则会得到错误的结果。
请尝试以下指令,省略前面指定中的“-s INSPECTION”,或者指定为 VGG 模式,看看结果如何?
$ python3 image_client.py -m inception_graphdef -u 192.168.0.10:8000 -s VGG ${HOME}/images/mug.jpg
4. 对文件夹所有图片进行推理
如果有多个要进行推理计算的标的物(图片),Triton 用户端可用文件夹为单位来提交要推理的内容,例如以下指令就能一次对 ${HOME}/images 目录下所有图片进行推理:
$ python3 image_client.py -m inception_graphdef -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images
例如我们在文件夹中准备了 car.jpg、mug.jpg、vulture.jpg 三种图片,如下:

执行后反馈的结果如下:

显示推理检测的结果是正确的!
5. 用“-b”参数指定批量处理的值
执行前面指令的结果可以看到“batch size 1”,表示用户端每次提交一张图片进行推理,所以出现 Request 1、Request 2 与 Request 3 总共提交三次请求。
现在既然有 3 张图片,可否一次提交 3 张图片进行推理呢?我们可以用“-b”参数来设定,如果将前面的指令中添加“-b 3”这个参数,如下:
$ python3 image_client.py -m inception_graphdef -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images -b 3
现在显示的结果如下:

现在看到只提交一次“batch size 3”的请求,就能对三张图片进行推理。如果 batch 值比图片数量大呢?例如改成“-b 5”的时候,看看结果如何?如下:

现在可以看到所推理的图片数量是 5,其中 1/4、2/5 是同一张图片,表示重复使用了。这样就应该能清楚这个“batch size”值的使用方式。
但如果这里将模型改成 densenet_onnx 的时候,执行以下指令:
$ python3 image_client.py -m densenet_onnx -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images -b 3
会得到“ERROR: This model doesn’t support batching.”的错误信息,这时候就回头检查以下模型仓里 densenet_onnx 目录下的 config.pbtxt 配置文件,会发现里面设置了“max_batch_size : 0”,并不支持批量处理。
而 inception_graphdef 模型的配置文件里设置“max_batch_size : 128”,如果指令给定“-b”参数大于这个数值,也会出现错误信息。
6. 其他:
另外还有指定通讯协议的“-i”参数、使用异步推理 API 的“-a”参数、使用流式推理 API 的“–streaming”参数等等,属于较进阶的用法,在这里先不用过度深入。
以上所提供的 5 个主要参数,对初学者来说是非常足够的,好好掌握这几个参数就已经能开始进行更多图像方面的推理实验。
















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











