






目录
论文链接:https://arxiv.org/abs/2305.07243
项目工程(源):https://github.com/neonbjb/tortoise-tts
项目工程(已封装):https://git.ecker.tech/mrq/ai-voice-cloning
摘要
近年来,自回归变压器和ddpms的应用彻底改变了图像生成领域。这些方法将图像生成的过程建模为逐步的概率过程,并利用大量的计算和数据来学习图像分布。这种提高性能的方法不必局限于图像。本文描述了一种将图像生成领域的进步应用于语音合成的方法。TorToise - 一种富有表现力的多语音文本到语音系统。
背景
文本转语音
文字转语音(TTS)研究领域主要局限于在相对较小的数据集上开发高效模型。这个选择是由以下几点驱动的:1. 希望建立可大规模部署的高效语音生成模型,因此必须具有较高的采样率。2. 缺乏非常大的、已转录的语音数据集。3. 在TTS中传统使用的编码器-解码器模型架构面临扩展的挑战。
Neural MEL Inverters
大多数现代文字转语音系统在编码为MEL光谱图的语音数据上运行。对于神经网络来说,选择这种编码空间的主要原因是其具有高度的空间压缩性。例如,Tacotron使用的MEL配置在22kHz采样的原始音频波形数据上实现了256倍的压缩,但又包含了大部分原始数据的信息。因此,许多研究致力于寻找将MEL光谱图高质量地解码回音频波形的方法。这种合成器通常被称为"声码器",但在本文中更通用地称为"MEL反演器"。基于神经网络构建的现代MEL反演器非常复杂,可以生成几乎和实际录音波形无法区分的音频波形,且在训练集以外具有很高的泛化能力。作者利用Univnet(Kim,2021)的实现作为其文字转语音系统的最后阶段,以便利用这些研究成果。
图像生成
尽管TTS系统主要关注延迟问题,但在其他领域并非如此。例如,在图像生成方面,更多的关注点在于训练能够生成高质量结果的模型,而不考虑采样时间。为了这篇文章的目的,作者深入研究了以下两个研究领域:
DALL-E
DALL-E(Ramesh等人,2021)展示了如何将自回归解码器应用于文本到图像生成。这尤其吸引人,因为NLP领域已经投入大量研究来扩展仅包含解码器的模型。然而,DALL-E仍然存在两个重要问题:首先,它依赖于完整序列的自注意力机制,其计算和内存需求为O(N^2),其中N为序列长度。在处理图像或音频等序列长度较大的模态时,这尤其令人头疼。其次,传统的自回归方法要求在离散域中操作。图像被编码为离散标记序列,使用量化自动编码器。然后,DALL-E使用自回归先验模型对这些标记序列进行建模。这是DALL-E在表达能力方面的优势,但它带来了一个代价,即需要一个解码器将这些图像标记转换回组成图像的像素值。我认为,DALL-E所使用的学习式VQVAE解码器是其大部分样本表现出模糊不清的原因。
DDPMs
生成模型领域长期以来一直被表现为均值寻求行为(导致模糊)或模态崩溃(导致多样性或泛化能力不足)的模型困扰。最近,去噪扩散概率模型(DDPMs(Ho等人,2020年))成为了第一种能产生清晰、连贯和多样性图像的生成模型。研究表明,这些模型非常擅长利用低质量的引导信号来重建这些引导信号衍生的高维空间。换句话说,它们在超分辨率方面表现出色。然而,DDPMs有两个重要的注意事项:1. 传统的DDPM方法依赖于在采样开始前已知的固定输出形状。具体来说,与本文相关的一个例子是,DDPMs无法学会将文本转换为音频信号,因为它们无法解决文本与音频之间的隐含对齐问题。2. DDPMs必须在多个迭代中采样。这个采样过程消耗大量计算资源,意味着从DDPM中采样总是会带来显著的延迟成本。
Re-ranking
