







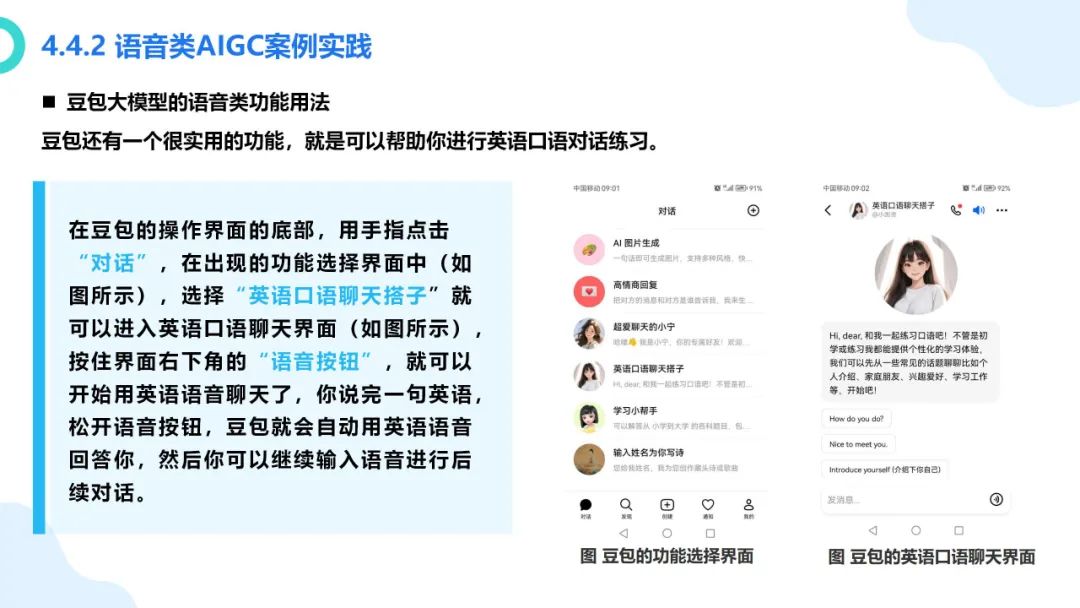
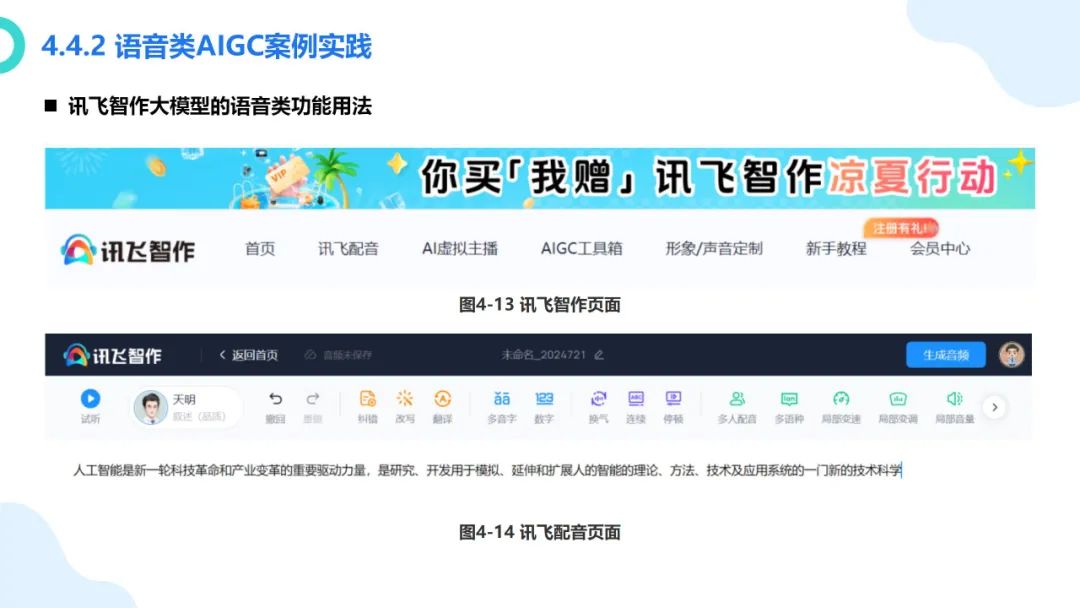
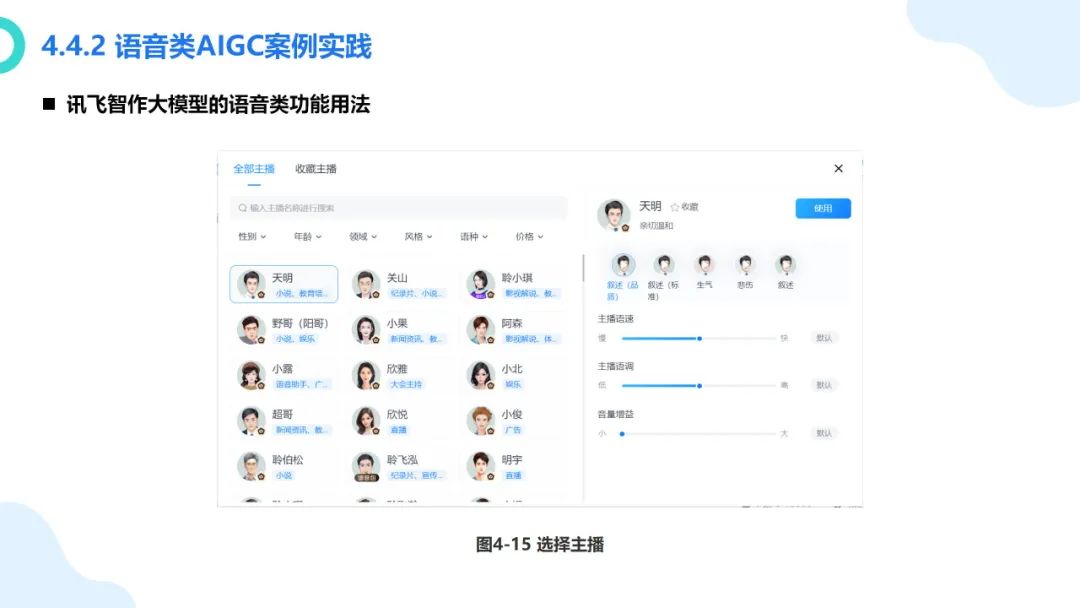
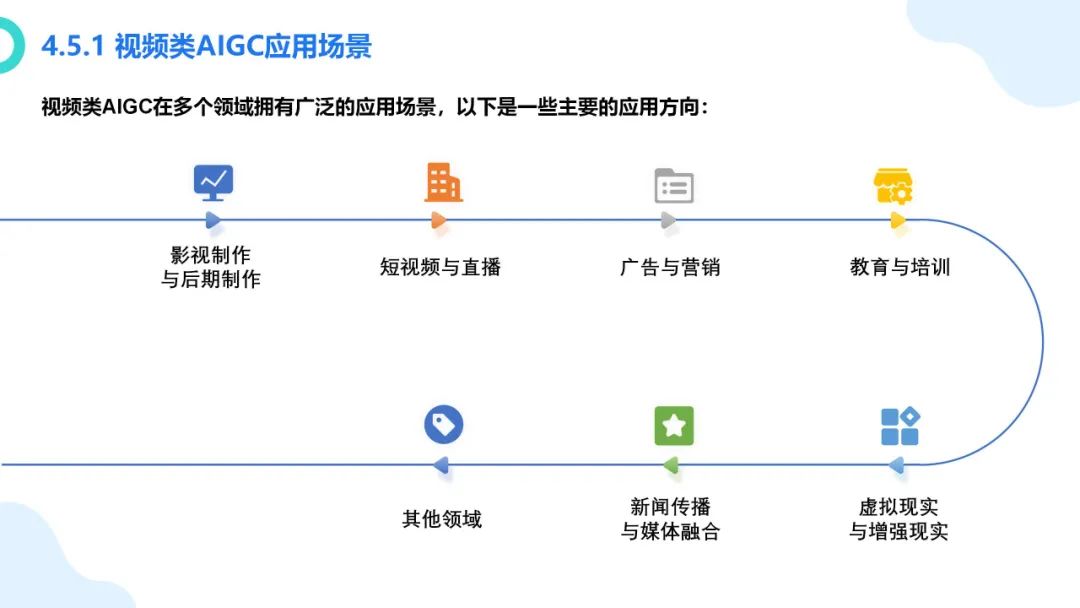
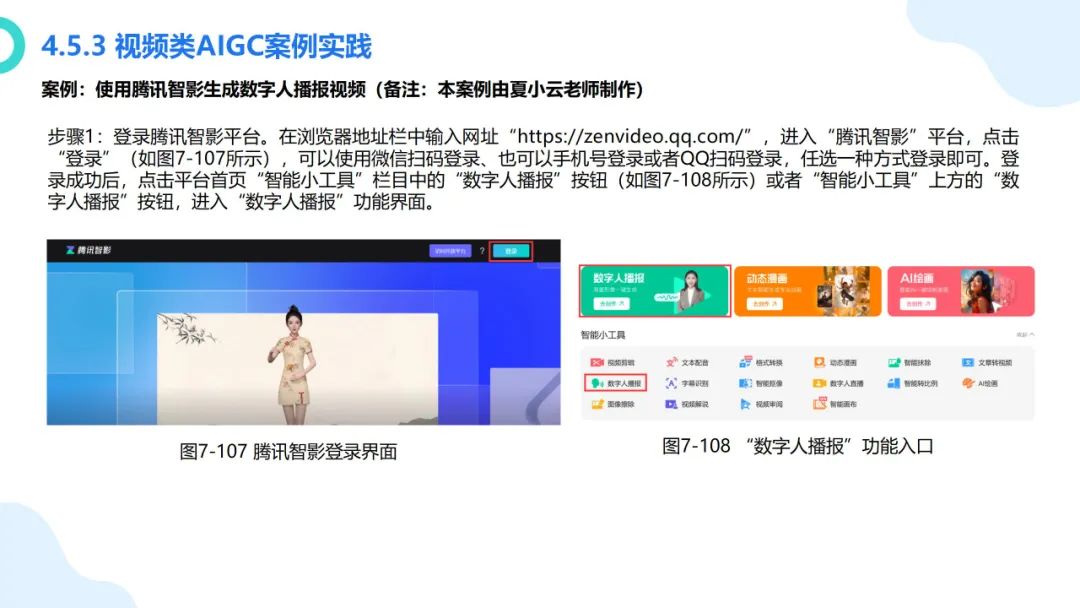
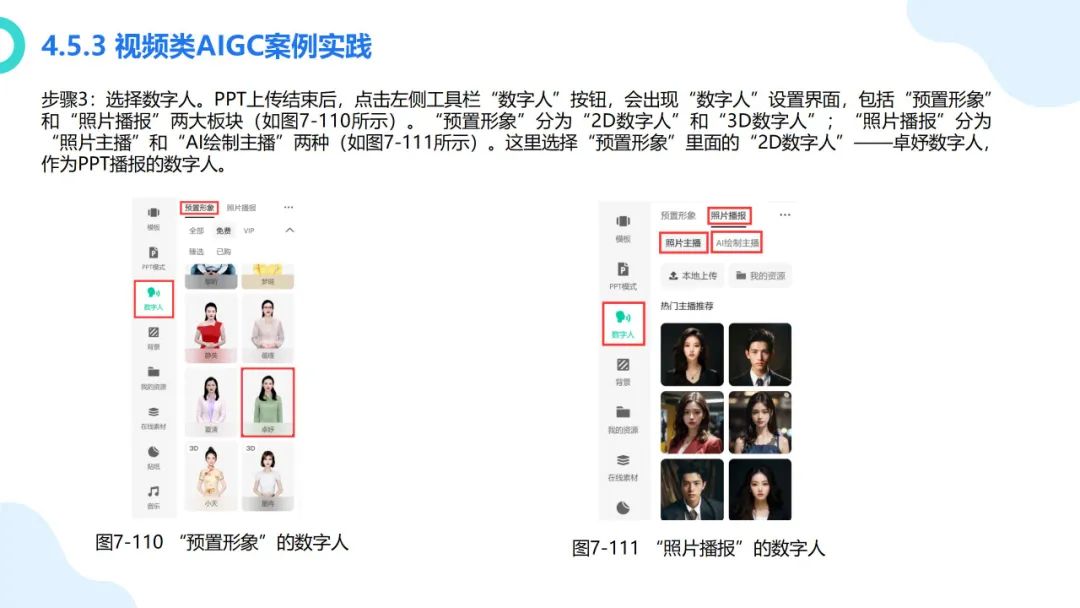
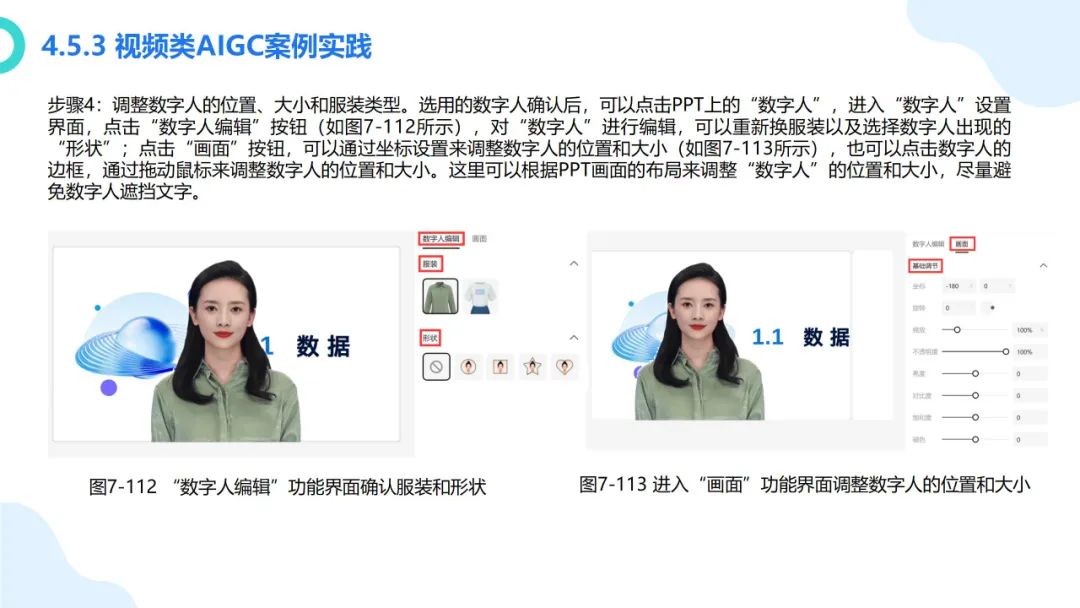
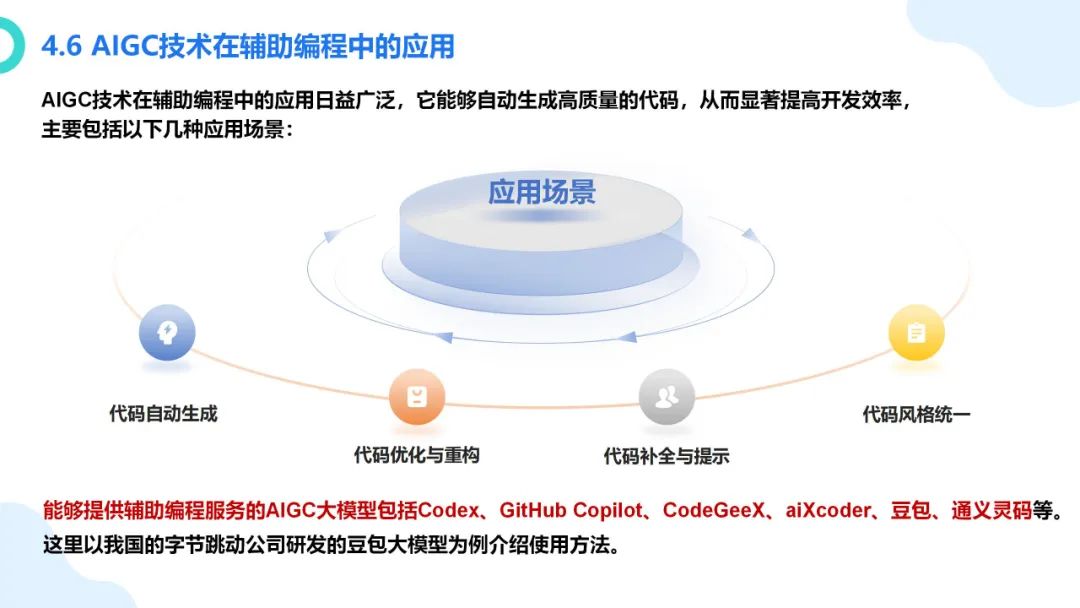
在数字化浪潮汹涌澎湃的当下,大模型如同一颗璀璨新星,强势崛起并迅速成为科技领域的焦点。从最初的理论探索到如今在各个行业的广泛应用,大模型正以惊人的速度重塑着我们的生活与工作模式。它不仅是人工智能技术发展的重大突破,更是推动经济增长、提升社会治理效能、促进科技创新的关键力量。本报告将深入剖析大模型的核心概念、原理特点以及丰富多元的应用实践案例,旨在让大家全面了解大模型这一前沿技术,明晰其在当下及未来发展中的重要地位与深远影响 ,共同探索如何借助大模型的力量推动社会各项事业迈向新的高度。
