







CV-transformer
VIT
transformer

sequence结构采用的是RNN网络,后面时刻的信息依赖于前一时刻,存在无法并行运算的问题。
CNN没有时序上的依赖可以进行并行运算,但CNN倾向于提取局部信息,没有全局视野。
Transformer的优势:
并行运算、全局视野、灵活堆叠能力。

VIT结构设计

VIT采用原版transformer的编码端。
VIT输入端适配
将图片进行切分,然后进行编号,送入至网络中。
- Patch 0:为了整合信息的向量,即将整个图片的信息形成一个可学习的向量,用这个向量表示这个图片的信息,可用于后续分类。
- 位置编码:将图片进行切分后,图像失去了位置信息,transformer的网络特性决定了其内部运算是空间信息无关的,因此设立一个位置信息编码送入至网络,即利用一个可学习的向量来进行位置编码,将patch向量和位置向量直接相加组成输入。
- 数据流:输入图片
(
b
,
c
,
h
,
w
)
(b,c,h,w)
(b,c,h,w),切分后图片的输入维度
(
b
,
N
,
P
2
c
)
(b,N,P^2c)
(b,N,P2c),其中
N
=
h
w
/
p
2
N=hw/p^2
N=hw/p2,N为切分块数,P为每块的边大小。Linear projection of flattened patch:先拉平再降维。

训练方法
先在大数据集上进行预训练,再在小数据集上微调。
迁移过去后,将原本的MLP head换掉,换成对应类别数的FC层。
处理不同尺寸输入的时候,需要对位置编码的结果进行插值
attention距离和网络层数的关系
attention的距离可以等价为conv中感受野大小

可以看到越深的层数,attention跨越的距离越远;但在最底层,有的head也可以覆盖到很远的距离,这可以说明负责global信息整合。
分类结果和什么有关

整体来看模型注意力集中的地方都和分类的语义有关。
PVT
pyramid vision transformer(金字塔VIT)
VIT缺点
- 显存占用
模型中参数、模型每一层的输出、BP时的参数、优化器中的一些参数都会占用显存。 - 表示方法

- 难以用在下游任务中
PVT意义
展示了纯transformer在CV下游领域内的应用方式,引发了什么是一个好backbone的思考
模型总览

CNN有特征金字塔结构,可以提取出不同size的feature map。VIT是直筒型的结构,即feature map的size在一开始就固定,因此VIT用于下游任务较为困难。那么,PVT引入金字塔结构,每个block是一个VIT,提取出不同size的feature map。
PVT模型结构

直筒型结构的缺点
VIT中feature map的分辨率依赖于patch size。但是最佳的patch size与输入图片相关。

图片越简单,需要切的片越少。
但是,在下游任务中,高分辨率是必须的,即切片数越多可能越好,比如语义分割中。
并且直筒型结构无法灵活地调整显存开销
图像金字塔
当一种分辨率的feature map无法很好表示时,可以采用多个
VIT使用FPN地困境 - MHA的困境:q,k的数量和切分patch的大小相关。patch越小,q,k越多,MHA计算越慢,显存占用越高;patch越大,feature map分辨率越低,会影响到下游任务的性能。
解决方案
人为限制K、V的个数。
swin transformer
VIT的缺点
- 显存占用:token的数量
token是指模型运行中最小的处理单元,VIT中的token是指一个patch,token的数量就是patch的数量。 - 表示方法:token应该多大
- 难以用在下游任务

transformer迁移到CV中的两个挑战 - 物体尺度不一:利用分层结构(pyramid)来解决该问题
- 图像分辨率大:即切片数量大,那么为了可以在高分辨率上运行,限制attention的计算范围。
swin transformer结构

- patch merging:切片(token)合并,即将之前stage切分的token重新合并成一个,以便后续的切分。每个stage开始前做降采样,来缩小分辨率,并调整通道数进而形成更有层次化的设计,并节省一定运算量。
W-MSA
MHA的困境:

- 解决方案:swin transformer采用window multiscale self attention,将attention的计算限制在同一个窗口内,使得复杂度降到了O(n)(layer采用的是W-MSA)。存在问题:window和window之间是不相关的,缺乏global性。因此在切分时,为了使window之间存在交叉,采用其他切分方法。

