







[ADown算法介绍]
YOLOv9中的ADown(Adaptive Downsampling)降采样模块是一种创新的特征提取与空间维度压缩技术,其核心原理和优点如下:
一、ADown模块的原理
-
自适应空间压缩
ADown通过动态调整下采样策略(如卷积核大小、步长或通道融合方式),在降低特征图空间分辨率的同时,保留更多语义信息。其设计避免了传统池化或固定步长卷积带来的信息丢失,尤其对小目标检测更友好。 -
多尺度特征融合
模块可能结合局部特征(如浅层细节)与全局特征(如深层语义),通过跨层连接或注意力机制(如通道注意力、空间注意力)增强特征表达能力。例如,在降采样过程中保留高频边缘信息,同时融合低频语义信息。 -
轻量化设计
采用分组卷积(Group Convolution)、深度可分离卷积(Depthwise Separable Convolution)或通道混洗(Channel Shuffle)等技术,减少计算量和参数量,提升推理速度。例如,通过分组卷积降低通道间的冗余计算。
二、ADown模块的优点
-
信息保留能力
相比传统下采样方法(如最大池化),ADown能更好地保留边缘、纹理等细节信息,减少空间信息的丢失,从而提升小目标检测的精度。例如,在交通监控场景中,能更准确地识别车牌或行人。 -
计算效率高
通过轻量化设计,ADown在降低特征图分辨率的同时,显著减少计算量和参数量,适合资源受限的设备(如移动端或嵌入式设备)。例如,在无人机或机器人视觉任务中,能实现实时检测。 -
可扩展性与灵活性
ADown可与其他模块(如SPP、FPN)结合,适应不同尺度的目标检测需求。例如,在复杂场景中,通过多尺度特征融合提升检测鲁棒性。 -
提升模型性能
在YOLOv9中,ADown通过优化特征提取路径,增强了模型对不同尺度目标的感知能力,尤其在密集场景或小目标检测中表现突出。例如,在COCO数据集上的实验表明,ADown模块能显著提升mAP(平均精度)。
三、与其他下采样方法的对比
- 传统池化(如Max Pooling):信息丢失严重,对小目标不友好。
- 跨步卷积(Strided Convolution):计算效率高,但可能忽略局部细节。
- ADown:结合了自适应策略和多尺度融合,在信息保留与计算效率之间取得平衡。
总结
YOLOv9的ADown模块通过自适应空间压缩、多尺度特征融合和轻量化设计,在降低特征图分辨率的同时,显著提升了模型的检测精度和效率,尤其适合小目标检测和资源受限场景。其设计理念体现了深度学习模型在目标检测任务中对信息保留与计算效率的双重追求。
【yolov11框架介绍】
2024 年 9 月 30 日,Ultralytics 在其活动 YOLOVision 中正式发布了 YOLOv11。YOLOv11 是 YOLO 的最新版本,由美国和西班牙的 Ultralytics 团队开发。YOLO 是一种用于基于图像的人工智能的计算机模
Ultralytics YOLO11 概述
YOLO11 是Ultralytics YOLO 系列实时物体检测器的最新版本,以尖端的精度、速度和效率重新定义了可能性。基于先前 YOLO 版本的令人印象深刻的进步,YOLO11 在架构和训练方法方面引入了重大改进,使其成为各种计算机视觉任务的多功能选择。
Key Features 主要特点
- 增强的特征提取:YOLO11采用改进的主干和颈部架构,增强了特征提取能力,以实现更精确的目标检测和复杂任务性能。
- 针对效率和速度进行优化:YOLO11 引入了精致的架构设计和优化的训练管道,提供更快的处理速度并保持准确性和性能之间的最佳平衡。
- 使用更少的参数获得更高的精度:随着模型设计的进步,YOLO11m 在 COCO 数据集上实现了更高的平均精度(mAP),同时使用的参数比 YOLOv8m 少 22%,从而在不影响精度的情况下提高计算效率。
- 跨环境适应性:YOLO11可以无缝部署在各种环境中,包括边缘设备、云平台以及支持NVIDIA GPU的系统,确保最大的灵活性。
- 支持的任务范围广泛:无论是对象检测、实例分割、图像分类、姿态估计还是定向对象检测 (OBB),YOLO11 旨在应对各种计算机视觉挑战。

与之前的版本相比,Ultralytics YOLO11 有哪些关键改进?
