







- 在文本分类中,由于文本数据有其领域特殊性,因此,在一个领域上训练的分类器,不能直接拿来作用到另一个领域上,这就需要用到迁移学习。
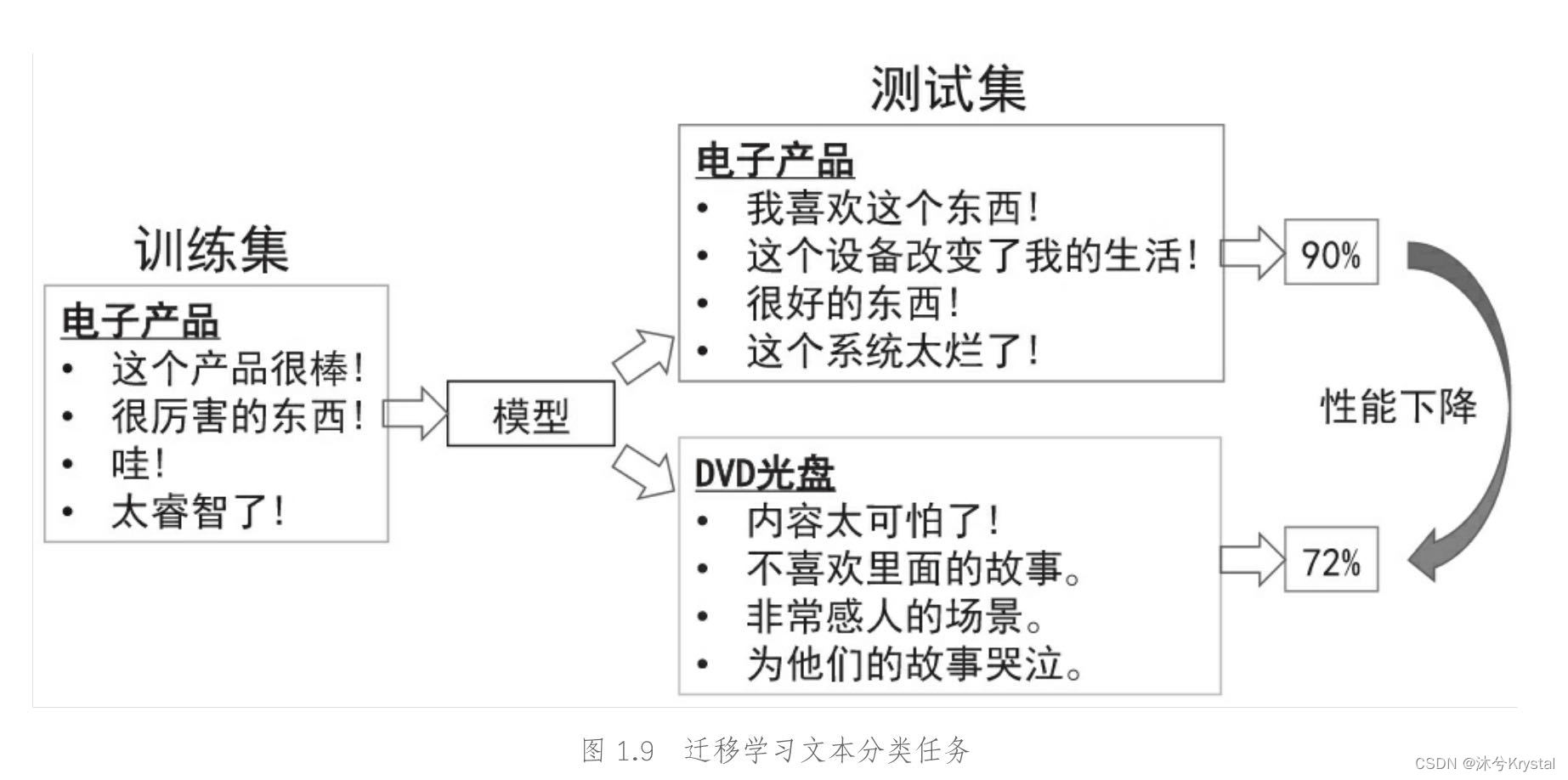
- 迁移学习是机器学习中重要的研究领域,ICML、NIPS、AAAI、ICIR等国际人工智能顶会不断推出迁移学习相关主题的研讨会。
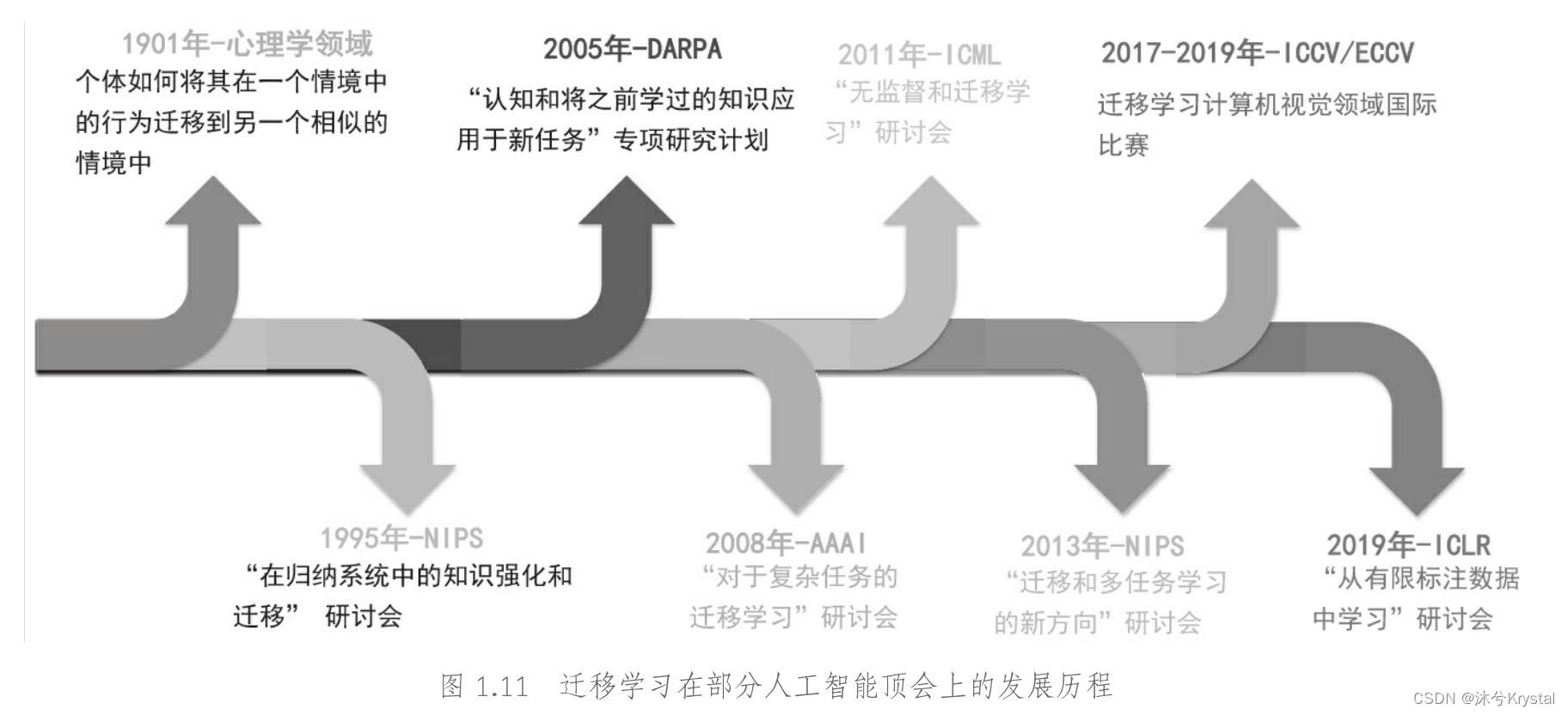
- 以计算机为载体,机器学习涉及统计学、概率论、凸优化、程序设计等多个子领域。
结构风险最小化
- 机器学习就是要寻找一个最优函数 f f f,使得其在所有的训练数据上达到最小的损失。上述学习目标也可以被称为 经验风险最小化 (Empirical Risk Minimization, ERM),其中的损失函数也称为 经验风险。
