






预测算法——CNN-GRU、LSTM、BiGRU、BiLSTM-Attention
本文汇总了基于卷积神经网络(CNN)与循环神经网络(RNN)及其变体(如GRU、LSTM、BiGRU、BiLSTM)组合的多种预测算法,深入探讨了这些算法的原理、结构、优缺点以及实际应用场景。此外,本文特别介绍了结合Attention机制的CNN-RNN组合算法Attention机制通过动态权重分配让模型能够关注序列中的重要特征,提高了预测性能和模型的可解释性。这类算法在自然语言处理、时间序列分析、视频分析等领域展现出强大的能力。
一、CNN-GRU 算法介绍
1. 算法原理
1.1定义与描述
CNN-GRU模型是卷积神经网络(CNN)与门控循环单元(GRU)的结合体。CNN擅长从输入数据中提取空间特征,而GRU用于处理时间序列,捕捉序列数据中的时间依赖性。该组合特别适用于需要同时分析空间和时间特征的数据,如图像字幕生成、视频分析等任务。
1.2工作原理
-
输入层:首先输入数据(如图像或序列)进入CNN。
-
卷积层:CNN通过卷积和池化操作提取数据的局部特征,生成特征图。
-
展平层:将CNN输出的特征图展平为一维向量。
-
GRU层:将展平的向量输入GRU,GRU通过门控机制(更新门和重置门)处理序列数据,学习时间依赖性。
-
输出层:通过全连接层和激活函数,输出预测结果。
1.3数理基础
-
CNN的核心在于卷积操作,公式为:
(I∗K)(x,y)=i∑j∑I(x−i,y−j)⋅K(i,j)其中,I 是输入特征图,K 是卷积核。 -
GRU的更新门和重置门的计算公式:
zt=σ(Wz⋅[ht−1,xt])rt=σ(Wr⋅[ht−1,xt])ht=(1−zt)⋅ht−1+zt⋅tanh(Wh⋅[rt⋅ht−1,xt])其中,zt 是更新门,rt 是重置门,ht 是GRU单元的隐状态。
2. 算法结构
2.1模块组成
-
卷积模块(CNN):负责提取空间特征。
-
时间序列处理模块(GRU):处理序列特征,学习时间依赖。
-
全连接层:将提取的特征进行组合和映射,输出结果。
2.2流程图
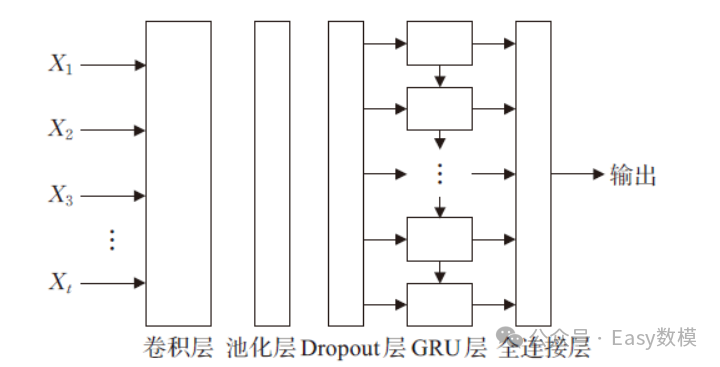
3. 优点与缺点
3.1优点
-
• 特征提取能力强:CNN可以高效提取数据的空间特征,GRU捕捉时间特征,两者结合大幅提高模型表现。
-
• 计算效率高:GRU相较于LSTM,参数更少,计算速度更快,适合实时应用。
-
• 鲁棒性好:对处理缺失数据或噪声数据有较好的稳定性。
3.2缺点
-
对数据量要求较高:需要大量数据进行训练以达到较好的效果。
-
可能出现梯度消失:在长时间序列处理时,GRU可能会出现梯度消失问题,影响学习效果。
-
复杂性高:结构复杂,调参难度较大,可能需要大量实验来优化模型性能。
4. 应用场景
4.1实际应用
-
时间序列预测:如股票价格预测、销售量预测、流量预测。
-
图像字幕生成:用于图像描述生成,通过提取图像特征并生成自然语言描述。
-
视频分类与动作识别:处理带有时间信息的视频数据,识别动作和场景。
4.2典型案例
-
自动驾驶:结合CNN-GRU进行道路场景识别,捕捉实时交通标志和路况信息。
-
医疗诊断:用于心电图分析,识别患者心律异常,通过时空特征的联合分析提高诊断准确率。
-
智能监控:分析视频监控中的异常行为,如异常入侵、打斗场景识别等。
5.python案例
1.导入必要的库
import os
import math
import pandas as pd
import numpy as np
from math import sqrt
from numpy import concatenate
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler, StandardScaler, LabelEncoder
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from pandas import DataFrame, concat
import keras.backend as K
from scipy.io import savemat, loadmat
from sklearn.neural_network import MLPRegressor
from keras.callbacks import LearningRateScheduler
from tensorflow.keras import Input, Model, Sequential
import mplcyberpunk
from prettytable import PrettyTable
import warnings
warnings.filterwarnings("ignore")2.加载并准备数据
# 加载数据集
dataset = pd.read_csv("电力负荷预测数据1.csv", encoding='gb2312')
print(dataset)
# 从数据集中提取数据,排除第一列
values = dataset.values[:, 1:]
# 确保所有数据都是浮点格式
values = values.astype('float32')
3.定义数据整理函数
def data_collation(data, n_in, n_out, or_dim, scroll_window, num_samples):
res = np.zeros((num_samples, n_in * or_dim + n_out))
for i in range(0, num_samples):
h1 = values[scroll_window * i: n_in + scroll_window * i, 0:or_dim]
h2 = h1.reshape(1, n_in * or_dim)
h3 = values[n_in + scroll_window * (i): n_in + scroll_window * (i) + n_out, -1].T
h4 = h3[np.newaxis, :]
h5 = np.hstack((h2, h4))
res[i, :] = h5
return res
4.准备训练和测试数据
n_in = 5 # 输入前5行的数据
n_out = 2 # 预测未来2步的数据
or_dim = values.shape[1] # 记录特征数据维度
num_samples = 2000 # 设置用于训练和测试的数据样本数量
scroll_window = 1 # 滑动窗口大小
res = data_collation(values, n_in, n_out, or_dim, scroll_window, num_samples)
values = np.array(res)
n_train_number = int(num_samples * 0.85) # 设置85%作为训练集
Xtrain = values[:n_train_number, :n_in * or_dim]
Ytrain = values[:n_train_number, n_in * or_dim:]
Xtest = values[n_train_number:, :n_in * or_dim]
Ytest = values[n_train_number:, n_in * or_dim:]
# 对训练集和测试集进行归一化
m_in = MinMaxScaler()
vp_train = m_in.fit_transform(Xtrain)
vp_test = m_in.transform(Xtest)
m_out = MinMaxScaler()
vt_train = m_out.fit_transform(Ytrain)
vt_test = m_out.transform(Ytest)
# 调整数据形状
vp_train = vp_train.reshape((vp_train.shape[0], n_in, or_dim))
vp_test = vp_test.reshape((vp_test.shape[0], n_in, or_dim))
5.定义和训练CNN-GRU模型
def cnn_gru_model():
inputs = Input(shape=(vp_train.shape[1], vp_train.shape[2]))
conv1d = Conv1D(filters=64, kernel_size=2, activation='relu')(inputs)
maxpooling = MaxPooling1D(pool_size=2)(conv1d)
reshaped = Reshape((-1, 64))(maxpooling)
gru = GRU(128, activation='selu', return_sequences=False)(reshaped)
outputs = Dense(vt_train.shape[1])(gru)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='mse', optimizer='Adam')
model.summary()
return model
model = cnn_gru_model()
history = model.fit(vp_train, vt_train, batch_size=32, epochs=50, validation_split=0.25, verbose=2)6.绘制训练和验证损失曲线
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()7.进行预测并反归一化数据
yhat = model.predict(vp_test)
yhat = yhat.reshape(num_samples - n_train_number, n_out)
predicted_data = m_out.inverse_transform(yhat)
8.定义评估指标函数并计算预测性能
def mape(y_true, y_pred):
record = []
for index in range(len(y_true)):
temp_mape = np.abs((y_pred[index] - y_true[index]) / y_true[index])
record.append(temp_mape)
return np.mean(record) * 100
def evaluate_forecasts(Ytest, predicted_data, n_out):
mse_dic = []
rmse_dic = []
mae_dic = []
mape_dic = []
r2_dic = []
table = PrettyTable(['测试集指标', 'MSE', 'RMSE', 'MAE', 'MAPE', 'R2'])
for i in range(n_out):
actual = [float(row[i]) for row in Ytest]
predicted = [float(row[i]) for row in predicted_data]
mse = mean_squared_error(actual, predicted)
mse_dic.append(mse)
rmse = sqrt(mean_squared_error(actual, predicted))
rmse_dic.append(rmse)
mae = mean_absolute_error(actual, predicted)