一、 什么是大模型
大模型通常指的是大规模的人工智能模型,是一种基于深度学习技术,具有海量参数、强大的学习能力和泛化能力,能够处理和生成多种类型数据的人工智能模型。
通常说的大模型的“大”的特点体现在:参数数量庞大、训练数据量大、计算资源需求高等。大模型是具有数百万到数十亿甚至上万亿参数的神经网络模型,比如,2020年,OpenAI公司推出了GPT-3,模型参数规模达到了1750亿,2023年3月发布的GPT-4的参数规模是GPT-3的10倍以上,达到1.8万亿,2021年11月阿里推出的M6 模型的参数量达10万亿。这些模型需要大量的计算资源和存储空间来训练和存储,并且往往需要进行分布式计算和特殊的硬件加速技术。简单来讲,大模型就是用大数据模型和算法进行训练的模型,它能够捕捉到大规模数据中的复杂模式和规律,从而预测出更加准确的结果。很多先进的模型由于拥有很“大”的特点,使得模型参数越来越多,泛化性能越来越好,在各种专门的领域输出结果也越来越准确。
二、 DeepSeek与大模型的关系
DeepSeek是专注于大模型研发的重要力量,旗下研发的DeepSeek V3/R1等大模型在自然语言处理任务中表现出色。它利用大规模数据和先进算法进行训练,具备强大的语言理解与生成能力。DeepSeek通过优化模型架构、提升算力效率等,推动大模型在智能客服、内容创作、智能写作等多场景落地, 为大模型技术发展和实际应用拓展发挥积极作用,助力行业智能化升级。
2024年12月26日,DeepSeek发布了全新一代大模型DeepSeek-V3。在多个基准测试中,DeepSeek-V3的性能均超越了其他开源模型,甚至与顶尖的闭源大模型GPT-4o不相上下,尤其在数学推理上,DeepSeek-V3更是遥遥领先。DeepSeek-V3以多项开创性技术,大幅提升了模型的性能和训练效率。DeepSeek-V3在性能比肩GPT-4o的同时,研发却只花了558万美元,训练成本不到后者的二十分之一。因为表现太过优越,DeepSeek在硅谷被誉为“来自东方的神秘力量”。2025年1月20日,DeepSeek-R1正式发布,拥有卓越的性能,在数学、代码和推理任务上可与OpenAI o1媲美。