DALL-E引入了一种名为“重新排序”的处理自回归模型输出的方法。该过程从自回归模型中随机抽样,并从k个输出中选择最高质量的输出用于下游任务。这样的操作需要一个强大的判别器:一个能区分好的文本/图像配对和坏的配对的模型。DALL-E使用了CLIP(Radford等人,2021年),这是一个通过对比文本和图像配对目标进行训练的模型。
方法
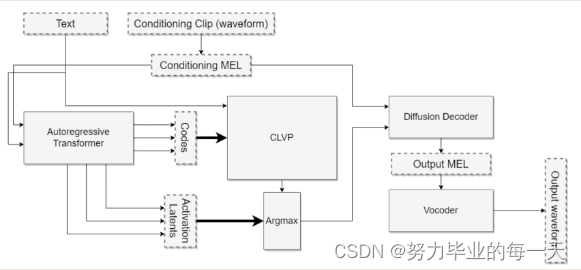
1.自回归模型擅长在不对齐的领域(如视觉、文本和语音)之间进行转换。
2.DDPMs在连续域中操作,使它们能够对富有表现力的模态进行建模。
这两种类型的模型都已经展示出了在额外计算和数据的支持下提高性能的能力。当面临生成连续数据(如语音谱图或图像)等问题时,这两种方法的结合可能具有一些明显优势。具体而言,在推理过程中,自回归模型将用于将文本标记序列转换为表示输出空间的标记序列(在例子中,为语音标记)。接下来,DDPM将用于将这些标记解码成高质量的语音表示。
将自回归+DDPM应用于TTS
为了构建之前提议的系统,我们需要训练以下神经网络:
-
一个自回归解码器,根据文本预测语音标记的概率分布。
-
一个类似于CLIP的对比模型,用于对自回归解码器的输出进行排名。
-
一个DDPM,可以将语音标记转换回语音谱图。
所有这些网络的架构和训练过程大都遵循各自文献中的流程。详细信息可以在B中找到。
在实现这个系统时,需要注意以下几点:
-
对于自回归解码器,可以使用现有的模型,如Transformer、LSTM等,训练时需要根据文本输入预测输出的语音标记。
-
对于对比模型,可以参考OpenAI的CLIP实现。这个模型可以同时处理文本和语音标记,并学会为不同的输出提供排序。训练时可以利用成对的文本和语音数据。
-
DDPM部分可以参考现有的Denoising Diffusion Probabilistic Models实现。训练时需注意输入和输出分别为语音标记和对应的语音谱图,以便在推理阶段将标记解码为实际语音。
通过结合这些组件,我们可以构建一个端到端的文本到语音系统,它可以生成连续的语音数据,同时保留文本和语音之间的潜在关系。这种方法充分利用了自回归模型和DDPM的优势,旨在实现更自然和高质量的语音生成。
调节输入
TorToise的一个独特设计选择是为自回归生成器和DDPM提供一个额外的输入,我称之为语音调节输入。语音调节输入以目标说话者的一个或多个音频片段为起点。这些片段被转换为MEL语谱图,并通过一个由自注意力层堆叠构成的编码器进行处理。自回归生成器和DDPM都有各自的调节编码器,这两个编码器与其各自的网络一起学习。这些层的输出经过平均,得到一个单独的向量。对所有编码过的调节片段的向量再次进行平均,然后将其作为输入输入到自回归或调节网络中。
调节输入背后的直觉是,它为模型提供了一种推断说话者的声音特征(如音调和韵律)的方法,从而大大减小了与给定文本输入对应的可能语音输出的搜索空间。这样,根据所提供的语音样本,生成器和DDPM可以在生成语音时模仿说话者的声音特点,以实现更自然、语调和韵律更接近目标的语音生成效果。
"TorToise 技巧"
在大部分的训练过程中,DDPM被训练为将离散的语音编码转换为MEL语谱图。当这个过程收敛后,我对DDPM进行微调,使用来自AR模型输出的自回归潜在空间替代语音编码。这个过程在B部分有详细描述。这里的逻辑是,AR潜在空间在语义上比离散标记丰富得多。通过在这个潜在空间上进行微调,我们提高了下游扩散模型的效率。我将这个过程与近期的研究类比,该研究表明,在冻结文本编码器条件下训练解码器模型可以显著提高效率。这种微调是我对各种模型训练过程进行的调整中,对模型输出质量贡献最大的因素之一。
CLVP(改自CLIP)
