






导读
提到大模型大家可能首先想到的是对话式人工智能,却很少想到视觉领域。其实大模型在视觉领域中也有许多应用,本文对此汇总了目前市面上常用的视觉大模型,希望对大家有所帮助。
1、Griffon-G: Bridging Vision-Language and Vision-Centric Tasks via Large Multimodal Models
https://github.com/jefferyZhan/Griffon
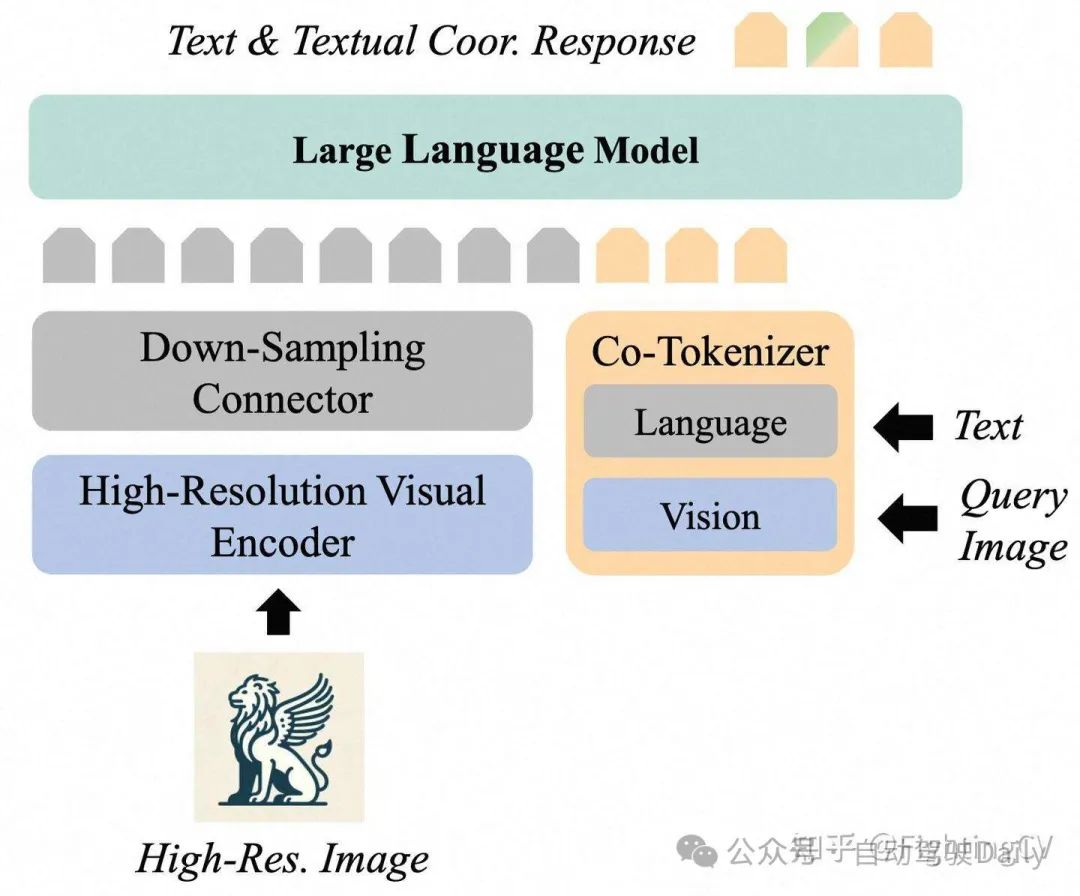
Motivation:
- 目前的VLM不能兼备vision-center和vision-language的能力
- 直接堆叠这两个任务的数据并不能很好的提升两个任务的性能
Contribution:
- 推出名为 CCMD-8M 的多维精选和整合的多模态数据集
- 提出了 Griffon-G,一个统一的多模态模型,能够解决视觉语言和以视觉为中心的任务。
- 提出 Paradigm Progressive Learning Pipeline 解决了来自不同范式的各种任务联合优化过程中遇到的训练折叠问题
精选数据集策略:
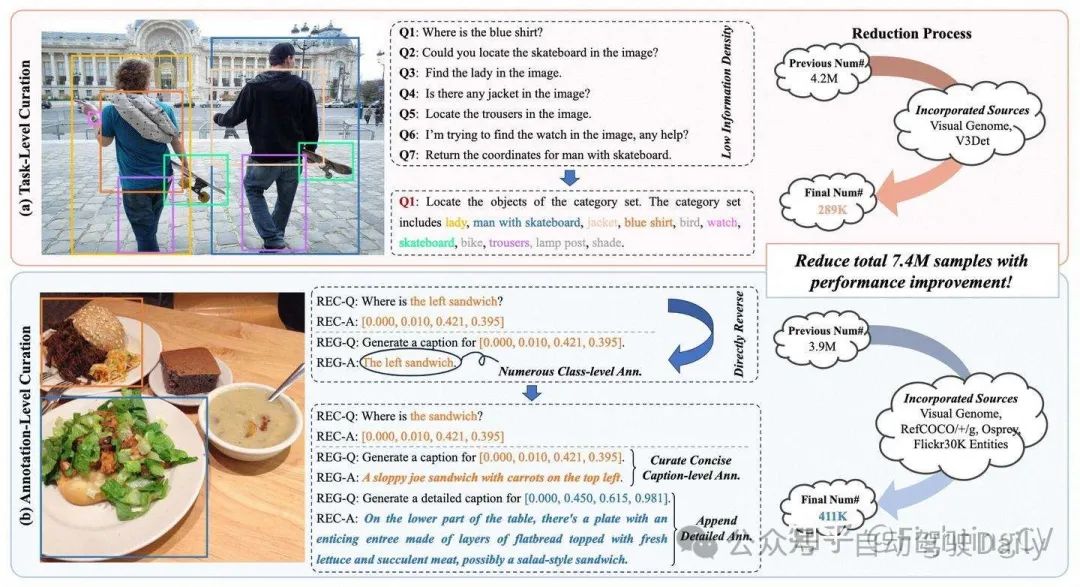
- Task-Level Curation:将多个single-object rec的数据合并成一个multi-object rec的数据
- Annotation-Level Curation:过滤掉信息量低(只有类别信息)的数据
Paradigm Progressive Learning Pipeline
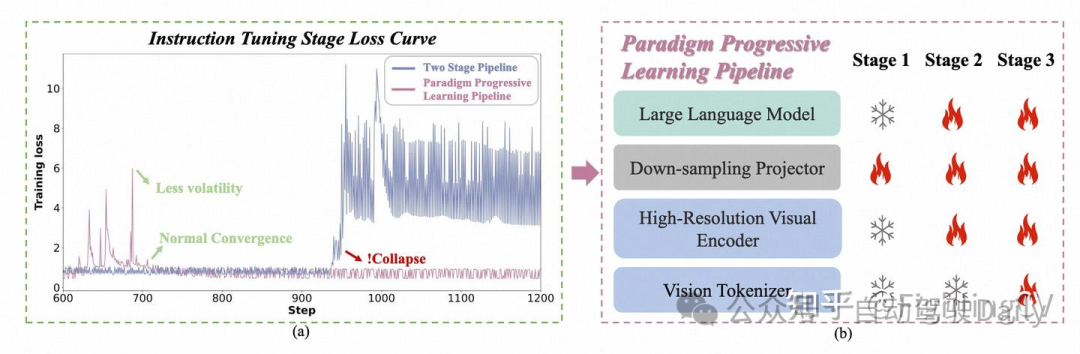
- Stage1: 训练projector对齐视觉语言模态
- Stage2: 用区域感知预训练集来训练出了Vision tokenizer之外的部分,使其具备一定的视觉感知能力
- Stage3: 用instruction-following训练,其中只有visual referring object counting data才会训练Vision tokenizer
2、Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
https://huggingface.co/spaces/fffiloni/Sa2VA-simple-demo