其采用的大规模强化学习技术,仅需少量标注数据即可显著提升模型性能,为大模型训练提供了新思路。 2025年1月28日,DeepSeek发布了文生图模型Janus-Pro,在多模态理解和文本到图像的指令跟踪功能方面都取得了重大进步,同时还增强了文本到图像生成的稳定性。在GenEval和DPG-Bench基准测试中,Janus-Pro的准确率测试结果分别为80%和84.2%,高于包括OpenAI DALL-E 3在内的其他对比模型。
三、 大模型的基本原理
在大模型中,文本数据会被切分成一个个有意义的片段,这些片段就被称为Token,一个Token可能是一个字符、一个单词或单词的组合等。大模型在处理文本数据时,需要将文本转化为计算机能够理解的形式,每个Token会被映射为一个特定的向量表示,这样模型就能对文本进行计算和处理。在生成文本时,模型也是逐个Token地进行输出。模型会根据输入以及已经生成的上下文,预测下一个可能的Token,直到生成完整的文本内容。比如在对话系统中,模型根据用户的输入和对话历史,生成合适的回复,每次生成一个Token,逐步构建出完整的回复语句。Token的数量可以用来衡量模型处理的文本规模以及计算量。一般来说,处理的Token数量越多,模型需要学习的信息就越多,计算量也越大,对模型的性能要求也就越高。 同时,模型处理Token的速度、生成Token的准确性等也是评估模型性能的重要指标。因此,对于一些收费的大模型产品,其收费价格都是以Token以单位,比如,GPT-4的收费标准是,输入(你向大模型提交内容)100万个Token收费30美元,输出(大模型给你返回结果)100万个Token收费60美元。
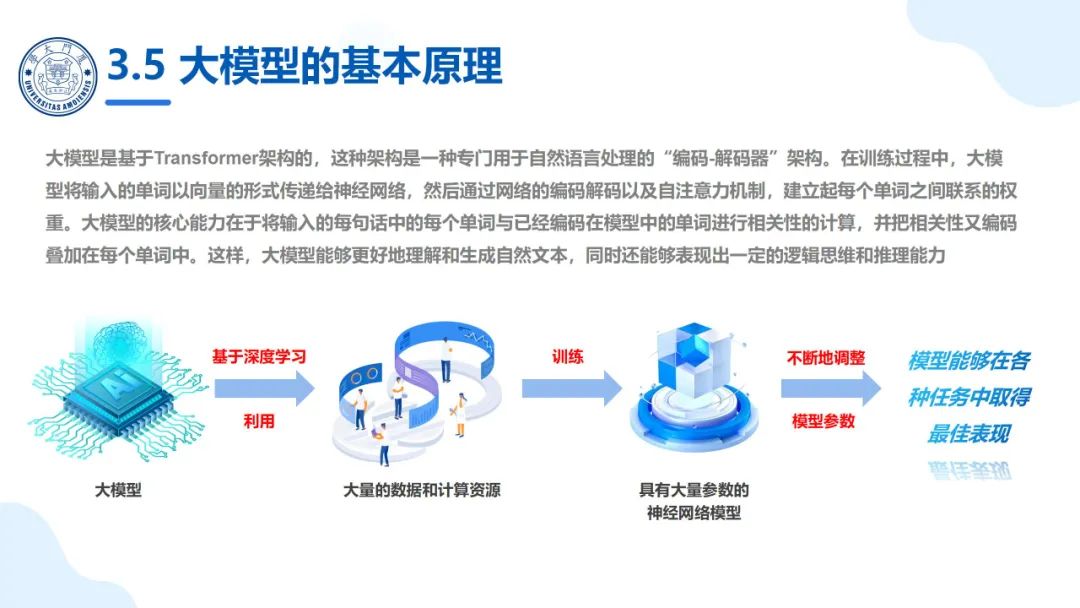
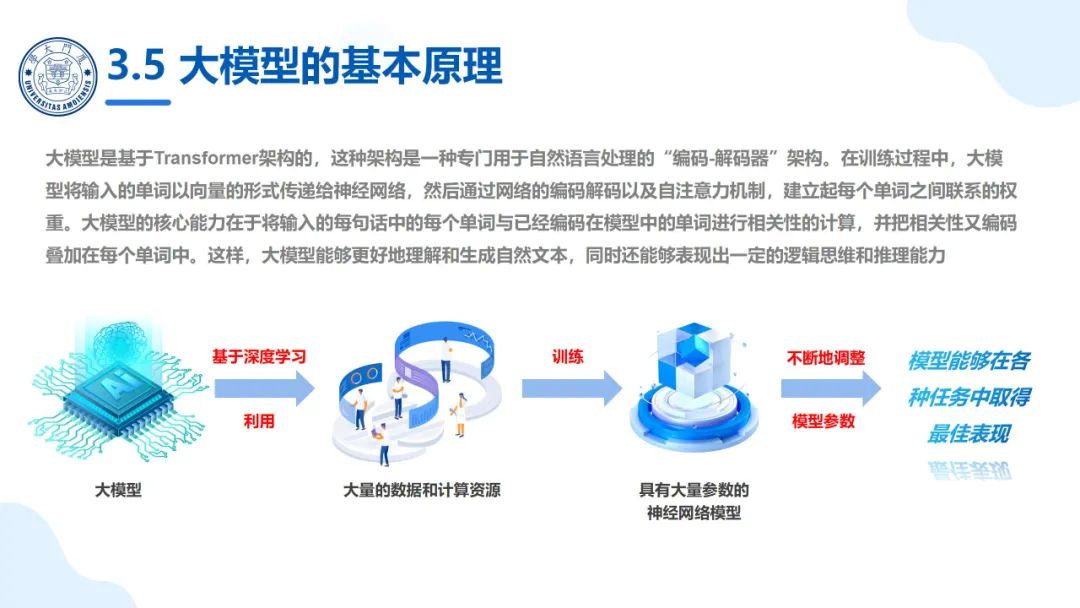
大模型是基于深度学习的,它利用大量的数据和计算资源来训练具有大量参数的神经网络模型。 通过不断地调整模型参数,使得模型能够在各种任务中取得最佳表现。大模型是基于Transformer架构的,这种架构是一种专门用于自然语言处理的“编码-解码器”架构。在训练过程中,大模型将输入的单词以向量的形式传递给神经网络,然后通过网络的编码解码以及自注意力机制,建立起每个单词之间联系的权重。