







Problem Definition
Cache Data Refresh
- We have 576 cache files, each file (in fact, a file pair, one is an index file, the other is data file) contains point to address mapping: (latitude, longitude) -> Address, i.e., the result of reverse geocoding.
- some data (addresses) may be out of date, now we need get updated address of those points.
Requirement
- There is no date info for each cache entry [point, address], so we refresh all points in cache file, that is, regenerate the cache file in whole.
- The refresh can be interrupted and continue from the breakpoint - we do not want start from beginning.
- Total points number is about 80M, we need finish it in given time, or the refresh duration time can be controlled.
- The refresh is done on-line. After refresh finished, the server switch to new cache file and back up old cache file.
- There are several peer server, each server has same data (576 cache files), we want all of the server get updated addresses in the same time.
Solution1
- For each cache file
- For each point in the cache file
- read point from cache file - R
- get updated address - G
- write new address into new cache file - W
- For each point in the cache file
Limits:
- If the refresh is interrupted, one cache file need restart at right beginning. Suppose a cache file contains 5m points, the server crash when the refresh coming to the last point of 5m points. Then all the 4.99m effort is lost.
- The whole process is in single thread, its rate is limits by the bottleneck process: get updated address.
Solution2
Instead of 'R-G-W' one point by one point. We first snap all the points in the cache file intensively, and put all the point in 4096 point files. So each point file contains a certain number of points. Then use several threads to repeat 'R-G' process using point files, and one threads to repeat 'W' process. Once a point file is finished, delete it and process next file.
- For each cache file
- For each point in the cache file
- read point from cache file
- write point into point file, create a new file every 80m/4096 points
- For each point in the cache file
- For each point file
- For each point in the point file - multiply threads, each threads handle one file
- read point from point file
- get updated address
- add new address into write thread queue
- Delete the point file once it finish all the points
- For each point in the point file - multiply threads, each threads handle one file
- For each point in the write queue
- Write new address into new cache file
Benefit:
- If the refresh is interrupted, at most one point file work is lost.
- Use multiply threads in bottleneck function('G'), so we speed up the whole refresh. The refresh rate is controlled by thread number
Postmortem
1. How to handle batch process
1) break down (Split) and reassemble to get pipelining
http://en.wikipedia.org/wiki/Assembly_line
Consider the assembly of a car: assume that certain steps in the assembly line are to install the engine, install the hood, and install the wheels (in that order, with arbitrary interstitial steps); only one of these steps can be done at a time. In traditional production, only one car would be assembled at a time. If engine installation takes 20 minutes, hood installation takes 5 minutes, and wheel installation takes 10 minutes, then a car can be produced every 35 minutes.
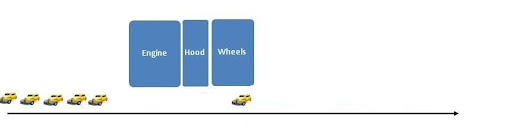
In an assembly line, car assembly is split between several stations, all working simultaneously. When one station is finished with a car, it passes it on to the next. By having three stations, a total of three different cars can be operated on at the same time, each one at a different stage of its assembly.
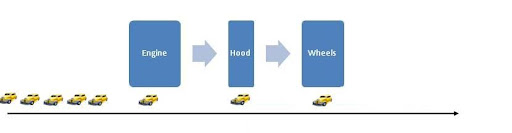
After finishing its work on the first car, the engine installation crew can begin working on the second car. While the engine installation crew works on the second car, the first car can be moved to the hood station and fitted with a hood, then to the wheels station and be fitted with wheels. After the engine has been installed on the second car, the second car moves to the hood assembly. At the same time, the third car moves to the engine assembly. When the third car’s engine has been mounted, it then can be moved to the hood station; meanwhile, subsequent cars (if any) can be moved to the engine installation station.
Assuming no loss of time when moving a car from one station to another, the longest stage on the assembly line determines the throughput (20 minutes for the engine installation) so a car can be produced every 20 minutes, once the first car taking 35 minutes has been produced.
http://en.wikipedia.org/wiki/Pipeline_(computing)
http://en.wikipedia.org/wiki/Instruction_pipeline
2) find the bottleneck in a proper granularity
3) intermediate result/state may be helpful. In above case, point file.
2. Cache Design
Considering about cache expire. Generally Date info or life time is created together with cache entry.
3. Quadtrees
Why not database to store the entry ?
please see Quadtrees
1) C++ Implementation
2) Use Case
















 208
208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











