







前言
先前的话,我们终于是把我们整个架子搭起来了,这里重复一下我们的流程,那就是,首先,我们通过解析文本,然后呢遍历文本当中的我们定义的合法关键字,然后呢,把他们封装为一个Token,之后我们开始构建到我们的语法树,然后交给解释器完成操作。只是当时我们做的是针对这个数学运算。那么现在的话,我们要来实现的是我们的这个变量,效果是这样的:

语法规则
所以,现在的话,我们不得不谈论一下我们的语法规则了。语法规则非常重要,这意味着我们将用何种规则来处理我们的递归。例如,我们先前的语法规则是这样的,例如:
*
/ \
+ 2
/ \
5 3
再结合我们先前实现,构建这颗语法树的代码:
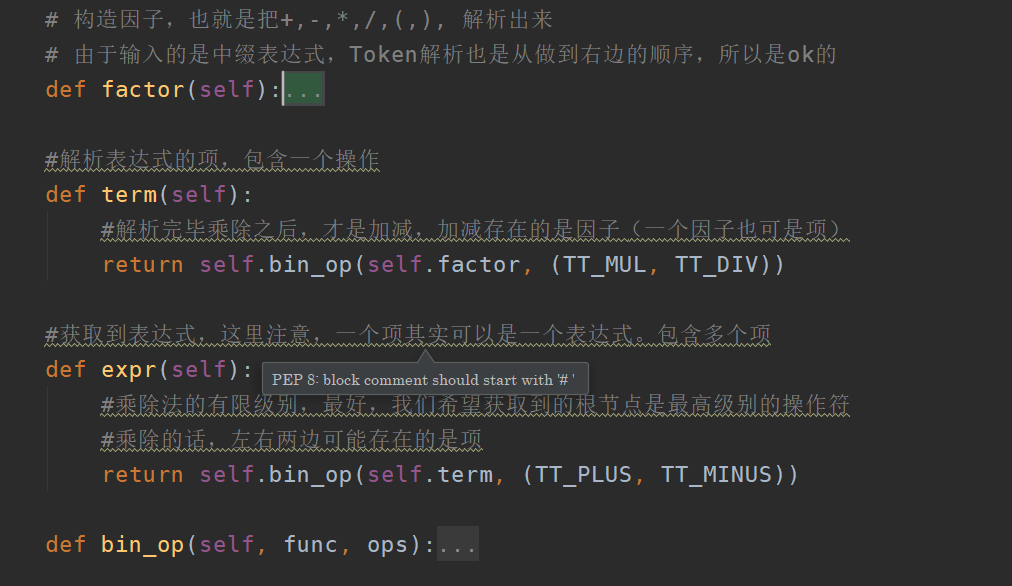
表示
我们在这里是定义了这几个东西:
expr(表达式) :由一个项(term)后面跟随零个或多个类似于加法(PLUS)或减法(MINUS)操作符的项组成。
term(项) :由一个因子(factor)后面跟随零个或多个类似于乘法(MUL)或除法(DIV)操作符的因子组成。
factor(因子) :可以是整数(INT)或浮点数(FLOAT) :是一个加法(PLUS)或减法(MINUS)操作符后面跟随一个因子
:或者是括号内的一个表达式(expr)。
用标准一点的描述就是:
表达式 :
- 项 ((+|-) 项)*
项 :
- 因子 ((*|/) 因子) *
因子 :
- 整数|浮点数
- (+|-) 因子
( 表达式 )
在这里,我们的表达式可以由项组成,例如这个:

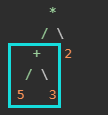
都可以叫做表达式,我们在构建这个语法树的时候,目的是希望把最外面的那个也就是最上面的节点找到。然后这里由于我们是按照顺序写代码,解析的token也是按照顺序的,然后编码的时候都是使用中缀表达式,所以,我们处理的时候最外层的就是最外层的最后的运算,后面解释器处理的时候,用刚刚的这棵树表示就是,我们最后处理这个*。按照我们的处理逻辑,就是先找到了这个 * 然后再左右递归处理得到了这个语法树。
然后框起来的部分,也可以作为一个项。
之后是我们的因子,这个因子的话,其实既可以是一个数,也可以是一个项,或者表达式。
那么在代码当中到底是咋回事呢:
其实是这样的:
一个节点其实就是一个factory。项,表达式也是节点。只不过,表达式,描述的是,相对来说的根节点,项描述的是,相对根节点的子节点。那么因子其实也是一个节点,只是这个节点的属性不清楚,可能是数字,有可能是项,也有可能是表达式。那么什么叫做相对根节点呢,其实只看这一个子树,例如刚刚框起来的部分,+ 相当于是一个根节点,所以它可以表示的是一个表达式,但是相对于这个+来说,蓝色框起来的部分只是一个项。
我们构建语法树的标准是,先去找到表达式,也就是最后的一个运算,然后找到它左右两边的表达式,(相对于当前节点来说是项)然后进入到项,此时递归处理(这个项,对于当前节点来说是表达式)
这么一说的话,我想,应该是解释清楚了。
那么这里的话,我们换回英文的表达,虽然这个Hlang是针对中文的,但是咱们开发用的还是英文。主要是对其里面的函数命名:
expr : term ((PLUS|MINUS) term)*
term : factor ((MUL|DIV) factor)*
factor : (PLUS|MINUS) factor
: power
power : atom (POW factor)*
atom : INT|FLOAT
: LPAREN expr RPAREN
这里的话,加了结果东西,主要是为了对付这个次幂。那么同样的你也发现了他大致的一个运算优先级。
次幂实现
所以的话,那么在这里的话,补充一下这个次幂的实现,首先我们这里加了个运算规则,也就是语法规则,显然我们要做的是,