大模型的核心能力在于将输入的每句话中的每个单词与已经编码在模型中的单词进行相关性的计算,并把相关性又编码叠加在每个单词中。这样,大模型能够更好地理解和生成自然文本,同时还能够表现出一定的逻辑思维和推理能力。
四、 大模型的分类
按照输入数据类型的不同,大模型主要可以分为以下三大类:
(1)语言大模型: 也称为“大语言模型”(LLM,Large Language Mode),是指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。代表性产品包括GPT系列(OpenAI)、Bard(Google)、文心一言(百度)等。
(2)视觉大模型: 是指在计算机视觉(Computer Vision,CV)领域中使用的大模型,通常用于图像处理和分析。这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务,如图像分类、目标检测、图像分割、姿态估计、人脸识别等。代表性产品包括VIT系列(Google)、文心UFO、华为盘古CV、INTERN(商汤)等。
(3)多模态大模型: 是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。这类模型结合了NLP和CV的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。代表性产品包括DingoDB多模向量数据库(九章云极DataCanvas)、DALL-E(OpenAI)、悟空画画(华为)、midjourney等。
五、 常见的AIGC大模型工具
常见的AIGC大模型工具包括OpenAI的ChatGPT、深度求索DeepSeek、百度文心一言、科大讯飞的讯飞星火、阿里通义千问、华为盘古、字节跳动豆包、月之暗面Kimi等。这些工具基于大规模语言模型技术,具备文本生成、语言理解、知识问答、逻辑推理等多种能力,可广泛应用于写作辅助、内容创作、智能客服等多个领域。它们通过不断迭代和优化,为用户提供更加智能、高效的内容生成解决方案。
部分报告PPT展示
以下是PPT的部分内容,全文141页:
《厦大团队:大模型概念、技术与应用实践》



















如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