SW-MSA
W-MSA存在问题:硬性的限制会丢失全局信息,限制了模型能力,因此需要一个跨window的操作,增强window间的交互。

移动切分后,window的数量变多,之前不同window之间会有交互,但window的尺寸变得不一样了。因此,可以采用padding的方式将window的尺寸变得一样,在mask掉其他值,这样就可以直接调用原本的方法。


相对位置编码
绝对:对于每个位置生成一个固定的位置编码
相对:当前位置相对于其他位置,当前位置编码是多少。且相对位置编码的index是对每个window内的patch写死的,不可学习的。
DETR
背景(以往方法的问题)
目前的方法都不直接,即无论是单阶段还是两阶段,无论是anchor based还是anchor free的,它们都无一列外地需要使用后处理方法:NMS来过滤掉冗余地预测框。目前的方法都是基于dense prediction,在原理上,这种操作方式不符合人类识别物体的方式。
DETR的研究意义
- DETR将目标检测作为一个set prediction(集合预测)问题。
- 简洁高效,可以去除诸如NMS、anchor生成的先验知识操作。
- 设计了一个set-based的全局损失函数,并采用transformer的encoder-decoder结构。
- 原理简洁,无需特殊库的支持
目标检测简介

目标检测其实是两个问题:定位(localization)和分类(classification)
以往方法: - RCNN类型:将检测分为[定位,分类]两个阶段来操作,即预定位->crop->分类(散步)。
- yolo系列:单阶段检测器,一次前向解决定位+分类问题
- fcos类型:anchor free的方法,在feature map上的每个点预测结果。
这种方法都是通过预定位再分类的方法,是一种dense prediction。只是在两阶段中,是将位置信息显式地标出来,然后逐个proposal分类+微调;单阶段中,位置信息是通过feature map上的相对位置关系得到,然后逐pixel分类+微调。这种情况下,总会需要后处理(NMS)。 - NMS:因为总会有多个proposal对应同一个instance或者多个pixel对应同一instance,那么这些多出来的框就要处理下。NMS(非极大值抑制)。
NMS的两个假设:如果两个框离得很近,那么两个框很有可能属于同一个instance;在属于同一个instance得框中,分类得分越高的,定位质量越高bi如。
但NMS的假设并不总是成立,即两个instance本来就很近


DETR



set predication
问题定义:一个预测集和GT集之间匹配的问题。

问题在于匹配的方式有多种,那么应该选那种?
->match loss最小的那一种。
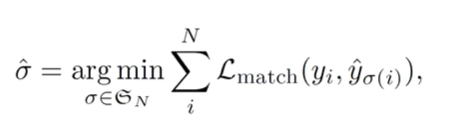
采用匈牙利匹配找到loss最小的匹配方式。
position embedding
位置编码是写死的,不可学习的。
图像是2d的,因此:

encoder-decoder

DETR的位置编码会应用到每一个encoder上,而不只是开头的一个,而且只会加到QK上,不影响V。
右边为编码器,多出来的MSA,K和V来自于encoder,Q来自于obj queries。
obj queries是一个可学习的向量(num,b,dim)。num是人为给的值,远大于图片内物体数量,默认为100.b为batch size。dim是attention运行过程中用的未读数。
deformable DETR
DETR的问题
DETR提出一套不同于dense prediction的pipeline,将检测视为一个set prediction的问题,成功去掉了anchor和NMS。
但在实际应用中,DETR在训练阶段面临难以收敛的困难,即训练开销过高;测试阶段,transformer存在计算量的问题,只能在分辨率最低的feature map上运行,导致小目标行的性能很差。
deformable DETR提出一种改进的attention机制,收敛速度更快,精度更高。
DETR收敛慢的缺点是:attention map变稀疏需要很长时间,transformer计算量大,只能运行在最后一层feature map上,导致小物体性能差。
deformable DETR总览

主体结构与DETR一致,利用多层feature map;所有attention采用deformable attention。
DCN(deformable CNN)
deformable是指可变形的,即参与卷积计算的点是可变的。



deformable attention
















 7517
7517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









