







Transformer取代RNN,在nlp大杀四方之后,也来CV领域争夺市场了,大有取代CNN的趋势。目前关于Transformer在CV领域的应用越来越多,本文选具有代表性的有用于分类的Vit,用于检测的detr,和用于分割的mask2former做了简单介绍。
一. Transformer简介
关于transformer的讲解,这里介绍两篇公众号文章,都是很简单通透的那种。
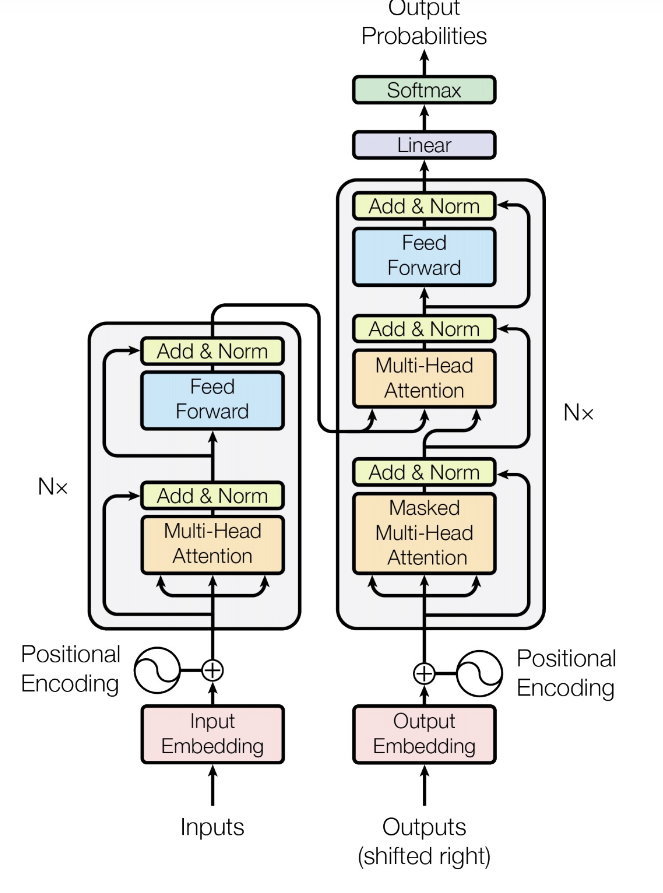
如图就是transformer《Attention Is All You Need》的网络架构,是2014年提出的网络,忽略了CNN和RNN, 全部使用自注意力机制。
网络由输入、输出、Encoder和Decoder部分组成,Encoder和Decoder都可叠加N次。
先看输入部分,把输入经过Embedding映射之后,对于每个输入,得到一个embedding vector,又叫token。在文本领域,比如word2vector把单词映射成一个特定维度的向量,在图像领域把每个patch通过卷积映射成一个特定维度的向量,这个过程就叫embedding。直接embedding后的序列化数据是没有位置信息的,所以再叠加一个positional encoding,一般采用直接向量相加的方式构成整个输入。
然后看Encoder部分,从图中就可以看出,Encoder主要包含两个结构,一个multi-head Attention和一个feed forward网络,然后还在两个结构上加上了残差连接。feed forward很简单,就是一个全连接网络,所以Encoder的主要亮点就是Multi-Head Attention。
要想弄清楚Multi-Head Attention,首先要搞清楚Self-Attention。在学习CNN的时候,相信很多人都听说国Attention, 比如Channel Attention,不过那些是建立在输出对不同输入的注意力,而Self-Attention,是建立在输入之间的相互注意力,即输入的某一个token,在经过编码后,其他token(包括自己)各自奉献的比例权重有多少。
对于每一个token, 都和三个待学习的矩阵、
、
相乘,得到三个向量
、
、
,那么,
如何理解上式呢,假如我们的一共四个token,每个token是512维,假如 、
、
的维度是(512, 64),那么得到的每个token的
、
、
的维度都是(1, 64), 此时,选中一个token的查询向量q, 然后和其他所有token的k做内积得到权重分数,然后权重分数经过softmax归一化在0-1区间,再乘以每个token的v的加权平均就得到注意力后的自身表示了。至于为什么要除以
呢,这是因为把不同q、k的内积放在同一个range下面,避免过大时候softmax的对应项输出过大,造成其他项梯度消失。这个过程就是一个自注意力过程,用代码表示会清楚一些,参考下述代码。
import torch
from torch import nn
import math
class BertSelfAttention(nn.Module):
def __init__(self):
super(BertSelfAttention, self).__init__()
# x : (4, 512) 每一行为一个token, 每个token的维度512
self.query = nn.Linear(512, 64, bias=False) # nn.Linear为W_q : (512, 64)
self.key = nn.Linear(512, 64, bias=False) # nn.Linear为W_k : (512, 64)
self.value = nn.Linear(512, 64, bias=False) # nn.Linear为W_v : (512, 64)
def forward(self, x):
Q = self.query(x) # (4, 64)
K = self.key(x) # (4, 64)
V = self.value(x) # (4, 64)
attentison_scores = torch.matmul(Q, K.transpose(-1, -2)) # (4, 4)
attentison_scores = attentison_scores / math.sqrt(64) # (4, 4)
# 针对每一行进行softmax,即每个token的表示中,其他token(包含自己)的各自占的权重
attentison_scores = nn.Softmax(dim=-1)(attentison_scores)# (4, 4)
out = torch.matmul(attentison_scores, V) # (4, 4) * (4, 64) = (4, 64)
return out
而所谓的multi-head attention,不过是在多个attention,我们有多个查询/键/值权重矩阵集(Transformer使用八个注意力头,因此我们对于每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
然后看Decoder部分。从图中可以明显的看出,Decoder主要是Masked Multi-Head Attention和Encoder-Decoder组成的。
因为Decoder是按照序列顺序一个一个解码出输出的,后面的输出依赖于前面的输出,所以对于输出端的Self-Attention来说,要mask掉未来的信息。这个比较好理解,如下图所示:

Decoer的主要不同就是Encoder-Decoder Attention, 从网络图中可以看出,对于Decoder部分的Multi-Head Attention, 既有来自于Output的输出,还有来自于Decoder的输出。其中来自于Decoder的输出就与这里的Multi-Head Attention组成了Econder-Decoder Attention。在Decoder中,我们知道Attention就是每个token都有三个向量q、k、v,那么在Encoder-Decoder中就是用Decoder的q,来与Encoder的k和v来做注意力计算。从网络图中我们也可以看出,Encoder的输出到Encoder-Decoder Attention连了两条线,Mask Multi-Head Attention的输出到Encoder-Decoder Attention连了一条线。
- Key:从Encoder的输出中计算
- Value:从Encoder的输出中计算
- Query:从Decoder之前的输出中计算
注意,解码过程中,Encoder输出的K,V都是不变的。整个网络的Output Probabilities为长度为词汇表大小的概率向量v,取概率最大的一个词汇为当前解码出的输出。
二. VIT
VIT(Vision Transformer)是2020年Google团队提出的将Transformer应用在图像分类的模型,成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究。
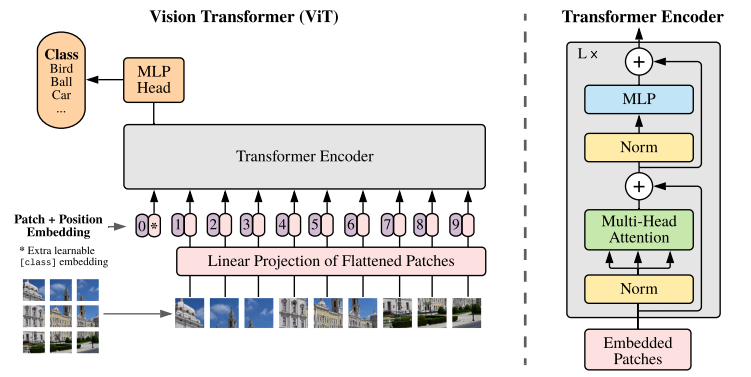
1)Patch+Position Embedding
将图片分为固定大小的patch,patch大小为16x16,patch经过embeding后得到token(由此可见图像分辨率越大,分出的patch越多,token越多)。embeding的过程在实际应用中直接用卷积实现。对于每一个patch,都有一个位置编码,如图中的0-9,位置编码向量维度与token相同,两者直接sum作为下一步的输入。需要注意的是,这里有一个用于Extra leanable class embedding,用*表示,这个*是一个用于分类的向量,维度与token也一样,和其他token组成seq,送入Transformer Encoder.
2) Transformer Encoder.
在上文中已经详细介绍了Transformer。Vit网络中,也只是使用了Transformer的Encoder部分。
3)MLP Head
MLP Head只是一个线性全连接层。最后会将特殊字符 * 对应的输出 作为encoder的最终输出 ,代表最终的image presentation进行分类。
可以看出,VIT结构简单,易于拓展。就是图像patch化后直接套transformer, 且Encoder部分可以N次叠加构建更大的模型。
ViT原论文中最核心的结论是,当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果
但是当训练数据集不够大的时候,ViT的表现通常比同等大小的ResNets要差一些,因为Transformer和CNN相比缺少归纳偏置(inductive bias),即一种先验知识,提前做好的假设。CNN具有两种归纳偏置,一种是局部性(locality/two-dimensional neighborhood structure),即图片上相邻的区域具有相似的特征;一种是平移不变性,即相同的卷积核在图像不同位置能检出相同的特征(所以才能参数共享)。当CNN具有以上两种归纳偏置,就有了很多先验信息,需要相对少的数据就可以学习一个比较好的模型,而Transformer需要大量的数据学习这些先验知识。但但是使用基于CNN的方法还是存在感受野有限的问题,不能很好的建模长远的依赖关系(全局信息),而基于transformer的方法可以很好的建模全局信息。
三. DETR
【2020】End-to-End Object Detection with Transformers
3.1 网络架构
DETR(Detection Transformer)是第一篇将Transformer应用到目标检测方向的算法

