







本文主要参考了论文 A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS,以及其中提到的各 YOLO 原论文。
NMS
- 对所有检测框,按置信度降序排序。
- 选择最高置信度的检测框,添加到最终结果中。
- 计算其与剩下所有检测框的 IOU,若其超过 IOU 阈值则移除。
- 重复直到所有检测框被处理完。
YOLOv1
模型
将输入图像分成 S x S 个 grid。
每个 grid 预测 B 个 bounding box,以及 C 个分类的条件概率。
每个 bounding box 包含 5 个预测值:
x
,
y
,
w
,
h
,
c
o
n
f
i
d
e
n
c
e
x,y,w,h,confidence
x,y,w,h,confidence,其
x
,
y
x,y
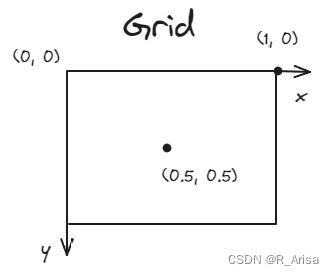
x,y 是 bounding box 中心坐标,相对每个 grid 归一化,如下图:
而
w
,
h
w, h
w,h 是 bounding box 相对于整张图像的宽高,也被归一化。例如 bounding box 的宽高是 150 x 75,而图像的宽高是 300 x 300,则
w
=
150
/
300
=
0.5
w=150/300=0.5
w=150/300=0.5,
h
=
75
/
300
=
0.25
h=75/300=0.25
h=75/300=0.25。
最终预测输出是一个 S × S × ( B × 5 + C ) S \times S \times (B \times 5 + C) S×S×(B×5+C) 的张量。
S, B 是超参数,C 是类别的数量。
置信度 c o n f i d e n c e = P r ( O b j e c t ) × I O U p r e d t r u t h confidence=Pr(Object) \times IOU^{truth}_{pred} confidence=Pr(Object)×IOUpredtruth,其中 P r ( O b j e c t ) Pr(Object) Pr(Object) 取值为 0 或 1,表示是否检测到目标。
关于 P r ( O b j e c t ) Pr(Object) Pr(Object) 的取值论文中没有明确提及,0 或 1 是我的猜测,因为文章中说用 IOU 表示置信度,如果 P r ( O b j e c t ) Pr(Object) Pr(Object) 表示概率,那么就矛盾了。
对于检测到的目标,每个 grid 还会预测 C 个
P
r
(
C
l
a
s
s
i
∣
O
b
j
e
c
t
)
Pr(Class_i|Object)
Pr(Classi∣Object),代表检测到目标的前提下,是每个类别的条件概率。
最终在 test 阶段,输出结果的置信度
c
o
n
f
i
d
e
n
c
e
=
P
r
(
C
l
a
s
s
i
∣
O
b
j
e
c
t
)
×
P
r
(
O
b
j
e
c
t
)
×
I
O
U
=
P
r
(
C
l
a
s
s
i
)
×
I
O
U
confidence=Pr(Class_i|Object) \times Pr(Object) \times IOU=Pr(Class_i) \times IOU
