






以下是神经网络中常见的激活函数及其优缺点、改进方法以及示例代码,并将其按照适用场景分类:
1. Sigmoid 激活函数
Sigmoid 激活函数的公式为
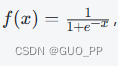
输出值在 0 到 1 之间。
优点:
可以将输出值映射到概率分布,常用于二元分类问题。
缺点:
容易发生梯度消失现象,造成深层网络难以训练。
输出值不是以0为中心的,这会影响优化过程的收敛速度。
改进:
Tanh 函数:Tanh 函数是 Sigmoid 函数的变种,输出值在 -1 到 1 之间,相对于 Sigmoid 更容易进行标准化处理。
Hard Sigmoid 函数:Hard Sigmoid 函数是 Sigmoid 函数的一种简单近似,可以降低计算复杂度,提高运算速度。
示例代码:
python
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
适用场合:二元分类问题
2. ReLU 激活函数
ReLU(Rectified Linear Unit)激活函数的公式为
f(x)=max(0,x),只保留正数部分,负数部分置为 0。
优点:
计算速度快,易于实现。
可以缓解梯度消失问题,提高深层网络的训练速度和准确率。
缺点:
只有正数部分有导数,负数部分导数为 0,可能造成神经元死亡(永远不会被激活)。
容易出现“神经元坍塌”现象,即某些神经元输出恒为 0。
改进:
Leaky ReLU 函数:Leaky ReLU 函数在负数部分引入一个小的斜率,避免了神经元彻底“死亡”的情况。
PReLU 函数:PReLU 函数是对 Leaky ReLU 的进一步改进,采用可学习参数,适应不同的数据集。
示例代码:
python
import numpy as np
def relu(x):
return np.maximum(0, x)
适用场合:多分类和回归问题
3. Tanh 激活函数
Tanh(双曲正切)激活函数的公式为
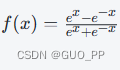
输出值在 -1 到 1 之间。
优点:
比 Sigmoid 函数更具有非线性特性。
输出值在 -1 到 1之间,更容易进行数据标准化。
缺点:
受到梯度消失问题的影响。
改进:
STReLU 函数:STReLU 函数是对 Tanh 函数的改进版本,采用可学习参数,适应不同的数据集。
ISRLU 函数:ISRLU 函数引入了一个参数,可以适当调整斜率和截距,取得更好的效果。
示例代码:
python
import numpy as np
def tanh(x):
return np.tanh(x)
适用场合:分类和回归问题
4. Softmax 激活函数
Softmax 激活函数的公式为 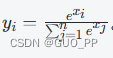
Softmax 激活函数将多个输入值转换为概率分布,常用于多分类问题。
优点:
可以将多个输入值映射到一个概率输出。
对于多元分类问题效果良好。
缺点:
受到过拟合的影响较大,在训练数据不充足时容易出现过拟合现象。
改进:
Sparsemax 函数:Sparsemax 函数是对 Softmax 函数的改进版本,可以产生更稀疏的输出。
Gumbel-Softmax 函数:Gumbel-Softmax 函数是对 Softmax 函数的改进版本,加入了噪声,可以降低模型对训练数据的敏感度。
示例代码:
python
import numpy as np
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1)[:, np.newaxis])
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
适用场合:多元分类问题
5. Swish 激活函数
Swish 激活函数的公式为
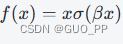
其中 σ 指 Sigmoid 函数,β 是可学习参数。
优点:
比 ReLU 函数更具有非线性特性。
在一些数据集上能够取得更好的分类效果。
缺点:
计算复杂度较高。
改进:
Mish 函数:Mish 函数是对 Swish 函数的改进版本,可以进一步提高分类效果和收敛速度。
示例代码:
python
import numpy as np
def swish(x, beta=1.0):
return x * sigmoid(beta * x)
def mish(x):
return x * np.tanh(softplus(x))
适用场合:
分类和回归问题,特别是在超参数调整时表现良好。
6. ELU 激活函数
ELU(Exponential Linear Unit)激活函数的公式为
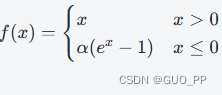
,其中 α 是可学习参数。
优点:
比 ReLU 函数更具有非线性特性。
对于负数部分使用指数函数,可以避免神经元死亡问题。
缺点:
计算复杂度较高。
改进:
SELU 函数:SELU 函数是对 ELU 函数的改进版本,并且具有自归一化特性,适用于深层网络。
示例代码:
python
import numpy as np
def elu(x, alpha=1.0):
return np.where(x > 0, x, alpha * (np.exp(x) - 1))
def selu(x, alpha=1.67326, scale=1.0507):
scale_alpha = scale * alpha
return scale_alpha * np.where(x > 0, x, np.exp(x) - 1)
适用场合:
分类和回归问题,特别是在深层网络中表现良好。
7. Softplus 激活函数
Softplus 激活函数的公式为
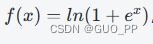
,输出值是正数。
优点:
具有一定的非线性特性。
对于负数部分使用指数函数,可以避免神经元死亡问题。
缺点:
梯度值不稳定,可能会出现梯度消失或爆炸的问题。
改进:
Swish 函数:Swish 函数是对 Softplus 函数的改进版本,可以加强非线性特性,并且具有一定的正则化效果。
示例代码:
python
import numpy as np
def softplus(x):
return np.log(1 + np.exp(x))
def swish(x, beta=1.0):
return x * sigmoid(beta * x)
适用场合:
分类和回归问题。
- Hard Swish 激活函数
Hard Swish 激活函数是对 Swish 函数的改进版本,公式为
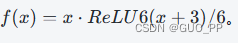
优点:
计算速度快,易于实现。
可以缓解梯度消失问题,并具有一定的正则化能力。
缺点:
对于大于等于 3 的输入值,输出值始终为常量,可能会影响模型表现。
改进:
Mish-hard 函数:Mish-hard 函数是对 Hard Swish 函数的改进版本,引入了可学习参数,可以适应不同的数据集。
示例代码:
python
import numpy as np
def hard_swish(x):
return x * np.minimum(np.maximum(x + 3, 0), 6) / 6
def mish_hard(x, beta=1.0, gamma=1.0):
return x * np.tanh(softplus(beta * x)) * hard_sigmoid(gamma * x)
适用场合:
分类和回归问题。
分类:
一.非线性激活函数
这是神经网络中最常见的类型。非线性激活函数能够使模型输出更加复杂的函数关系,增加模型的表达能力。常用的非线性激活函数有sigmoid、tanh、ReLU等。
二.线性激活函数
线性激活函数不具备非线性特性,只是简单地将输入信号乘以一个权重系数,并加上一个偏置项。因此,使用线性激活函数的模型只能够表示线性函数,对于实际问题并不适用。
三.Softmax激活函数
Softmax激活函数通常用于多分类问题中,它能够将模型的输出转换为一个概率分布,方便进行分类。具体来说,Softmax激活函数会将模型的输出值归一化到[0,1]之间,并且所有输出的和必须等于1。
四.恒等映射激活函数
恒等映射激活函数将输入信号直接输出,不做任何变换。这种激活函数通常用于回归问题中,因为在回归问题中需要输出连续的实数值,而不是离散的类别标签。
总的来说,选择适合的激活函数需要根据具体问题进行权衡,不同的激活函数可能对模型的性能和训练效率产生不同的影响。















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









