







MLOps: From Model-centric to Data-centirc AI 吴恩达讲座
(一)
AI system = Code + Data
Data id food for AI
80%准备工作
source and prepare high quality data
20%具体操作 动作
train a model
(二)
Lifecycle of an ML Project
- Scope project (define project)
- Collect data (define and collect data)
- train model (training, error analysis & iterative improvement迭代改进)
- deploy in production (deploy部署, monitor监督 and maintain 维护system)
部署生产中可能会更新模型或者收集更多的数据
(三)scope project
making data quality systematic: MLOps (machine learning operations)
model-centirc view
collect what data you can, and develop a model good enough to deal with the noise in the data.
hold the data fixed and iteratively improve the code/model.
data-centric view
the consistency of the data is paramout. use tools to improve the data quality; this will allow mutiple model to do well.
hold the code fixed and iteratively improve the data.
(三)collect data
small data and label consistently
在小数据集上,clean labels更加重要(一致性 consistent)
10,000训练样例
两种办法: 清洗数据或者扩大训练数据集
(四)train model
making it systematic - iteratively improving the data:
· train a model
· error analysis to identify the types of data the algorithm does poorly on 某个数据集
· either get more of that data via data augmentation, data generation or data collection (change inputs x) or give more consistent definition for labels if they were found to be ambiguous(change labels y)
(五)deploy
monitor performance in deployment , and flow new data back for continuous refinement of model.
· systematically check for concept drift / data drift (performance degradation性能下降)
· flow data back to retrain / updata model regularly
(六)
from big data to good data
MLOps’ most important task: ensure consistently high-quality data in all phases of the ML project lifecycle.
good data is :
- defined consistently(definition of labels y is unambiguous)标签定义是明确的,一致性的【个人认为这点很重要,在本科阶段做的英语长难句大创项目中,我们在标注英语句子制定标注规范的时候就遇到标签定义不明确的问题,导致后续标注出现了很多问题,训练效果也不好。】
- cover of important cases(good coverage of inputs x)覆盖重要的案例,输入要全面
- has timely feedback from production data(distribution covers data drift and concept drift)及时从数据产品中得到反馈,主要包括数据漂移和概念漂移。concept drift指的是label的分布或定义发生了变化,data drift表示特征的分布发生了变化。
- sized appropriately 合适的数据规模
important frontier:
MLOps tools to make data-centric AI an efficient and systematic process. 类似数据里的git平台工具
论文: dataperf :benchmarks for data-centric ai development
摘要