Ultralytics YOLO11 与其前身相比引入了多项重大进步。主要改进包括:
- 增强的特征提取:YOLO11采用改进的主干和颈部架构,增强了特征提取能力,以实现更精确的目标检测。
- 优化的效率和速度:精细的架构设计和优化的训练管道可提供更快的处理速度,同时保持准确性和性能之间的平衡。
- 使用更少的参数获得更高的精度:YOLO11m 在 COCO 数据集上实现了更高的平均精度(mAP),参数比 YOLOv8m 少 22%,从而在不影响精度的情况下提高计算效率。
- 跨环境适应性:YOLO11可以跨各种环境部署,包括边缘设备、云平台和支持NVIDIA GPU的系统。
- 支持的任务范围广泛:YOLO11 支持多种计算机视觉任务,例如对象检测、实例分割、图像分类、姿态估计和定向对象检测 (OBB)
【测试环境】
windows10 x64
ultralytics==8.3.0
torch==2.3.1
【改进流程】
1. 新增ADown.py实现骨干网络(代码太多,核心模块源码请参考改进步骤.docx)然后在同级目录下面创建一个__init___.py文件写代码
from .ADown import *
2. 文件修改步骤
修改tasks.py文件
创建模型配置文件
yolo11-ADown.yaml内容如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, ADown, [128]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, ADown, [256]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, ADown, [512]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, ADown, [1024]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, ADown, [256]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, ADown, [512]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
3. 验证集成
使用新建的yaml配置文件启动训练任务:
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('yolo11-ADown.yaml') # build from YAML and transfer weights
# Train the model
results = model.train(data='coco128.yaml',epochs=100, imgsz=640, batch=8, device=0, workers=1, save=True,resume=False)成功集成后,训练日志中将显示ADown模块的初始化信息,表明已正确加载到模型中。
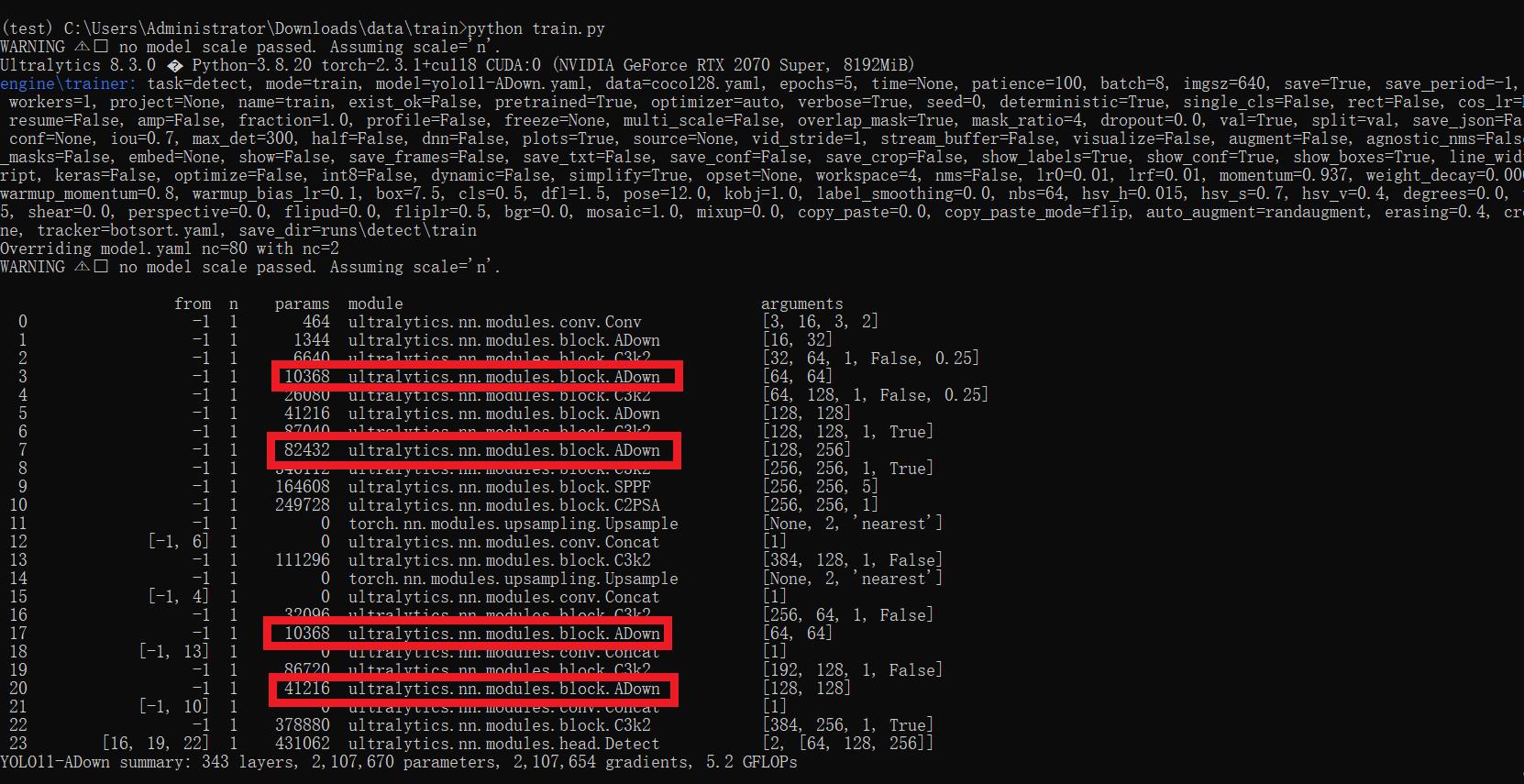
【训练说明】
第一步:首先安装好yolov11必要模块,可以参考yolov11框架安装流程,然后卸载官方版本pip uninstall ultralytics,最后安装改进的源码pip install .