mae_dic.append(mae)
MApe = mape(actual, predicted)
mape_dic.append(MApe)
r2 = r2_score(actual, predicted)
r2_dic.append(r2)
if n_out == 1:
strr = '预测结果指标:'
else:
strr = '第' + str(i + 1) + '步预测结果指标:'
table.add_row([strr, mse, rmse, mae, str(MApe) + '%', str(r2 * 100) + '%'])
return mse_dic, rmse_dic, mae_dic, mape_dic, r2_dic, table
mse_dic, rmse_dic, mae_dic, mape_dic, r2_dic, table = evaluate_forecasts(Ytest, predicted_data, n_out)
print(table)
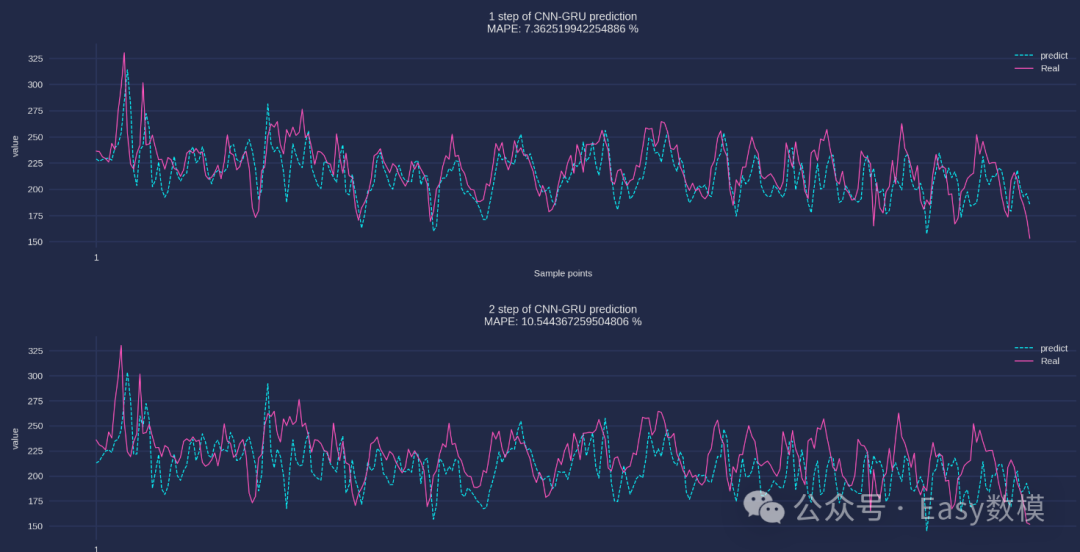
| 测试集指标 | MSE | RMSE | MAE | MAPE | R2 |
| 第1步预测结果指标: | 463.79201039391955 | 21.5358308498632 | 16.4265939839681 | 7.362519942254886% | 18.84109038829068% |
| 第2步预测结果指标: | 856.2547738725033 | 29.261831348575967 | 23.541549224853515 | 10.544367259504806% | -45.866190306192856% |
9.绘制预测结果
from matplotlib import rcParams
config = {
"font.family": 'serif',
"font.size": 10,
"mathtext.fontset": 'stix',
"font.serif": ['Times New Roman'],
'axes.unicode_minus': False
}
rcParams.update(config)
plt.ion()
for ii in range(n_out):
plt.rcParams['axes.unicode_minus'] = False
plt.style.use('cyberpunk')
plt.figure(figsize=(10, 2), dpi=300)
x = range(1, len(predicted_data) + 1)
plt.xticks(x[::int((len(predicted_data) + 1))])
plt.tick_params(labelsize=5)
plt.plot(x, predicted_data[:, ii], linestyle="--", linewidth=0.5, label='predict')
plt.plot(x, Ytest[:, ii], linestyle="-", linewidth=0.5, label='Real')
plt.rcParams.update({'font.size': 5})
plt.legend(loc='upper right', frameon=False)
plt.xlabel("Sample points", fontsize=5)
plt.ylabel("value", fontsize=5)
if n_out == 1:
plt.title(f"The prediction result of CNN-GRU :\nMAPE: {mape(Ytest[:, ii], predicted_data[:, ii])} %")
else:
plt.title(f"{ii + 1} step of CNN-GRU prediction\nMAPE: {mape(Ytest[:, ii], predicted_data[:, ii])} %")
plt.ioff()
plt.show()
二、CNN-LSTM 算法介绍
1. 算法原理
1.1定义与描述
CNN-LSTM模型是卷积神经网络(CNN)与长短期记忆网络(LSTM)的结合体。CNN用于从输入数据中提取空间特征,而LSTM用于处理时间序列数据,捕捉长时间的序列依赖性。该模型适用于需要同时分析空间特征和时间特征的数据,如文本生成、视频分析等任务。
1.2工作原理
-
输入层:首先输入数据(如图像或序列)进入CNN。
-
卷积层:CNN通过卷积和池化操作提取数据的局部特征,生成特征图。
-
展平层:将CNN输出的特征图展平为一维向量。
-
LSTM层:将展平的向量输入LSTM,LSTM通过输入门、遗忘门和输出门机制处理序列数据,捕捉长时间依赖性。
-
输出层:通过全连接层和激活函数,输出预测结果。
1.3数理基础
-
CNN的卷积操作公式为:
(I∗K)(x,y)=i∑j∑I(x−i,y−j)⋅K(i,j)其中,I 是输入特征图,K 是卷积核。 -
LSTM的核心在于其门控机制,计算公式如下:
-
遗忘门:ft=σ(Wf⋅[ht−1,xt]+bf)
-
输入门:it=σ(Wi⋅[ht−1,xt]+bi)
-
输出门:ot=σ(Wo⋅[ht−1,xt]+bo)
-
细胞状态更新:Ct=ft⋅Ct−1+it⋅tanh(WC⋅[ht−1,xt]+bC)
-
隐状态更新:ht=ot⋅tanh(Ct)
-
2. 算法结构
2.1模块组成
-
卷积模块(CNN):负责提取空间特征。
-
时间序列处理模块(LSTM):处理序列特征,学习长时间依赖性。
-
全连接层:将提取的特征进行组合和映射,输出结果。
2.2流程图
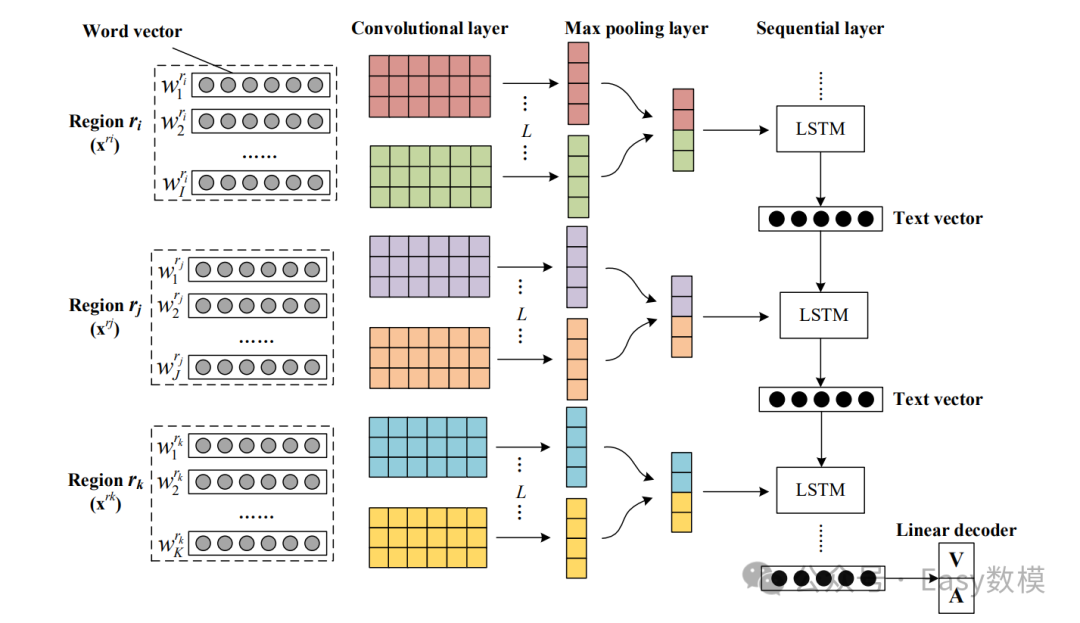
3. 优点与缺点
3.1优点
-
特征提取能力强:CNN可以高效提取数据的空间特征,LSTM能够处理长时间依赖性。
-
灵活性高:适用于处理各种类型的时空数据,如文本、视频等。
-
解决梯度消失问题:LSTM通过门控机制有效解决了长期依赖问题中的梯度消失问题。
3.2缺点
-
计算复杂度高:LSTM结构复杂,计算成本较高,训练时间长。
-
调参难度大:需要大量的实验来调优模型参数。
-
对数据量要求高:需要大量的数据来训练,以达到较好的效果。
4. 应用场景
4.1实际应用
-
时间序列预测:如股市预测、天气预测、能源负荷预测。
-
视频分析:如动作识别、场景理解、视频描述生成。
-
自然语言处理:如文本生成、机器翻译、情感分析。
4.2典型案例
-
智能对话系统:结合CNN-LSTM进行对话生成和情感分析,提高用户体验。
-
金融分析:用于时间序列数据的预测和风险管理。
-
医疗诊断:结合图像和时间序列数据进行复杂诊断,如疾病预测和治疗建议。
5.python案例
1.导入必要的库
import os # 操作系统功能
import math # 数学功能
import pandas as pd # 数据处理与分析
import openpyxl # Excel文件操作
from math import sqrt # 计算平方根
from numpy import concatenate # 数组拼接
import matplotlib.pyplot as plt # 绘图
import numpy as np # 数值计算
from sklearn.preprocessing import MinMaxScaler, StandardScaler, LabelEncoder # 数据预处理
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score # 评估指标
from tensorflow.keras.layers import * # 神经网络层
from tensorflow.keras.models import * # 神经网络模型
from pandas import DataFrame, concat # 数据框操作
import keras.backend as K # Keras后端
from scipy.io import savemat, loadmat # MATLAB文件操作
from sklearn.neural_network import MLPRegressor # 神经网络回归模型
from keras.callbacks import LearningRateScheduler # 学习率调度
from tensorflow.keras import Input, Model, Sequential # Keras模型构建
import mplcyberpunk # 绘图风格
from prettytable import PrettyTable # 表格打印
import warnings
warnings.filterwarnings("ignore") # 忽略警告2.加载和准备数据
dataset = pd.read_csv("电力负荷预测数据1.csv", encoding='gb2312')
print(dataset)
values = dataset.values[:, 1:] # 选择所有行,去除第一列
values = values.astype('float32') # 转换数据类型为浮点数3.定义数据整理函数
def data_collation(data, n_in, n_out, or_dim, scroll_window, num_samples):
res = np.zeros((num_samples, n_in * or_dim + n_out))
for i in range(num_samples):
h1 = values[scroll_window * i: n_in + scroll_window * i, 0:or_dim]
h2 = h1.reshape(1, n_in * or_dim)
h3 = values[n_in + scroll_window * i: n_in + scroll_window * i + n_out, -1].T
h4 = h3[np.newaxis, :]
h5 = np.hstack((h2, h4))
res[i, :] = h5
return res4.数据集划分与归一化
n_in = 5 # 输入步长
n_out = 2 # 输出步长
or_dim = values.shape[1] # 特征维度
num_samples = 2000 # 样本数量
scroll_window = 1 # 滑动窗口大小
res = data_collation(values, n_in, n_out, or_dim, scroll_window, num_samples)
values = np.array(res)
n_train_number = int(num_samples * 0.85)
Xtrain = values[:n_train_number, :n_in * or_dim]
Ytrain = values[:n_train_number, n_in * or_dim:]
Xtest = values[n_train_number:, :n_in * or_dim]
Ytest = values[n_train_number:, n_in * or_dim:]
m_in = MinMaxScaler()
vp_train = m_in.fit_transform(Xtrain)
vp_test = m_in.transform(Xtest)
