







[目的/意义] 近年来,人工智能在农业领域的应用取得了显著进展,但仍面临诸如模型数据收集标记困难、模型泛化能力弱等挑战。大模型技术作为近期人工智能领域新的热点技术,已在多个行业的垂直领域中展现出了良好性能,尤其在复杂关联表示、模型泛化、多模态信息处理等方面较传统机器学习方法有着较大优势。
[进展] 本文首先阐述了大模型的基本概念和核心技术方法,展示了在参数规模扩大与自监督训练下,模型通用能力与下游适应能力的显著提升。随后,分析了大模型在农业领域应用的主要场景;按照语言大模型、视觉大模型和多模态大模型三大类,在阐述模型发展的同时重点介绍在农业领域的应用现状,展示了大模型在农业上取得的研究进展。
[结论/展望] 对农业大模型数据集少而分散、模型部署难度大、农业应用场景复杂等困难提出见解,展望了农业大模型未来的发展重点方向。预计大模型将在未来提供全面综合的农业决策系统,并为公众提供专业优质的农业服务。

引言
大模型(Big Models)[1],或称基础模型(Foundation Models)[2],指经过在大规模数据上训练,具有庞大参数量的深度神经网络模型。这些模型通常基于Transformer[3]架构,通过自监督的方法从大量数据中进行学习,不仅拥有卓越的通用能力,也可以适应不同的下游任务。通过扩展,模型在多个领域展示出强大能力的同时,甚至可以涌现出的新能力。例如基于GPT(Generative Pre-trained Transformer)[4]系列技术的ChatGPT对话机器人,可以经过一定的提示词,在如机器翻译、情感分析、文本摘要等大量的自然语言处理任务中表现出色,亦可以推理小模型无法处理的复杂逻辑。
大模型一般使用自监督(Self-supervised)的方式进行大规模的训练,然后将模型应用于不同的下游任务。自监督的学习方式摆脱了对大量人工标记的依赖。通过扩展模型的规模与训练量,模型的任务范围与性能均能有显著提高,同时微调(Fine-tuning)也可以在特定任务上利用少量数据快速提升模型能力。在大模型中,以语言大模型(Large Language Models, LLMs)[5]为代表性成果,其可以通过一定的提示词完成广泛的文本生成任务,展现出强大的模型泛化能力。大模型也包括视觉大模型(Large Vision Models, LVMs)与多模态大模型(Large Multi-modal Models, LMMs)等。
现代农业的迅猛发展与人工智能技术进步密切相关,特别是深度学习的突破性进展对农业产生了深远影响。深度学习强大的特征学习与数据处理等能力,使其在杂草控制、作物病虫害检测、畜牧业管理以及农业遥感等领域均有广泛应用。然而,这些方法大多使用监督学习,依赖于特定的高质量人工标注数据。收集和标注这类数据集不仅耗时、耗资巨大,且模型迁移到其他任务的能力有限,限制了数据规模与模型的发展。因此,寻找能够跨应用领域通用的模型和技术,减少对大规模数据标记的新方法,扩展深度学习框架的通用性,是推动农业等领域进步的重要挑战。
农业大模型(Agricultural Big Models)是为克服上述困难的一次重大尝试,为解决农业领域数据较少且分散的现状提供了方案,同时其广泛的任务迁移能力也得到了多个农业子领域的关注。图1介绍了大模型的构建流程,包含使用异构数据训练模型,对模型微调提升能力,以及使用外部系统增强生成能力等;最终,模型可以用于多种农业综合服务中,提供强大而全面的农业问题解决方案。
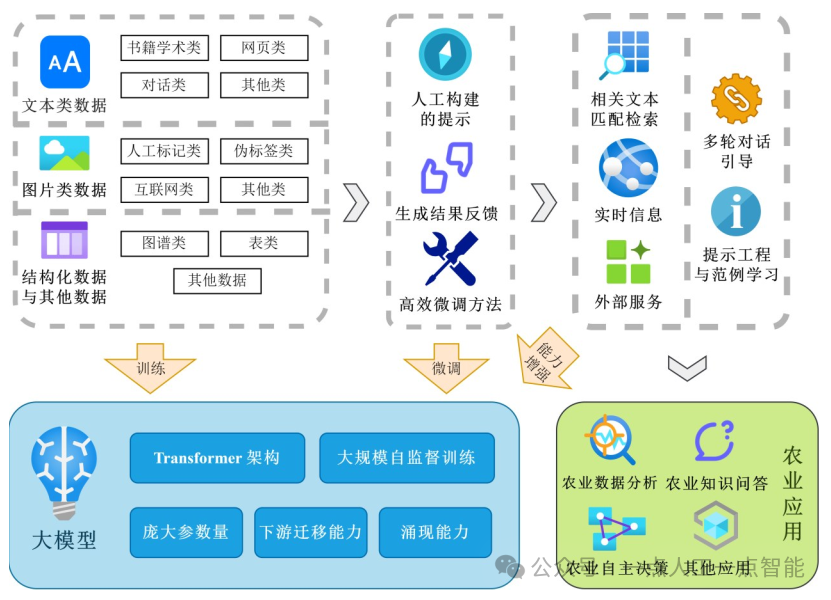
图1 农业大模型的构建流程与应用[6,7]
为梳理大模型的农业应用现状,探讨大模型的农业应用潜力,本文首先介绍了大模型关键技术;其次分析了大模型在农业领域可能的应用场景,分别介绍语言大模型、视觉大模型和多模态大模型三种常见大模型及其农业应用案例,展示模型在农业领域的影响。最后,阐述大模型在农业领域发展面临的挑战,并给出农业大模型的发展思路。