confidence=Pr(Classi∣Object)×Pr(Object)×IOU=Pr(Classi)×IOU,这个结果既包含了识别类别的置信度,又包含了坐标位置的置信度。
关于 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i|Object) Pr(Classi∣Object) 是每个 grid 预测 C 个,还是只有在检测到目标的前提下才预测该值,文章中没有详细说明。但我认为应该是只有检测到才预测此值,否则 P r ( O b j e c t ) = 0 Pr(Object)=0 Pr(Object)=0 时,该值是无意义的。
优化
过多置信度为 0(即没有目标的 grid)会导致模型不稳定、早期发散严重。解决方法是增加坐标的 loss,减少置信度的 loss。
评估
- 可以达到 45 帧率。
- 但是对小目标的检测精度不高。
- 与其他非实时算法相比,精度不高,定位不准。
YOLOv2
模型
为每个 grid 引入若干个 anchor box(文中有时候也叫 prior box),是预先定义的用于匹配检测对象的形状的框。
之前的锚框都是手动选取的,YOLOv2 则对训练集中标注的边框使用 K-means 算法进行自动生成。
最后为每个 anchor box 预测坐标和类别。
优化
使用锚框会遇到两个问题:
1)如何先验地选择anchor box
解决方法:使用k-means聚类算法选择锚框。
2)模型不稳定
以往用到锚框时,任何锚框都可以在图像中的任何位置,而不管是哪个位置预测的边界框,这导致很长时间才能收敛。
解决方法:不预测偏移,而是预测相对于网格单元的位置坐标。这使得参数更容易学习,因而更稳定。
另外,YOLOv2 也针对 YOLOv1 对小目标检测效果不好做了改进。
将 grid 的分辨率从 13x13 提高到 26x26 可以使得小目标更易被检测。最后再从 26x26x512 转换到 13x13x2048 使得可以和最初的特征融合(concatenate)。
最后,由于没有使用全连接层,因此输入可以是不同的大小。
评估
- 使用了 WordTree 进行分类,利于有各种相同子类(如狗和各种狗)的检测,但对于服装等没有具体父类标签的检测效果不好。
YOLOv3
模型
- 给每个预测对象只分配一个锚框。
- 为每个分类使用二元交叉熵而非 softmax 进行训练。使得可以给同一个目标多个标签,如 Person 和 Man(即避免 softmax 的非此即彼问题)。
- 不同于 YOLOv2 为每个 grid 使用 5 个锚框,YOLOv3 为每个 grid 使用 3 个锚框(为了 3 尺度)
- 最重要的是引入 多尺度(multi-scale) 预测。
多尺度实际上就是多 grid size。
YOLOv3 使用 3 尺度得到 3 个输出张量,其 size 分别为 N × N × [ 3 × ( 4 + 1 + 80 ) ] N\times N\times [3\times (4+1+80)] N×N×[3×(4+1+80)]。
其中 N 是经下采样后的三个尺度值,如原图是 416,分别经过 32 倍,16 倍,8 倍的降采样后 N 就分别为 13, 26, 52。后面的 3 表示一个 grid cell 里有 3 个 bounding box。
架构
一个不错的 YOLOv3 模型架构图:

其中 CBL 指 Convolution-BatchNorm-Leaky ReLU 块,SPP(Spatial pyramid pooling)用于在没有下采样(即步幅 stride=1)时连接多个 max pooling 输出。
评估
- 在 IOU 阈值提高时表现下降明显。
目标检测网络架构
YOLOv3 后目标检测的网络架构被分为三个部分:backbone, neck 和 head。
Backbone
通常是一个 CNN,用于提取特征。
Neck
对主干提取的特征进行聚合和细化,往往侧重于增强不同尺度的空间和语义信息。
Head
进行最后预测,分类、定位等,再加上一些后处理步骤,如 NMS。
YOLOv4
就是使用各种 BoF 和 BoS 对 YOLOv3 进行修改,得到最佳效果。
BoF:指只改变训练策略,增加训练成本,但不增加推理时间的方法。如数据增强。
BoS:指稍微增加推理成本但显著提高准确率的方法。
具体如下:

优化
- 使用 mosaic augmentation 将 4 个图像合并成一个。
使得目标在不同于它们通常出现的场景被检测。 - 使用 Self-adversarial Training (SAT) 将一个图像中的目标去除,但扔保留标签。
以提高鲁棒性
架构
性能最好的架构是:
- backbone:对Darknet-53的修改,采用跨阶段部分连接(CSPNet),以Mish激活函数。
- neck:使用 YOLOv3- SPP,多尺度预测使用修改版本的 path aggregation network(PANet) 而不是 FPN 或 spatial attention module(SAM)。
- head:和 YOLOv3 保持相同。
架构如下:
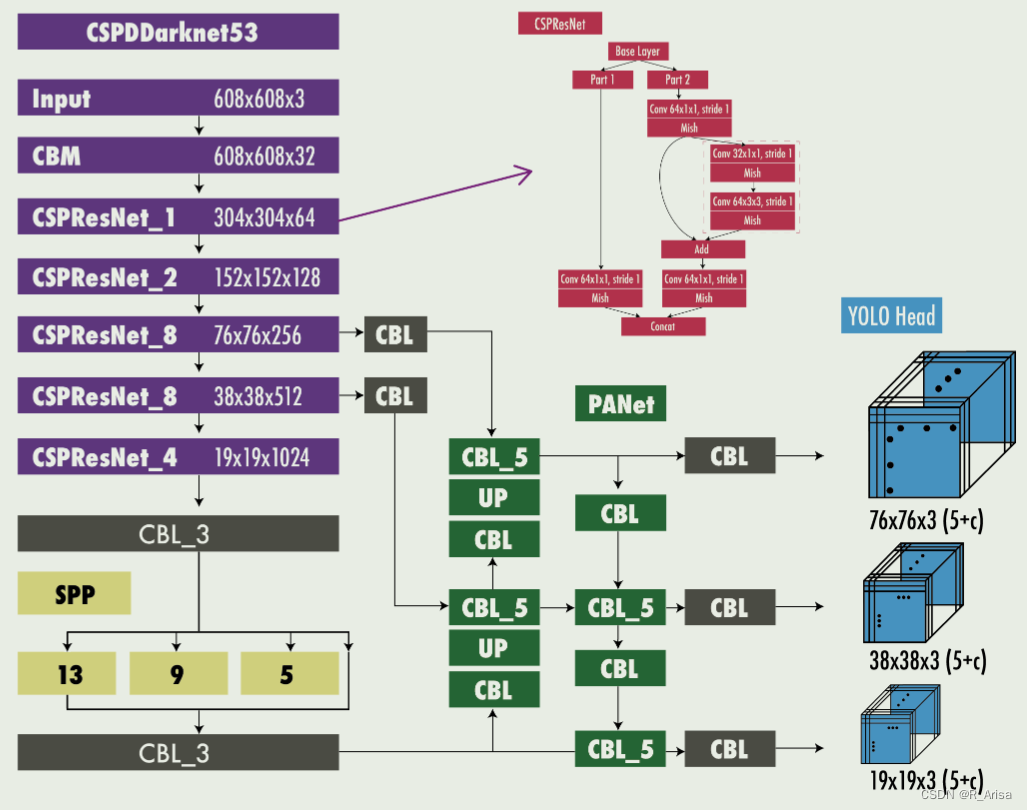
其中 CMB 表示 Convolution + Batch Normalization + Mish activation,CBL 表示 Convolution + Batch Normalization + Leaky ReLU,UP 表示 upsampling,SPP 表示 Spatial Pyramid Pooling,PANet 是 Path Aggregation Network.
YOLOv5
只是对 YOLOv4 做一点小小的修改,最主要的区别是它使用 pytorch 实现,因此而流行。
YOLOX
优化
- Anchor free
- Multi positives
因为无锚框,所有检测到的预测框也会减少,为补偿这部分训练时的损失,引入 Multi positives,将一个预测周围的 3x3 区域都作为 positive。 - Decoupled head
将分类置信度和定位精度解耦为分别用两个 head 进行检测。 - 改进 Label assignment
使用 simOTA 将 label assignment(就是将输出与 gt 进行匹配评估检测效果,如使用 IOU) 转换为最小运输代价问题。
YOLOv8
优化
- 转向了 Anchor free。
- 对目标、分别、回归分别使用解耦的 head。
YOLO-NAS
适合实时边缘设备应用。
优化
- 使用量化和混合量化。
- 使用自动标签和自蒸馏的预训练。
- 使用 AutoNAC 自动设计架构。















 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









