






-
介绍
P-R曲线是一种用于评估分类器性能的常用工具,特别适用于处理不均衡类别分布的问题。P-R 曲线展示了在不同阈值下分类器的精确率和召回率之间的关系。P-R 曲线的横轴是召回率,纵轴是精确率。通过改变分类器的阈值,在横轴上从 0 到 1 的范围内取不同的点,可以计算出对应的精确率和召回率,并绘制出 P-R 曲线。
-
精确率(Precision):在所有被分类为正例的样本中,真实为正例的样本所占的比例。精确率衡量了模型预测为正例的样本中真实正例的准确性。
-
召回率(Recall):在所有真实正例中,被正确分类为正例的样本所占的比例。召回率衡量了模型能够正确预测出真实正例的能力。
ROC曲线是一种用于评估二分类器性能的图形工具。它展示了在不同阈值下,分类器的真正例率与假正例率之间的关系。ROC 曲线的横轴是 FPR,纵轴是 TPR。通过改变分类器的阈值,可以计算出不同阈值下的 TPR 和 FPR,并绘制出 ROC 曲线。
-
真正例率(True Positive Rate,TPR):在所有真实正例中,被正确分类为正例的样本所占的比例,即召回率。TPR衡量了分类器对真实正例的识别能力。
- 假正例率(False Positive Rate,FPR):在所有真实负例中,被错误分类为正例的样本所占的比例。FPR衡量了分类器将负例错误分类为正例的能力。
-
混淆矩阵
P-R曲线和ROC曲线的绘制离不开混淆矩阵——表示模型将样本分类的结果的矩阵

其中TP、FP、FN、TN是进行精确率,召回率,真正例率,假正例率计算的重要数据:
精准率:P=TP/FP+TP
召回率:R=TP/TP+FN
真正例率:TPR=TP/TP+FN
假正例率:FPR=FP/TN+FP
- 绘制
在前面KNN算法的基础我们可以添加绘制P-R曲线和ROC曲线的功能:
1.首先,由于前面KNN算法中我们未分离训练集和测试集,因此无法得到大批量的预测结果。所以,我们首先在原来代码的基础上进行修改,对半划分训练集与测试集。当然,也可以调整其比例,修改test_ratio的值即可。
# 从test.txt中解析数据,并随机将数据集划分为训练集和测试集
def load_dataset(filename, test_ratio=0.5):
with open(filename) as f:
lines = f.readlines()
dataset = []
labels = []
for line in lines:
record = line.strip().split('\t')
dataset.append([float(x) for x in record[:-1]])
labels.append(record[-1])
# 将label转换为数字编码
label_dict = {'口碑极差':1, '口碑不佳':2, '不受欢迎':3, '一般':4, '受欢迎':5, '较受欢迎':6, '很受欢迎':7}
labels = [label_dict[x] for x in labels]
# 随机打乱数据集,并按照test_ratio的比例划分为训练集和测试集
indices = np.arange(len(dataset))
np.random.shuffle(indices)
test_size = int(test_ratio * len(dataset))
test_indices = indices[:test_size]
train_indices = indices[test_size:]
train_dataset = [dataset[i] for i in train_indices]
test_dataset = [dataset[i] for i in test_indices]
train_labels = [labels[i] for i in train_indices]
test_labels = [labels[i] for i in test_indices]
return np.array(train_dataset), train_labels, np.array(test_dataset), test_labels2.在classifyPerson中,我们添加上计算精确率和召回率的代码,同时,未来避免出现除以零错误的错误,添加一些条件语句。
# 计算精确率和召回率
TP = 0 # True Positive
FP = 0 # False Positive
FN = 0 # False Negative
for i in range(len(test_dataset)):
normTestData = (test_dataset[i] - minVals) / ranges
predictedLabel = classify0(normTestData, normMat, train_labels, 3)
if predictedLabel >= 4:
if predictedLabel == test_labels[i]:
TP += 1
else:
FP += 1
else:
if predictedLabel == test_labels[i]:
FN += 1
# 处理除以零错误
if TP + FP == 0:
precision = 0
else:
precision = TP / (TP + FP)
if TP + FN == 0:
recall = 0
else:
recall = TP / (TP + FN)
print(f"精确率:{precision}")
print(f"召回率:{recall}")
3.最后进行P-R图的绘制,首先始化两个空数组precisions和recalls,用于存储每个阈值对应的精确率和召回率。接下来,通过遍历测试数据集中的每个样本,计算在当前阈值下的真正例、假正例和假负例的数量。在每次预测中,将归一化后的测试数据输入到classify0函数中,该函数会返回一个预测标签。根据预测标签和实际标签是否相等以及预测标签是否大于等于当前阈值,将对应的计数器增加,以便计算精确率和召回率。在计算精确率和召回率之后,将其添加到precisions和recalls数组中。循环结束后,使用plt.plot函数绘制P-R曲线,其中横轴是召回率,纵轴是精确率。然后,添加横轴和纵轴的标签,并设置图表的标题。最后,调用plt.show()显示图表。同时也要注意处理零而产生的错误。我们可以通过修改thresholds = np.linspace(0, 10, num=1000)中的数值来控制阈值范围,计算出对应的精确率和召回率
# 绘制P-R图
thresholds = np.linspace(0, 10, num=1000)
precisions = []
recalls = []
for threshold in thresholds:
true_positives = 0
false_positives = 0
false_negatives = 0
for i in range(len(test_dataset)):
normTestData = (test_dataset[i] - minVals) / ranges
predictedLabel = classify0(normTestData, normMat, train_labels, 3)
if predictedLabel >= threshold:
if predictedLabel == test_labels[i]:
true_positives += 1
else:
false_positives += 1
else:
if predictedLabel == test_labels[i]:
false_negatives += 1
# 处理除以零错误
if true_positives + false_positives == 0:
precision = 0
else:
precision = true_positives / (true_positives + false_positives)
if true_positives + false_negatives == 0:
recall = 0
else:
recall = true_positives / (true_positives + false_negatives)
precisions.append(precision)
recalls.append(recall)
plt.plot(recalls, precisions)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('P-R Curve')
plt.show()4.知晓了基本原理后,我们可以利用现有库来精简我们的代码。在sklearn.metrics中有 roc_curve, auc的功能,调用其函数我们可以完成对ROC曲线的绘制。
# 计算预测概率
predicted_probabilities = []
for data in test_dataset:
normTestData = (data - minVals) / ranges
predicted_probabilities.append(classify0(normTestData, normMat, train_labels, 3))
# 计算ROC曲线
fpr, tpr, _ = roc_curve(test_labels, predicted_probabilities)
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()5.运行之后出现的P-R图结果如下:
很明显,该曲线并不符合一般P-R曲线的模样,当预测阈值设置得很高时,模型会将所有样本都预测为负例,即所有点都位于(0,0),在这种情况下,精确率和召回率都为0。随着阈值的降低,一些真正为正例的样本被正确分类,即TP增加,FN和FP减少,从而导致精确率和召回率的增加。P-R图的起点在(0,0)是合理的,因为它反映了在将所有样本都预测为负例时的模型性能。不过这也表明我的样本数量与质量方面有所欠缺,需要对其进行数量与质量的提高。