m_out = MinMaxScaler()
vt_train = m_out.fit_transform(Ytrain)
vt_test = m_out.transform(Ytest)
vp_train = vp_train.reshape((vp_train.shape[0], n_in, or_dim))
vp_test = vp_test.reshape((vp_test.shape[0], n_in, or_dim))5.定义和训练CNN-LSTM模型
def cnn_lstm_model():
inputs = Input(shape=(vp_train.shape[1], vp_train.shape[2]))
conv1d = Conv1D(filters=64, kernel_size=2, activation='relu')(inputs)
maxpooling = MaxPooling1D(pool_size=2)(conv1d)
reshaped = Reshape((-1, 64))(maxpooling)
lstm = LSTM(128, activation='selu', return_sequences=False)(reshaped)
outputs = Dense(vt_train.shape[1])(lstm)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='mse', optimizer='Adam')
model.summary()
return model
model = cnn_lstm_model()
history = model.fit(vp_train, vt_train, batch_size=32, epochs=50, validation_split=0.25, verbose=2)6.绘制训练和验证损失曲线
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()7.模型预测与反归一化
yhat = model.predict(vp_test)
yhat = yhat.reshape(num_samples - n_train_number, n_out)
predicted_data = m_out.inverse_transform(yhat)8.评估预测性能
def mape(y_true, y_pred):
record = []
for index in range(len(y_true)):
temp_mape = np.abs((y_pred[index] - y_true[index]) / y_true[index])
record.append(temp_mape)
return np.mean(record) * 100
def evaluate_forecasts(Ytest, predicted_data, n_out):
mse_dic, rmse_dic, mae_dic, mape_dic, r2_dic = [], [], [], [], []
table = PrettyTable(['测试集指标', 'MSE', 'RMSE', 'MAE', 'MAPE', 'R2'])
for i in range(n_out):
actual = [float(row[i]) for row in Ytest]
predicted = [float(row[i]) for row in predicted_data]
mse = mean_squared_error(actual, predicted)
rmse = sqrt(mse)
mae = mean_absolute_error(actual, predicted)
MApe = mape(actual, predicted)
r2 = r2_score(actual, predicted)
table.add_row([f'第{i + 1}步预测结果指标:', mse, rmse, mae, f'{MApe}%', f'{r2 * 100}%'])
return table
print(evaluate_forecasts(Ytest, predicted_data, n_out))| 测试集指标 | MSE | RMSE | MAE | MAPE | R2 |
|---|---|---|---|---|---|
| 第1步预测结果指标: | 433.84 | 20.83 | 15.79 | 7.13% | 24.08% |
| 第2步预测结果指标: | 659.10 | 25.67 | 19.86 | 9.06% | -12.28% |
9.绘制预测结果
from matplotlib import rcParams
config = {
"font.family": 'serif',
"font.size": 10,
"mathtext.fontset": 'stix',
"font.serif": ['Times New Roman'],
'axes.unicode_minus': False
}
rcParams.update(config)
plt.ion()
for ii in range(n_out):
plt.style.use('cyberpunk')
plt.figure(figsize=(10, 2), dpi=300)
x = range(1, len(predicted_data) + 1)
plt.xticks(x[::int((len(predicted_data) + 1))])
plt.tick_params(labelsize=5)
plt.plot(x, predicted_data[:, ii], linestyle="--", linewidth=0.5, label='predict')
plt.plot(x, Ytest[:, ii], linestyle="-", linewidth=0.5, label='Real')
plt.legend(loc='upper right', frameon=False)
plt.xlabel("Sample points", fontsize=5)
plt.ylabel("value", fontsize=5)
plt.title(f"{ii+1} step of CNN-LSTM prediction\nMAPE: {mape(Ytest[:, ii], predicted_data[:, ii])} %")
plt.ioff()
plt.show()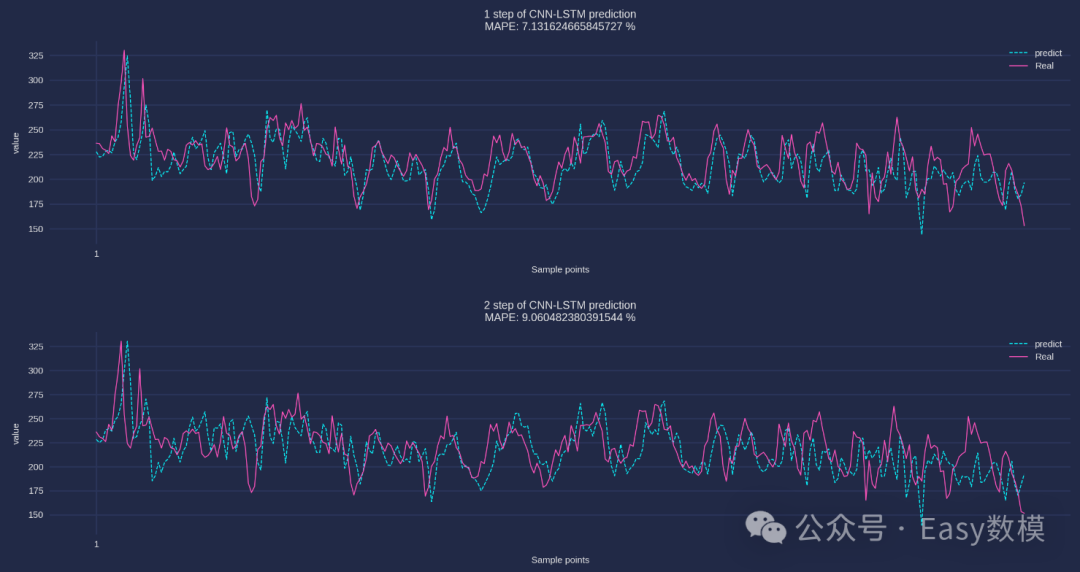
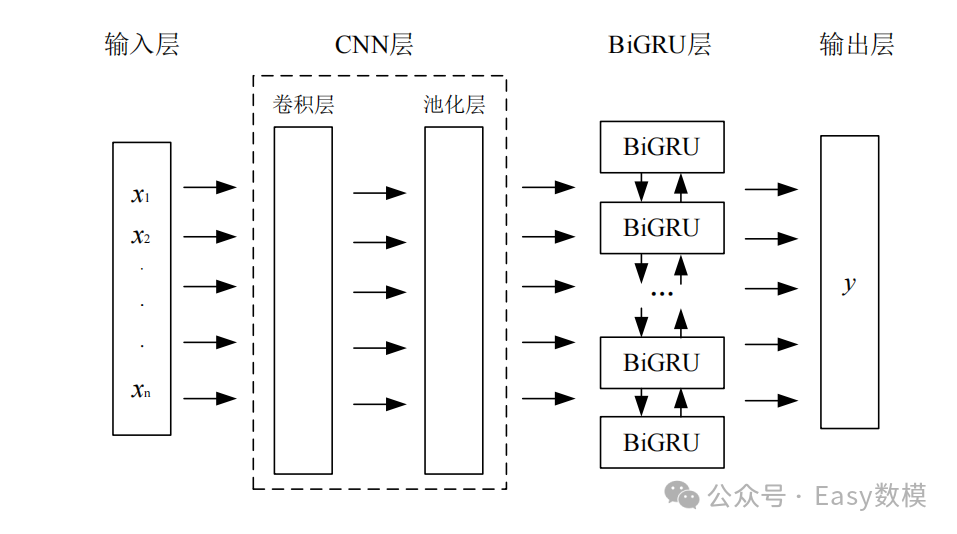
三、CNN-BiGRU 算法介绍
1. 算法原理
1.1定义与描述
CNN-BiGRU模型结合了卷积神经网络(CNN)和双向门控循环单元(BiGRU)。CNN用于提取输入数据的空间特征,而双向GRU(BiGRU)能够从正向和反向同时处理时间序列数据,捕捉双向的时间依赖性。该模型特别适用于需要双向上下文理解的任务,如语音识别和自然语言处理。
1.2工作原理
-
输入层:首先输入数据(如图像或序列)进入CNN。
-
卷积层:CNN通过卷积和池化操作提取数据的局部特征,生成特征图。
-
展平层:将CNN输出的特征图展平为一维向量。
-
BiGRU层:将展平的向量输入双向GRU(BiGRU),从前向和后向同时学习序列数据的特征,捕捉双向时间依赖性。
-
输出层:通过全连接层和激活函数,输出预测结果。
1.3数理基础
-
CNN的卷积操作公式为:
(I∗K)(x,y)=i∑j∑I(x−i,y−j)⋅K(i,j)其中,I 是输入特征图,K 是卷积核。 -
BiGRU的计算公式:
-
更新门和重置门的计算与普通GRU相同,但双向计算包含前向和后向的状态:zt(f)=σ(Wz(f)⋅[ht−1(f),xt])zt(b)=σ(Wz(b)⋅[ht+1(b),xt])
-
前向和后向隐状态的更新公式类似:ht(f)=(1−zt(f))⋅ht−1(f)+zt(f)⋅tanh(Wh(f)⋅[rt(f)⋅ht−1(f),xt])ht(b)=(1−zt(b))⋅ht+1(b)+zt(b)⋅tanh(Wh(b)⋅[rt(b)⋅ht+1(b),xt])
-
2. 算法结构
2.1模块组成
-
卷积模块(CNN):负责提取空间特征。
-
时间序列处理模块(BiGRU):从前向和后向同时处理序列特征,学习双向时间依赖性。
-
全连接层:将提取的特征进行组合和映射,输出结果。
2.2流程图
3. 优点与缺点
3.1优点
-
双向依赖性学习:BiGRU可以从前向和后向同时学习序列特征,提高对序列数据的理解能力。
-
计算效率高:相较于双向LSTM,BiGRU结构更简单,计算效率更高。
-
更好的上下文捕捉能力:适合对上下文理解要求高的任务,如语音识别和文本生成。
3.2缺点
-
模型复杂度高:双向结构增加了模型的计算和存储开销。
-
对数据量要求较高:需要大量的数据训练,以充分学习双向特征。
-
调参难度大:双向模型和多层结构增加了调参的难度。
4. 应用场景
4.1实际应用
-
语音识别:结合前向和后向信息,提高语音识别的准确度。
-
自然语言处理:用于文本生成、命名实体识别、情感分析等任务。
-
视频分析:在动作识别和场景理解任务中更好地捕捉上下文信息。
4.2典型案例
-
对话系统:在智能对话系统中,使用CNN-BiGRU提高对用户语句的理解能力。
-
医疗文本分析:对医疗文献和病历进行文本分类和实体识别。
-
安全监控:分析监控视频中的异常行为,结合前后帧的信息提高识别准确性。
5.python代码
1.导入必要的库
import os # 操作系统功能
import math # 数学功能
import pandas as pd # 数据处理与分析
import openpyxl # Excel文件操作
from math import sqrt # 计算平方根
from numpy import concatenate # 数组拼接
import matplotlib.pyplot as plt # 绘图
import numpy as np # 数值计算
from sklearn.preprocessing import MinMaxScaler, StandardScaler, LabelEncoder # 数据预处理
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score # 评估指标
from tensorflow.keras.layers import * # 神经网络层
from tensorflow.keras.models import * # 神经网络模型
from pandas import DataFrame, concat # 数据框操作
import keras.backend as K # Keras后端
from scipy.io import savemat, loadmat # MATLAB文件操作
from sklearn.neural_network import MLPRegressor # 神经网络回归模型
from keras.callbacks import LearningRateScheduler # 学习率调度
from tensorflow.keras import Input, Model, Sequential # Keras模型构建
import mplcyberpunk # 绘图风格
