






背景介绍:
春节假日期间,美国人工智能研究公司OpenAI发布了Sora模型。在文生文、文生图之后,Sora突破了文生视频技术,可以根据文本指令生成长达1分钟的逼真和富有想象力的视频,引起网络和公众高度关注。那么Sora模型的基本原理是什么?可能会带来哪些变化和影响?
原理介绍:
我们将sora的整个训练过程可以划分为四个大的步骤
步骤一:使用 DALLE 3( CLIP )把文本和图像对 <text,image> 建立关联性;
在训练阶段,将视频按1帧或者隔n帧用DALLE3(CLIP)按照一定的规范形成对应的描述文本,然后输入模型训练。
在推理阶段,首先将用户输入的prompt用GPT4按照一定的规范把它详细化,然后输入模型得到结果。
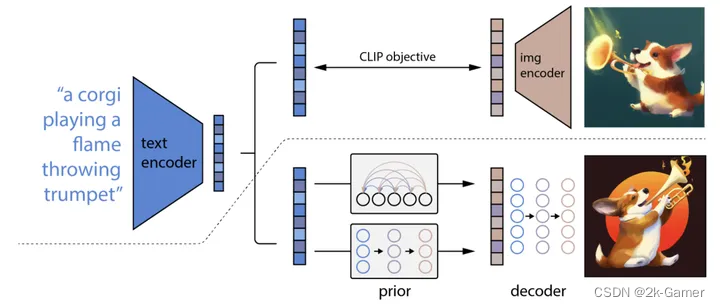
DALLE2结构
CLIP 接受~亿对 <图片-文字> 数据训练,学习到给定文本与图像的关系
CLIP 并不是试图预测给定图像对应文字说明,而是学习给定文本与图像之间的关联,
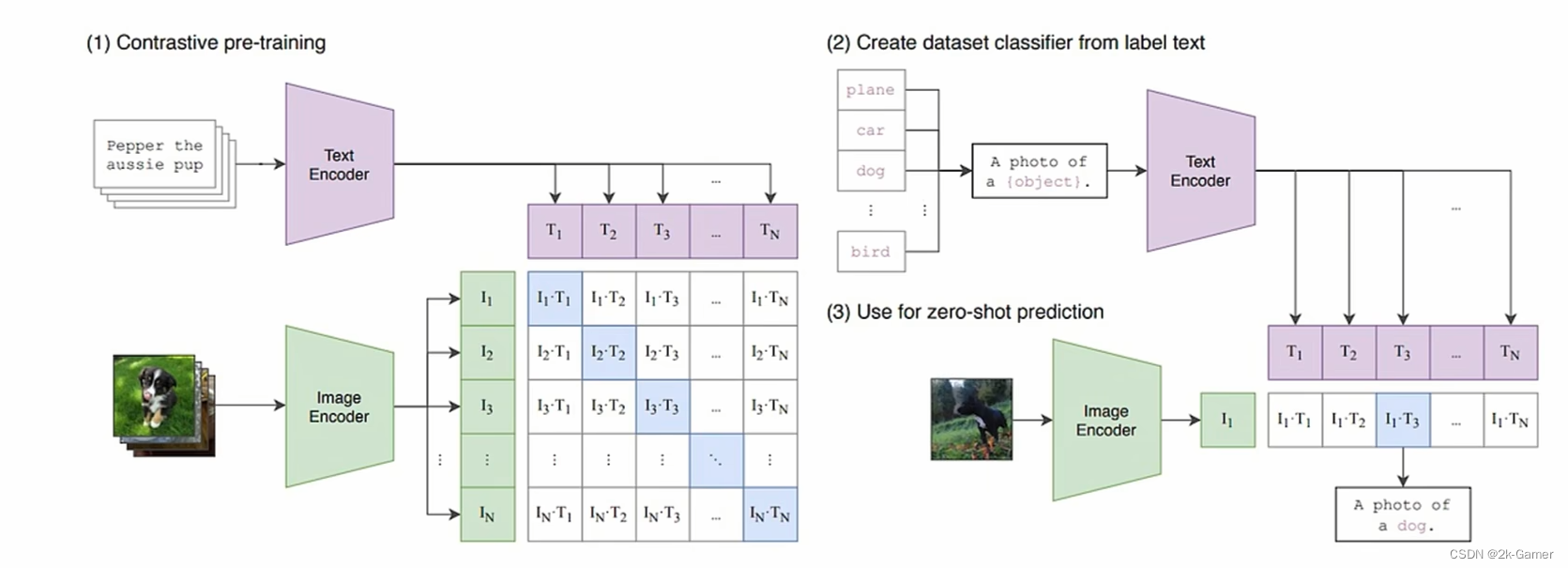
步骤二:视频数据切分为 Patches 通过 VAE 编码器压缩成低维空间表示
首先要了解VAE的网络结构
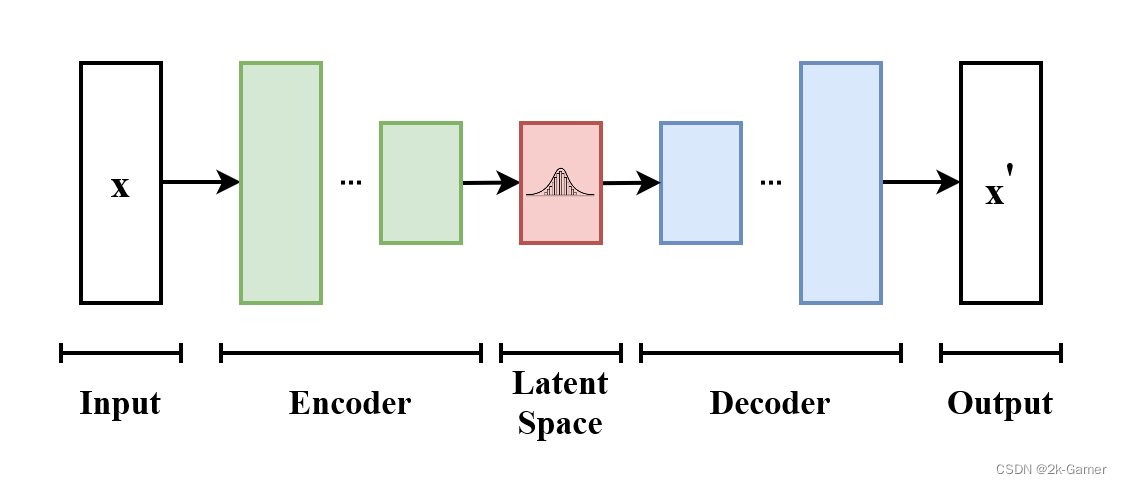
VAE的基本框架,模型接受x为输入,编码器将其压缩到潜空间,解码器以在潜空间采样的信息为输入,
并产生x'使其与x尽可能相似。
Sora首先通过一个encoder【VAE结构】将视频帧压缩到一个低维度隐式空间(包含时间和空间上的压缩,然后展开成序列的形式送入模型训练,同样的模型预测也是隐式的序列,然后用decoder解码器去解码映射回像素空间形成视频