机器学习(ML)的研究一般集中在模型上,而最突出的数据集被用于日常的机器学习任务,而不考虑这些数据集对潜在问题的广度、难度和忠实度。忽视数据集的基本重要性导致了现实应用中数据级联存在的主要问题,以及数据集驱动的模型质量标准饱和,阻碍了
研究的发展。为了解决这个问题,我们提出了 DataPerf,一个评估机器学习数据集和数据集工作算法的基准包。我们打算启用“数据棘轮”,其中训练集将有助于评估相同问题上的测试集,反之亦然。这种反馈驱动的策略将产生一个良性循环,加速以数据为中心的人工智能的发展。MLCommons 协会将维护 DataPerf
处理数据的流程框架
为了了解数据集的范围、质量和局限性,加快后续的改进,本文定义了 DataPerf 基准套件,它是任务、度量和规则的集合。我们以当今复杂的以数据为中心的开发流水线为例,抽象出一部分我们认为是主要瓶颈的具体任务。图展示了一个这样的管道。为了开发高质量的机器学习应用程序,用户通常依赖于一组以数据为中心的操作来提高数据质量,并在考虑到模型所产生的错误的情况下,重复以数据为中心的迭代来战略性地改进这些操作。DataPerf 的目标是捕捉这种以数据为中心的管道的主要阶段,以提高机器学习的数据质量。基准测试的例子包括数据调试、数据评估、培训和测试集的创建,以及涵盖一系列机器学习应用程序的选择算法。
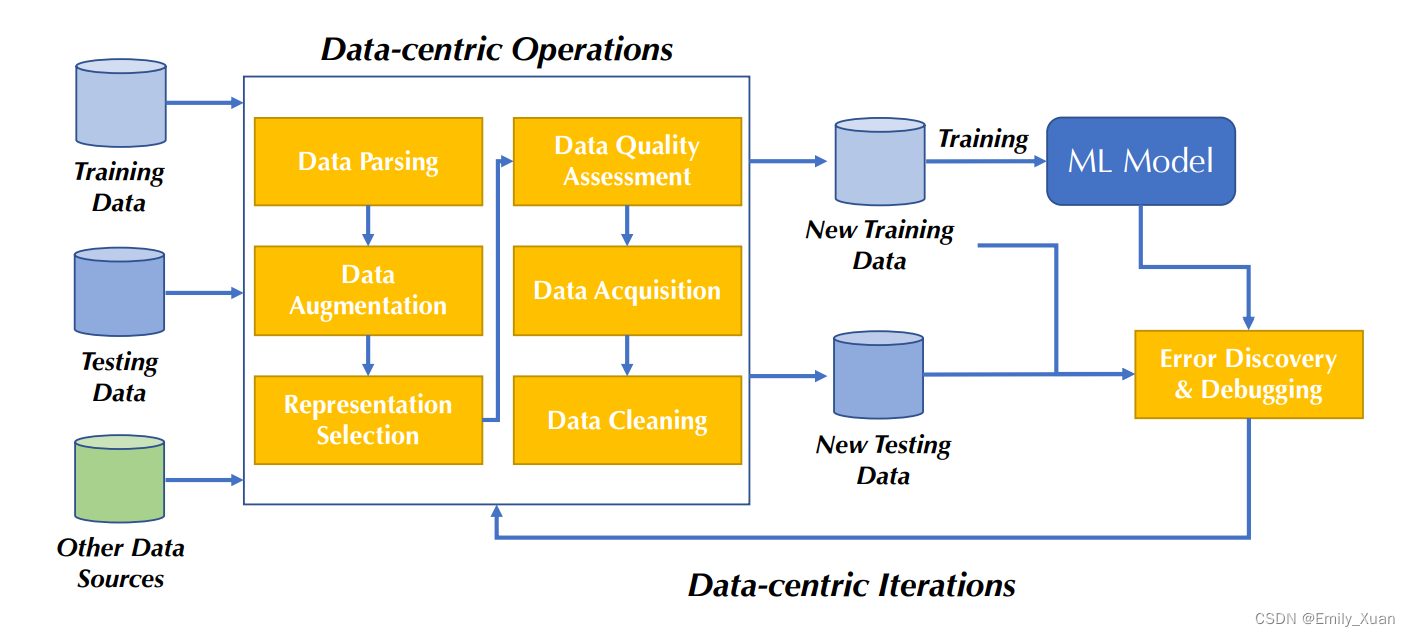
DataPerf 是一种科学仪器,用于系统地测量各种机器学习任务的训练和测试数据集的质量,并测量构造这些数据集的算法的质量。它的基准、度量、规则、排行榜和挑战旨在加速以数据为中心的人工智能。其目的是培养数据和模型基准,从而开发一个机器学习解决方案。
图的说明:为了开发高质量的机器学习应用程序,用户通常依赖于一组以数据为中心的操作来提高数据质量,并在考虑到模型所产生的错误的情况下,重复以数据为中心的迭代来战略性地细化这些操作。DataPerf 的目标是对这种以数据为中心的管道的所有关键阶段进行基准测试,以提高机器学习的数据质量。
benchmark suite
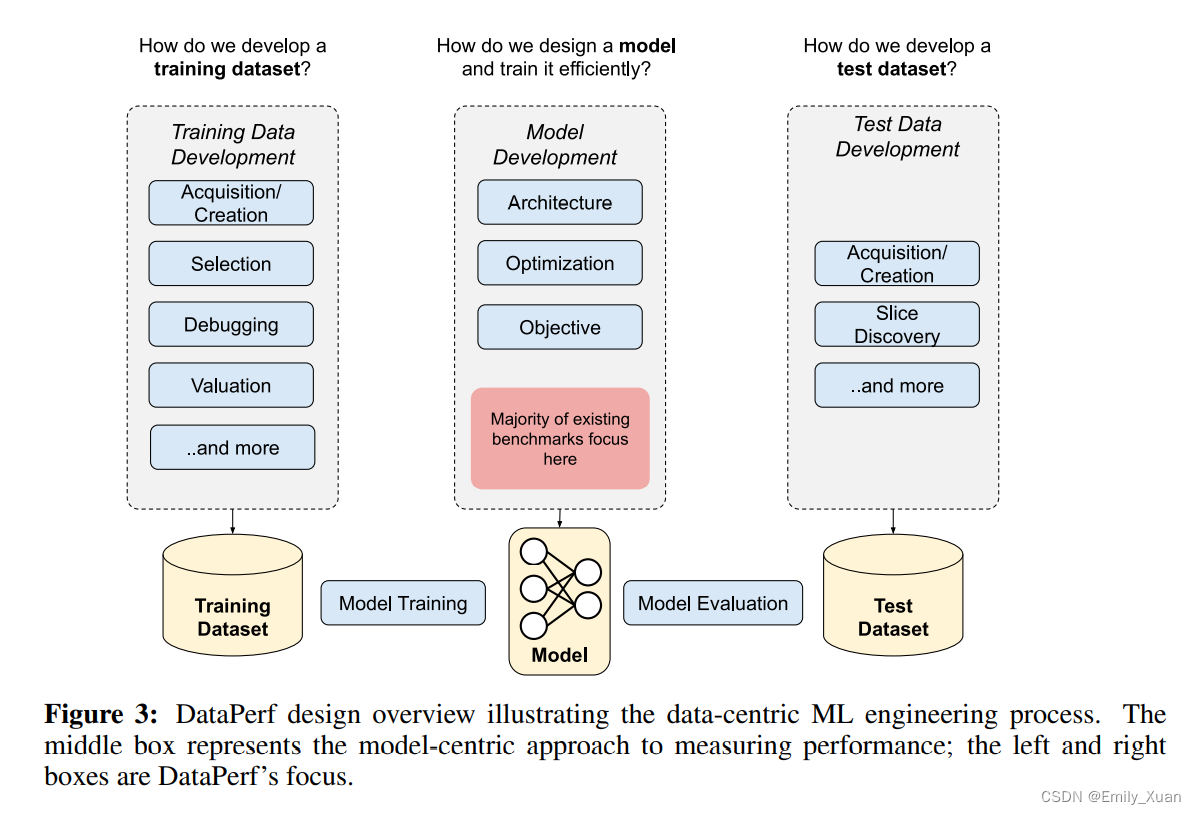
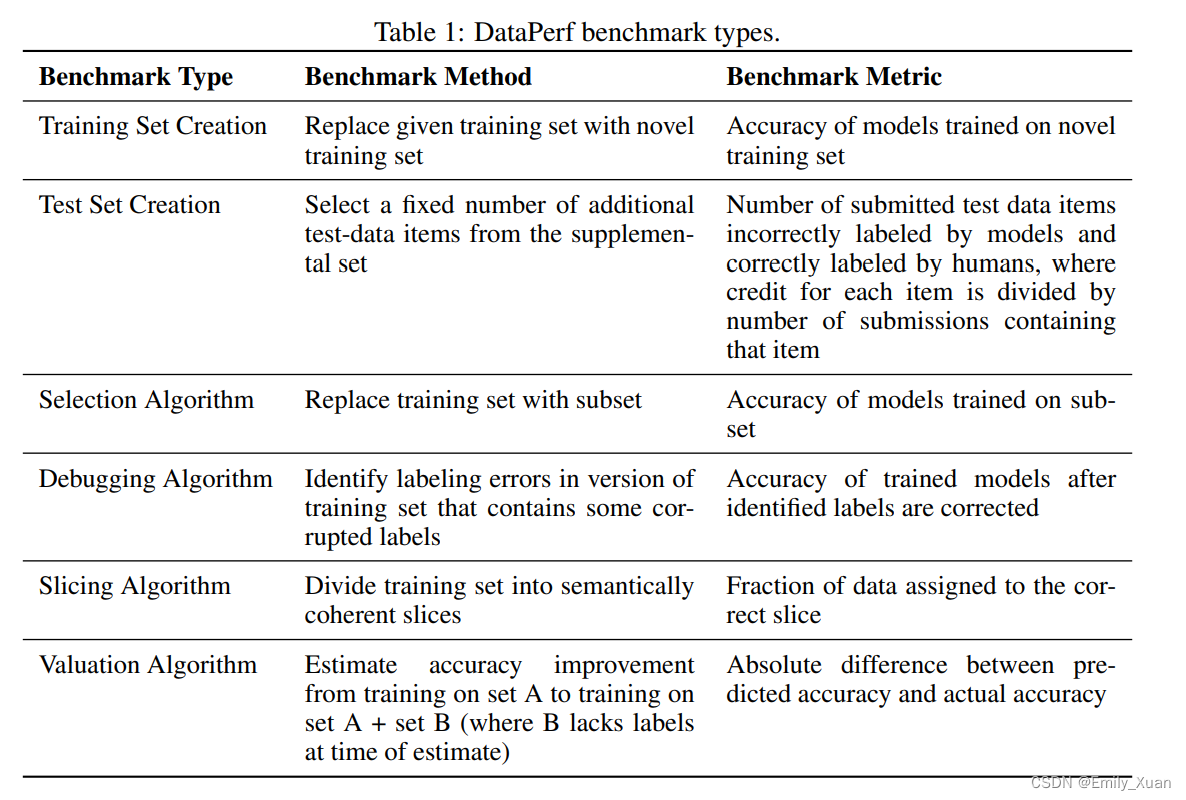
论文:what can data-centric AI learn from data and ML engineering?
- 数据和人工智能应用程序需要不断地运行和训练,而不是仅仅一次。
- 生产部署工作流通常以代码为中心,而不是以模型或数据为中心。
- 数据监控必须是可操作的。
- 对于版本控制代码和数据的端到端支持非常有用。
- 一些应用程序不允许向人工注释器或开发者显示数据。














 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