from prettytable import PrettyTable # 表格打印
import warnings
warnings.filterwarnings("ignore") # 忽略警告2.加载和准备数据
dataset = pd.read_csv("电力负荷预测数据1.csv", encoding='gb2312') # 读取CSV文件
print(dataset)
values = dataset.values[:, 1:] # 选择所有行,去除第一列
values = values.astype('float32') # 转换数据类型为浮点数3.定义数据整理函数
def data_collation(data, n_in, n_out, or_dim, scroll_window, num_samples):
res = np.zeros((num_samples, n_in * or_dim + n_out))
for i in range(num_samples):
h1 = values[scroll_window * i: n_in + scroll_window * i, 0:or_dim]
h2 = h1.reshape(1, n_in * or_dim)
h3 = values[n_in + scroll_window * i: n_in + scroll_window * i + n_out, -1].T
h4 = h3[np.newaxis, :]
h5 = np.hstack((h2, h4))
res[i, :] = h5
return res4.数据集划分与归一化
n_in = 5 # 输入步长
n_out = 2 # 输出步长
or_dim = values.shape[1] # 特征维度
num_samples = 2000 # 样本数量
scroll_window = 1 # 滑动窗口大小
res = data_collation(values, n_in, n_out, or_dim, scroll_window, num_samples)
values = np.array(res)
n_train_number = int(num_samples * 0.85)
Xtrain = values[:n_train_number, :n_in * or_dim]
Ytrain = values[:n_train_number, n_in * or_dim:]
Xtest = values[n_train_number:, :n_in * or_dim]
Ytest = values[n_train_number:, n_in * or_dim:]
m_in = MinMaxScaler()
vp_train = m_in.fit_transform(Xtrain)
vp_test = m_in.transform(Xtest)
m_out = MinMaxScaler()
vt_train = m_out.fit_transform(Ytrain)
vt_test = m_out.transform(Ytest)
vp_train = vp_train.reshape((vp_train.shape[0], n_in, or_dim))
vp_test = vp_test.reshape((vp_test.shape[0], n_in, or_dim))5.定义和训练CNN-BiGRU模型
def cnn_bigru_model():
inputs = Input(shape=(vp_train.shape[1], vp_train.shape[2]))
conv1d = Conv1D(filters=32, kernel_size=2, activation='relu')(inputs)
maxpooling = MaxPooling1D(pool_size=2)(conv1d)
reshaped = Reshape((-1, 32))(maxpooling)
bigru = Bidirectional(GRU(128, activation='selu', return_sequences=False))(reshaped)
outputs = Dense(vt_train.shape[1])(bigru)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='mse', optimizer='Adam')
model.summary()
return model
model = cnn_bigru_model()
history = model.fit(vp_train, vt_train, batch_size=32, epochs=50, validation_split=0.25, verbose=2)6.绘制训练和验证损失曲线
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()7.模型预测与反归一化
yhat = model.predict(vp_test)
yhat = yhat.reshape(num_samples - n_train_number, n_out)
predicted_data = m_out.inverse_transform(yhat)8.评估预测性能
def mape(y_true, y_pred):
record = []
for index in range(len(y_true)):
temp_mape = np.abs((y_pred[index] - y_true[index]) / y_true[index])
record.append(temp_mape)
return np.mean(record) * 100
def evaluate_forecasts(Ytest, predicted_data, n_out):
mse_dic, rmse_dic, mae_dic, mape_dic, r2_dic = [], [], [], [], []
table = PrettyTable(['测试集指标', 'MSE', 'RMSE', 'MAE', 'MAPE', 'R2'])
for i in range(n_out):
actual = [float(row[i]) for row in Ytest]
predicted = [float(row[i]) for row in predicted_data]
mse = mean_squared_error(actual, predicted)
rmse = sqrt(mse)
mae = mean_absolute_error(actual, predicted)
MApe = mape(actual, predicted)
r2 = r2_score(actual, predicted)
table.add_row([f'第{i + 1}步预测结果指标:', mse, rmse, mae, f'{MApe}%', f'{r2 * 100}%'])
return table
print(evaluate_forecasts(Ytest, predicted_data, n_out))| 测试集指标 | MSE | RMSE | MAE | MAPE | R2 |
|---|---|---|---|---|---|
| 第1步预测结果指标: | 35381.87 | 188.10 | 148.07 | 8.22% | 80.40% |
| 第2步预测结果指标: | 36356.55 | 190.67 | 148.42 | 8.23% | 79.25% |
9.绘制预测结果
from matplotlib import rcParams
config = {
"font.family": 'serif',
"font.size": 10,
"mathtext.fontset": 'stix',
"font.serif": ['Times New Roman'],
'axes.unicode_minus': False
}
rcParams.update(config)
plt.ion()
for ii in range(n_out):
plt.style.use('cyberpunk')
plt.figure(figsize=(10, 2), dpi=300)
x = range(1, len(predicted_data) + 1)
plt.xticks(x[::int((len(predicted_data) + 1))])
plt.tick_params(labelsize=5)
plt.plot(x, predicted_data[:, ii], linestyle="--", linewidth=0.5, label='predict')
plt.plot(x, Ytest[:, ii], linestyle="-", linewidth=0.5, label='Real')
plt.legend(loc='upper right', frameon=False)
plt.xlabel("Sample points", fontsize=5)
plt.ylabel("value", fontsize=5)
plt.title(f"{ii+1} step of CNN-BiGRU prediction\nMAPE: {mape(Ytest[:, ii], predicted_data[:, ii])} %")
plt.ioff()
plt.show()四、CNN-BiLSTM 算法介绍
1. 算法原理
1.1定义与描述
CNN-BiLSTM模型结合了卷积神经网络(CNN)和双向长短期记忆网络(BiLSTM)。CNN用于提取输入数据的空间特征,而双向LSTM(BiLSTM)可以从正向和反向同时处理时间序列数据,捕捉双向的长时间依赖性。该模型特别适用于需要理解长时间上下文的任务,如复杂文本生成和时间序列预测。
1.2工作原理
-
输入层:首先输入数据(如图像或序列)进入CNN。
-
卷积层:CNN通过卷积和池化操作提取数据的局部特征,生成特征图。
-
展平层:将CNN输出的特征图展平为一维向量。
-
BiLSTM层:将展平的向量输入双向LSTM(BiLSTM),从前向和后向同时学习序列数据的特征,捕捉双向长时间依赖性。
-
输出层:通过全连接层和激活函数,输出预测结果。
1.3数理基础
-
CNN的卷积操作公式为:
(I∗K)(x,y)=i∑j∑I(x−i,y−j)⋅K(i,j)其中,I 是输入特征图,K 是卷积核。 -
BiLSTM的计算公式:
-
遗忘门:ft(f)=σ(Wf(f)⋅[ht−1(f),xt]+bf(f))ft(b)=σ(Wf(b)⋅[ht+1(b),xt]+bf(b))
-
输入门:it(f)=σ(Wi(f)⋅[ht−1(f),xt]+bi(f))it(b)=σ(Wi(b)⋅[ht+1(b),xt]+bi(b))
-
输出门:ot(f)=σ(Wo(f)⋅[ht−1(f),xt]+bo(f))ot(b)=σ(Wo(b)⋅[ht+1(b),xt]+bo(b))
-
细胞状态更新:Ct(f)=ft(f)⋅Ct−1(f)+it(f)⋅tanh(WC(f)⋅[ht−1(f),xt]+bC(f))Ct(b)=ft(b)⋅Ct+1(b)+it(b)⋅tanh(WC(b)⋅[ht+1(b),xt]+bC(b))
-
隐状态更新:ht(f)=ot(f)⋅tanh(Ct(f))ht(b)=ot(b)⋅tanh(Ct(b))
-
2. 算法结构
模块组成
-
卷积模块(CNN):负责提取空间特征。
-