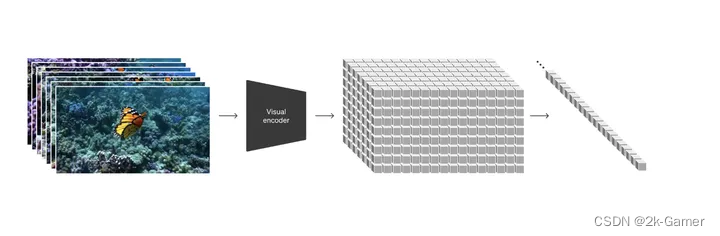
最终效果可以统一不同大小格式的视频和图片数据,具有可扩展性
在推理阶段可以通过将patches组合成不同形状从而控制视频生成的尺寸大小
步骤三:基于 Difusion Transformer 从图像语义生成,完成从文本语义到图像语义进行映射;
潜空间扩散模型 LDM
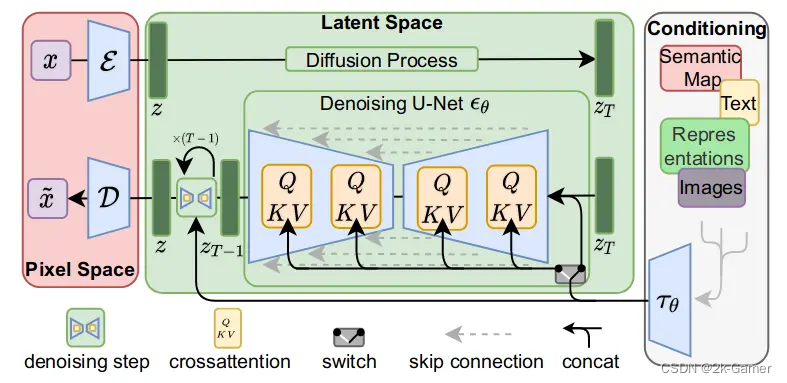
Latent Diffusion Models(LDMs)是基于潜空间的扩散模型,LDMs 大量自编码器的运算基于潜空间数据,降低了计算复杂度,从而大幅节省了算力,其应用场景包含有条件(根据文本或图像生成图像)和无条件(去噪/着色/根据涂鸦合成)的图像生成。
主逻辑分成三部分:第一部分是像素空间与潜空间之间的转换,即感知图像压缩(粉色);
第二部分是在潜空间操作的扩散模型(绿色);
第三部分是用文本描述或其它图片作为条件,控制图像生成(白色)。
U 型网络结构 U-Net,LDM 的绿色部分包含 U-Net,它最早被应用于医学影像领域,用于识别病灶。
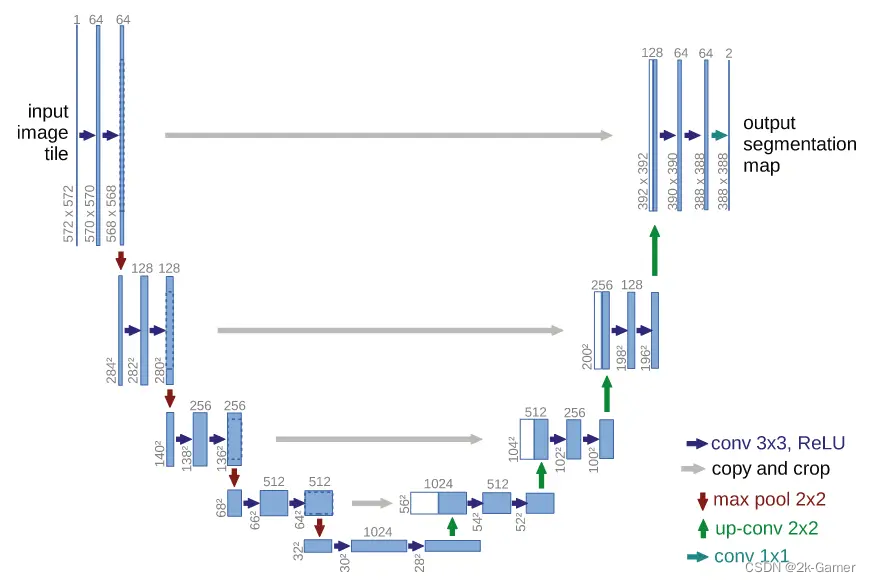
它是一个典型的编码解码器结构,结构完全对称,UNet 架构的归纳偏差对具有空间结构(上下左右的相关性)的数据特别有效,之前的扩展模型内部都是基于 U-Net 网络构建的。
结合 Diffusion 与 Transformer DiT
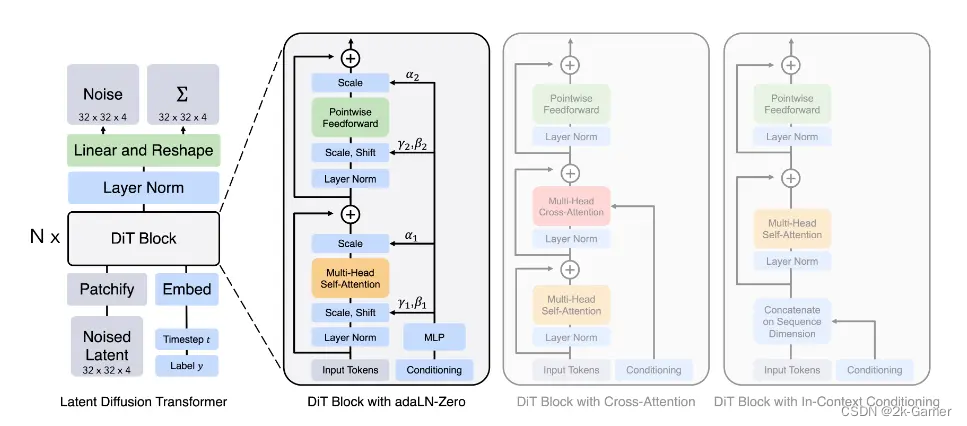
DIT 的核心是提出用基于潜空间 patch 的 Transformer 模型替换之前的 U-Net 模型,来预测噪声实现去噪,这个替换效果就是随着数据规模或者训练时间的增强,模型表现的效果越好。