- 事实上,一个好的机器学习模型,不仅需要对训练数据有强大的拟合能力,还需要对未来的新数据具有足够的预测能力。结构风险最小化(Structural Risk Minimization, SRM)是统计机器学习中一个非常重要的概念。
- SRM准测要求模型在你和训练数据的基础上,也要具有相对简单的复杂性(较低的VC维(Vapnik-Chervonenkis dimension)。
- 通常采用正则化(Regularization)的方法来控制模型的复杂性。
- VC维 是用来衡量研究对象(数据集与学习模型)可学习性的指标。VC维反映了可学习性,与数据量和模型的复杂度相关。因此,VC维较低的模型,其复杂性也较低。
- 常用的正则化项有:控制样本的稀疏程度、筛选样本的L1正则化,使求解简单、避免过拟合的L2正则化,控制目标熵值的熵最小化等。
数据的概率分布
- 传统的机器学习假设模型的训练和测试数据服从同一数据分布。
- 在真实的应用中,训练数据和测试数据的分布往往不尽相同。
迁移学习的问题定义
- 领域(Domain)是学习的主体,主要由两部分构成: 数据 和 生成这些数据的概率分布。
- 一个领域可以被表示为:
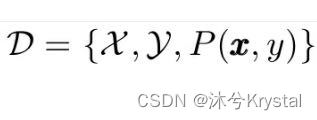
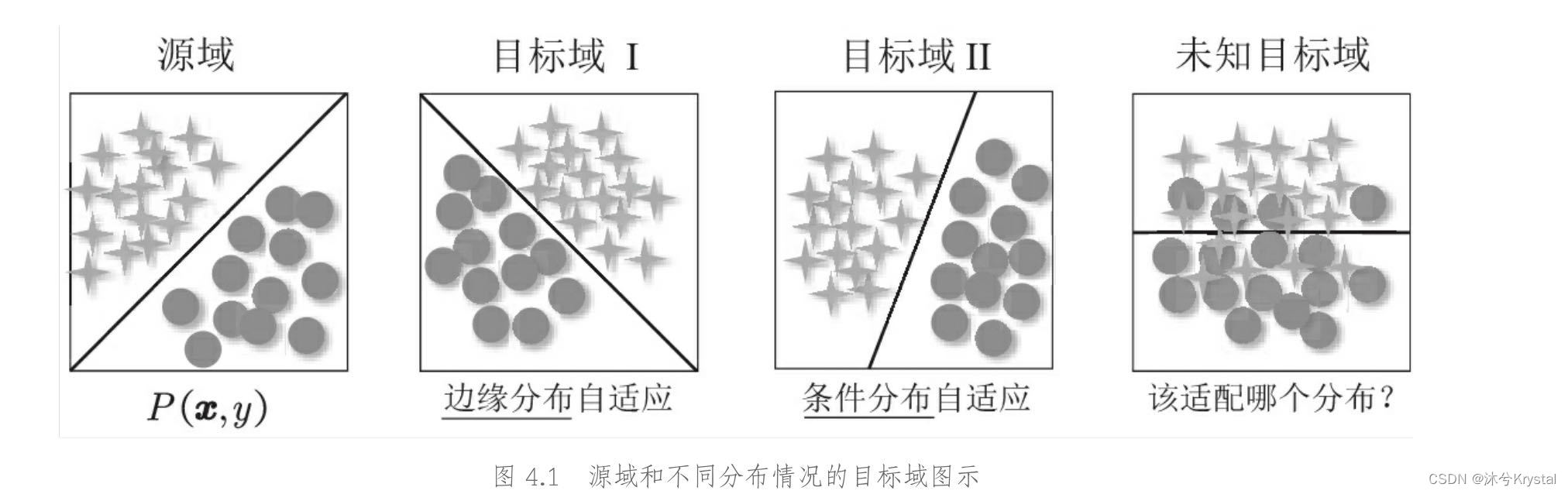
- 两个领域:被迁移的领域和待学习的领域。被迁移的领域、含有知识的领域被称为 源领域 (Source domain,源域),而待学习的领域,被称为 目标领域(Target domain,目标域)。

