






datadist函数的设计目的是对预测函数所基于的原始数据进行统计学上的总结,以避免重复读取原始数据。
Discription
对于给定的一组变量或数据框,确定影响和绘制ting范围的变量摘要、要调整的值,以及Predict, plot.Predict, ggplot.Predict, summary.rms, survplot, 和 nomogram.rms的总体范围。如果datadist在进行数据拟合之前即被调用且所指向的结果对象已用 options(datadist="name") 语句指定,使用 Design() 语句可以将数据特征与拟合方法一起存储。因此,之后使用摘要进行的预测和拟合将不需要再次访问在拟合中使用的原始数据。或者,在使用这3个函数时,您可以指定模型中每个变量的值,或者指定其中一些变量的值,并允许函数从datadist创建的对象中查找其余值(如调整级别)。最好的方法可能是在拟合任何模型之前运行datadist一次,存储所有潜在变量的分布摘要。二进制变量的调整值为0,分类变量的调整值为最频繁出现的一类(或自选的第一个类别级别),有序变量的调整值为中间水平,连续变量的调整值为中位数。请参阅q.display和q.effect的描述,了解如何为连续变量选择显示和效果范围。
Usage
datadist(..., data, q.display, q.effect=c(0.25, 0.75),
adjto.cat=c(' mode' ,' first' ), n.unique=10)
# 下文必须添加options(datadist="dd")
# 可用于 summary, plot, survplot, predict
# dd是datadist函数结果的存储变量|
...
| 由逗号分隔的变量名称列表、单个数据框或使用Design信息进行的一次拟合。这个列表中的第一个元素也可以是先前调用datadist所创建的对象;之后的变量将会添加到这个datadist对象中。 (直接翻译的原文档,现在我也不太懂啥意思) |
|
data
| 所需处理的数据框。 |
|
q.display
| 两个百分位数(q分位数和1-q分位数)的集合,用于计算用于显示回归关系的连续变量的范围。默认值是q和1−q,其中q = 10/max(n, 200), n是未丢失的观测数。n<200时,使用5和95百分位数。如果指定q.display,无论是否n<200都按第一种情况来。 |
|
q.effect
| 输入两个百分位数的值,默认为两个四分位数,即0.25和0.75 |
|
adjto.cat
|
default is
"mode"
, indicating that the modal (most frequent) category for categorical (factor) variables is the adjust-to setting. Specify "first"
to use the first level of factor variables as the adjustment values. In the case of many levels having the maximum frequency, the fifirst such level is used for "mode"
.
原文贴在这里,这个玩意没搞明白啥意思,希望有大佬解释下。默认值见上图。
|
|
n.unique
| 具有n.unique或更少唯一值的变量被认为是离散变量,因为它们的唯一值存储在值列表中。这将影响列线图等功能。Design确定变量是否离散的。 |
Value
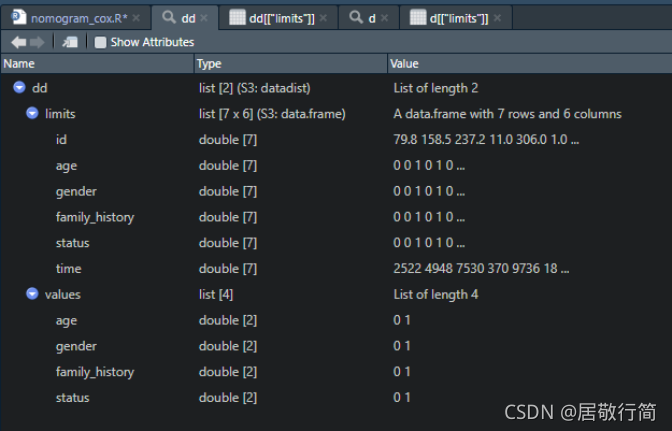
样例如上图,生成样例的代码如下:
library(openxlsx)
library(rms)
file_location <- "C:/Users/hwr99/Desktop/nomogram.xlsx"
sourcedata <- read.xlsx(file_location, sheet=1)
dd = datadist(sourcedata, q.display = c(0,1), q.effect = c(0.25,0.75))
options(datadist = "dd")结果分为两个表:limits和values。
values就是值域表:它把所有可能出现的序列和分类变量的取值全部列在其中
limits是对原始数据的总结表:
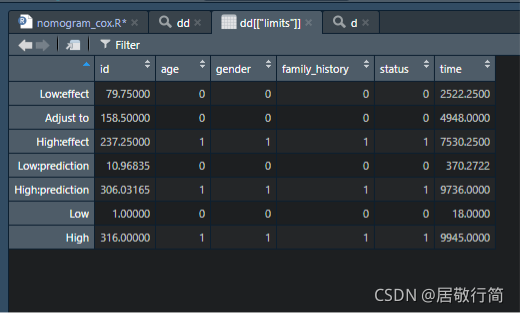
Low:effect 根据之前函数中q.effect项提供的值计算的较小的那个百分位数
Adjust to 中位数
High:effect 根据之前函数中q.effect项提供的值计算的较小的那个百分位数
Low:perdiction 按q.display提供的q和1-q计算出的较小百分位数
High:perdiction 按q.display提供的q和1-q计算出的较小百分位数
Low 极小值
High 极大值
P.S. CSDN文本编译器真难用

















 1339
1339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









