






课程打卡凭证

实验目的
在MindSpore使用KNN算法对wine数据集(UCI Machine Learning Repository)进行分类。
KNN算法
KNN算法,即K最近邻分类算法,它是基于实例的代表性算法。基于实例的学习算法与基于模型的不同,它没有训练的过程,因此不涉及模型训练和优化。
最近邻算法

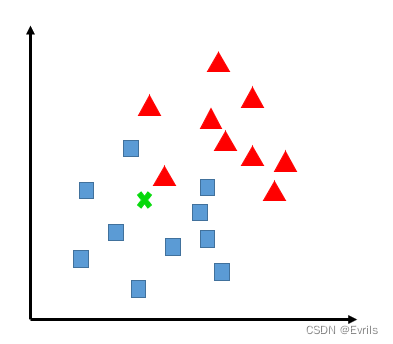
为了判定未知样本的类别,以全部的训练样本作为代表点,计算未知样本与所有训练样本的距离,并且以最近邻者的类别作为决策未知样本类别的唯一依据。如上图所示。
但是,最近邻算法有明显的缺陷,即对噪声数据过于敏感,在下图中,未知样本x就容易误判。因此,引入了K最近邻分类算法。
K最近邻分类算法
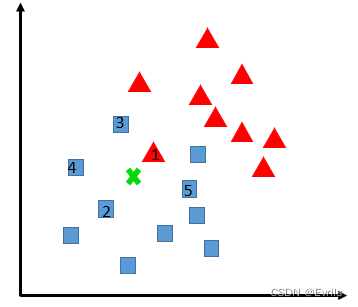
K最近邻分类算法是最近邻算法的一个拓展。它的基本思路是,选择未知样本一定范围内确定个数的K个样本,该K个样本大多数属于某一类型,则未知样本判定为该类型。如下图所示,未知样本x判定为正方形。
KNN算法的实现步骤
1. 计算未知样本和每个训练样本的距离dist
2. 对距离从小到大排序,取前K个样本
3. 统计K个最近邻样本中每个类别出现的次数
4. 选择出现频率最大的类别作为未知样本的类别
实验过程
数据处理
数据准备与加载

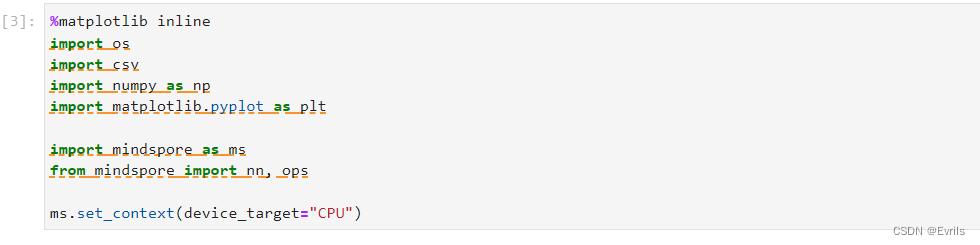
导入必要的库与模块,这里把硬件设备设置为CPU,也可以设置为Ascend。

wine数据集具体如图所示。其中,第一个特征为红酒的类别,后面十三个特征为红酒的十三个属性,详见UCI Machine Learning Repository。
数据处理