把图片切成小块 patch(可将其视为 LLM 中的 token,简单地讲就是语言模型中的词),然后输入 Transformer 结构,使模型学习每帧图像内部小块之间的空间关系。
步骤四:DiT 生成的低维空间表示,通过VAE 解码器恢复成像素级的视频数据
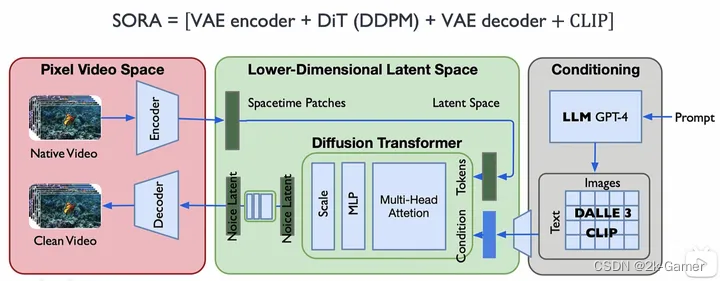
最后我们看下sora整体结构,按照我们上面分开描述的模块,我们将所有的模块组合就是最终的sora网络训练架构,分别包含 VAE DiT(DDPM) CLIP等
参考b站up主ZOMI酱的画的Sora结构
现有缺陷:
Sora目前的技术路线还无法正确模拟世界的物理规律
Sora之所以能对物理世界规律进行模拟,一个可能的原因在于大数据驱动下,人工智能模型体现出一种学习能力,即Sora通过观察和学习海量视频数据后,洞察了视频中时空子块单元之间所应保持的物理规律。其实,人类也是基于对自然界斗转星移、节气变迁和昼夜交替,以及微观物质世界物质合成与生命演化的观测,推导出各种物理规律。虽然Sora很难像人类一样,将物理世界中诸如牛顿定律、湍流方程和量子学定理等,以数学方程罗列于人工模型中,但Sora能记住时空子块单元之间应遵守的模式,进而利用这些模式约束时空子块的组合。
OpenAI 技术报告中透露,Sora能够深刻地“理解”运动中的物理世界,堪称真正的世界模型。OpenAI想强调,Sora不是单纯的视频生成模型,不只是视频行业颠覆者,而是世界的模拟器,它打开了一条通往模拟物理世界的有效路径。OpenAI仅列举了作为物理世界的模拟器应具备的几个特点和例子——3D一致性、远程相关性、物体持久性、与世界互动等,却并未对“什么是世界的模拟器”做任何定义和具体分析。但我们大概可以总结出它的逻辑:Sora生成的视频能够在相当长的时空范围内不违反物理世界的常见规律,比如重力、光电、碰撞等。如果模型规模进一步提升,它有可能模拟生成物理世界的视频。
