







一、
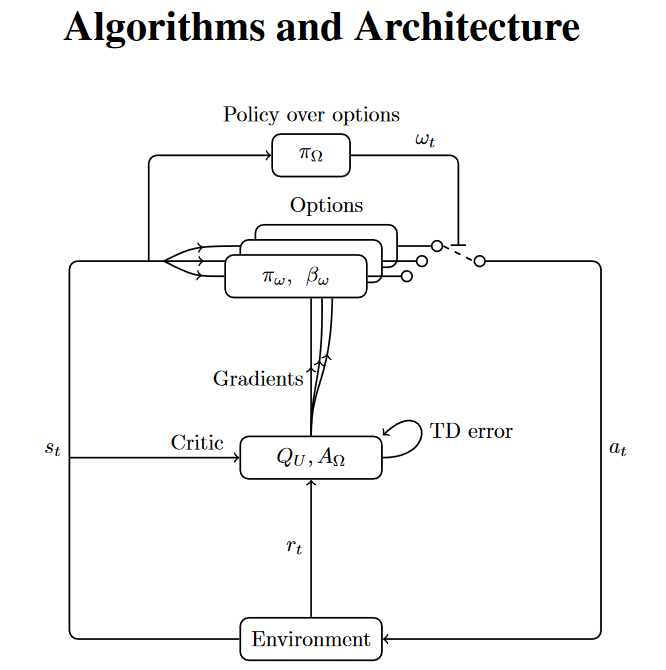
顶层策略选择option,再由option选择action



三、代码
1.指数和的对数
链接
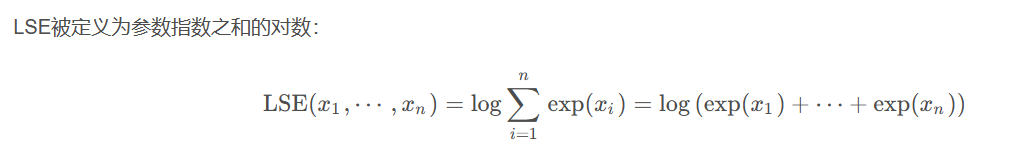
主要解决计算Softmax或CrossEntropy2时出现的上溢(overflow)或下溢(underflow)问题。
2.移动平均法
移动平均法是一种分析时间序列的常用工具,它可以消除周期变动和不规则变动的影响,反映长期趋势。1
移动平均法有以下几种类型:
- 简单移动平均法:就是计算最近N期序列值的算术平均数,作为未来各期的预测结果。2
- 加权移动平均法:就是给最近N期序列值赋予不同的权重,计算加权平均数,作为未来各期的预测结果。2
- 趋势移动平均法:就是对简单移动平均值再做一次移动平均,利用滞后偏差的规律来建立直线趋势的预测模型。2
移动平均法的优点是简单易用,能够平滑随机波动,适合做近期预测。34
移动平均法的缺点是会造成信息的损失,不能反映序列的曲线趋势,对于有明显季节性或周期性的序列效果不佳。
四、分层强化学习
-
分阶段的强化学习是指将一个复杂的强化学习任务分解为多个层次或子任务,从而提高学习效率和泛化能力的方法。分阶段的强化学习也称为分层强化学习(Hierarchical Reinforcement Learning),是强化学习的一个重要分支。
-
分阶段的强化学习的主要挑战是如何定义和学习不同层次的策略,如何协调上下层次的交互,以及如何处理稀疏奖励和探索问题等1。目前,有许多不同的分阶段的强化学习方法,根据不同的角度和侧重点,可以分为以下几类:
- 基于选项(Options)的学习,是一种将一系列动作组合成一个子技能的方法,上层策略选择不同的选项,下层策略执行选项中的动作3。例如,Options Critic4是一种基于Actor-Critic框架的选项学习方法。
- 基于分层局部策略(Hierarchical Partial Policy)的学习,是一种将原始状态空间划分为不同抽象层次的方法,每个层次有自己的局部策略和奖励函数3。例如,MAXQ是一种从任务分解的角度出发的分层局部策略学习方法。
- 基于子任务(Sub-task)的学习,是一种将原始任务分解为多个子任务,并为每个子任务定义目标和奖励函数的方法3。例如,HAC是一种使用Hindsight方法来加速子任务学习的方法。
参考:
代码解析:
if option_terminations[option].sample(state):
option = policy_over_options.sample(state)
option_switches += 1
avg_duration += (1.0 / option_switches) * (duration - avg_duration)
duration = 1



















 1414
1414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









