








模型原因
我们为什么要有岭回归和LASSO回归呢?
因为根据线性回归模型的参数估计公式β=(X’X)-1X’y可知,得到β的前提是矩阵X’X可逆,但在实际应用中,可能会出现自变量个数多于样本量或者自变量间存在多重共线性的情况,即X’X的行列式为0。此时将无法根据公式计算回归系数的估计值β。
列数多于行数
比如电商中,一个顾客可能购买多个商品,那么行数就小于列数
举个例子,我们先构造矩阵:

计算X‘X

计算行列式
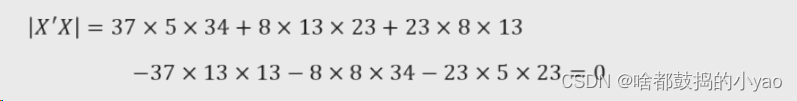
变量和变量间存在多重共线性
构造矩阵(X3=2X1,相关性非常强)

计算X’X

计算行列式
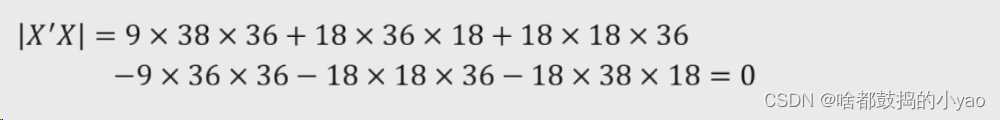
岭回归模型
为解决多元线性回归模型中可能存在的不可逆问题,统计学家提出了岭回归模型。该模型解决问题的思路就是在线性回归模型的目标函数之上添加l2正则项(也称为惩罚项)。
理论分析
岭回归的目标函数:
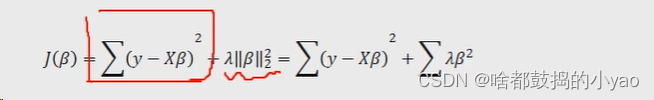
其中:
1、在线性回归模型的目标函数之上添加l2正则项,其中为非负数
2、当λ=0时,目标函数退化为线性回归模型的目标函数
3、当λ→+∞时,通过缩减回归系数使β趋近于0
4、λ是l2正则项平方的系数,用于平衡模型方差(回归系数的方差)和偏差
然后进行求解
首先展开岭回归模型中的平方项
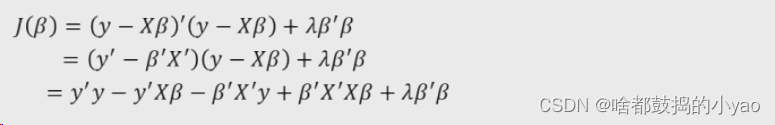
计算导函数
对于如何计算的数学公式,我在前面一节:Python大数据分析——一元与多元线性回归模型里有写,大家可以点击直接查看学习,这里直接给出结果
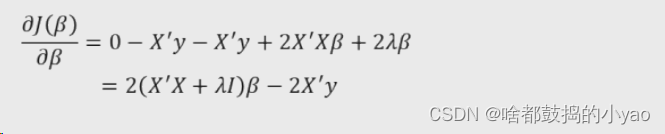
然后令导数等于0求参数
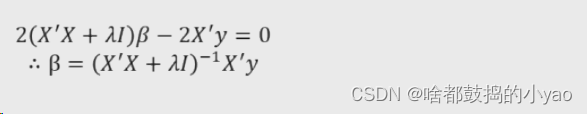
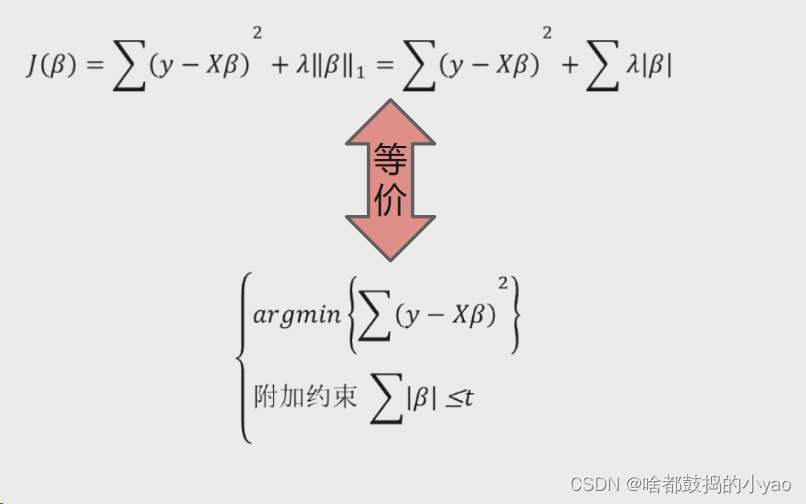
在高等数学中,我们可以通过一种凸优化的方法将其等价
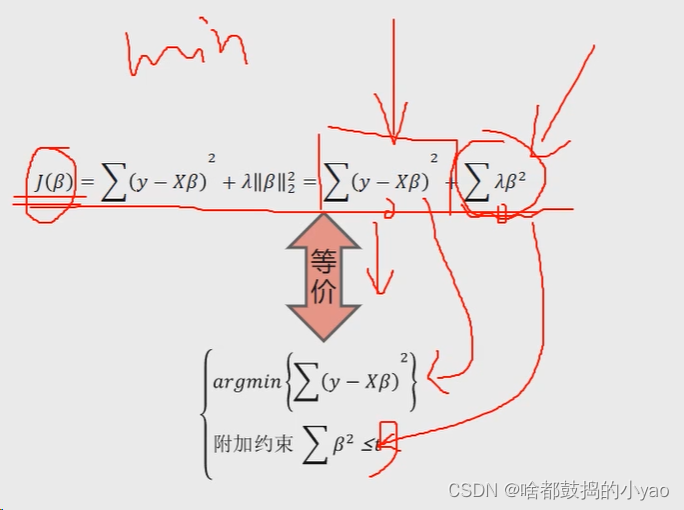
这里我们用几何概念来理解一下这个变化是如何来的
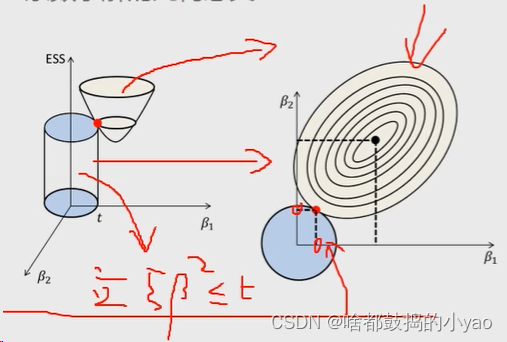
其中线性回归的目标函数是倒圆锥体,附加约束是圆柱立体模型