正如前面提到的,从生成模型中获取富有表现力的输出的一个好策略是使用定性判别器对多个输出进行重新排序,然后仅选择最优的输出。DALL-E就是使用CLIP来实现这个功能的。这种用于CLIP的方法也可以应用于语音:毕竟,绝大多数的TTS数据集只是音频片段和文本的配对。通过在对比设置中对这些配对进行建模训练,模型就能成为一个优秀的语音判别器。对于TorToise,我训练了对比语言-语音预训练Transformer(Contrastive Language-Voice Pretrained Transformer,简称CLVP)。它具有很多与CLIP相同的属性,但值得注意的是,它作为一个评分模型,用于重新排序AR模型的TTS输出。
为了使这项工作在推理中能高效地进行,作者训练了CLVP,以便将离散化的语音标记与文本标记配对。这样,CLVP可以在不调用昂贵的扩散模型的情况下,重新排序多个AR输出。这为在保持高质量输出的同时降低推理成本提供了可能性。
训练
这些模型在1年的时间里,在一个包含8个NVIDIA RTX-3090的小集群上进行了训练。有关这些模型如何训练的具体细节可以在B部分找到。
在这样的硬件配置下,训练需要耗费大量时间和计算资源。通常,训练高质量的TTS模型可能需要数周或数月的时间。为了使模型收敛并达到良好的性能,可能需要进行大量的超参数调整和实验。尽管硬件和训练时间的需求较高,但这对于实现高质量的语音生成和模型改进是必要的。
值得注意的是,开发这样一个包含多个组件的系统可能需要跨多个领域的专业知识,如自然语言处理、语音信号处理和概率建模等。此外,实时性和推理速度在实际应用中起着关键作用,可能需要对模型结构进行进一步优化以降低延迟和计算成本。
VQVAE
与 TorToise 一起使用的 VQVAE 与原始的 van der Oord 等人提出的 VQVAE 最为相似。它在 MEL 频谱图上进行操作。它由一个小型残差卷积网络组成,该网络将频谱图额外压缩 4 倍,并生成一个包含 8192 个 tokens 的码书。在训练 VQVAE 时,作者发现更大的批量大小会降低重建损失,因此为其基础设施使用了非常大的批量大小。输入样本被限制为 40960 个 PCM 读数,即 2 秒钟的音频。训练 VQVAE 的主要瓶颈是数据加载器。

VQVAE 的训练曲线。Y 轴是对数对数尺度的 MSE 损失。X 轴是训练步骤的数量。

表1:VQVAE模型细节和超参数
Autoregressive Prior
AR 解码器使用 bog-standard GPT-2 架构,通常遵循 DALLE-1 论文的训练指令。与 DALL-E 不同,只使用了密集的自注意力。提示组装如下:

语音条件编码是通过一个单独的编码器学习的,该编码器接收相关片段(同一个人讲话的另一个片段)的 MEL 频谱图,并生成一个放置在注意力上下文前面的单一向量嵌入。每个训练样本生成两个编码,它们被平均在一起。条件编码器的最大输入长度为 132,300 个样本,或 6 秒钟的音频。使用学习到的位置嵌入。MEL tokens 和文本 tokens 分别具有自己的位置参数。文本输入未填充,MEL tokens 右填充以使每个批次的序列长度一致。最大序列长度为 402 个文本 tokens + 604 个 MEL tokens。出于效率原因,在训练的前半部分,模型只接收不超过 6 秒钟的音频片段。在此之后,音频片段长度可达完整长度(27 秒)。

log-log 量表的早期训练曲线。Y 轴是 MEL 标记的交叉熵损失。X 轴是训练步骤的数量。由于在线更改,不包括训练和微调的长尾,这些更改是在曲线中添加不可重现的噪声。

AR 先验细节和超参数
在训练自回归解码器收敛后,作者在LibriTTS和HIFITTS的干净音频数据集上对其进行微调。