- 增加关键合法的Token类型
- 修改解析的顺序
- 修改解释器运行的规则

然后的话,我们修改我们解析的步骤:
先添加支持的Token类型:

然后在解析里面添加:
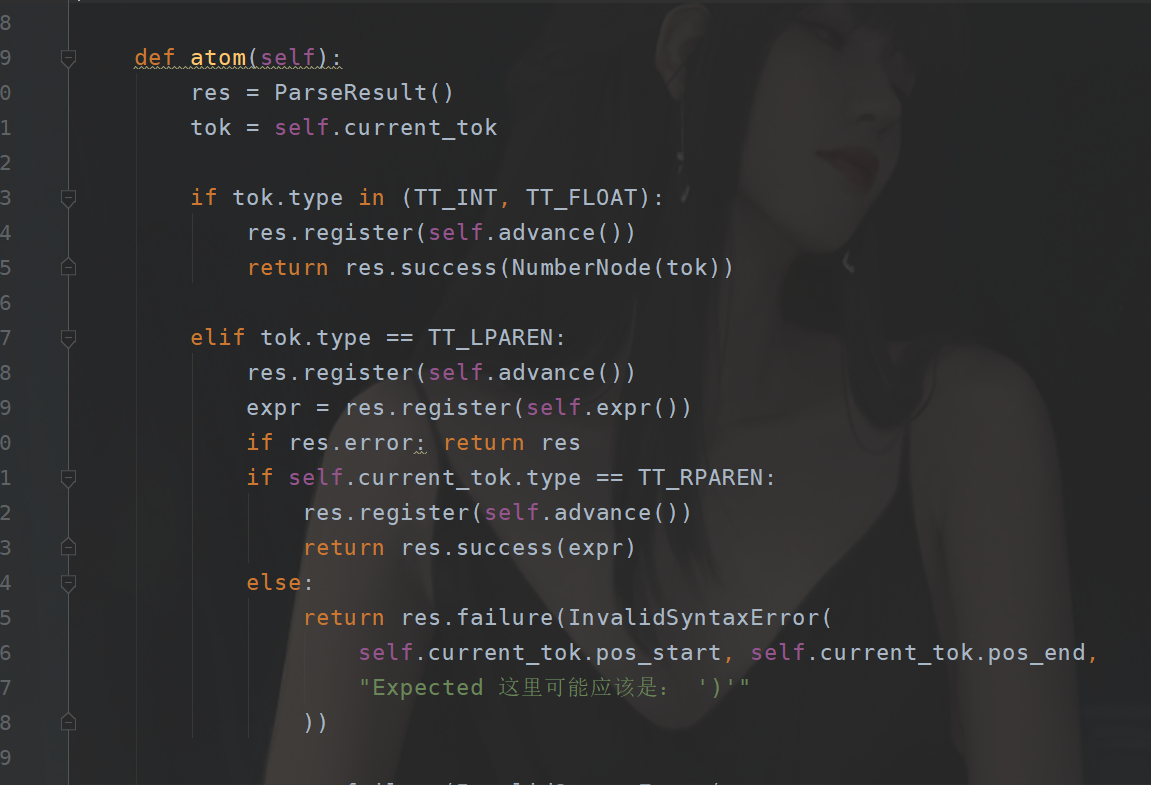
然后对Number添加:

最后修改解释器规则:
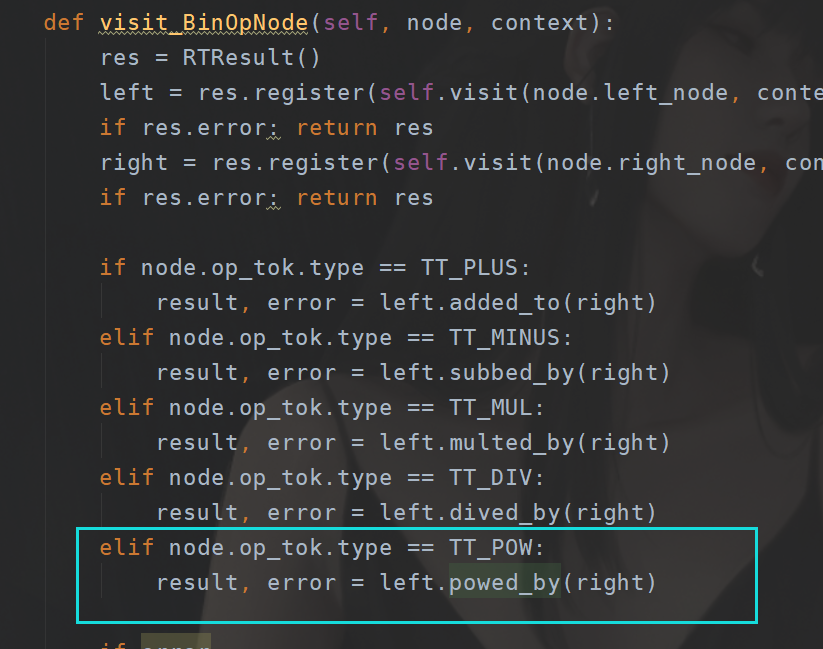
这样一来次幂就实现了。
变量实现
那么聊完了这个,我们要来说道说道这个变量的实现了。
通过前面的描述我想应该知道一件事情,那就是,这个我们需要定义清楚里面的优先级。因为变量的实现,本质上只是多了一个等号的运算实现。
优先级
所以等于号的优先级别是啥呢。确定好优先级,我们才能够确定解析的顺序。这里的话,就不卖关子了,直接看到:
expr : KEYWORD:VAR IDENTIFIER EQ expr
: term ((PLUS|MINUS) term)*
term : factor ((MUL|DIV) factor)*
factor : (PLUS|MINUS) factor
: power
power : atom (POW factor)*
atom : INT|FLOAT|IDENTIFIER
: LPAREN expr RPAREN
翻译过来就是:等于号可能是最后运算的。
实现
okey,在这里的话,我们来看到是如何实现的,在这里千万注意,这个实现的话,不要带入太多的细节。你去理解的话,因为这个是递归算法,理解递归,编写递归算法的核心,就是定义这个函数是干什么的,然后函数的核心业务逻辑只处理当前一个节点上面的情况,之后确定好边界即可。只是在这里维护了更多的信息。
那么在这里开始之前,我们还有一个问题,那就是,关于变量的问题,先解析变量,由变量开始建立这个语法树对不对。这个时候,先前的运算为什么可以我们是知道为什么的,这里不在重复了,那就是顺序+中缀。那么对于变量赋值其实也是一样的,本质上我们就是对于=的处理。只是的话,左边的节点比较特殊而已。
步骤
okey,这个时候我们来看看我们要做啥
首先我们有三个组件
- 词法解析器
定义新的合法token
IDENTIFIER
VAR
EQ
我们要将这三个家伙加入到token当中。
-
解析器
然后是解析器,我们显然要把这个也就行解析,解析的顺序按照我们刚刚那个语法确定的顺序进行解析。先检查=,然后表达式 -
解释器
之后的话,是我们的解释器,我们要从根节点出发,处理我们的运算步骤。这个时候的话,我们要检查的事情就多了。首先,如果当前的节点用到了变量,如果变量是子树,那么老规矩,递归操作即可。如果不是子树,或者左子树用到了,右子树当中的变量节点,如果执行顺序是先执行左子树,右子树没有实例化变量,也就是变量没有值的话,那么说明顺序不对,也就是变量声明的顺序不对,要报个错哦。如果是用到了父亲或者以上节点的变量,那么我们要取值,这个时候的话,我们就需要把这个变量的值存起来,方便直接拿过来。
这里对应的情况是这样的:
var a = 1
a + 5
这个时候肯定先处理到a,这个时候要把a这个节点的值给保存起来,进行维护。所以这里的话,可以使用到栈,但是更简单的实现是直接用hash, 这样的话,实现就更加简单了。
但是这里的话,我们还有一件事情需要做,那就是如何维护,子节点下面的变量是否应该被另一个子树的节点访问?子节点,孙子节点的变量意味着什么?显然,这里我们引出全局变量和局部变量。父亲,爷爷的自然是相对于全局变量,反之为局部变量。如果这些变量由节点自己维护,那么就形成了隔离的作用域。说白了就是,这种情况:
a + 5
var a=1