https://github.com/magic-research/Sa2VA
(8卡A800-80G)
Motivation:
- 希望将image chat, image referring segmentation, video chat, referring video object segmentation, grounded caption generation任务用一个模型来完成。
Contribution:
- 我们开发了 Sa2VA,将 SAM-2 和类似 LLaVA 的模型组合成一个模型的简单框架
- 提出一个大的referring video object segmentation benchmark
模型:
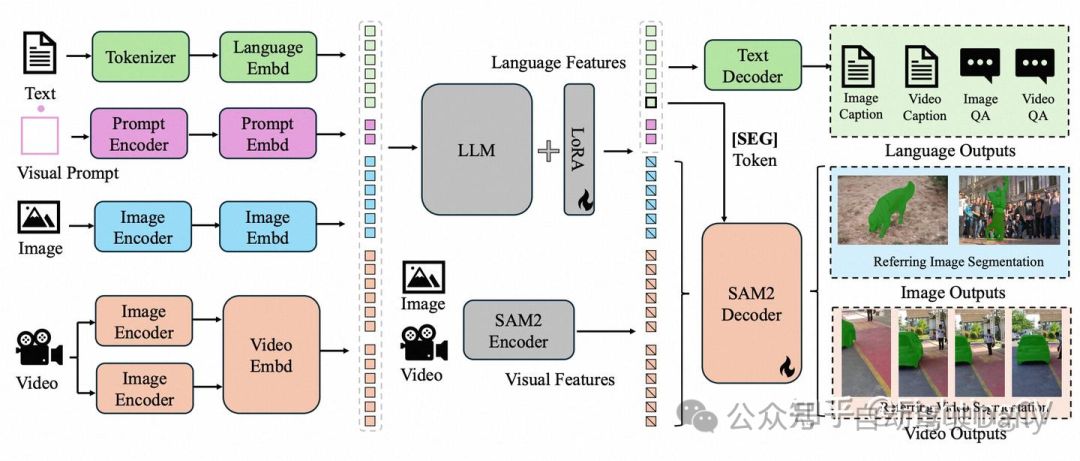
模型首先将输入文本、视觉提示、图像和视频编码为符元嵌入。 然后,这些符元通过一个大型语言模型(LLM)进行处理。 输出文本符元用于生成[SEG]符元和相关的语言输出。 SAM-2解码器接收来自SAM-2编码器的图像和视频特征,以及[SEG]符元,以生成相应的图像和视频掩码。
数据集标注:
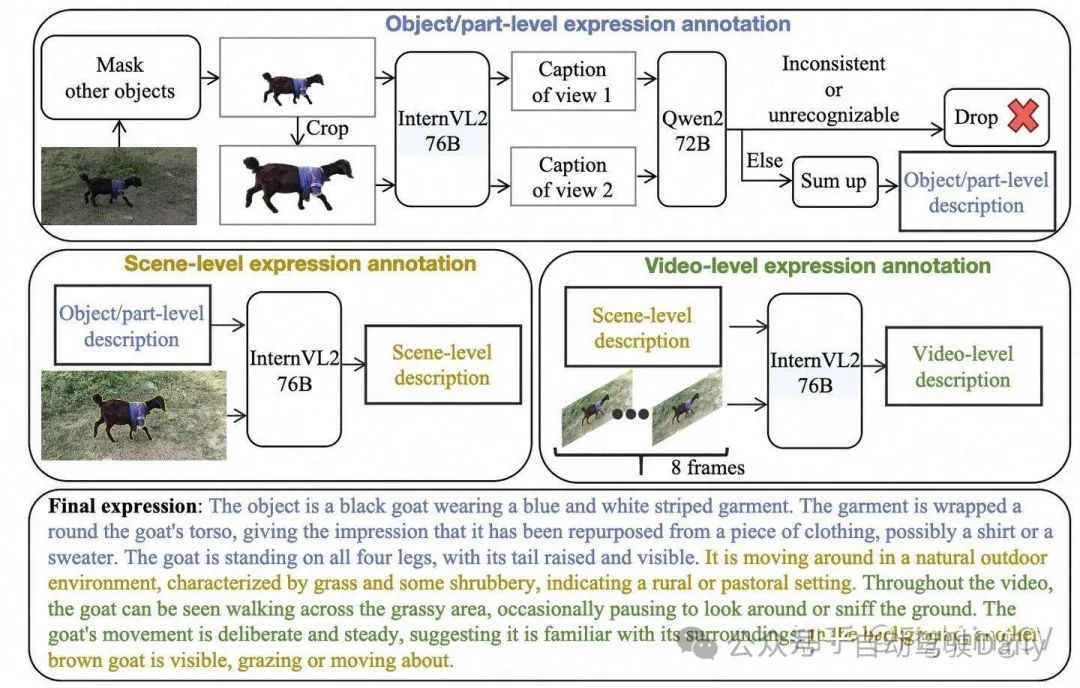
- Object/part-level annotation:将mask区域裁剪输入到LLM里面生成part-level caption
- Scene-level annotation:“黄色轮廓用于突出显示图像中的对象+上阶段的caption”输入到LLM中生成scene-level caption
- Video-level annotation:“黄色轮廓用于突出显示图像中的对象(8帧)+上阶段的caption”输入到LLM生成video-level caption
训练集:
3、LLMDet: Learning Strong Open-Vocabulary Object Detectors under the Supervision of Large Language Models
https://github.com/iSEE-Laboratory/LLMDet
(8* L20* 2 day)
Motivation:
通过为每张图像生成图像级详细描述,与大型语言模型进行协同训练的开放词汇检测器可以进一步提高性能。
Contribution:

- 收集一个数据集 GroundingCap - 1M,其中每张图像都配有相关的定位标签和图像级详细描述。
- 以包括标准定位损失和描述生成损失在内的训练目标对开放词汇检测器进行微调,得到LLMDet。
- 改进后的 LLMDet 反过来可以构建更强大的大型多模态模型
方法:
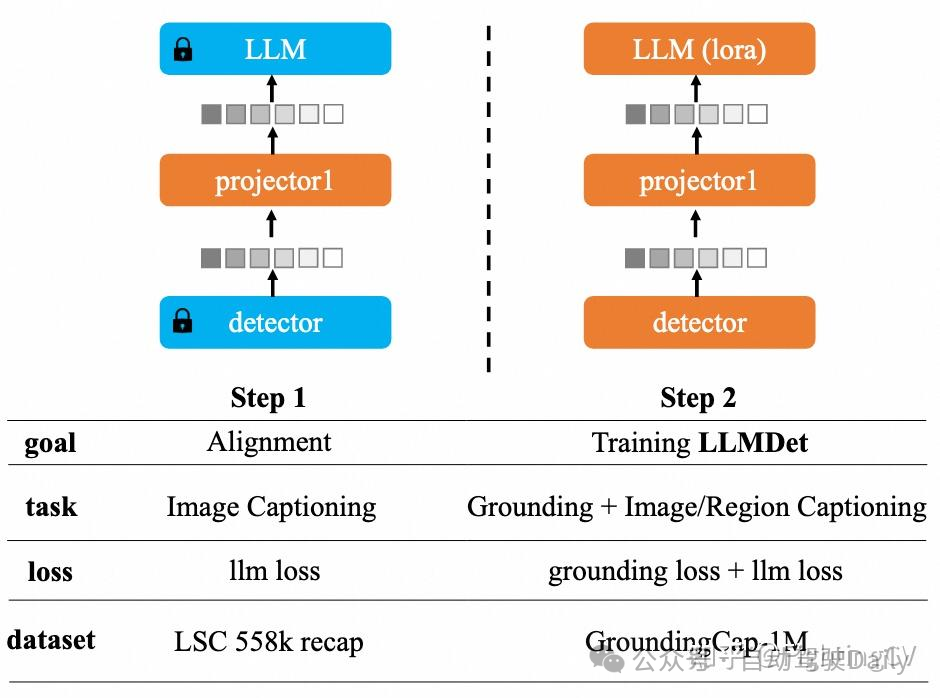
在每一步中,橙色模块是可训练的,而蓝色模块是冻结的。在第一步中,我们训练一个投影器,使检测器的特征与大型语言模型对齐,以便我们可以将大型语言模型集成到检测器中而不破坏预训练的特征。然后,在第二步中,我们使用标准的定位任务和新引入的描述任务来训练检测器。
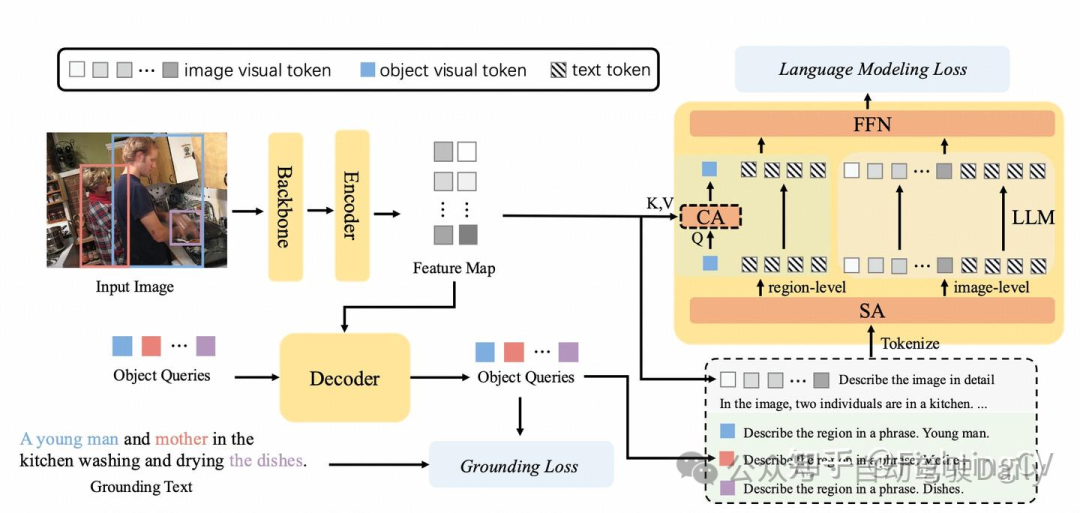
LLMDet 包含一个标准的开放词汇检测器和一个大语言模型(LLM),并在定位损失和语言建模损失的共同作用下进行训练。LLM 旨在使用特征图作为视觉输入生成图像级别的描述,同时使用单个目标查询作为视觉输入生成区域级别的描述,这两种描述通过不同的提示进行区分。在区域级别生成中,只有视觉标记会通过 LLM 中的交叉注意力(CA)模块,这部分用虚线框突出显示。由于图像级别和区域级别生成中的标记数量差异很大,我们分别对 LLM 进行两次前向传播以节省内存和计算资源。在推理阶段可以丢弃 LLM,这样就不会产生额外的成本。
LLMDet 的总体训练目标是定位损失和生成损失的组合:
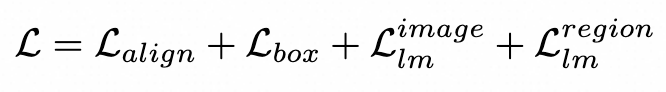
4、Image Segmentation Using Text and Image Prompts
Motivation:
基于CLIP,能够利用图片和文本作为prompt来进行grounding
方法:
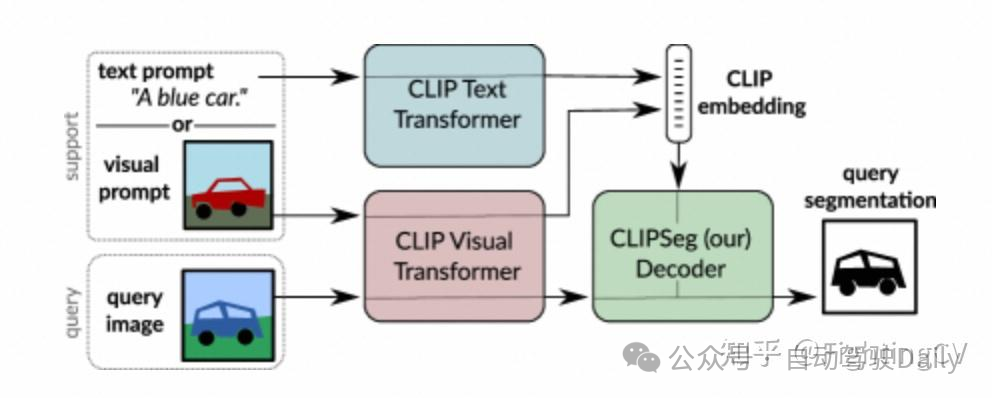
它能够根据任意文本查询或示例图像进行分割。为了实现这个系统,我们采用预训练的 CLIP 模型作为主干,并在其顶部训练一个薄条件分割层(解码器)。 我们使用 CLIP 的联合文本-视觉嵌入空间来调节我们的模型,这使我们能够处理文本形式和图像形式的提示。
5、ReferDINO: Referring Video Object Segmentation with Visual Grounding Foundations
Motivation:

我们提出了ReferDINO,这是一种端到端的RVOS方法,它通过继承基础视觉定位模型强大的视觉-语言理解和空间定位能力,有效地解决了上述问题。
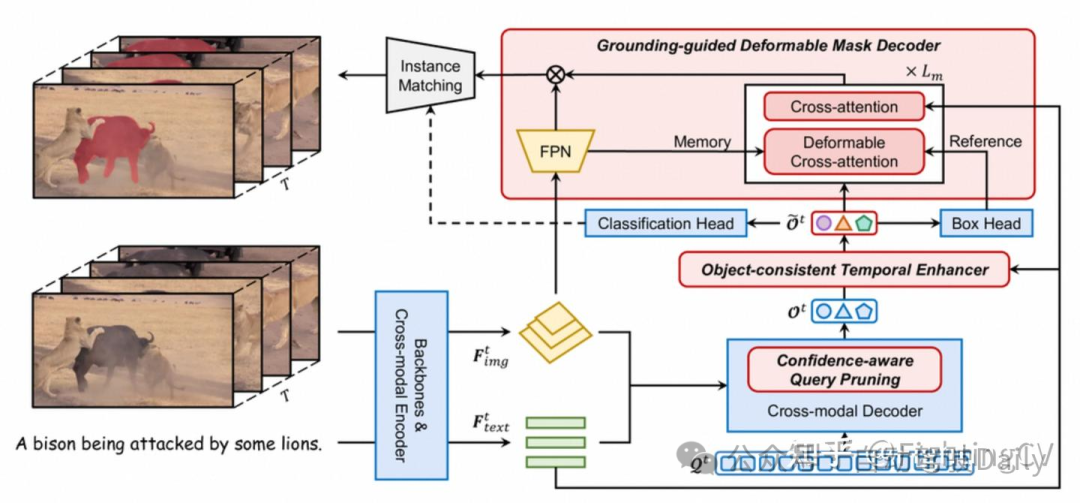
eferDINO的整体架构。 以蓝色着色的模块借自GroundingDINO,而以红色着色的模块是这项工作中新引入的。 基于逐帧目标特征{ t}t=1T,我们的目标一致性时序增强器利用跨模态文本特征实现帧间目标交互。 然后,我们的定位引导的可变形掩码解码器根据位置预测、跨模态文本特征和高分辨率特征图生成候选目标的掩码。 为了进一步提高视频处理效率,我们在跨模态解码器中引入了一种置信度感知查询剪枝策略。 最佳彩色视图。
For 表征
6、VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks
https://github.com/TIGER-AI-Lab/VLM2Vec
Motivation:
- 希望利用VLM进行embeding,在多个任务上表现优异
Contribution:
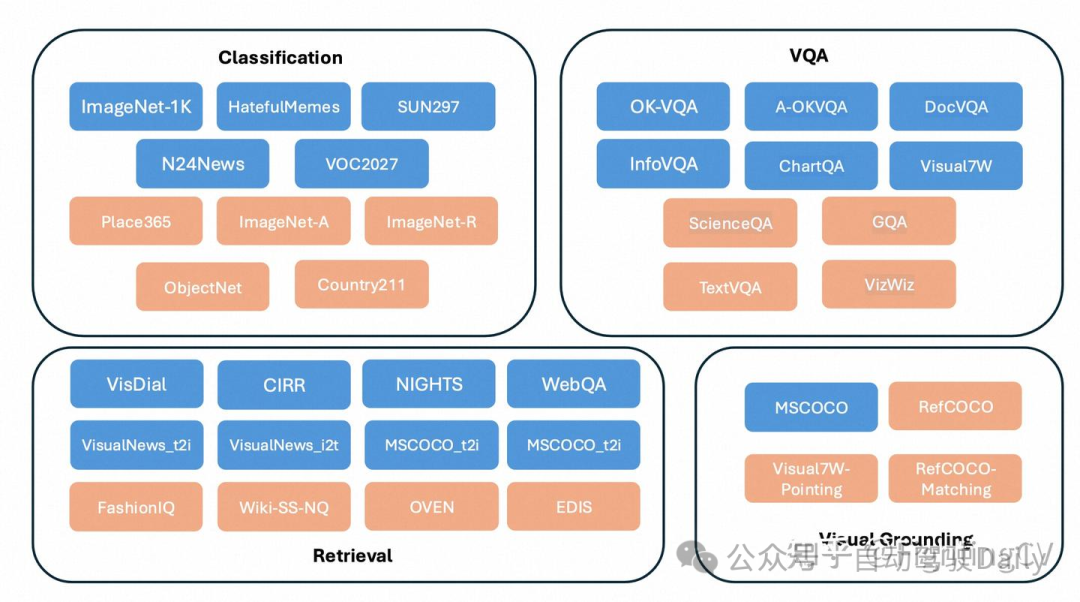
- 提出一种新的基准,MMEB (大规模多模态嵌入基准),其中包含 36 个数据集,涵盖四个元任务类别:分类、视觉问答、检索和视觉定位。(将这些任务都改为排序任务,计算Precision@1)
- 采用Phi-3.5-V和LLaVA-1.6等预训练视觉语言模型作为Vlm2Vec的骨干,利用VLM进行embeding。
方法:
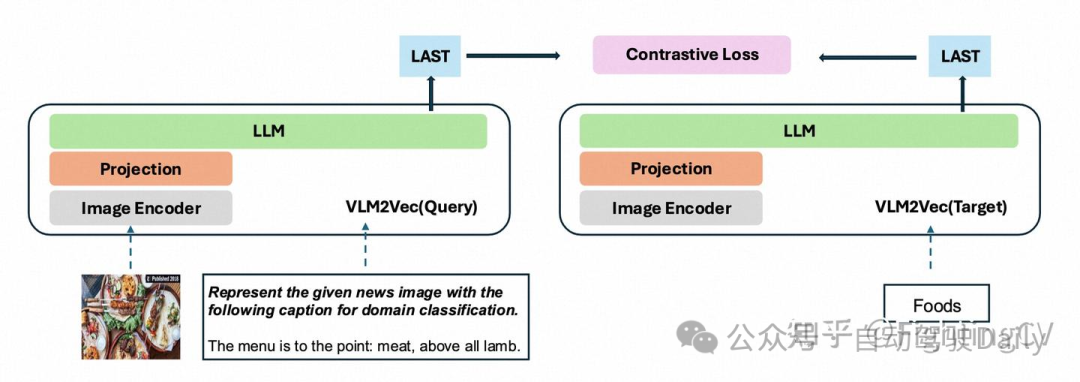
Vlm2Vec 使用 VLM 作为主干来深度整合图像和文本特征。 它通过遵循特定于任务的指令,使用查询和目标之间的对比损失进行训练。 训练数据包括查询和目标两侧各种模态的组合,其中可能包括图像、文本或图像文本对。
7、GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
https://huggingface.co/Alibaba-NLP/gme-Qwen2-VL-2B-Instruct
Motivation:
- 利用MLLM进行单模态检索、跨模态检索、融合模态检索
Contribution:

- 构建了一个通用多模态检索基准UMRB,包含47个数据集,涵盖单模态检索、跨模态检索、融合模态检索