世界模拟器是指可以逼真反映虚拟世界或现实世界的模型或系统。物理世界的模拟器能够在虚拟环境中重现物理现实,为用户提供一个逼真且不违反物理规律的数字世界。
Sora生成视频中之所以会出现违背物理学规律的例子,也可以从其文生视频的原理来分析:
Sora将视频分解成时空令牌,然后学习上下文中令牌间连接的概率分布,并且依据这一概率分布由白噪声生成令牌、连接令牌,解码成短视频。每个令牌表达图像或者视频中的一个局部区域,不同局部区域间的拼接成为问题的关键。
Sora相对独立地学习每个令牌,将令牌间的空间关系用训练集中体现的概率来表达,但无法精准表达令牌间时空的因果关系。这种“局部合理,整体荒谬”的生成视频,意味着模型学会了碎片化知识的连接概率,但是缺乏时空上下文的大范围整体观念。
另外Sora采用的是目前最为热门的扩散模型,在计算传输映射的时候,必然会光滑化数据流形的边界,从而混淆不同的模式,直接跳过临界态图像的生成。因此视频看上去从一个状态突然跳跃到另外一个状态,中间最为关键的倾倒过程缺少,导致物理上的荒谬。
由此可见,虽然Sora声称是“作为世界模拟器的视频生成模型”,但目前的技术路线无法正确模拟世界的物理规律。
究其原因,首先,用概率统计的相关性(指Transformer用以表达令牌之间的统计相关性)无法精确表达物理定律的因果性,自然语言的上下文相关无法达到偏微分方程的精密程度,而物理定律目前只有偏微分方程才能精密表达;
其次,虽然Transformer可以学习临近时空令牌间的连接概率,但是无法判断全局的合理性,整体的合理性需要更高层次的数学理论观点、或者更为隐蔽而深厚的自然科学和人文科学的背景,目前的Transformer无法真正悟出这些全局观点;