a 都还没有定义,我们假设这个语法树可以构建成功。但是显然在执行的时候,a 没有被进行处理,也就是赋值,所以必然报错。在我们的运行的时候的语法树当中,不同子树之间的变量的关系层级不同,所以最后导致它的作用域不同,说白了就是层级不同,没有执行到,导致异常的问题。
解析关键字
那么废话不多说,我们先来看到如何解析到我们的关键字。
首先:
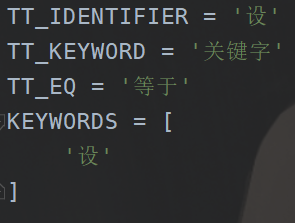
当然我们在定义一下过滤词:
DIGITS = '0123456789'
CHINESE_WORD = "设"
LETTERS = string.ascii_letters + CHINESE_WORD
LETTERS_DIGITS = LETTERS + DIGITS
我们新增这个东西。
然后到我们的解析部分。

这个函数负责解析实现
def make_identifier(self):
"""
识别关键字
:return:
"""
id_str = ''
pos_start = self.pos.copy()
while self.current_char != None and self.current_char in LETTERS_DIGITS + '_':
id_str += self.current_char
self.advance()
tok_type = TT_KEYWORD if id_str in KEYWORDS else TT_IDENTIFIER
return Token(tok_type, id_str, pos_start, self.pos)
这里注意,我们的关键字是设 但是变量名只能是英文+数字。为什么,首先我们的目的是给小孩子用的,小学第一次学变量,没记错的话,都是 设 x = xx 所以这里保留这个习惯。当然还有个原因,如果要做到和Python类似的那种的话,直接没有关键字的话,确实比较难,但是变量名任意包含中文确实也可以做到,只需要检查等号左边结束即可,但是这样做可能不符合习惯。
语法解析
之后的话,是我们的语法解析。这里的话,我们主要就是先解析我们的等于号,为了解析到变量。
不过在这里我们要先定义两个对象:
VarAccessNode 类表示一个设的访问节点。它具有以下属性和方法:
- var_name_tok:表示设名的令牌(token)对象。
- pos_start:表示节点在源代码中的起始位置,通过var_name_tok.pos_start获取。
- pos_end:表示节点在源代码中的结束位置,通过var_name_tok.pos_end获取。VarAssignNode 类表示一个设的赋值节点。它具有以下属性和方法:
- var_name_tok:表示设名的令牌(token)对象。
- value_node:表示赋给设的值的节点对象。
- pos_start:表示节点在源代码中的起始位置,通过var_name_tok.pos_start获取。
- pos_end:表示节点在源代码中的结束位置,通过value_node.pos_end获取。
class VarAccessNode:
def __init__(self, var_name_tok):
self.var_name_tok = var_name_tok
self.pos_start = self.var_name_tok.pos_start
self.pos_end = self.var_name_tok.pos_end
class VarAssignNode:
def __init__(self, var_name_tok, value_node):
self.var_name_tok = var_name_tok
self.value_node = value_node
self.pos_start = self.var_name_tok.pos_start