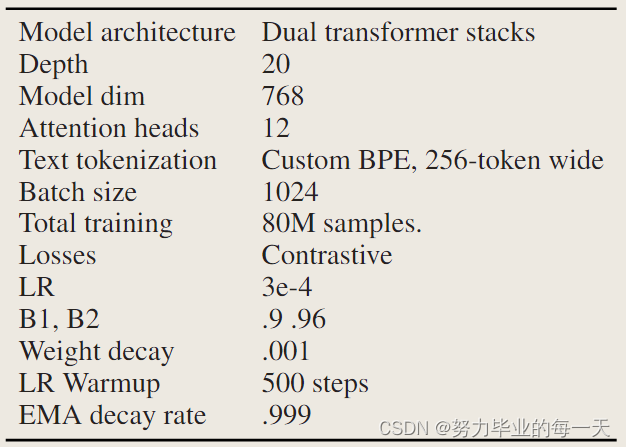
CLVP
原始的 DALLE 通过为给定的文本提示解码大量图像,然后将这些图像输入到 CLIP 中。CLIP 认为最接近输入文本的图像被用作最终输出。在 TorToise 中继续遵循这一思路,原因将在结果部分变得明显。作者构建了一个非常类似于 CLIP 的简单模型,称之为“对比语言-声音预训练”模型(Contrastive Language-Voice Pretrained,CLVP)。和 CLIP 一样,此模型为文本/语音对生成距离度量。CLVP 使用类似于 CLIP 文本编码器的架构,不过它使用了两个编码器:一个用于文本 tokens,另一个用于 MEL tokens。两个编码器中的 tokens 以 15% 的比率随机丢弃。使用固定位置嵌入。最大文本输入长度为 350 个 tokens(实际上从未见过)。最大 MEL token 输入长度为 293,即 13 秒钟的音频。

log-log 尺度上 CLVP 的后期训练曲线。Y 轴是交叉熵损失。X 轴是样本数。早期的训练曲线会丢失。
CLVP训练细节和超参数
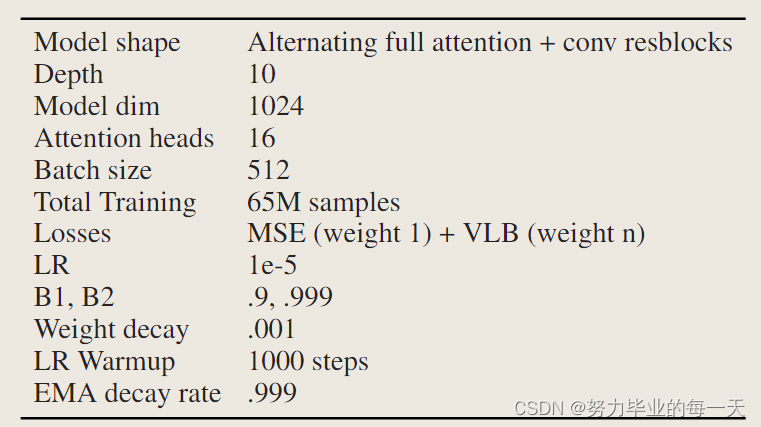
Diffusion Decoder
扩散模型使用一个定制的架构,将残差卷积与密集自注意力相结合。它与用于 DDPM 的传统 U-Net 模型最为相似,但不包括任何上采样或下采样。扩散模型接收 3 个条件源:时间步信号,它调节网络使用的组规范的缩放和偏移。一个语音条件信号,它也调节组规范的缩放和偏移。自回归模型的最终激活。
在训练扩散模型过程中,我尝试了几种不同的架构和条件类型,最终选择了这个方案。这包括:
架构:尝试了一个带注意力机制的“传统”U-net模型。全注意力网络在Frechet距离评估中表现明显更好。而不是使用MEL数据,而是操作PCM数据。这需要非常小的上下文窗口,而且仍然需要花费大量时间进行训练。解码MEL并使用语音合成器可以获得明显更好的质量。为了确保与现有的扩散噪声调度兼容,我对输入的MEL数据进行了重新缩放,使其落在[-1,1]区间内。比较解码MEL tokens和AR激活值。在AR激活值上进行训练成本较高,因为在每个训练步骤中,您需要通过AR网络进行前向传播。然而,基于AR激活值进行训练是扩散网络设计决策中对输出质量影响最大的因素。像将文本放在注意力上下文中这样的技巧可能会在某种程度上削弱这种优势。与图像扩散模型类似,利用无分类器引导对于高质量输出非常重要。在TorToise的情况下,我对语音条件信号和AR模型的激活值进行了引导。在训练过程中,有15%的时间,这两个信号都被丢弃并替换为学习到的嵌入向量。
在训练扩散解码器时,输入音频随机裁剪为220,500个样本,即10秒钟的音频。条件输入被裁剪为102,400个样本,即5秒钟的音频。虽然TorToise堆栈的其余部分在22kHz的音频采样率下运行,扩散解码器输出的MEL光谱图是根据24kHz的音频计算的。这种差异仅为确保与预先训练的Univnet语音合成器的兼容性,模型堆栈使用的是这种语音合成器,并非出于性能方面的原因。
 扩散模型损失,log-log 尺度。Y 轴:MSE 损失,X 轴:训练样本。
扩散模型损失,log-log 尺度。Y 轴:MSE 损失,X 轴:训练样本。
扩散解码器细节和超参数
推理过程
一旦该框架的四个模型完全训练完成,推理过程如下:
-
将条件输入和文本输入到自回归模型中并解码出大量输出候选项。
-
使用CLVP为每个语音候选项和文本之间生成相关性分数。
-
选择排名前k的语音候选项,针对每个候选项:
-
使用DDPM解码成MEL光谱图。