时间序列处理模块(BiLSTM):从前向和后向同时处理序列特征,学习双向长时间依赖性。
-
全连接层:将提取的特征进行组合和映射,输出结果。
流程图
3. 优点与缺点
3.1优点
-
双向依赖性学习:BiLSTM可以从前向和后向同时学习长时间序列特征,提高对序列数据的理解能力。
-
强大的记忆能力:LSTM擅长捕捉长时间依赖性,能够解决梯度消失问题。
-
上下文敏感:适合需要深度理解上下文关系的任务,如文本生成和机器翻译。
3.2缺点
-
计算复杂度高:BiLSTM结构复杂,计算开销大,训练时间较长。
-
调参困难:需要大量的实验来调优模型参数和结构。
-
对硬件资源要求高:大规模的BiLSTM模型可能需要较大的存储和计算资源。
4. 应用场景
4.1实际应用
-
时间序列预测:如电力负荷预测、气象数据分析、金融市场预测等。
-
自然语言处理:文本生成、机器翻译、命名实体识别、情感分析。
-
视频分析:在复杂场景和行为预测中利用双向上下文信息进行精准识别。
4.2典型案例
-
医疗文本分析:对医学文献和病历数据进行深度分析和分类,识别关键医学实体和术语。
-
机器人导航:在机器人路径规划中,结合双向LSTM预测环境变化和规划最优路径。
-
自动摘要生成:利用双向依赖性学习,生成高质量的文档摘要和新闻摘要。
5.python案例
-
导入必要的库
import os # 操作系统功能
import math # 数学功能
import pandas as pd # 数据处理与分析
import openpyxl # Excel文件操作
from math import sqrt # 计算平方根
from numpy import concatenate # 数组拼接
import matplotlib.pyplot as plt # 绘图
import numpy as np # 数值计算
from sklearn.preprocessing import MinMaxScaler, StandardScaler, LabelEncoder # 数据预处理
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score # 评估指标
from tensorflow.keras.layers import * # 神经网络层
from tensorflow.keras.models import * # 神经网络模型
from pandas import DataFrame, concat # 数据框操作
import keras.backend as K # Keras后端
from scipy.io import savemat, loadmat # MATLAB文件操作
from sklearn.neural_network import MLPRegressor # 神经网络回归模型
from keras.callbacks import LearningRateScheduler # 学习率调度
from tensorflow.keras import Input, Model, Sequential # Keras模型构建
import mplcyberpunk # 绘图风格
from prettytable import PrettyTable # 表格打印
import warnings
warnings.filterwarnings("ignore") # 忽略警告2.加载和准备数据
dataset = pd.read_csv("电力负荷预测数据1.csv", encoding='gb2312') # 读取CSV文件
print(dataset)
values = dataset.values[:, 1:] # 选择所有行,去除第一列
values = values.astype('float32') # 转换数据类型为浮点数3.定义数据整理函数
def data_collation(data, n_in, n_out, or_dim, scroll_window, num_samples):
res = np.zeros((num_samples, n_in * or_dim + n_out))
for i in range(num_samples):
h1 = values[scroll_window * i: n_in + scroll_window * i, 0:or_dim]
h2 = h1.reshape(1, n_in * or_dim)
h3 = values[n_in + scroll_window * i: n_in + scroll_window * i + n_out, -1].T
h4 = h3[np.newaxis, :]
h5 = np.hstack((h2, h4))
res[i, :] = h5
return res4.数据集划分与归一化
n_in = 5 # 输入步长
n_out = 2 # 输出步长
or_dim = values.shape[1] # 特征维度
num_samples = 2000 # 样本数量
scroll_window = 1 # 滑动窗口大小
res = data_collation(values, n_in, n_out, or_dim, scroll_window, num_samples)
values = np.array(res)
n_train_number = int(num_samples * 0.85)
Xtrain = values[:n_train_number, :n_in * or_dim]
Ytrain = values[:n_train_number, n_in * or_dim:]
Xtest = values[n_train_number:, :n_in * or_dim]
Ytest = values[n_train_number:, n_in * or_dim:]
m_in = MinMaxScaler()
vp_train = m_in.fit_transform(Xtrain)
vp_test = m_in.transform(Xtest)
m_out = MinMaxScaler()
vt_train = m_out.fit_transform(Ytrain)
vt_test = m_out.transform(Ytest)
vp_train = vp_train.reshape((vp_train.shape[0], n_in, or_dim))
vp_test = vp_test.reshape((vp_test.shape[0], n_in, or_dim))5.定义和训练CNN-BiLSTM模型
def cnn_bilstm_model():
inputs = Input(shape=(vp_train.shape[1], vp_train.shape[2]))
conv1d = Conv1D(filters=64, kernel_size=2, activation='relu')(inputs)
maxpooling = MaxPooling1D(pool_size=2)(conv1d)
reshaped = Reshape((-1, 64))(maxpooling)
bilstm = Bidirectional(LSTM(128, activation='selu', return_sequences=False))(reshaped)
outputs = Dense(vt_train.shape[1])(bilstm)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='mse', optimizer='Adam')
model.summary()
return model
model = cnn_bilstm_model()
history = model.fit(vp_train, vt_train, batch_size=32, epochs=50, validation_split=0.25, verbose=2)6.绘制训练和验证损失曲线
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()7.模型预测与反归一化
yhat = model.predict(vp_test)
yhat = yhat.reshape(num_samples - n_train_number, n_out)
predicted_data = m_out.inverse_transform(yhat)8.评估预测性能
def mape(y_true, y_pred):
record = []
for index in range(len(y_true)):
temp_mape = np.abs((y_pred[index] - y_true[index]) / y_true[index])
record.append(temp_mape)
return np.mean(record) * 100
def evaluate_forecasts(Ytest, predicted_data, n_out):
mse_dic, rmse_dic, mae_dic, mape_dic, r2_dic = [], [], [], [], []
table = PrettyTable(['测试集指标', 'MSE', 'RMSE', 'MAE', 'MAPE', 'R2'])
for i in range(n_out):
actual = [float(row[i]) for row in Ytest]
predicted = [float(row[i]) for row in predicted_data]
mse = mean_squared_error(actual, predicted)
rmse = sqrt(mse)
mae = mean_absolute_error(actual, predicted)
MApe = mape(actual, predicted)
r2 = r2_score(actual, predicted)
table.add_row([f'第{i + 1}步预测结果指标:', mse, rmse, mae, f'{MApe}%', f'{r2 * 100}%'])
return table
print(evaluate_forecasts(Ytest, predicted_data, n_out))| 测试集指标 | MSE | RMSE | MAE | MAPE | R2 |
|---|---|---|---|---|---|
| 第1步预测结果指标: | 5125.36 | 71.59 | 52.46 | 11.80% | 32.00% |
| 第2步预测结果指标: | 5840.17 | 76.42 | 60.79 | 14.13% | 21.88% |
9.绘制预测结果
from matplotlib import rcParams
config = {
"font.family": 'serif',
"font.size": 10,
"mathtext.fontset": 'stix',
"font.serif": ['Times New Roman'],
'axes.unicode_minus': False
}
rcParams.update(config)
plt.ion()
for ii in range(n_out):
plt.style.use('cyberpunk')
plt.figure(figsize=(10, 2), dpi=300)
x = range(1, len(predicted_data) + 1)