- 基于QWen多模态大模型提出GME模型,用于多模态检索
方法:
利用MLLM提取embedding,利用对比学习进行训练。
8、LamRA: Large Multimodal Model as Your Advanced Retrieval Assistant
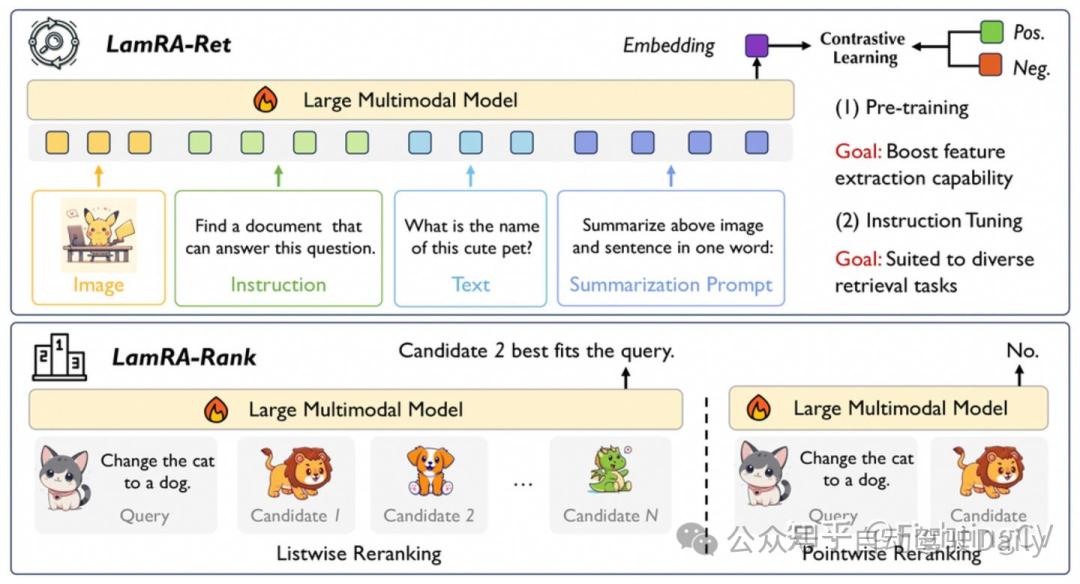
For 分割
9、Segment Anything Model 2
https://github.com/facebookresearch/sam2
Motivation:
将图像分割推广到视频领域。该任务将视频任意帧上的点、框或掩码作为输入,以定义感兴趣的片段,并预测其时空掩码(即 “小掩码”)。一旦预测出小掩码,就可以通过在其他帧中提供提示对其进行迭代改进。
Contribution:
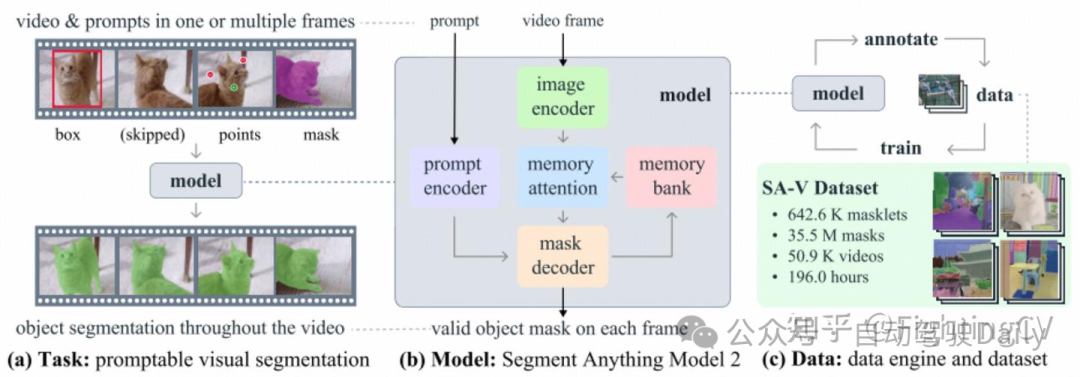
- 提出SAM2,进行图像和视频上的可提示视觉分割(PVS)任务。
- 采用了一个数据引擎,通过使用本文的模型与注释者互动注释新的和具有挑战性的数据来生成训练数据
方法:
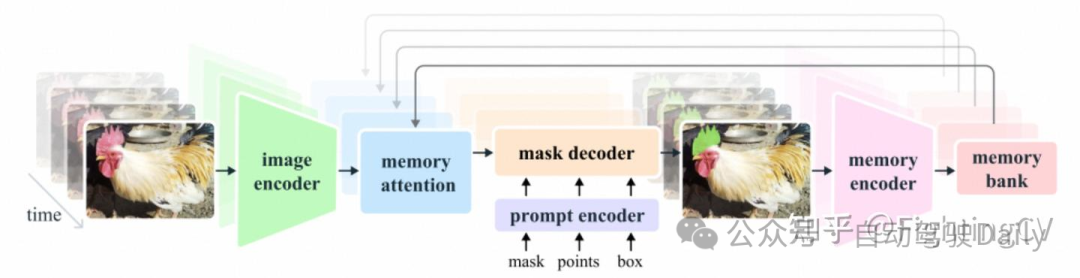
对于给定的帧,分割预测取决于当前提示和/或先前观察到的记忆。视频以流媒体的方式处理,图像编码器每次使用一个帧,并从前一帧中交叉关注目标对象的记忆。掩码解码器(也可选择接受输入提示)预测该帧的分段掩码。最后,存储器编码器转换预测和图像编码器嵌入(未在图中显示),以便在未来帧中使用。
SAM 2解码器使用的帧嵌入不是直接来自图像编码器,而是以过去预测和提示帧的记忆为条件。相对于当前帧提示帧也可能“来自未来”。帧的memory由存储器编码器根据当前的预测产生,并放置在memory bank中以供以后的帧使用。内存attention操作从图像编码器获取每帧嵌入,并在memory bank上对其进行调整,以产生之后传递给掩码解码器的嵌入。
- Image Encoder:图像编码器在整个交互过程中只运行一次,其作用是提供无条件的token(特征嵌入)。我们使用 MAE 预先训练的 Hiera 图像编码器,它是分层的、这样就能在解码过程中使用多尺度特征。