这里共178个样本,将第一个特征作为因变量Y,后面十三个特征作为自变量X。

将数据划分为训练集和测试集。
计算距离
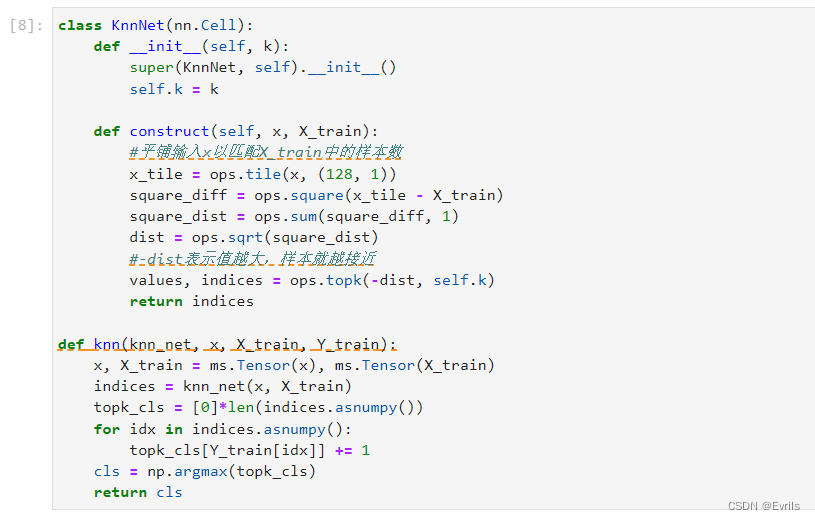
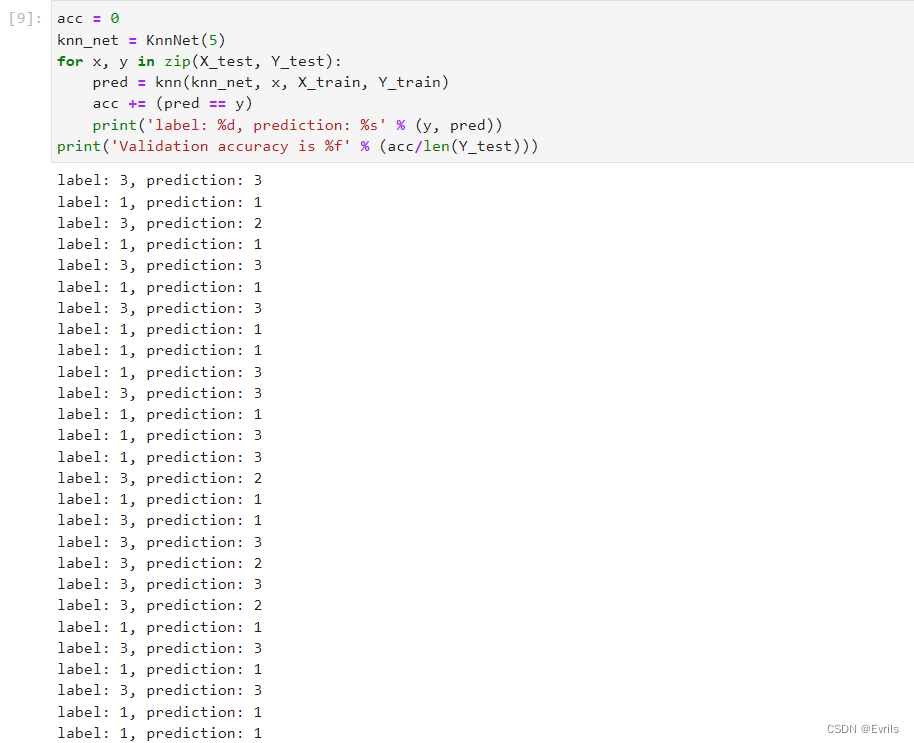
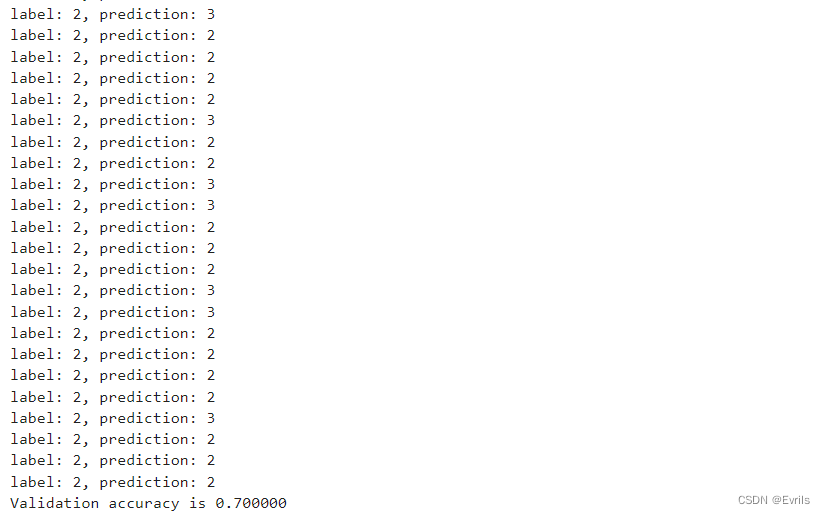
模型预测















 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