-
使用常规的语音合成器将其转换为波形。
-
在解码自回归模型时,使用P=.8、重复惩罚=2和softmax温度=.8的核采样。
从DDPMs中采样是一个研究得很多且不断变化的领域。在设计TorToise时,作者发现在质量和推理速度之间取得最佳平衡的采样配置如下:
-
算法:DDIM(Song et al., 2022)
-
调度:线性
-
采样步骤:64
-
无条件引导常数:2
数据集
因为作者的目标是训练一个本质上是大型语言模型的模型,所以作者需要大量的数据。作者从LibriTTS(Zen等人,2019)和HiFiTTS(Bakhturina等人,2021)数据集开始,这两个数据集合并后包含了896小时的转录语音。作者构建了一个额外的“扩展”数据集,包含从互联网上的有声书和播客中获取的49,000小时的语音音频。官方的LibriTTS测试拆分被用于验证目的。
作者独立地构建了一个由从网络上抓取的有声书和播客组成的扩展TTS数据集。这些数据在500毫秒的静音处进行切分,保留5-20秒之间的任何音频片段。然后,作者通过一个其训练的分类器管道处理这些片段,删除有背景噪音、音乐、质量较差(如电话通话)、多个人同时说话和混响的音频。由于磁盘空间限制,作者不得不限制抓取的数量。最终结果是得到了49,000小时的清洗过的音频片段。作者使用wav2vec2-large模型对这个数据集进行了转录。我个人对这个模型进行了微调,以预测标点符号,因为引号、逗号和感叹号对于生成语音非常重要,但通常不包括在语音识别模型的训练中。微调是在LibriTTS和HiFiTTS数据集上进行的,预训练模型权重和转录脚本可以在这里找到。
实验
文本到语音系统很难进行实验性比较,因为许多最先进的系统是闭源的,可供比较的样本很少。为此,作者构建了自己的评估套件,它使用CLVP在真实样本和生成样本之间生成一个距离度量,类似于图像使用的FID分数。作者还使用开源的wav2vec模型来表征语音片段的“可理解性”。作者已经在这里将这项工作开源。除此之外,可以在这里找到由TorToise生成的样本和其他论文生成的样本之间的比较。
结论
TorToise是最近使用通用模型架构的一系列最先进突破的最新成果。几乎没有TorToise的一部分是专门为音频处理设计的,然而它在真实性方面胜过了所有之前的TTS模型。它通过以下方式实现了这一目标:
-
采用通用架构,如transformer层堆栈。
-
利用大量高质量的数据集。
-
在较大规模和高批量大小下进行训练。
通过遵循上述3点,作者从这个项目中得到的主要启示是结果的强大程度。作者认为,任何数字化方式都可能受到使用这个框架的生成建模的影响。
未来工作
以下是未来在TorToise基础上进行工作时进行的架构调整建议:
-
限制VQVAE码表嵌入维度。实验证明,这可以显著提高性能。
-
相对位置编码。自回归模型使用固定位置编码,限制了其生成的语音总量。使用相对编码将允许任意长度序列。
-
在更大的批量大小上训练CLVP。对比模型受益于极大的批量大小。
-
对更长的音频序列进行CLVP训练。CLVP只看到过13秒的剪辑,这可能是重新排名较长样本效果不佳的原因。
-
扩散解码器架构。扩散解码器是一个省略前馈块的注意力网络。回顾起来,这是一个糟糕的设计决策,应该包含前馈块。
-
以24kHz的速度训练整个模型堆栈,或以22kHz的采样率重新训练Univnet。
-
更长时间地训练更多数据。TorToise的训练曲线表明,我们离过拟合还很远。只要训练更长时间,很可能就能改善结果。

















 1390
1390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











