







训练监督学习算法的主要有以下5个步骤:
-
数据预处理
-
选择一个衡量机器学习模型性能的指标
-
选择机器学习算法并训练模型
-
评估模型的性能
-
调整算法参数设置并调试模型
本文还是使用《机器学习系列02:第一个机器学习算法—感知机》一文中介绍的感知机算法和鸢尾花数据集为例简要说明一下这5个步骤。
一、数据预处理
我们已经收集到了150个带有品种标签的鸢尾花样本组成的训练集,经过组内一致论证后(实际工作中,特征选择非常麻烦且耗时,这里为了节省篇幅和照顾初学者,就假设已经选好了特征,后面我们会逐渐学习这些技巧),我们选择萼片长度和花瓣长度作为区分3种鸢尾花品种的特征。
那么我们现在就加载数据集:

在机器学习领域中一般用大写字母 X 表示特征集,可以看到这里 X 是一个 150 行 2 列的矩阵。每行对应一个样本,每列对应样本的一个特征,y 表示样本所属的类别或者目标值(target value)。
不过有一个问题,y 里面的值是文字,这对机器学习算法来说可行不通,我们需要借助 scikit-learn 提供的 LabelEncoder 来将文字标签转成数字。

现在将手头上的数据集按照 7:3 的比例随机将样本分配到训练集和测试集中,为了保证划分之后的训练集和测试集中每个类别的样本数量分布均匀,我们需要分层采样。
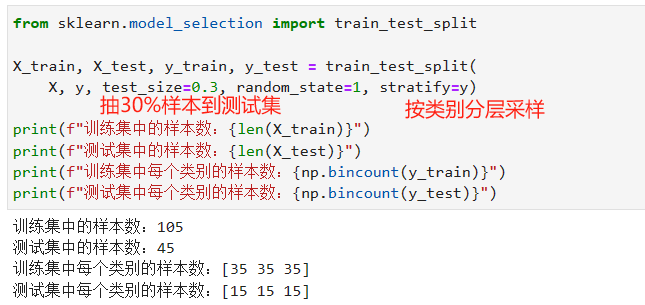
现在训练集和测试集中的样本已经完全被随机打乱了。
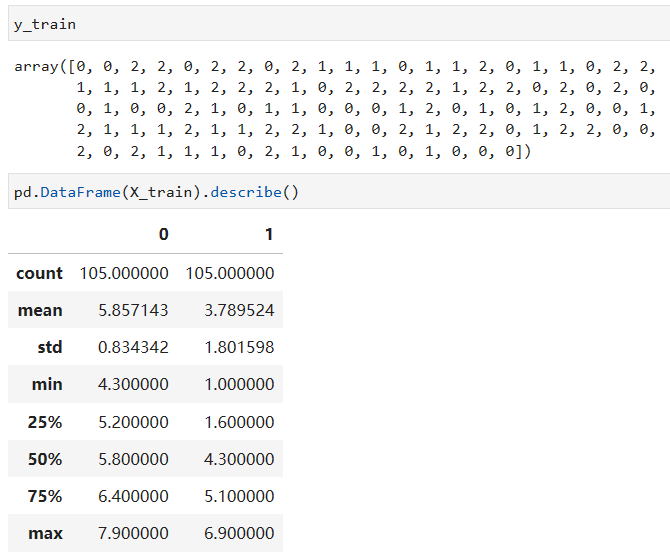
X_train 和 X_test 其实是 numpy array,所以我们可以通过将其转成 pandas dataframe 的形式查看2个数值特征的统计数据。可以看到,这2个特征的取值范围分别是 4.3 ~ 7.9 和 1.0 ~ 6.9。
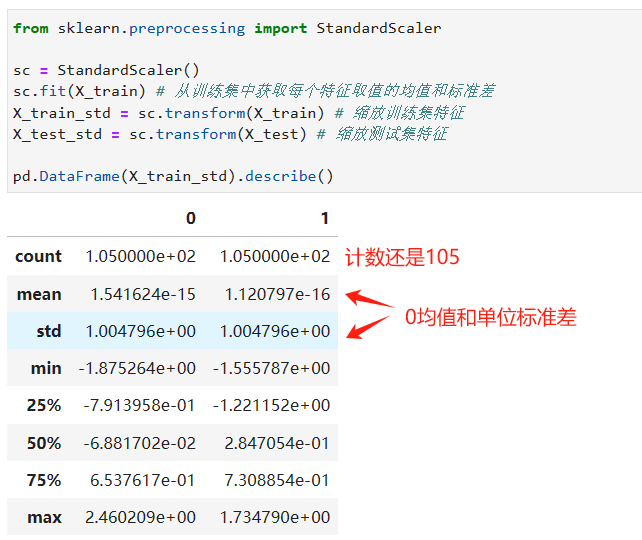