那么这是求β,我们的λ怎么求呢,用的就是交叉验证法
首先将数据集拆分成k个样本量大体相当的数据组(如图中的第一行),并且每个数据组与其他组都没有重叠的观测;
然后从k组数据中挑选k-1组数据用于模型的训练,剩下的一组数据用于模型的测试(如图中的第二行);
以此类推,将会得到k种训练集和测试集。在每一种训练集和测试集下,都会对应一个模型及模型得分(如均方误差)
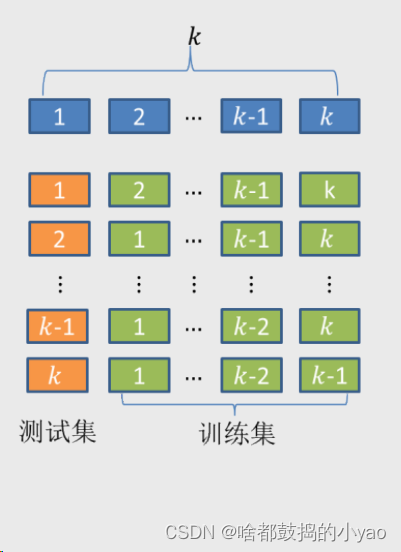
就是说当λ=1,放进10重数据组,得出一个平均得分;然后2、3…的时候都会有一个,然后看哪一个λ最可靠。
函数
λ值的确定–交叉验证法
RidgeCV(alphas=(0.1, 1.0, 10.0), fit_intercept=True, normalize=False,
scoring=None, cv=None)
alphas:用于指定多个lambda值的元组或数组对象,默认该参数包含0.1、1和10三种值。
fit_intercept:bool类型参数,是否需要拟合截距项,默认为True。
normalize:bool类型参数,建模时是否需要对数据集做标准化处理,默认为False。
scoring:指定用于评估模型的度量方法。
cv:指定交叉验证的重数。
注意:
最新版本的RidgeCV函数已经没有normalize=False的设置了
示例
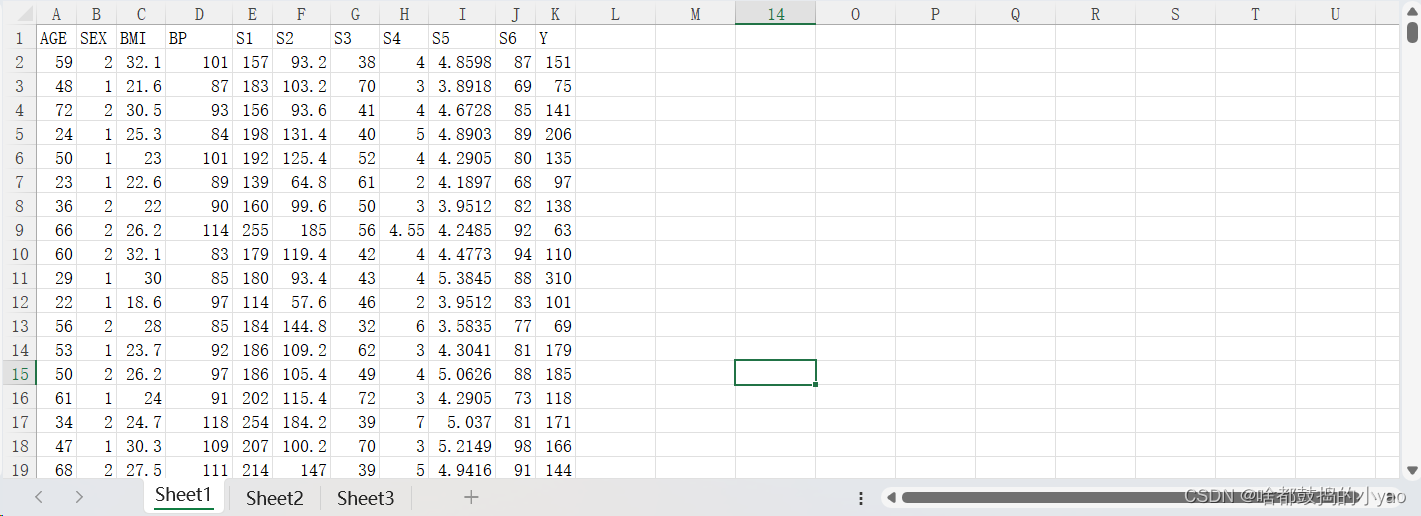
先来看下数据长什么样:
# 导入第三方模块
import pandas as pd
import numpy as np
from sklearn import model_selection
from sklearn.linear_model import Ridge,RidgeCV
from sklearn.metrics import mean_squared_error
# 读取糖尿病数据集
diabetes = pd.read_excel(r'D:\pythonProject\data\diabetes.xlsx')
# 构造自变量(剔除患者性别、年龄和因变量,这些都为非数值化参数)
predictors = diabetes.columns[2:-1]
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = model_selection.train_test_split(diabetes[predictors], diabetes['Y'],