self.pos_end = self.value_node.pos_end
由于这里新增了节点,因此我们对应这个ParseResult也要进行修改:
class ParseResult:
def __init__(self):
self.error = None
self.node = None
self.advance_count = 0
def register_advancement(self):
self.advance_count += 1
def register(self, res):
self.advance_count += res.advance_count
if res.error: self.error = res.error
return res.node
def success(self, node):
self.node = node
return self
def failure(self, error):
if not self.error or self.advance_count == 0:
self.error = error
return self
然后的话,我们就可以愉快地进行解析了
这里重点看到的就是这个解析函数变量,先解析到等于的,这个变量,因为如果有变量,肯定是先设再处理。
def expr(self):
res = ParseResult()
#这个时候的话,我们先去解析变量
if self.current_tok.matches(TT_KEYWORD, '设'):
res.register_advancement()
self.advance()
if self.current_tok.type != TT_IDENTIFIER:
return res.failure(InvalidSyntaxError(
self.current_tok.pos_start, self.current_tok.pos_end,
"Expected 这里期望是:设(关键字)"
))
var_name = self.current_tok
res.register_advancement()
self.advance()
if self.current_tok.type != TT_EQ:
return res.failure(InvalidSyntaxError(
self.current_tok.pos_start, self.current_tok.pos_end,
"Expected 这里期望是: '='"
))
res.register_advancement()
self.advance()
expr = res.register(self.expr())
if res.error: return res
return res.success(VarAssignNode(var_name, expr))
node = res.register(self.bin_op(self.term, (TT_PLUS, TT_MINUS)))
if res.error:
return res.failure(InvalidSyntaxError(
self.current_tok.pos_start, self.current_tok.pos_end,
"Expected 这里期望是: '设(关键字)', 整数, 浮点数, 设的变量名, '+', '-' or '('"
))
return res.success(node)
解释器
之后来到我们的解释器部分。
在这里我们需要维护变量,所以我们用这两个家伙去维护。
class Context:
def __init__(self, display_name, parent=None, parent_entry_pos=None):
