










针对二分类问题,最后一层的输出可以采用不同的设置方式,关键取决于目标值y_target的数据处理形式。
目标输出 (0 or 1)
如果y_target处理成(N, 1)格式,即布尔型格式(但本质应该还是整型)
最后一层的网络结构,采用1个神经元的全连接网络:
方案一
tf.keras.layers.Dense(1) #最后层
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
方案二
tf.keras.layers.Dense(1, activation='sigmoid') #最后层
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=False),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
Note: 两个方案的区别是最后一层是否使用sigmoid激活函数处理,将y_pred处理为[0, 1]之间的概率值。同时,处理二元交叉熵的时候,from_logits设置存在差异。
from_logits设置
根据Tensorflow 官网tf.keras.losses.BinaryCrossentropy介绍对未经过概率处理y_pred(方案一)最好设置from_logits=True,使得计算结果更加稳定。
from_logits=True 就表示需要在计算loss前再进行一次概率处理('sigmoid’或者‘softmax’)
结果比较
在没有设置tf随机种子的情况下,比较两个方案的预测结果基本相同
方案一

方案二
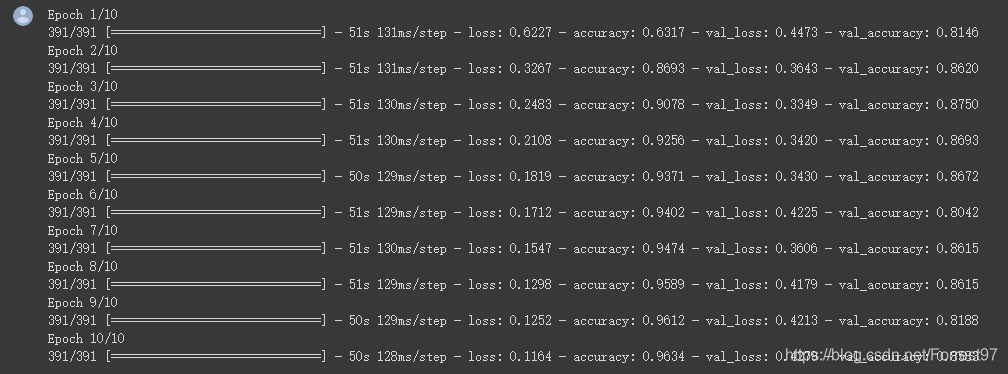
所以,方案一和二在本质上没有任何区别
无概率处理结果
再对比一下最后一层不做概率处理的训练结果

可以看出,由于网络的输出数值不收敛于目标输出的[0,1]区间内,不仅loss数值更大,而且导致整个网络无法训练成功。可见正确设置from_logits对网络训练十分重要。
目标输出 one_hot 编码(10 or 01)
如果如果y_target处理成(N, 2)格式,即输出是经过one_hot编码,本质上同多分类的问题的处理方式相同。
因此针对二分类问题num_classes=2,
activation=‘sigmoid’, 如前一节方案一,没有激活层时注意设置from_logits=False
loss=losses.CategoricalCrossentropy()
tf.keras.layers.Dense(num_classes, activation='sigmoid' )#最后层
newnet.compile(optimizer=optimizers.Adam(lr=1e-3),
loss=losses.CategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])














 5075
5075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