第二步:将自己数据集按照dataset文件夹摆放,要求文件夹名字都不要改变
第三步:分别打开train.py,coco128.yaml和模型参数yaml文件修改必要的参数,最后执行python train.py即可训练
【提供文件】
├── [官方源码]ultralytics-8.3.0.zip
├── train/
│ ├── coco128.yaml
│ ├── dataset/
│ │ ├── train/
│ │ │ ├── images/
│ │ │ │ ├── firc_pic_1.jpg
│ │ │ │ ├── firc_pic_10.jpg
│ │ │ │ ├── firc_pic_11.jpg
│ │ │ │ ├── firc_pic_12.jpg
│ │ │ │ ├── firc_pic_13.jpg
│ │ │ ├── labels/
│ │ │ │ ├── classes.txt
│ │ │ │ ├── firc_pic_1.txt
│ │ │ │ ├── firc_pic_10.txt
│ │ │ │ ├── firc_pic_11.txt
│ │ │ │ ├── firc_pic_12.txt
│ │ │ │ ├── firc_pic_13.txt
│ │ └── val/
│ │ ├── images/
│ │ │ ├── firc_pic_100.jpg
│ │ │ ├── firc_pic_81.jpg
│ │ │ ├── firc_pic_82.jpg
│ │ │ ├── firc_pic_83.jpg
│ │ │ ├── firc_pic_84.jpg
│ │ ├── labels/
│ │ │ ├── firc_pic_100.txt
│ │ │ ├── firc_pic_81.txt
│ │ │ ├── firc_pic_82.txt
│ │ │ ├── firc_pic_83.txt
│ │ │ ├── firc_pic_84.txt
│ ├── train.py
│ ├── yolo11-ADown.yaml
│ └── 训练说明.txt
├── [改进源码]ultralytics-8.3.0.zip
├── 改进原理.docx
└── 改进流程.docx 【常见问题汇总】
问:为什么我训练的模型epoch显示的map都是0或者map精度很低?
回答:由于源码改进过,因此不能直接从官方模型微调,而是从头训练,这样学习特征能力会很弱,需要训练很多epoch才能出现效果。此外由于改进的源码框架并不一定能够保证会超过官方精度,而且也有可能会存在远远不如官方效果,甚至精度会很低。这说明改进的框架并不能取得很好效果。所以说对于框架改进只是提供一种可行方案,至于改进后能不能取得很好map还需要结合实际训练情况确认,当然也不排除数据集存在问题,比如数据集比较单一,样本分布不均衡,泛化场景少,标注框不太贴合标注质量差,检测目标很小等等原因
【重要说明】
我们只提供改进框架一种方案,并不保证能够取得很好训练精度,甚至超过官方模型精度。因为改进框架,实际是一种比较复杂流程,包括框架原理可行性,训练数据集是否合适,训练需要反正验证以及同类框架训练结果参数比较,这个是十分复杂且漫长的过程。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