- Memory attention:Memory attention的作用是将当前帧的特征与过去帧的特征和预测以及任何新的提示联系起来。我们堆叠了 L 个transformer模块,第一个模块将当前帧的图像编码作为输入。每个区块执行self-attention,然后cross-attention(提示/未提示)帧和对象的记忆,这些记忆存储在一个记忆库中,接着是一个 MLP。
- Memory encoder:通过使用卷积模块对输出掩码进行下采样,并将其与图像编码器的无条件帧嵌入相加,生成记忆,然后使用轻量级卷积层来融合信息。
- Memory bank:通过维护最多N个最近帧的FIFO记忆队列来保留视频中目标对象的过去预测信息,并将提示信息存储在最多M个提示帧的FIFO队列中。
- Prompt encoder:提示编码器与SAM的相同,可以通过点击(正或负)、边界框或蒙版来提示,以定义给定帧中对象的范围。稀疏提示由位置编码表示,并对每种提示类型的学习嵌入求和,而掩码则使用卷积嵌入并使用帧嵌入求和。
- mask decoder:解码器设计很大程度上遵循SAM,如下图所示:堆叠“双向”transformer块来更新提示符和帧嵌入。与 SAM 不同的是,在 SAM 中,只要有positive的提示,就一定会有一个有效的对象被分割,而在 PVS 任务中,有可能在某些帧上不存在有效的对象(例如由于遮挡)。为了应对这种新的输出模式,增加了一个额外的头,用于预测当前帧上是否存在感兴趣的对象。
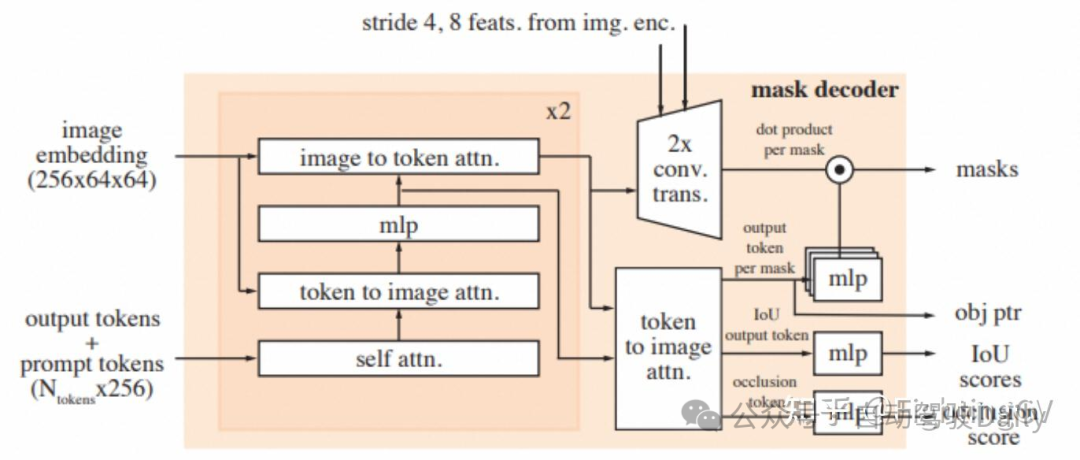
10、Segment Anything
https://github.com/facebookresearch/segment-anything
Motivation:
SAM借鉴了NLP领域的Prompt策略,通过给图像分割任务提供Prompt提示来完成任意目标的快速分割。Prompt类型可以是「前景/背景点集、粗略的框或遮罩、任意形式的文本或者任何指示图像中需要进行分割」的信息。如下图(a)所示,模型的输入是原始的图像和一些prompt,目标是输出"valid"的分割,所谓valid,就是当prompt的指向是模糊时,模型能够输出至少其中一个mask。
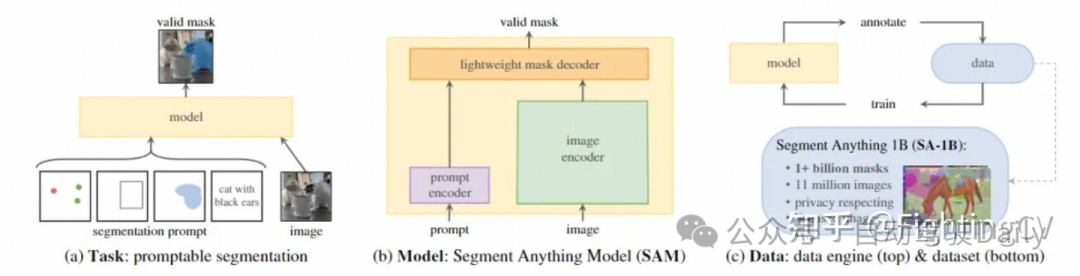
Contribution:
- Task: 这里构建了一个提示分割任务,这类任务在结构分类上,一般体现为多模态的模型;
- Model: 模型框架设计上主干是分割的架构,图像编码器,这里使用的VIT+MAE的组合方式进行训练;提示部分有不同输入的有不同的编码器;一个融合提示编码和图像编码的解码器;