许多机器学习优化算法在特征取值范围都一致时才能发挥最大功效,所以现在还需要对这2个数值特征进行缩放。
二、选择一个衡量机器学习模型性能的指标
我们现在要处理的是分类问题,分类问题最常用的性能指标就是:精度、召回率、准确率、F1值。
三、选择机器学习算法并训练模型
为特定问题和任务选择合适的分类算法需要从实践出发,也和你的经验相关;每种算法都有自己的优劣点,并且基于某些假设前提。套用 David H. Wolpert 的“没有免费午餐”(no free lunch)定理,没有一个分类器能够在所有可能的场景中表现最佳。在实践中,我始终建议你比较几种不同学习算法的性能,以选择针对特定问题的最佳模型。而且还要考虑数据集的特征或样本的数量、数据集中的噪声量以及数据集中的样本是否可线性分等。
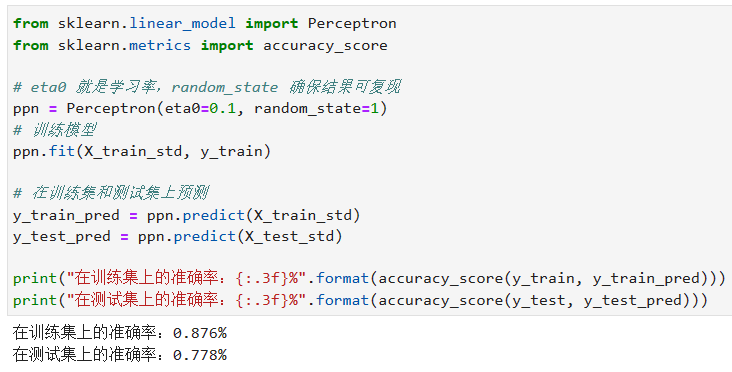
现在我们只会感知机,所以还是选择感知机。
四、评估模型的性能
单从准确率上看,感知机在训练集上的性能要远优于在测试集上的性能,这就是我们将要遇到的过拟合问题。这里先不做过多讨论。
我们再通过可视化的方式看一下分类决策超平面。
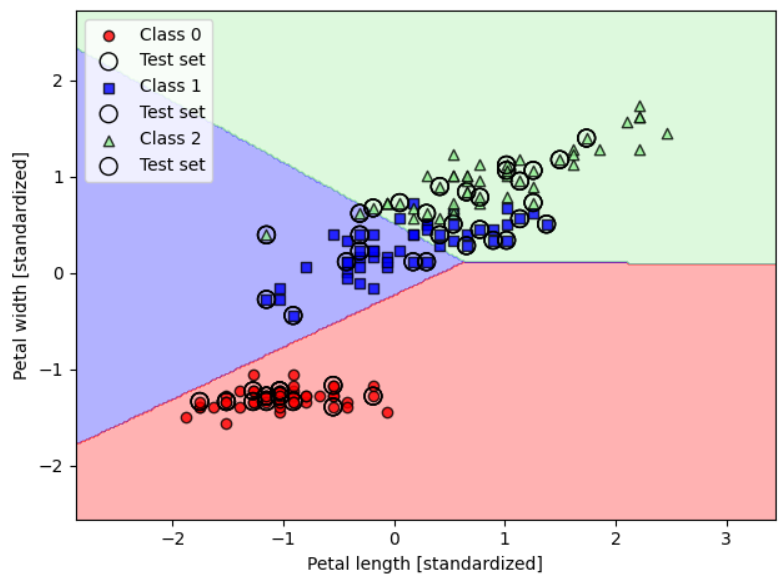
如果数据集线性不可分,那么感知机算法永远不会收敛,从上图也可以看出,感知机并不是一个好的选择。
五、调整算法参数设置并调试模型
结果不理想,一般会选择通过模型的参数或者干脆尝试另一个算法。不过本文的目的是展示一下机器学习问题的一般处理步骤,限于篇幅,先不讨论这一步了,以后会介绍的。
总结
我简单地以感知机算法区分鸢尾花品种的例子说明了机器学习的基本步骤,目的是让初学者形成一个大概的框架。














 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