如图为DETR(detection transformer)的网络架构图。从图中可以看出,此网络主要包含三个部分:
1) Backbone: 就是一个很简单的额CNN网络,比如ResNet,用来为输入图像做embedding, 经过CNN后得到featuremap。在featuremap中,每一个像素作为一个token使用,通道数C即token的维度d。
2)Transformer and Parallel Decoding: 经过backbone后的featuremap flatten一下就组成了序列化的token,将这些token送入transformer,来学习序列到序列的映射。
encoder部分基本和transformer一致,只是每层都增加了position encoding。
decoder跟transformer不同的是,是使用并行解码的,而不是跟机器翻译一样采用自回归的方式one-by-one的解码。如果我们需要预测出N个bbox,那就直接用N个bbox的object queries作为decoder的embeding input。然后跟transformer一样,用self-attition和encoder-decoder attition组成decoder部分。需要注意的是,这里的object queries是根据position encoding网络学习出来的。
3)FFN
FFN就是一个前馈网络,用来预测最终的N个box的c(class)和b(bbox)
3.2 集合预测和损失函数
从对网络结构的分析来看,DETR预测是一个box的集合,直接预测N个box出来,是一个postprocessing-free的方法。这也是DETR的最大贡献,就是提出了目标检测的新范式——Set Predcition
那么在集合预测中,我们的ground truth也要做成集合,和prediction对应上才行,实际做法中就是标注label时把没有目标的区域标注成 ϕ ,然后建立Set Prediction的loss, 这也是DETR的一大亮点,就是二分图匹配。