- Data: 数据工程,个人理解这是SAM模型牛逼之处,虽然数据工程这块处理手段看起来比较简单,但是SAM团队给我们展示了大道至简。这种让模型自动标注的思路、细节处理实际有非常大的研究、应用价值。
方法:
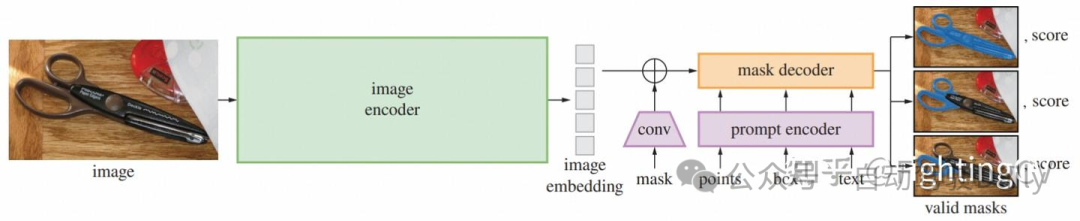
SAM由三部分组成,包括:图像编码器、提示编码器、轻量化的掩码解码器
- Image encoder:这里使用的是基于MAE训练的ViT模型。编码器只在一张图片上跑一次,然后应用到不同的提示。
- Prompt encoder: 提示有离散(points、boxes、text)和稠密(masks)两类。我们通过位置编码[95]来表示点和框,并使用CLIP的现成文本编码器(tip: CLIP模型的文本编码器在其他模型中大量使用,一般这个结构都不会再参与训练)来表示自由格式文本。稠密提示(即掩码)使用卷积编码,并与图像嵌入逐元素求和。
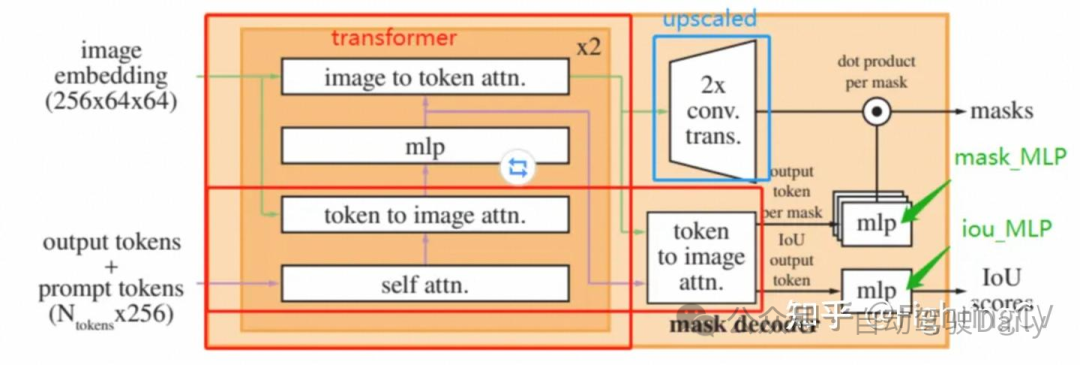
- Mask encoder:掩码解码器有效地将图像编码、提示编码和输出token映射到掩码。
For LLM
11、DeepSeek-V3
简介:
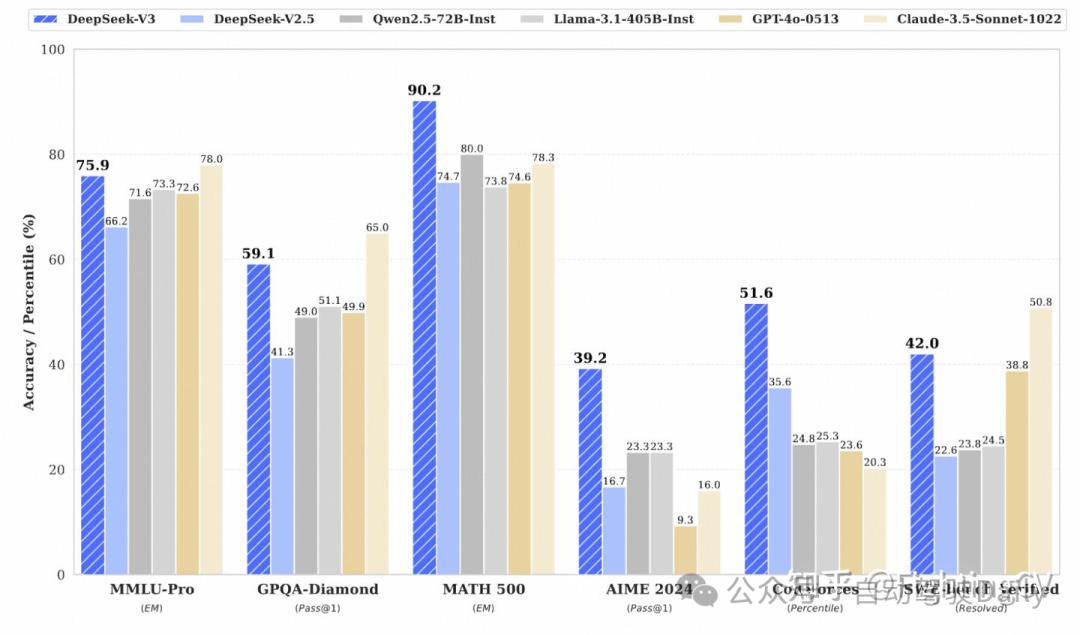
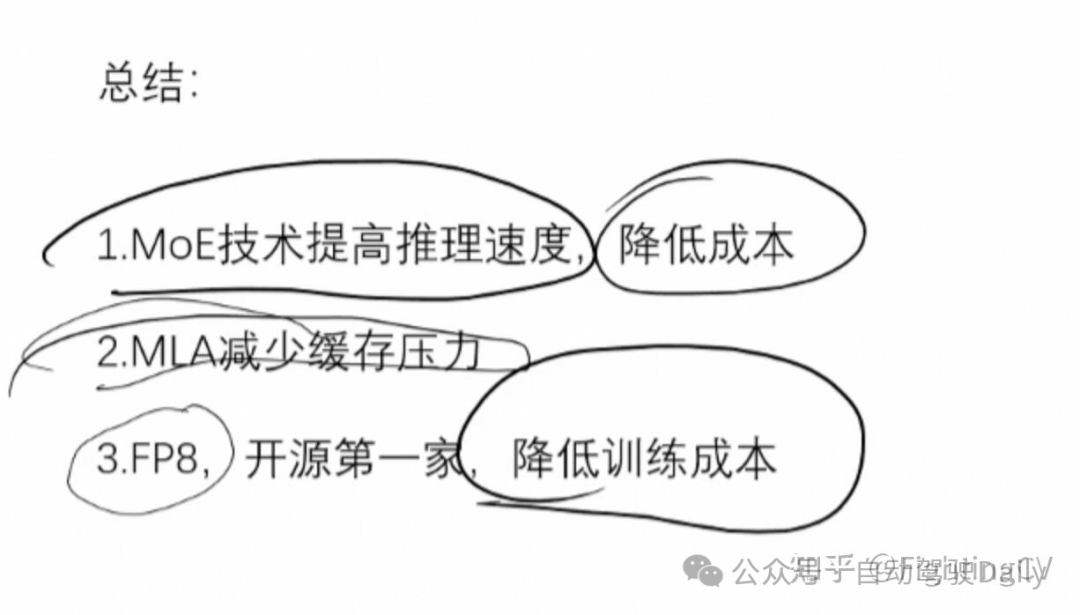
DeepSeek-V3 是一款性能卓越的混合专家(MoE)语言模型,整体参数规模达到 671B,其中每个 token 激活的参数量为 37B。
创新:
- Multi-Head Latent Attention(MLA):
DeepSeek-V3 在注意力机制方面采用了 MLA 架构。设向量维度为 d,注意力头数为 n_h ,每个头的维度为 dh d_h ,在特定注意力层中第 tt 个 token 的注意力输入表示为 ht∈Rdh_t\in \mathbb{R}^d 。MLA 的核心创新在于对注意力键和值进行低秩联合压缩,以降低推理过程中的键值(KV)缓存开销:
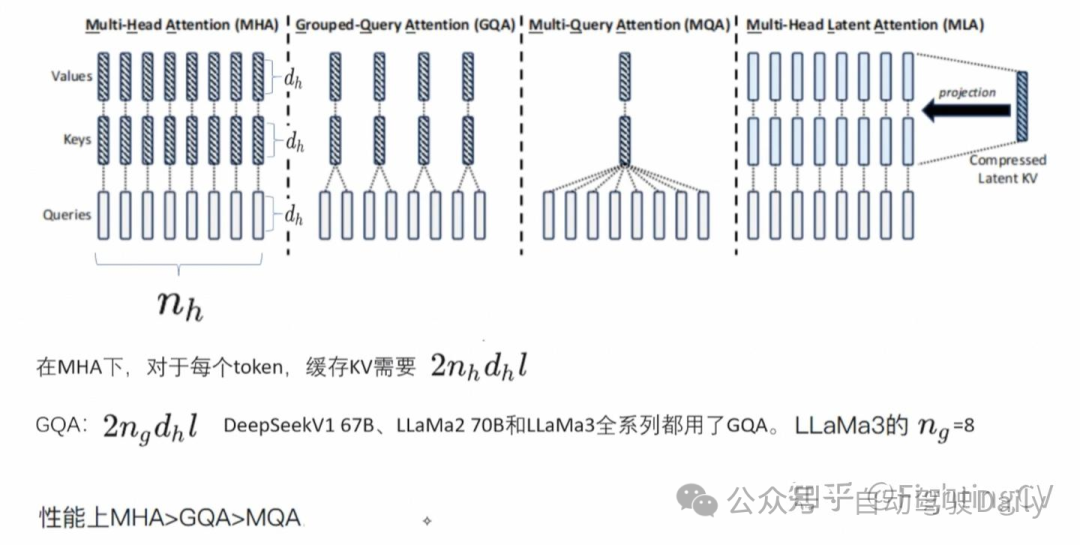
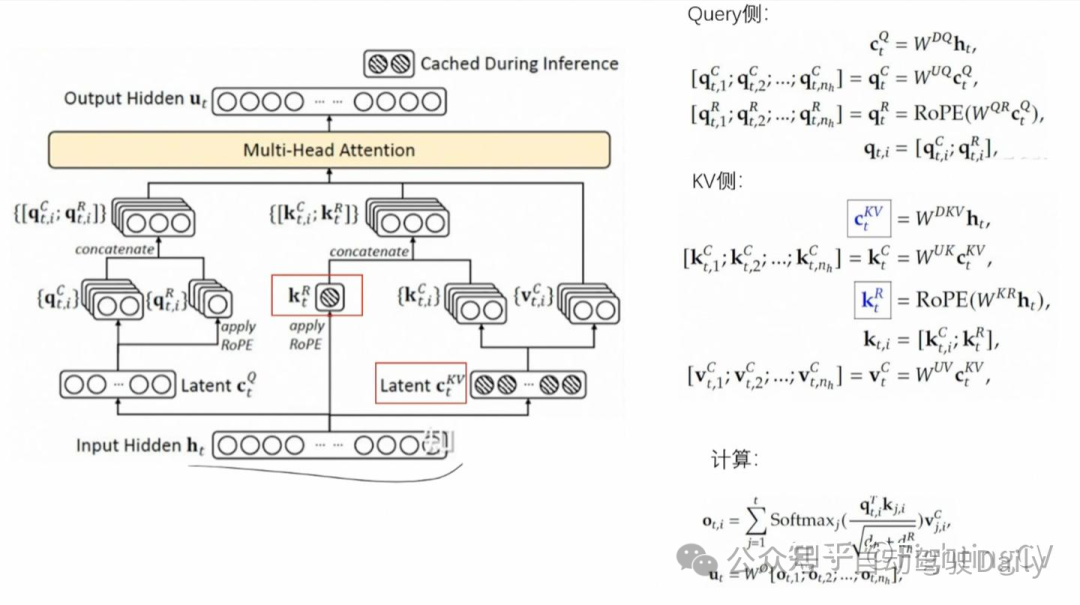
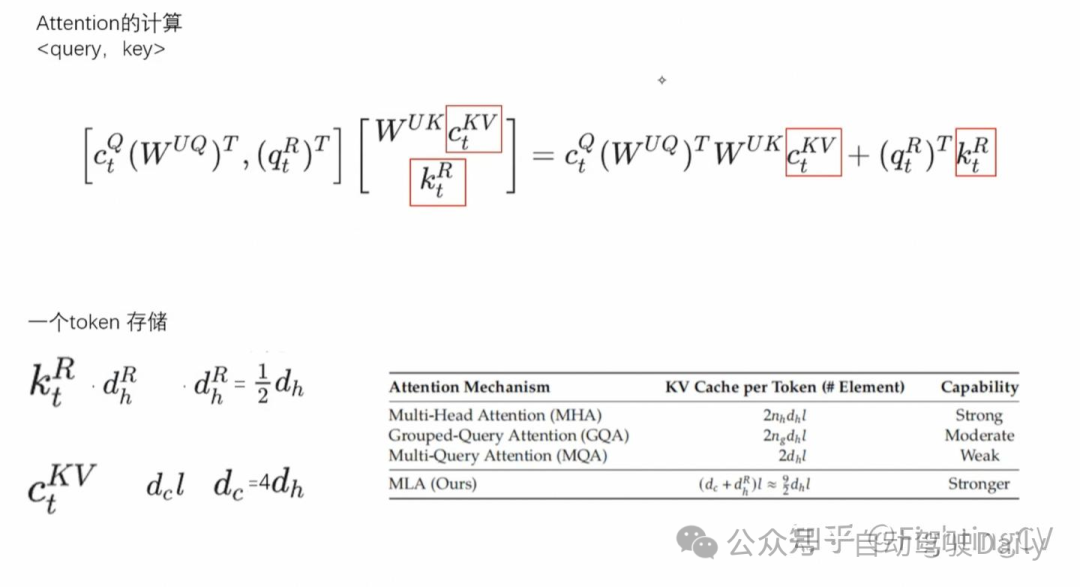