6.通过对样本中的数据进行追加与高质量更改后运行完成的P-R图和ROC图应如下:
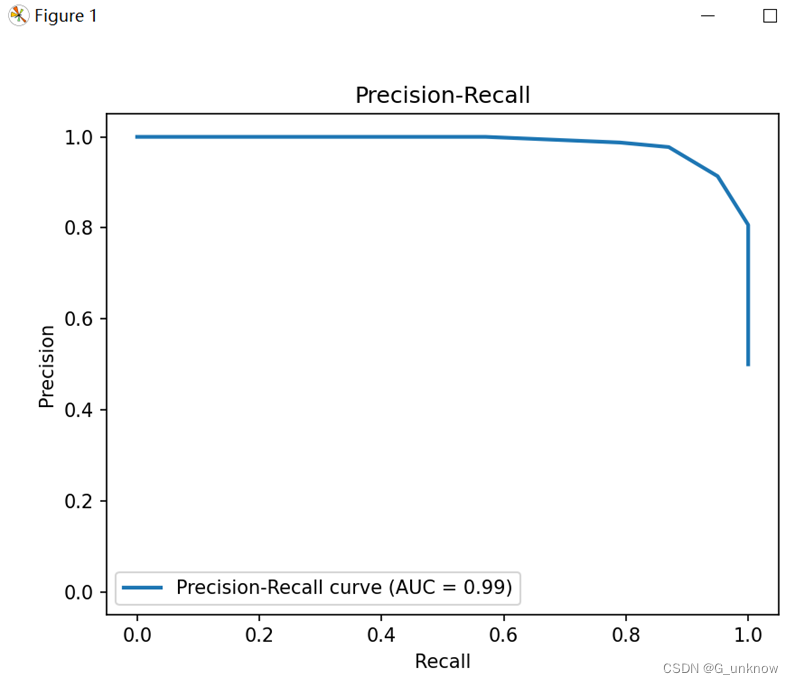
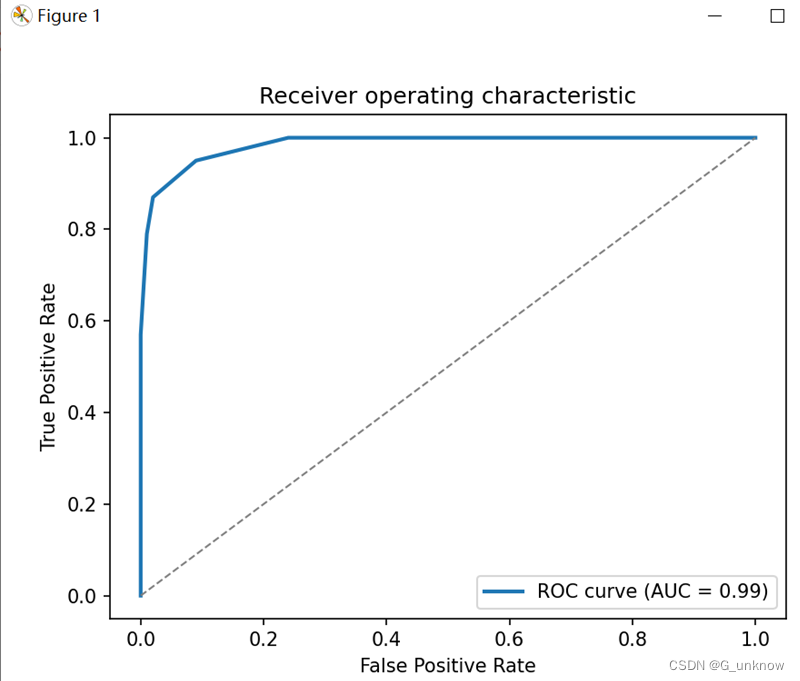
使用质量更高的样本集后明显曲线就会因此变得正常了














 3080
3080











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