大模型关键技术与特性
大模型依赖于诸多技术支撑,也具有区别于其他人工智能模型的特性。Transformer架构是当今众多大模型的基础,使大模型能够有效处理大规模的数据并扩展模型规模[3],扩展定理则指导大模型进行有限预算的最优开发,大规模的自监督学习使模型在无需人工监督的情况下扩展训练规模来提升能力。同时,大模型中新产生的涌现能力(Emergent abilities)[8],是其区别于其他小规模模型的重要特征。
1.1 Transformer模型的产生与核心原理
Transformer架构的设计核心是一种简单高效的自注意力(Self-attention)机制,通过计算序列内元素间的相互关注度分数,为各元素赋予差异化的重要性权重。这一设计使得模型能够在处理序列数据时,动态地集中处理序列中的关键信息,并能够覆盖序列中任意位置的数据元素,有效捕捉长程依赖关系。这种机制使得模型能够方便地扩展,不会因此在模型推理时丢失细节。此外,Transformer模型的架构允许并行化计算,模型在参数规模较大时训练效率有了显著提升。这些特性促使其在大模型领域具有广泛应用。
Transformer推动了自然语言处理领域的一系列重大进展。BERT(Bidirectional Encoder Representations from Transformers)[9]、GPT等基于Transformer架构的预训练语言模型相继产生,并在文本翻译等子领域展示出卓越的性能。
GPT使用了Transformer中的解码器设计,允许文本正向输入,并通过预测文本序列中的下一词来进行训练,使模型能够理解并生成连贯的文本内容。BERT则使用双向Transformer编码器架构,能够考虑到给定单词在上下文中的前后信息,实现同时从正向和反向与对文本的深入理解,显著提升了模型对语义的把握能力。同时,BERT通过在掩码语言建模(Masked Language Modeling)与下一句预测(Next Sentence Prediction),学习到复杂的语境关系。
随着模型的进一步扩大,例如GPT-3[10]、LLaMa(Large Language Model Meta AI)[11]等语言大模型的开发,将模型能力推升至新的高度。同时,Transformer架构的影响也扩展到了其他的人工智能子领域,如计算机视觉领域的代表模型ViT(Vision Transformer)[12],通过将图像分割成多个小块并应用Transformer架构处理,打破了传统依赖卷积神经网络(Convolutional Neural Networks, CNNs)的图像处理范式。
进一步地,Caron等[13]将ViT与自监督学习结合,提出了DINO(Self-distillation with No Labels)框架,在自监督条件下也能学习到图像中的深层语义特征,为构造视觉大模型奠定了一定的理论基础。
1.2 大模型的扩展定理
Transformer架构允许模型进行大规模的堆叠,而对模型规模、数据规模与计算量的扩展,可以大幅提高模型能力。尤其在语言大模型领域,开展了一些对扩展的定量研究。
语言大模型发展出两个代表性的法则[7]:KM(Kaplan-McCandlish)法则[14]与Chinchilla法则[15]。
KM法则是通过拟合神经语言模型的性能在不同模型规模(N)、数据集规模(D),以及训练计算量(C)三种变量的表现提出了一种性能随这三种要素扩展而提升的定量描述;Chinchilla法则提出了另一种形式来指导语言大模型进行最优计算量的训练,认为模型大小与数据量应以同比增加来在一定预算下取得最优模型。KM法则可以表示为公式(1)公式(3),Chinchilla法则表示为公式(4)公式(6)。
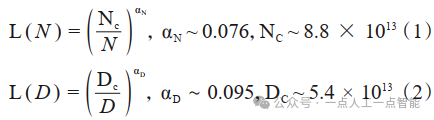
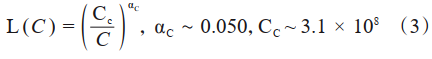
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