另外,Sora忽略了物理过程中最为关键的临界(灾变)态,一方面因为临界态样本的稀缺,另一方面因为扩散模型将稳恒态数据流形的边界模糊化,消弭了临界态的存在,生成的视频出现了不同稳恒态之间的跳跃。
未来应用:
文生视频技术未来将会在多个领域得到应用
随着生成式人工智能技术的不断发展,特别是文生视频技术受到大家的关注,后续关于这方面的研究会推动该领域再上一个台阶,技术的走向除了Sora目前存在的缺点,应该还有会其他突破。将来可能会在以下方面得到广泛应用:
创意行业:文生视频技术可以帮助艺术家、设计师和创作者快速生成创意作品,包括动画、影片、广告等,提高创作效率和降低成本。
营销和广告:文生视频技术可以根据用户的偏好和行为数据生成个性化的广告内容,提高广告效果和用户参与度。
视频制作和编辑:文生视频技术可以自动生成视频剪辑、字幕、特效等内容,简化视频制作和编辑的流程。
虚拟现实和增强现实:文生视频技术可以生成逼真的虚拟现实和增强现实内容,用于游戏、培训、教育等领域。
自动化视频生成:文生视频技术可以自动生成新闻、体育赛事、天气预报等视频内容,提高新闻媒体和娱乐行业的自动化程度。
客户服务和教育培训:文生视频技术可以帮助企业和教育机构快速生成培训视频、产品演示等内容,提升客户服务和教学效果。
随着文生视频技术的发展和完善,除了上述的基本应用领域外,将来还会渗透到更加专业的领域,带来更高效、创新和个性化的视频内容生成体验。
参考:
https://openai.com/research/video-generation-models-as-world-simulators

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