test_size = 0.2, random_state = 1234 )
# 构造不同的Lambda值(初始值是-5,终值是2,生成个数是200的一个等比数列)
Lambdas = np.logspace(-5, 2, 200)
# 设置交叉验证的参数,对于每一个Lambda值,都执行10重交叉验证
ridge_cv = RidgeCV(alphas = Lambdas, scoring='neg_mean_squared_error', cv = 10 ) # 评估得分为MSE(y-y预测)^2/N
# 模型拟合
ridge_cv.fit(X_train, y_train)
# 返回最佳的lambda值
ridge_best_Lambda = ridge_cv.alpha_
# ridge_best_Lambda
# 基于最佳的Lambda值建模
ridge = Ridge(alpha = ridge_best_Lambda)
ridge.fit(X_train, y_train)
# 返回岭回归系数
pd.Series(index = ['Intercept'] + X_train.columns.tolist(), data = [ridge.intercept_] + ridge.coef_.tolist())
# 预测
ridge_predict = ridge.predict(X_test)
# 预测效果验证
RMSE = np.sqrt(mean_squared_error(y_test,ridge_predict))
RMSE
输出:
1、最佳λ的值是:
0.6080224261649427
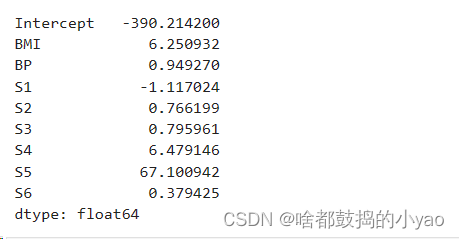
2、岭回归系数是:
3、预测及其效果验证:
53.38642682397507
LASSO回归模型
理论分析
岭回归模型解决线性回归模型中矩阵X’X不可逆的办法是添加l2正则的惩罚项,但缺陷在于始终保留建模时的所有变量,无法降低模型的复杂度。 对于此,Lasso回归采用了l1正则的惩罚项。所以他的优势就是降维了。
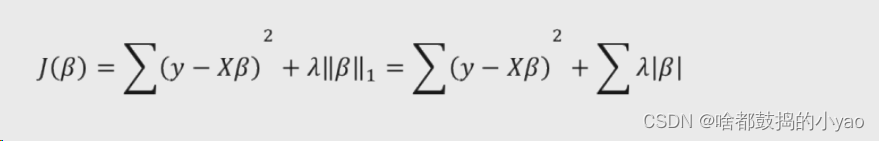
进行凸优化的等价
其系数几何意义
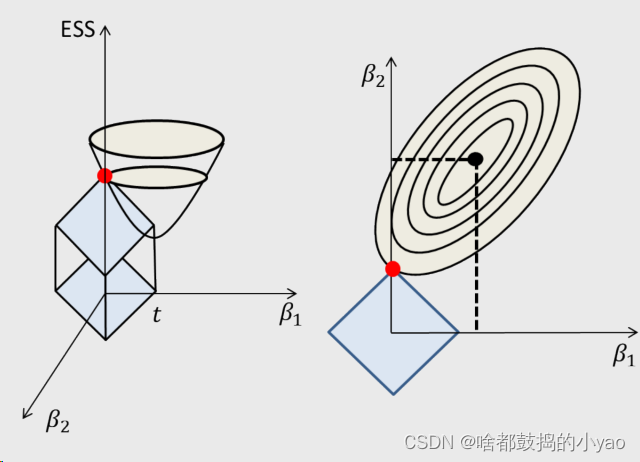