plt.xticks(x[::int((len(predicted_data) + 1))])
plt.tick_params(labelsize=5)
plt.plot(x, predicted_data[:, ii], linestyle="--", linewidth=0.5, label='predict')
plt.plot(x, Ytest[:, ii], linestyle="-", linewidth=0.5, label='Real')
plt.legend(loc='upper right', frameon=False)
plt.xlabel("Sample points", fontsize=5)
plt.ylabel("value", fontsize=5)
plt.title(f"{ii+1} step of CNN-BiLSTM prediction\nMAPE: {mape(Ytest[:, ii], predicted_data[:, ii])} %")
plt.ioff()
plt.show()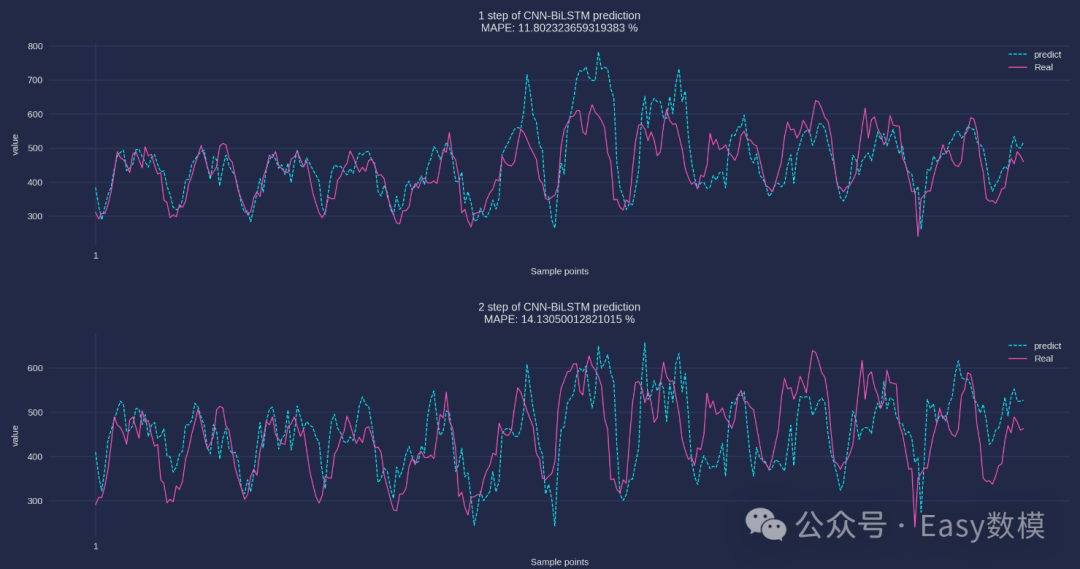
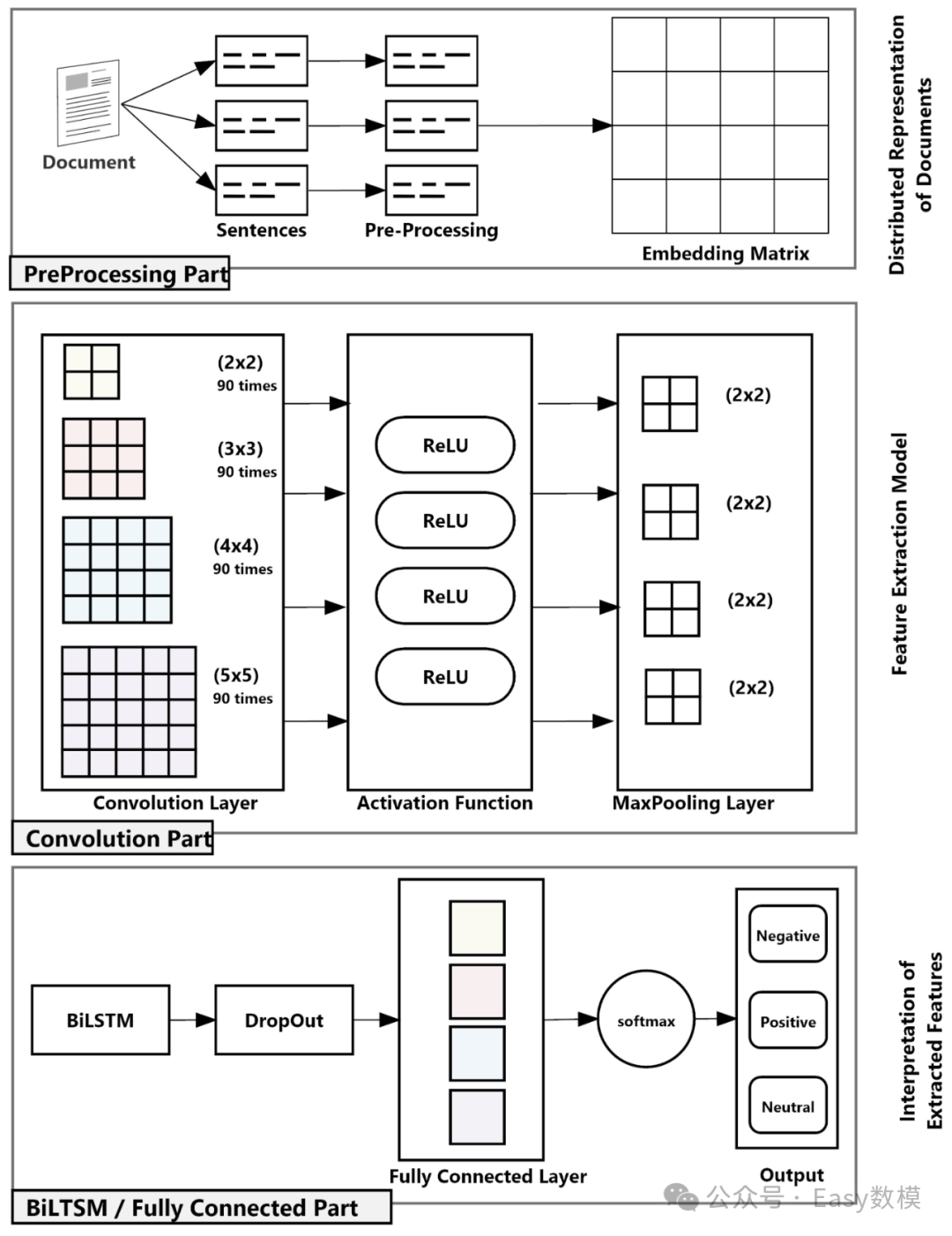
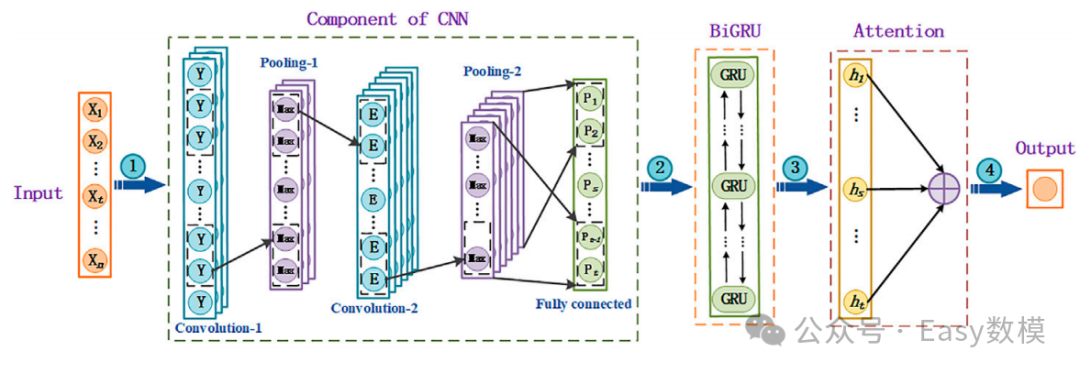
五、基于Attention机制的CNN-RNN组合算法
1. 算法原理
1.1定义与描述
这些算法组合了卷积神经网络(CNN)、循环神经网络(RNN,如GRU、LSTM、BiGRU和BiLSTM)以及注意力机制(Attention),用于在时空数据处理过程中动态关注关键特征,提高预测性能和模型的可解释性。CNN用于提取空间特征,RNN和其变体(GRU、LSTM、BiGRU、BiLSTM)用于提取时间序列特征,而Attention机制则通过为输入序列中的每个元素分配权重,使模型能够聚焦于重要特征。
1.2工作原理
-
CNN提取空间特征:输入数据(如图像或序列)首先经过卷积层,提取数据的局部和全局空间特征,生成特征图。
-
展平与序列处理(RNN/GRU/LSTM/BiGRU/BiLSTM):将特征图展平为一维向量,然后输入到RNN或其变体中。RNN通过不同的门控机制(如GRU的更新门和重置门,LSTM的输入门、遗忘门、输出门)处理时间序列数据,捕捉序列中的时间依赖性和上下文信息。
-
注意力机制(Attention):计算输入序列中每个时间步的注意力权重,模型根据这些权重来动态调整对输入序列不同部分的关注度,确保模型能够聚焦于对最终预测结果有重要贡献的特征。
-
输出层:经过注意力加权的特征被输入到全连接层,通过激活函数生成最终的预测结果。
1.3数理基础
-
卷积操作(CNN):
(I∗K)(x,y)=i∑j∑I(x−i,y−j)⋅K(i,j)其中,I 是输入特征图,K 是卷积核。 -
注意力机制(Attention):
-
注意力权重和上下文向量的计算:
αt=∑kexp(ek)exp(et)et=vTtanh(Whht+Wss)c=t∑αt⋅ht
-
2. 算法结构
模块组成
-
卷积模块(CNN):负责提取空间特征。
-
时间序列处理模块(RNN/GRU/LSTM/BiGRU/BiLSTM):用于学习时间依赖性和上下文信息。
-
注意力模块(Attention):根据注意力权重动态选择关键信息,提升模型对重要特征的提取能力。
-
全连接层:将提取的特征进行组合和映射,输出结果。
网络结构:CNN-BiGRU-Attention
3. 优点与缺点
3.1优点
-
动态特征选择:通过注意力机制,可以让模型聚焦于序列中重要的部分,提升对关键信息的提取能力。
-
强大的时空特征处理能力:结合CNN、RNN和Attention机制,适合处理复杂时空数据,如自然语言处理、视频分析等。
-
模型解释性强:注意力机制可以为模型提供可解释性,帮助理解模型的决策过程。
3.2缺点
-
计算复杂度高:Attention机制的引入增加了计算成本和时间消耗,尤其在大规模数据集上。
-
对硬件要求高:需要更多的计算资源和存储来处理Attention机制的计算。
-
调参复杂:组合模型的复杂性增加了超参数优化的难度,需要大量的实验进行调优。
4. 应用场景
4.1实际应用
-
自然语言处理(NLP):如机器翻译、文本摘要、问答系统等。
-
时间序列分析:如金融预测、能源负荷预测、医疗数据分析等。
-
视频分析和描述生成:如自动驾驶中的场景识别和视频内容生成。
4.2典型案例
-
机器翻译:在长句子和复杂语法的翻译任务中,使用Attention机制提高翻译质量。
-
医疗诊断:在心电图等时间序列医疗数据分析中,利用Attention机制聚焦于关键数据段。
-
推荐系统:在推荐系统中,通过Attention机制提升个性化推荐的准确度和用户体验。
5.python案例
5.1CNN-BiLSTM-Attention代码
-
导入必要的库
import os # 操作系统功能
import math # 数学功能
import pandas as pd # 数据处理与分析
import openpyxl # Excel文件操作
from math import sqrt # 计算平方根
from numpy import concatenate # 数组拼接
import matplotlib.pyplot as plt # 绘图
import numpy as np # 数值计算
from sklearn.preprocessing import MinMaxScaler, StandardScaler, LabelEncoder # 数据预处理
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score # 评估指标
from tensorflow.keras.layers import * # 神经网络层
from tensorflow.keras.models import * # 神经网络模型
from pandas import DataFrame, concat # 数据框操作
import keras.backend as K # Keras后端
from scipy.io import savemat, loadmat # MATLAB文件操作
from sklearn.neural_network import MLPRegressor # 神经网络回归模型
from keras.callbacks import LearningRateScheduler # 学习率调度
from tensorflow.keras import Input, Model, Sequential # Keras模型构建
import mplcyberpunk # 绘图风格
from prettytable import PrettyTable # 表格打印
import warnings
warnings.filterwarnings("ignore") # 忽略警告-
加载和准备数据
dataset = pd.read_csv("电力负荷预测数据1.csv", encoding='gb2312') # 读取CSV文件
print(dataset)
values = dataset.values[:, 1:] # 选择所有行,去除第一列
values = values.astype('float32') # 转换数据类型为浮点数3.定义数据整理函数
def data_collation(data, n_in, n_out, or_dim, scroll_window, num_samples):
res = np.zeros((num_samples, n_in * or_dim + n_out))
for i in range(num_samples):
h1 = values[scroll_window * i: n_in + scroll_window * i, 0:or_dim]
h2 = h1.reshape(1, n_in * or_dim)
h3 = values[n_in + scroll_window * i: n_in + scroll_window * i + n_out, -1].T
h4 = h3[np.newaxis, :]
h5 = np.hstack((h2, h4))
res[i, :] = h5
return res4.数据集划分与归一化
n_in = 5 # 输入步长
n_out = 2 # 输出步长
or_dim = values.shape[1] # 特征维度
num_samples = 2000 # 样本数量
scroll_window = 1 # 滑动窗口大小
res = data_collation(values, n_in, n_out, or_dim, scroll_window, num_samples)
values = np.array(res)
n_train_number = int(num_samples * 0.85)
Xtrain = values[:n_train_number, :n_in * or_dim]
Ytrain = values[:n_train_number, n_in * or_dim:]
Xtest = values[n_train_number:, :n_in * or_dim]
Ytest = values[n_train_number:, n_in * or_dim:]
m_in = MinMaxScaler()
vp_train = m_in.fit_transform(Xtrain)
vp_test = m_in.transform(Xtest)
m_out = MinMaxScaler()
vt_train = m_out.fit_transform(Ytrain)
vt_test = m_out.transform(Ytest)
vp_train = vp_train.reshape((vp_train.shape[0], n_in, or_dim))
vp_test = vp_test.reshape((vp_test.shape[0], n_in, or_dim))5.定义注意力层及CNN-BiLSTM-Attention模型
def attention_layer(inputs, time_steps):
a = Permute((2, 1))(inputs) # 交换维度
a = Dense(time_steps, activation='softmax')(a) # 权重计算
a_probs = Permute((2, 1), name='attention_vec')(a) # 交换回原始维度
output_attention_mul = Multiply()([inputs, a_probs]) # 应用注意力权重
return output_attention_mul
def cnn_bilstm_attention_model():
inputs = Input(shape=(vp_train.shape[1], vp_train.shape[2]))
conv1d = Conv1D(filters=64, kernel_size=2, activation='relu')(inputs)
maxpooling = MaxPooling1D(pool_size=2)(conv1d)
reshaped = Reshape((-1, 64 * maxpooling.shape[1]))(maxpooling)
