







代码:option-critic-arch-master
准备工作
打开代码option-critic-arch-master后发现有后缀为.ipynb的文件,经过查询发现是使用 Jupyter Notebook 来编写Python程序时的文件,所以用anaconda中的Jupyter Notebook打开查看。在jupyter下的File—>Download as —>python (.py)可以将.ipynb转化为.py文件。
一、实验环境介绍:fourrooms
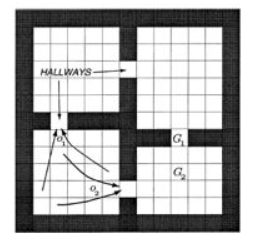
环境是经典的四个迷宫房间,每个房间之间通过一个过道连接,假设智能体当前处于左上方的房间内,其目标是到达G1处。
二、代码分析
the main loop for training
# History of steps and average durations
history = np.zeros((nruns, nepisodes, 2))
option_terminations_list = []
for run in range(nruns):定义训练次数
env = FourRooms()环境初始化
nstates = env.observation_space.shape[0]
nactions = env.action_space.shape[0]
# Following three belong to the Actor模块初始化定义
# 1. The intra-option policies - linear softmax functions策略函数,SoftmaxPolicy类更新Q_U价值表
option_policies = [SoftmaxPolicy(rng, lr_intra, nstates, nactions, temperature) for _ in range(noptions)]
# 2. The termination function - linear sigmoid function终止函数,SigmoidTermination类,更新是优势函数(控制更新幅度、速度和方向)和幅度。
option_terminations = [SigmoidTermination(rng, lr_term, nstates) for _ in range(noptions)]
# 3. The epsilon-greedy policy over options价值表更新由critic完成,所以EpsGreedyPolicy类里没有更新函数
policy_over_options = EpsGreedyPolicy(rng, nstates, noptions, epsilon)
# Critic内含顶层策略的Q值表更新,时间差分
critic = Critic(lr_critic, discount, policy_over_options.Q_Omega_table, nstates, noptions, nactions)
print('Goal: ', env.goal)
for episode in range(nepisodes):
# Change goal location after 1000 episodes 每一千步更新一次目标
# Comment it for not doing transfer experiments
if episode == 1000:
env.goal = rng.choice(possible_next_goals)
print('New goal: ', env.goal)
state = env.reset()
option = policy_over_options.sample(state)
action = option_policies[option].sample(state)
critic.cache(state, option, action)
duration = 1
option_switches = 0
avg_duration = 0.0
for step in range(nsteps):
state, reward, done, _ = env.step(action)
# Termination might occur upon entering new state判断当前是否需要终止
if option_terminations[option].sample(state):
option = policy_over_options.sample(state)
option_switches += 1
avg_duration += (1.0/option_switches)*(duration - avg_duration)
duration = 1
action = option_policies[option].sample(state)
# Critic update
critic.update_Qs(state, option, action, reward, done, option_terminations)
# Intra-option policy update with baseline
Q_U = critic.Q_U(state, option, action)
Q_U = Q_U - critic.Q_Omega(state, option)
option_policies[option].update(state, action, Q_U)
# Termination condition update优势函数的更新,用Q_Omega表格进行维护
option_terminations[option].update(state, critic.A_Omega(state, option))
duration += 1
if done:
break
history[run, episode, 0] = step
history[run, episode, 1] = avg_duration
option_terminations_list.append(option_terminations)
# Plot stuff
clear_output(True)
plt.figure(figsize=(20,6))
plt.subplot(121)
plt.title('run: %s' % run)
plt.xlabel('episodes')
plt.ylabel('steps')
plt.plot(np.mean(history[:run+1,:,0], axis=0))
plt.grid(True)
plt.subplot(122)
plt.title('run: %s' % run)
plt.xlabel('episodes')
plt.ylabel('avg. option duration')
plt.plot(np.mean(history[:run+1,:,1], axis=0))
plt.grid(True)
plt.show()存在问题的代码?
我认为下面这部分代码存在问题:
for step in range(nsteps):
state, reward, done, _ = env.step(action)
# Termination might occur upon entering new state
if option_terminations[option].sample(state):
option = policy_over_options.sample(state)
option_switches += 1
avg_duration += (1.0/option_switches)*(duration - avg_duration)
duration = 1
action = option_policies[option].sample(state)
# Critic update
critic.update_Qs(state, option, action, reward, done, option_terminations)当前的action与环境进行一次交互,拿到state, reward, done,state相对于此时的action有关算是‘next_state’,用‘next_state’再去拿到一次动作。
所以critic update中的state、option、action、reward、done不是在一次交互中所得到的。option还是那个option,reward和done是上一次action交互得到的。
要想解决这个问题,就得把state, reward, done, _ = env.step(action)移到拿到action后面,然后新生成的state用‘next_state’命名,传到critic update时用的是state,在下一次进到step函数时,再将state赋值next_state。这样就可以保证state、option、action、reward、done是在一次交互中所得到的。















 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









