







目录
二、Principal Component Analysis(PCA)
一、特征维度约减
1.1特征维度约减的概念
特征约减的目的是将高维特征向量映射到低维子空间中。
给定n个样本(每个样本维度为p维)通过特征变换、投影矩阵实现特征空间的压缩:
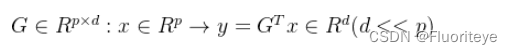
1.2为什么要约减?
有时候,我们可能收集到上百或者上千的特征变量,我们很难理清楚各个特征之间的关系。 也就常常容易出现这样的情况,两个特征是强相关的,但是却都用来训练。 例如厘米和英尺,都是长度的度量,两者具有强相关关系,如果存在大量这样的冗余特征,就非常影响机器学习的效率。 这时候我们就需要进行 维数约减(Dimensionality Reduction) 。
可视化:高位数据在2D或3D空间中的可视化
维度约减:高效的存储与检索
噪声消除:提升分类或识别精度
1.3常规约减方法
1.3.1无监督方法
无监督方法可以帮助我们在不需要标签信息的情况下进行特征维度约减,从而提取出数据的潜在结构和特征。
—Latent Semantic Indexing(LSI):truncated SVD
—Independent Component Analysis(ICA)
—Principal Component Analysis(PCA)
—Canonical Correlation Analysis(CCA)
1.3.2监督方法
监督方法可以利用标签信息来指导特征维度约减,选择那些对于目标变量具有较大预测能力的特征。
—Linear Discriminant Analysis(LDA)
1.3.3半监督方法
半监督学习方法是一种介于无监督学习和监督学习之间的方法,它利用有标签数据和无标签数据来进行特征维度约减。
—Research topic
二、Principal Component Analysis(PCA)
2.1PCA
基本思路:
—通过协方差分析,建立高维空间到低维空间的线性映射、矩阵
—保留尽可能多的样本信息
—压缩后的数据对分类、聚类尽量不产生影响,甚至有所提升
2.2PCA的核方法
核PCA的核心思想是通过将数据映射到高维特征空间,并在该空间中进行PCA。这种映射是通过使用核函数来实现的,常用的核函数包括线性核、多项式核和高斯核等。核函数的选择取决于数据的特点和任务的需求。
核PCA的步骤如下:
- 计算核矩阵:首先,根据选定的核函数,计算原始数据样本之间的相似度矩阵(也称为核矩阵)。
- 中心化核矩阵:对核矩阵进行中心化处理,确保样本在特征空间中的均值为零。
- 特征值分解:对中心化的核矩阵进行特征值分解,得到特征值和对应的特征向量。
- 选择主成分:根据特征值的大小,选择前k个特征值对应的特征向量作为主成分。
- 数据投影:将原始数据样本投影到由选定的主成分构成的新特征空间中。
2.3PCA人脸识别实例
import cv2
import numpy as np
from matplotlib import pyplot as plt
def img2Vector(image_file):
img = cv2.imread(image_file,0)
return np.reshape(img,(1,img.shape[0]*img.shape[1]))
def load_orl(k):
orlpath = 'Face_Dataset/Face/ORL_Faces'
train_face = []
train_label = []
test_face = []
test_label = []
sample = np.random.permutation(10)+1
for i in range(40):
people_num = i+1
for j in range(10):
image = orlpath + '/s' + str(people_num) + '/' + str(sample[j]) + '.pgm'
img = img2Vector(image)
if j<k:
train_face.append(img)
train_label.append(people_num)
else:
test_face.append(img)
test_label.append(people_num)
return np.array(train_face),np.array(train_label),np.array(test_face),np.array(test_label)
def PCA(data,r):
mean = np.mean(data,axis=0)
RemovedMean = data - mean
S = np.dot(RemovedMean.T,RemovedMean)/len(RemovedMean)
eigVals,eigVects = np.linalg.eig(S)
eigValInd = np.argsort(eigVals)[::-1]
redEigVects = eigVects[:,eigValInd][:,:r]
lowDDataMat = np.dot(RemovedMean, redEigVects)
return lowDDataMat,mean,redEigVects
def compare_images(original,reconstructed,index):
original_image = original[index].reshape(112,92)
reconstructed_image = reconstructed[index].reshape(112,92)
plt.figure(figsize=(8,4))
plt.subplot(1,2,1)
plt.imshow(original_image,cmap='gray')
plt.title('Original Image')
plt.subplot(1,2,2)
plt.imshow(reconstructed_image,cmap='gray')
plt.title('Reconstructed Image')
plt.show()
def face_recognize():
train_face,train_label,test_face,test_label = load_orl(5)
compare_indics = range(1)
for r in (10,40,100,1000):
print("当降到%d时" % r)
data_train_new,data_mean,V_r=PCA(train_face,r)
num_test = test_face.shape[0]
temp_face = test_face - data_mean
data_test_new = np.dot(temp_face, V_r)
reconstructed_test_faces = np.dot(data_test_new, V_r.T) + data_mean
for i in compare_indics:
compare_images(test_face,reconstructed_test_faces,i)
sortedDistIndicies = np.sum((data_train_new - data_test_new)**2, axis=1).argsort()
true_num = np.sum(train_label[sortedDistIndicies[:num_test]] == test_label)
accuracy = true_num / num_test
print(f"the classify accuracy is: {accuracy*100:.2f}%")
face_recognize()

三、总结
PCA是一种常用的降维技术,用于将高维数据转换为低维表示。PCA旨在通过找到数据中最重要的特征来减少数据的维度,同时保留尽可能多的信息。核心思想是将原始数据投影到一个新的特征空间,使得投影后的特征具有最大的方差。方差较大的特征往往包含了数据的重要信息,因此选择这些特征可以更好地表示原始数据。通过计算数据的协方差矩阵,可以得到特征值和特征向量。特征值表示每个特征向量对应的特征的重要程度,特征向量表示特征的方向。选取最大的k个特征值对应的特征向量作为主成分,构成降维后的特征空间。降维后的数据可以通过将原始数据投影到主成分上得到。















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