lstm_out = Bidirectional(LSTM(128, return_sequences=True))(reshaped)
attention_out = attention_layer(lstm_out, time_steps=reshaped.shape[1])
attention_flatten = Flatten()(attention_out)
outputs = Dense(vt_train.shape[1])(attention_flatten)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='mse', optimizer='Adam')
model.summary()
return model
model = cnn_bilstm_attention_model()
history = model.fit(vp_train, vt_train, batch_size=32, epochs=50, validation_split=0.25, verbose=2)6.绘制训练和验证损失曲线
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()7.模型预测与反归一化
yhat = model.predict(vp_test)
yhat = yhat.reshape(num_samples - n_train_number, n_out)
predicted_data = m_out.inverse_transform(yhat)8.评估预测性能
def mape(y_true, y_pred):
record = []
for index in range(len(y_true)):
temp_mape = np.abs((y_pred[index] - y_true[index]) / y_true[index])
record.append(temp_mape)
return np.mean(record) * 100
def evaluate_forecasts(Ytest, predicted_data, n_out):
mse_dic, rmse_dic, mae_dic, mape_dic, r2_dic = [], [], [], [], []
table = PrettyTable(['测试集指标', 'MSE', 'RMSE', 'MAE', 'MAPE', 'R2'])
for i in range(n_out):
actual = [float(row[i]) for row in Ytest]
predicted = [float(row[i]) for row in predicted_data]
mse = mean_squared_error(actual, predicted)
rmse = sqrt(mse)
mae = mean_absolute_error(actual, predicted)
MApe = mape(actual, predicted)
r2 = r2_score(actual, predicted)
table.add_row([f'第{i + 1}步预测结果指标:', mse, rmse, mae, f'{MApe}%', f'{r2 * 100}%'])
return table
print(evaluate_forecasts(Ytest, predicted_data, n_out))9.绘制预测结果
from matplotlib import rcParams
config = {
"font.family": 'serif',
"font.size": 10,
"mathtext.fontset": 'stix',
"font.serif": ['Times New Roman'],
'axes.unicode_minus': False
}
rcParams.update(config)
plt.ion()
for ii in range(n_out):
plt.style.use('cyberpunk')
plt.figure(figsize=(10, 2), dpi=300)
x = range(1, len(predicted_data) + 1)
plt.xticks(x[::int((len(predicted_data) + 1))])
plt.tick_params(labelsize=5)
plt.plot(x, predicted_data[:, ii], linestyle="--", linewidth=0.5, label='predict')
plt.plot(x, Ytest[:, ii], linestyle="-", linewidth=0.5, label='Real')
plt.legend(loc='upper right', frameon=False)
plt.xlabel("Sample points", fontsize=5)
plt.ylabel("value", fontsize=5)
plt.title(f"{ii+1} step of CNN-BiLSTM-Attention prediction\nMAPE: {mape(Ytest[:, ii], predicted_data[:, ii])} %")
plt.ioff()
plt.show()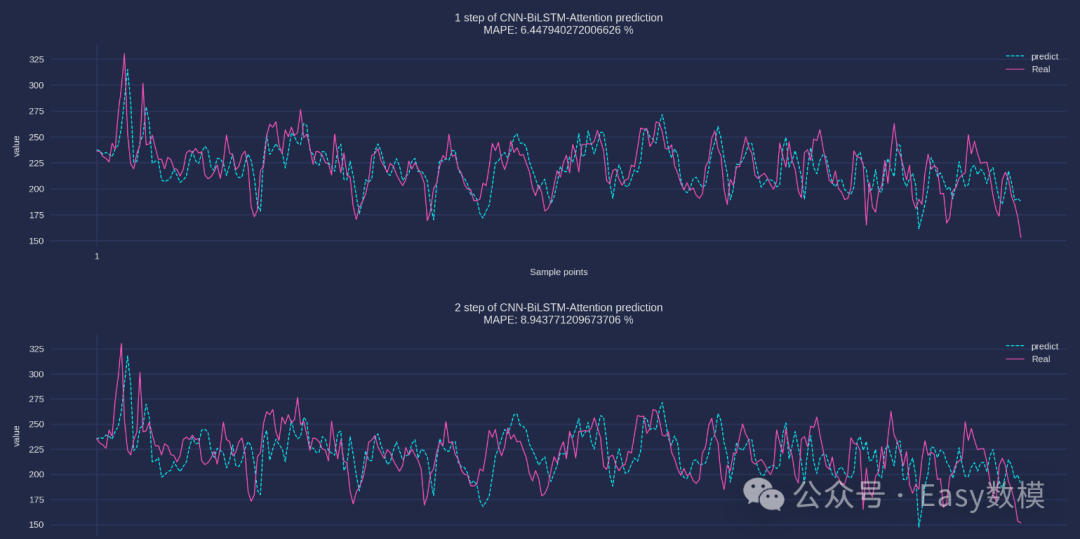
5.2CNN-BiGRU-Attention代码
1.导入必要的库
import os # 操作系统功能
import math # 数学功能
import pandas as pd # 数据处理与分析
import openpyxl # Excel文件操作
from math import sqrt # 计算平方根
from numpy import concatenate # 数组拼接
import matplotlib.pyplot as plt # 绘图
import numpy as np # 数值计算
from sklearn.preprocessing import MinMaxScaler, StandardScaler, LabelEncoder # 数据预处理
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score # 评估指标
from tensorflow.keras.layers import * # 神经网络层
from tensorflow.keras.models import * # 神经网络模型
from pandas import DataFrame, concat # 数据框操作
import keras.backend as K # Keras后端
from scipy.io import savemat, loadmat # MATLAB文件操作
from sklearn.neural_network import MLPRegressor # 神经网络回归模型
from keras.callbacks import LearningRateScheduler # 学习率调度
from tensorflow.keras import Input, Model, Sequential # Keras模型构建
import mplcyberpunk # 绘图风格
from prettytable import PrettyTable # 表格打印
import warnings
warnings.filterwarnings("ignore") # 忽略警告2.读取数据
dataset = pd.read_csv("电力负荷预测数据1.csv", encoding='gb2312')
print(dataset)
values = dataset.values[:, 1:]
values = values.astype('float32') 3.数据整理函数
def data_collation(data, n_in, n_out, or_dim, scroll_window, num_samples):
res = np.zeros((num_samples, n_in * or_dim + n_out))
for i in range(num_samples):
h1 = values[scroll_window * i: n_in + scroll_window * i, 0:or_dim]
h2 = h1.reshape(1, n_in * or_dim)
h3 = values[n_in + scroll_window * i: n_in + scroll_window * i + n_out, -1].T
h4 = h3[np.newaxis, :]
h5 = np.hstack((h2, h4))
res[i, :] = h5
return res4.数据集划分与归一化
n_in = 5
n_out = 2
or_dim = values.shape[1]
num_samples = 2000
scroll_window = 1
res = data_collation(values, n_in, n_out, or_dim, scroll_window, num_samples)
values = np.array(res)
n_train_number = int(num_samples * 0.85)
Xtrain = values[:n_train_number, :n_in * or_dim]
Ytrain = values[:n_train_number, n_in * or_dim:]
Xtest = values[n_train_number:, :n_in * or_dim]
Ytest = values[n_train_number:, n_in * or_dim:]
m_in = MinMaxScaler()
vp_train = m_in.fit_transform(Xtrain)
vp_test = m_in.transform(Xtest)
m_out = MinMaxScaler()
vt_train = m_out.fit_transform(Ytrain)
vt_test = m_out.transform(Ytest)
vp_train = vp_train.reshape((vp_train.shape[0], n_in, or_dim))
vp_test = vp_test.reshape((vp_test.shape[0], n_in, or_dim))5.定义注意力层及CNN-BiGRU-Attention模型
def attention_layer(inputs, time_steps):
a = Permute((2, 1))(inputs)
a = Dense(time_steps, activation='softmax')(a)
a_probs = Permute((2, 1), name='attention_vec')(a)
output_attention_mul = Multiply()([inputs, a_probs])
return output_attention_mul
def cnn_bigru_attention_model():
inputs = Input(shape=(vp_train.shape[1], vp_train.shape[2]))
conv1d = Conv1D(filters=64, kernel_size=2, activation='relu')(inputs)