- 领域自适应(Domain Adaptation):前2种情形相同,第3种情形不同。
- 领域自适应的问题定义如下:

- 领域自适应可以被分为三种:
- 监督领域自适应(SDA)
- 半监督领域自适应(SSDA)
- 无监督领域自适应(UDA)
分布差异的度量
边缘分布自适应(Marginal Distribution Adaptation)
- 边缘分布自适应的本质,与自变量偏移一样,针对的问题是源域和目标域的边缘概率分布不同, P s ( x ) ≠ P t ( x ) P_s(x)\ne P_t(x) Ps(x)=Pt(x)的情况。
- 自变量漂移同时假设二者的条件概率分布相同,即 P s ( y ∣ x ) ≈ P t ( y ∣ x ) P_s(y|x)\approx P_t(y|x) Ps(y∣x)≈Pt(y∣x)。
- 在这个假设的前提下,边缘分布自适应方法的目标是:减少源域和目标域的边缘概率分布的距离。
D ( P s ( x , y ) , P t ( x , y ) ) ≈ D ( P s ( x ) , P t ( x ) ) D(P_s(x,y), P_t(x,y)) \approx D(P_s(x), P_t(x)) D(Ps(x,y),Pt(x,y))≈D(Ps(x),Pt(x))
动态分布自适应(Dynamic Distribution Adaptation)

分布差异的统一表征

分布自适应因子的计算
- 随机猜测法和最大最小平均法。这两种方法需要大量的重复计算,结果并不具有可解释性。
- 动态迁移方法。A-distance 被定义为建立一个二分类器进行不同领域的分类得出的误差。
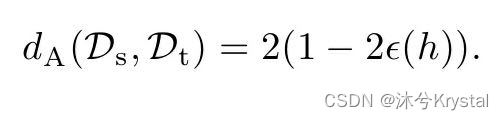

- 由于特征的动态和渐进变化性,此估计需要在每一轮迭代中给出。
迁移学习统一表征
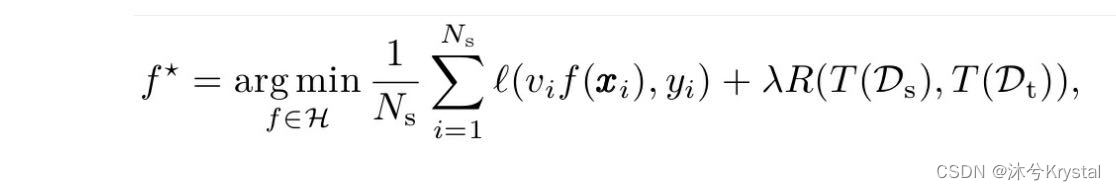
- v ∈ R N s \boldsymbol{v}\in \mathbb{R} ^{N_s} v∈RNs 为源域样本的权重。
- T T T 为作用于源域和目标域上的特征变换函数。
- R ( T ( D s ) , T ( D t ) ) R(T(\mathcal{D_s} ),T(\mathcal{D_t} )) R(T(Ds),T(Dt)) 为迁移正则化项(Transfer Regularization)。
- 迁移学习可以被概括为寻找合适的迁移正则化项的问题。
- 通过对
v
i
v_i
vi 和
T
T
T 取不同的情况,派生出三大类的迁移学习方法:

样本权重迁移法

特征变换迁移法
- 目标是:如何求解特征变换
T
T
T,使得特征变化后的源域和目标域的概率分布差异达到最小。

- 从生成对抗网络的观点来看,网络中的判别器用来判断数据来自真实图像还是噪声,当其无法分别真实图像和噪声产生的图像时,我们认为判别器学习到了领域不变的特征。这种判别器可以被看成一种隐式距离。
模型预训练迁移法

总结


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