减少K-V cache的缓存
- DeekSeekMoE:
在前馈网络(Feed-Forward Networks, FFN)部分,DeepSeek-V3 采用了 DeepSeekMoE 架构。相比传统的 MoE 架构(如 GShard),DeepSeekMoE 采用了更细粒度的专家分配机制,并创新性地将部分专家设置为共享专家。
对于 MoE 模型,不平衡的专家负载将导致路由崩溃,并在专家并行场景中降低计算效率。传统解决方案通常依赖辅助损失来避免不平衡负载。然而,过大的辅助损失会损害模型性能。为了在负载平衡和模型性能之间实现更好的权衡,研究团队开创了一种无辅助损失负载均衡策略来确保负载平衡。
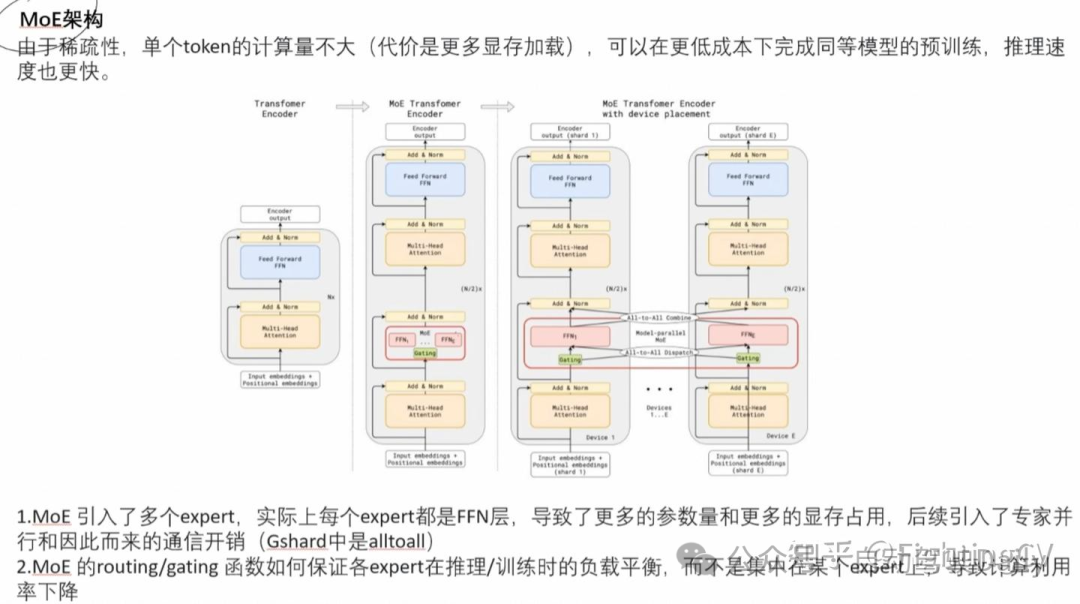
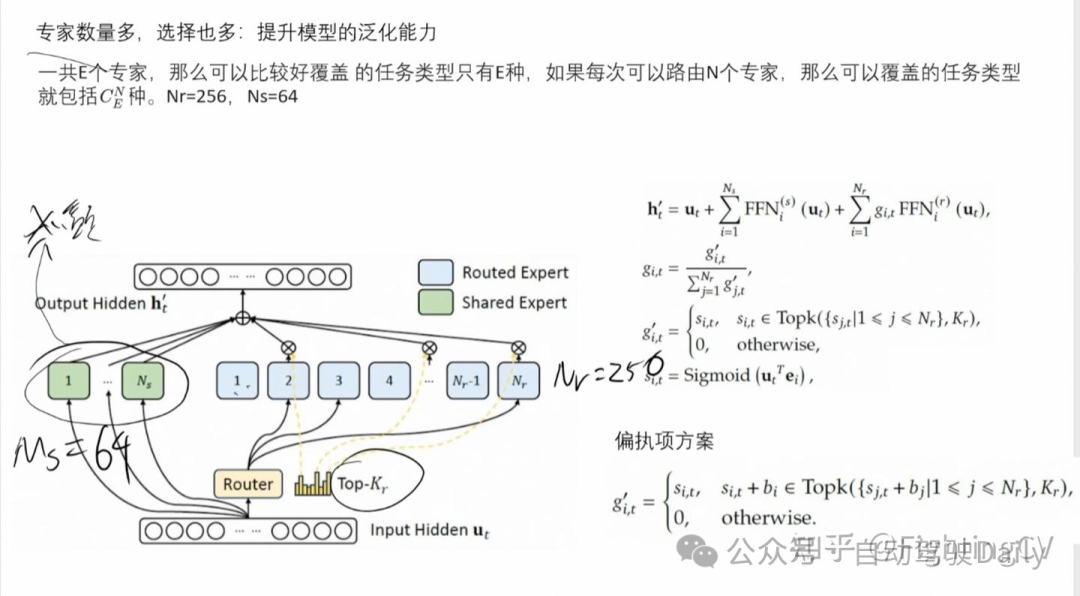

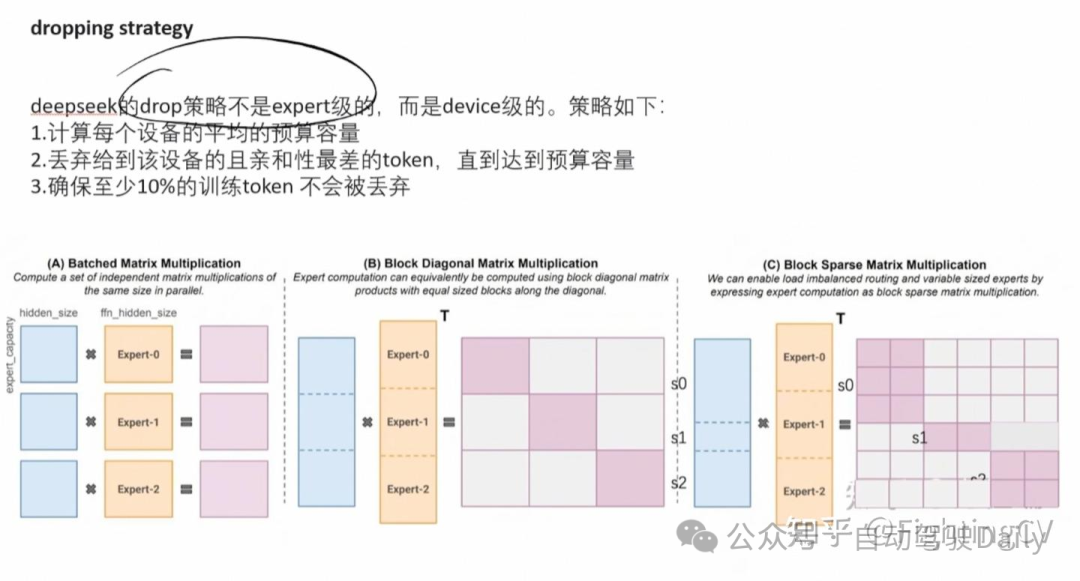
共享和独立专家;考虑每个专家的学习概率;考虑每个node的负载均衡
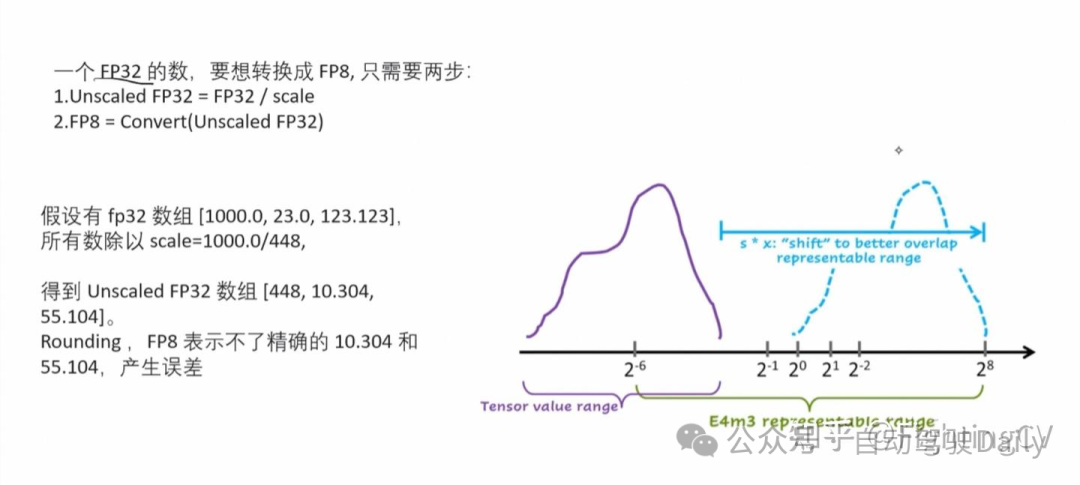
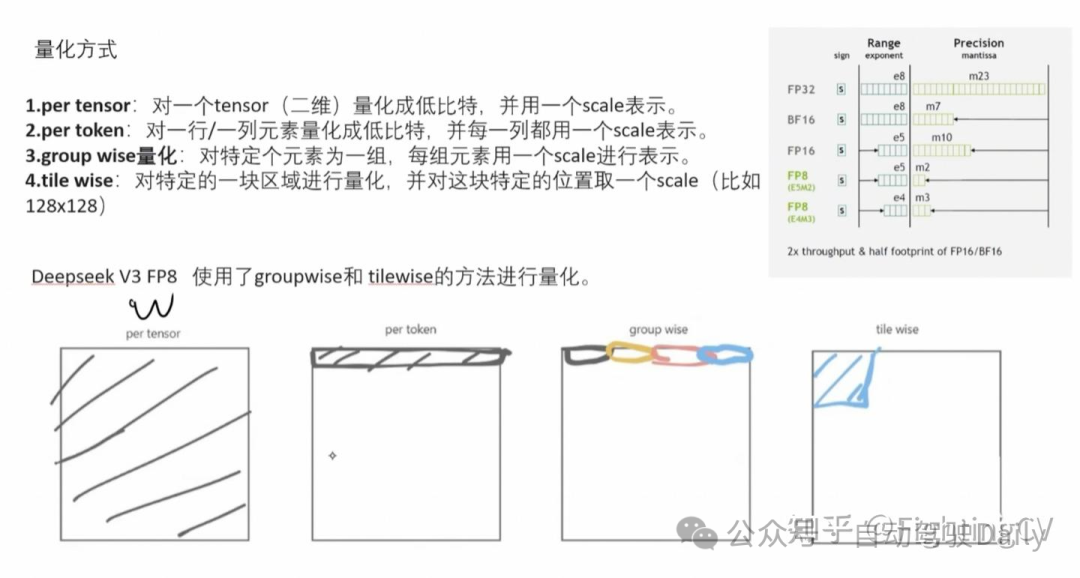
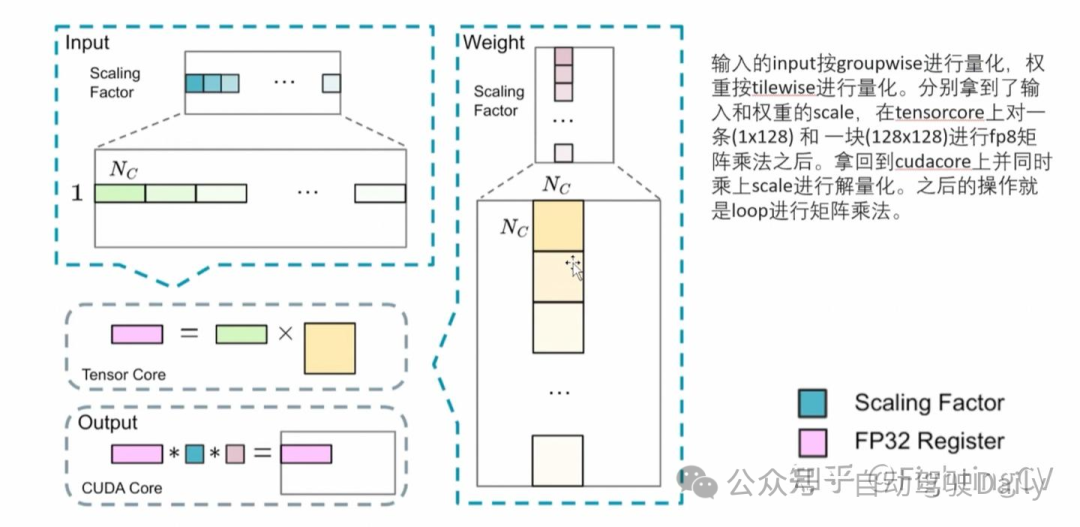
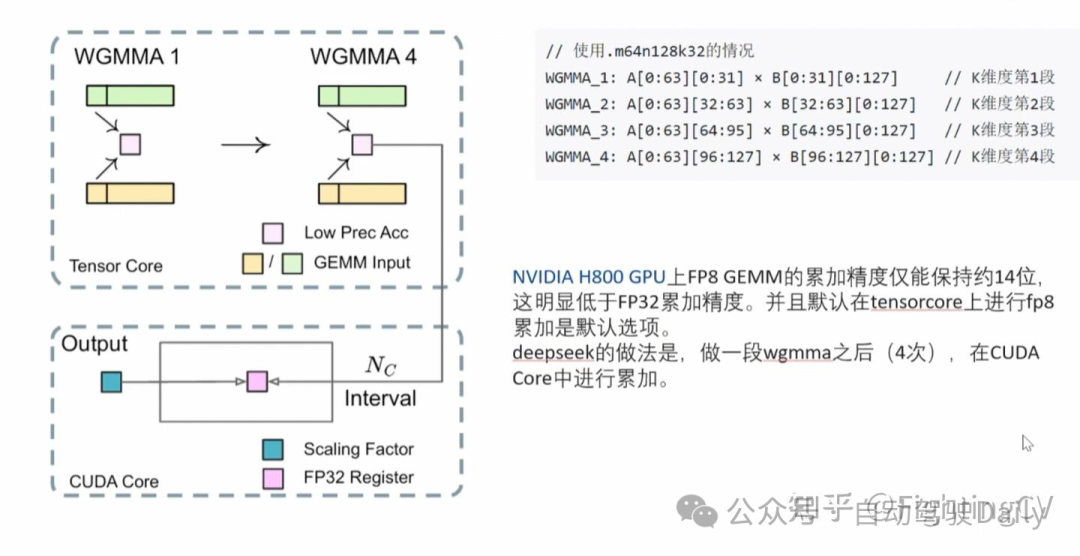
- FP8训练
基于低精度训练领域的最新进展,本研究开发了一种细粒度混合精度框架,采用 FP8 数据格式训练 DeepSeek-V3。

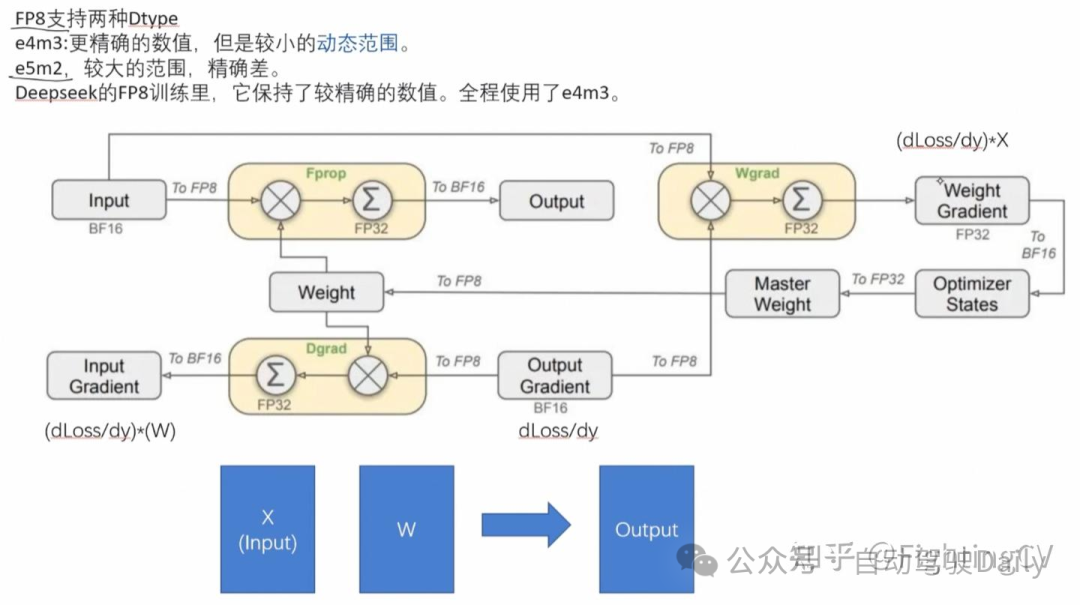
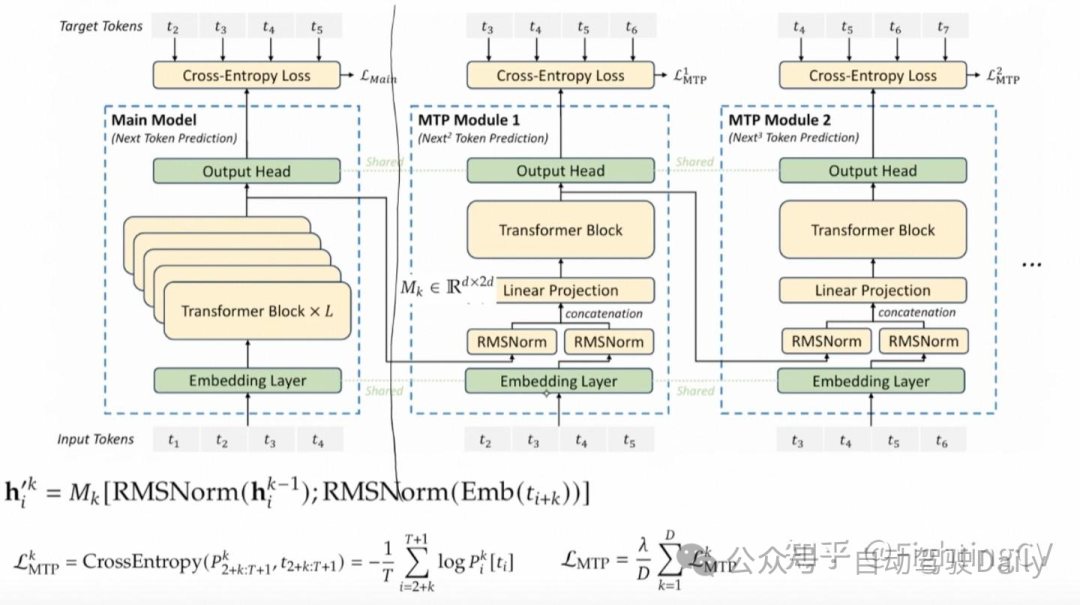
- Multi-Token Prediction:
DeepSeek-V3 创新性地采用了 MTP 目标,将预测范围扩展到每个位置的多个后续 token。
这种设计具有双重优势:
首先,MTP 目标通过增加训练信号的密度可能提高数据利用效率;其次,它使模型能够提前规划表征,从而更准确地预测后续 token。
总结:
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 5195
5195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