让俩个图像相交,发现比圆的图相交好收敛,也就是复杂度低
函数
λ值的确定–交叉验证法
LassoCV(alphas=None, fit_intercept=True, normalize=False, max_iter=1000, tol=0.0001)
alphas:指定具体的Lambda值列表用于模型的运算
fit_intercept:bool类型参数,是否需要拟合截距项,默认为True
normalize:bool类型参数,建模时是否需要对数据集做标准化处理,默认为False
max_iter:指定模型最大的迭代次数,默认为1000次
tol:是收敛条件
最新的功能包是没有normalize参数的
示例
依然是上面的糖尿病数据集
# 导入第三方模块
import pandas as pd
import numpy as np
from sklearn import model_selection
from sklearn.linear_model import Lasso,LassoCV
from sklearn.metrics import mean_squared_error
# 读取糖尿病数据集
diabetes = pd.read_excel(r'D:\pythonProject\data\diabetes.xlsx')
# 构造自变量(剔除患者性别、年龄和因变量,这些都为非数值化参数)
predictors = diabetes.columns[2:-1]
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = model_selection.train_test_split(diabetes[predictors], diabetes['Y'],
test_size = 0.2, random_state = 1234 )
# 构造不同的Lambda值(初始值是-5,终值是2,生成个数是200的一个等比数列)
Lambdas = np.logspace(-5, 2, 200)
# LASSO回归模型的交叉验证,都执行10重交叉验证,允许最大一万次迭代
lasso_cv = LassoCV(alphas = Lambdas, cv = 10, max_iter=10000)
lasso_cv.fit(X_train, y_train)
# 输出最佳的lambda值
lasso_best_alpha = lasso_cv.alpha_
# lasso_best_alpha
# 基于最佳的lambda值建模
lasso = Lasso(alpha = lasso_best_alpha, max_iter=10000)
lasso.fit(X_train, y_train)
# 返回LASSO回归的系数
pd.Series(index = ['Intercept'] + X_train.columns.tolist(), data = [lasso.intercept_] + lasso.coef_.tolist())
# 预测
lasso_predict = lasso.predict(X_test)
# 预测效果验证
RMSE = np.sqrt(mean_squared_error(y_test,lasso_predict))
RMSE
输出:
1、最佳λ的值是:
0.08026433522257174
2、LASSO回归系数:
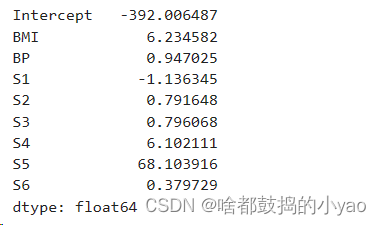
3、预测及其效果验证:
53.373985839769475
发现小于岭回归的53.38642682397507,所以略优于他
我们进行还可以进行线性回归比对
# 导入第三方模块
from statsmodels import api as sms
# 为自变量X添加常数列1,用于拟合截距项
X_train2 = sms.add_constant(X_train)
X_test2 = sms.add_constant(X_test)
# 构建多元线性回归模型
linear = sms.OLS(y_train, X_train2).fit()
# 返回线性回归模型的系数
linear.params
# 模型的预测
linear_predict = linear.predict(X_test2)
# 预测效果验证
RMSE = np.sqrt(mean_squared_error(y_test,linear_predict))
RMSE
输出:
53.42623939722987
发现比他们都大,说明效果不如这两者好。
















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