maxpooling = MaxPooling1D(pool_size=2)(conv1d)
reshaped = Reshape((-1, 64 * maxpooling.shape[1]))(maxpooling)
bigru_out = Bidirectional(GRU(128, return_sequences=True))(reshaped)
attention_out = attention_layer(bigru_out, time_steps=reshaped.shape[1])
attention_flatten = Flatten()(attention_out)
outputs = Dense(vt_train.shape[1])(attention_flatten)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='mse', optimizer='Adam')
model.summary()
return model
model = cnn_bigru_attention_model()
history = model.fit(vp_train, vt_train, batch_size=32, epochs=50, validation_split=0.25, verbose=2)6.绘制训练和验证损失曲线
plt.plot(history.history['loss'], label='train')
# 绘制训练过程中的损失曲线。
# history.history['loss']获取训练集上每个epoch的损失值。
# 'label='train''设置该曲线的标签为'train'。
plt.plot(history.history['val_loss'], label='test')
# 绘制验证过程中的损失曲线。
# history.history['val_loss']获取验证集上每个epoch的损失值。
# 'label='test''设置该曲线的标签为'test'。
plt.legend()
# 显示图例,方便识别每条曲线代表的数据集。
plt.show()
# 展示绘制的图像。7.模型预测与反归一化
yhat = model.predict(vp_test)
# 使用模型对测试集的输入特征(vp_test)进行预测。
# yhat是模型预测的输出值。
yhat = yhat.reshape(num_samples-n_train_number, n_out)
# 将预测值yhat重塑为二维数组,以便进行后续操作。
predicted_data = m_out.inverse_transform(yhat) # 反归一化8.评估预测性能
def mape(y_true, y_pred):
# 定义一个计算平均绝对百分比误差(MAPE)的函数。
record = []
for index in range(len(y_true)):
# 遍历实际值和预测值。
temp_mape = np.abs((y_pred[index] - y_true[index]) / y_true[index])
# 计算单个预测的MAPE。
record.append(temp_mape)
# 将MAPE添加到记录列表中。
return np.mean(record) * 100
# 返回所有记录的平均值,乘以100得到百分比。
def evaluate_forecasts(Ytest, predicted_data, n_out):
# 定义一个函数来评估预测的性能。
mse_dic = []
rmse_dic = []
mae_dic = []
mape_dic = []
r2_dic = []
# 初始化存储各个评估指标的字典。
table = PrettyTable(['测试集指标','MSE', 'RMSE', 'MAE', 'MAPE','R2'])
for i in range(n_out):
# 遍历每一个预测步长。每一列代表一步预测,现在是在求每步预测的指标
actual = [float(row[i]) for row in Ytest] #一列列提取
# 从测试集中提取实际值。
predicted = [float(row[i]) for row in predicted_data]
# 从预测结果中提取预测值。
mse = mean_squared_error(actual, predicted)
# 计算均方误差(MSE)。
mse_dic.append(mse)
rmse = sqrt(mean_squared_error(actual, predicted))
# 计算均方根误差(RMSE)。
rmse_dic.append(rmse)
mae = mean_absolute_error(actual, predicted)
# 计算平均绝对误差(MAE)。
mae_dic.append(mae)
MApe = mape(actual, predicted)
# 计算平均绝对百分比误差(MAPE)。
mape_dic.append(MApe)
r2 = r2_score(actual, predicted)
# 计算R平方值(R2)。
r2_dic.append(r2)
if n_out == 1:
strr = '预测结果指标:'
else:
strr = '第'+ str(i + 1)+'步预测结果指标:'
table.add_row([strr, mse, rmse, mae, str(MApe)+'%', str(r2*100)+'%'])
return mse_dic,rmse_dic, mae_dic, mape_dic, r2_dic, table
# 返回包含所有评估指标的字典。
mse_dic,rmse_dic, mae_dic, mape_dic, r2_dic, table = evaluate_forecasts(Ytest, predicted_data, n_out)
# 调用evaluate_forecasts函数。
# 传递实际值(inv_y)、预测值(inv_yhat)以及预测的步数(n_out)作为参数。
# 此函数将计算每个预测步长的RMSE、MAE、MAPE和R2值。
print(table)#显示预测指标数值9.绘制预测结果
from matplotlib import rcParams
config = {
"font.family": 'serif',
"font.size": 10,# 相当于小四大小
"mathtext.fontset": 'stix',#matplotlib渲染数学字体时使用的字体,和Times New Roman差别不大
"font.serif": ['Times New Roman'],#Times New Roman
'axes.unicode_minus': False # 处理负号,即-号
}
rcParams.update(config)
plt.ion()
for ii in range(n_out):
plt.rcParams['axes.unicode_minus'] = False
# 设置matplotlib的配置,用来正常显示负号。
# 使用赛博朋克风样式
plt.style.use('cyberpunk')
# 创建一个图形对象,并设置大小为10x2英寸,分辨率为300dpi。
plt.figure(figsize=(10, 2), dpi=300)
x = range(1, len(predicted_data) + 1)
# 创建x轴的值,从1到实际值列表的长度。
plt.xticks(x[::int((len(predicted_data)+1))])
# 设置x轴的刻度,每几个点显示一个刻度。
plt.tick_params(labelsize=5) # 改变刻度字体大小
# 设置刻度标签的字体大小。
plt.plot(x, predicted_data[:,ii], linestyle="--",linewidth=0.5, label='predict')
# 绘制预测值的折线图,线型为虚线,线宽为0.5,标签为'predict'。
plt.plot(x, Ytest[:,ii], linestyle="-", linewidth=0.5,label='Real')
# 绘制实际值的折线图,线型为直线,线宽为0.5,标签为'Real'。
plt.rcParams.update({'font.size': 5}) # 改变图例里面的字体大小
# 更新图例的字体大小。
plt.legend(loc='upper right', frameon=False)
# 显示图例,位置在图形的右上角,没有边框。
plt.xlabel("Sample points", fontsize=5)
# 设置x轴标签为"样本点",字体大小为5。
plt.ylabel("value", fontsize=5)
# 设置y轴标签为"值",字体大小为5。
if n_out == 1: #如果是单步预测
plt.title(f"The prediction result of CNN-BiGRU-Attention :\nMAPE: {mape(Ytest[:, ii], predicted_data[:, ii])} %")
else:
plt.title(f"{ii+1} step of CNN-BiGRU-Attention prediction\nMAPE: {mape(Ytest[:,ii], predicted_data[:,ii])} %")
# plt.xlim(xmin=600, xmax=700) # 显示600-1000的值 局部放大有利于观察
# 如果需要,可以取消注释这行代码,以局部放大显示600到700之间的值。
# plt.savefig('figure/预测结果图.png')
# 如果需要,可以取消注释这行代码,以将图形保存为PNG文件。
plt.ioff() # 关闭交互模式
plt.show()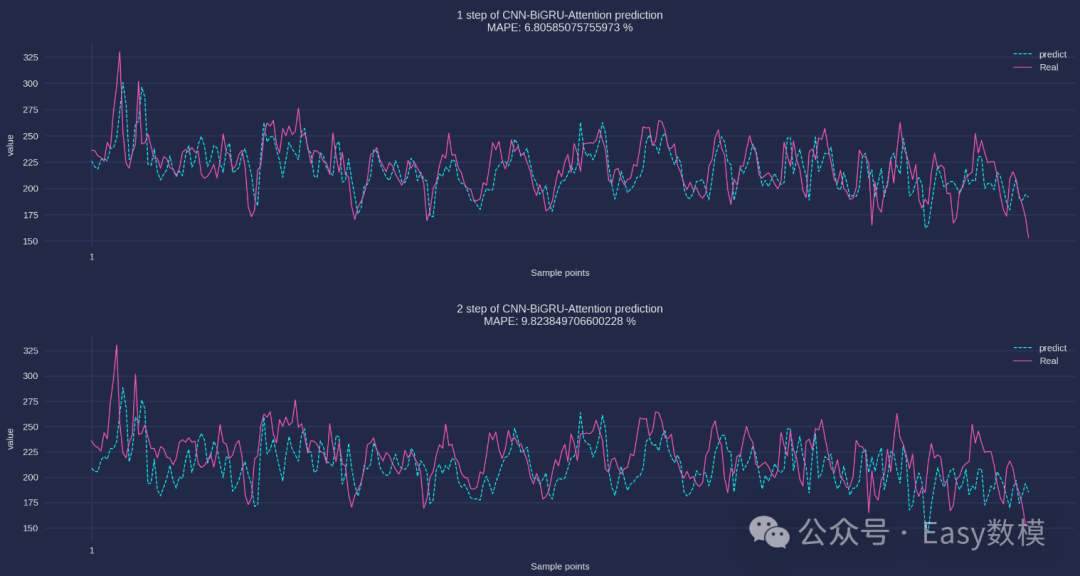

参考文献
Yu J, Zhang X, Xu L, et al. A hybrid CNN-GRU model for predicting soil moisture in maize root zone[J]. Agricultural Water Management, 2021, 245: 106649.
Wang J, Yu L C, Lai K R, et al. Dimensional sentiment analysis using a regional CNN-LSTM model[C]//Proceedings of the 54th annual meeting of the association for computational linguistics (volume 2: Short papers). 2016: 225-230.
Rhanoui M, Mikram M, Yousfi S, et al. A CNN-BiLSTM model for document-level sentiment analysis[J]. Machine Learning and Knowledge Extraction, 2019, 1(3): 832-847.


















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