如上就是DETR的损失函数,其中采用匈牙利匹配算法。这里的匈牙利匹配算法计算代价矩阵时,有分类代价和box边框代价,即

上公左边为分类代码,是交叉熵。右式是box的代码,其中为L1距离和IOU距离组成,通过一个超参数调节两者的比重:
![]()
3.3 DETR的理解
vit和detr其实都是使用了CNN来降采样,从而降低token数量来减少模型参数量级。只不过vit只用了transformer的encoder,而detr把decoder加进来解码预测box集合。至于为什么不是采用自回归,而是并行解码呢,因为对于检测任务来说,box之间并不像语言翻译那样,强烈的依赖上下文,所以直接并行解码是一个更好的选择。
1)优点
self-attition应用的是全featuremap的注意力,所以基于transformer架构的模型,对于上下文的关系是比较敏感的,比如对于相邻物体检测比较好,对于大目标检测效果比较好。
2)缺点
detr这种使用全局注意力的方式,与cnn关注于局部不同,r对于小目标的检测效果不太好。
由于transformer架构本来就是参数量比较大的,所以模型的复杂度较高,需要使用大量的数据训练,训练时间较长。
所以在此基础上,detr产生了很多变种,比较典型的有2021年的Deformable DETR,即稀疏的detr,就是把其注意力模块只关注参考周围的一小组关键采样点。Deformable DETR可以实现比DETR更好的性能(特别是在小目标上),训练时间减少10倍。COCO基准的大量实验证明了算法的有效性。
包括2021年底提出的Swin Transformer,其实也是沿着把self-attention限制到一定区域的做法来降低复杂度,swin transformer使用windows来把注意力限制在窗口内,聚焦了局部特征,mmdetection里有具体的实现。
四. Mask2Former
Mask2Former来自于MaskFormer, MaskFormer很大程度上采用了DETR的思想做语义分割和全景分割。
现在的方法通常将语义分割制定为per-pixel classification任务,而实例分割则使用mask classification来处理。
MaskFormer的观点是:mask classification完全可以通用,即可以使用完全相同的模型、损失和训练程序以统一的方式解决语义和实例级别的分割任务。

上图为MaskFormer的网络结构图,从图中可以看出,网络主要由两个分支组成,一个为picxel decoder分支,一个为transformer decoder分支,最后混合两个分支,接全连接后实现不同的任务。
- pixel decoder: 就是像素上采样。图像经过backbone和pixel decoder得到深度语义表示;
- transformer decoder: 借鉴DETR的object queries, 这里也使用N个queries, 解码成N个mask embeddings和N个class predictions。同样的,这里的N是大于类别K的,ground truth中不存在的类别用空来表示,建立与predictions的loss。同样使用bipartite matching loss。
- semantic segmentation:Head模块,最终产生
的输出。
maskformer的基本思想是把语义分割、实例分割用一个统一的框架、损失和训练过程来实现,都定义为掩膜分类任务,如果是语义分类任务在推理阶段加一个组合层即可获得预测结果。maskformer与detr思想类似,都是去除人工先验,把实例分割作为一个集合预测问题来看待。
mask2former是Facebook团队在2021年底提出的基于Transformer的端到端的检测、分割框架,是对2021年maskformer的进一步改进。
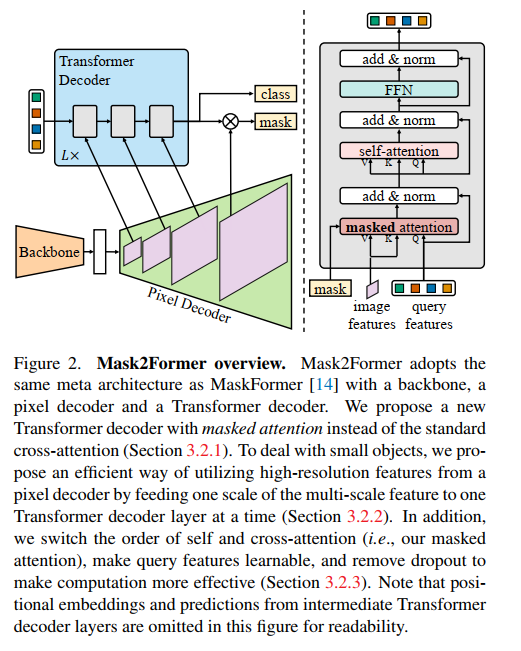
如图为Mask2Former的网络结果,从图中可以看出,mask2former在maskformer的基础上主要做了2个方面的改进。
1)mask attention
原来的attention是针对全局token来做的,mask attention是只关注那些前景toekn,忽略背景token,依旧是通过降低attention的作用区域来降低参数的做法。对于原始的attention (带残差链接的),可以表示为下列形式:

mask attention可表示为下列形式:

从公式中可以看出,在transformer decoder中,下一层只关注上一层mask prediction的前景区域。
2) 增加多尺度特征
在transformer decoder的不同层中,加入pixel decoder中的不同层作为输入,这些不同分辨率的层同时也都加入了正弦位置embedding和一个可学习的尺度embedding。也就是把pixel decoder的不同层作特征金字塔分别输入到transformer decoder的不同层中,这样作为特征金字塔,可以提升小目标的识别效果。














 5127
5127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