self.display_name = display_name
self.parent = parent
self.parent_entry_pos = parent_entry_pos
self.symbol_table = None
class SymbolTable:
def __init__(self):
#设值:key->value
self.symbols = {}
self.parent = None
def get(self, name):
value = self.symbols.get(name, None)
if value == None and self.parent:
return self.parent.get(name)
return value
def set(self, name, value):
self.symbols[name] = value
def remove(self, name):
del self.symbols[name]
之后的话,解释器其实只是多加了这两个方法:
"""
处理设的赋值节点,拿到设的值。
:param node:
:param context:
:return:
"""
def visit_VarAccessNode(self, node, context):
res = RTResult()
var_name = node.var_name_tok.value
value = context.symbol_table.get(var_name)
if not value:
return res.failure(RTError(
node.pos_start, node.pos_end,
f"'{var_name}' is not defined",
context
))
value = value.copy().set_pos(node.pos_start, node.pos_end)
return res.success(value)
"""
处理设的赋值节点,计算处理得到值,然后存起来
:param node:
:param context:
:return:
"""
def visit_VarAssignNode(self, node, context):
res = RTResult()
var_name = node.var_name_tok.value
value = res.register(self.visit(node.value_node, context))
if res.error: return res
#存储结果
context.symbol_table.set(var_name, value)
return res.success(value)
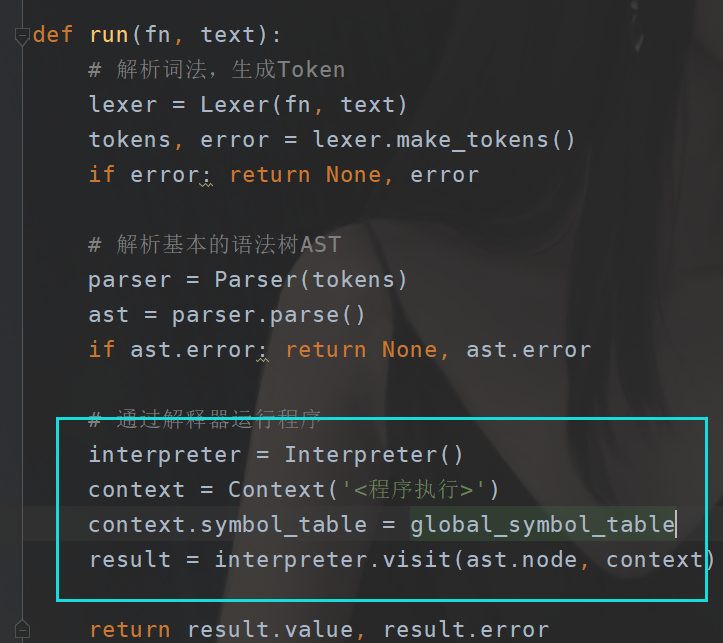
那么这里的话,还要注意的就是,这个时候,我们初始化的时候,要初始化这个变量的对照表了(变量名:变量值)
global_symbol_table = SymbolTable()
global_symbol_table.set("null", Number(0))
总结
以上的话,就是全部内容,那么接下来如果要继续实现的话,就是这样加节点就好了,只要理解了前面实现基本的数学运算的部分理解AST的话,理解基本的解释器的工作流程的话,其实后面的话就很好操作了。所谓AST其实就是按照我们定义的语法(执行过程)去生成一棵树,这个树是我们要执行的每一个步骤的描述,然后解释器,对这棵树进行操作,拿到值,然后按照不同的节点类型组装结果。















 1103
1103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











