







6 KNN (K近邻)
本文Github仓库已经同步文章与代码https://github.com/Gary-code/Machine-Learning-Park/tree/main/Part1%20Machine%20Learning%20Basics
代码说明:
| 文件名 | 说明 |
|---|---|
| knn_simple.ipynb | sklearn包knn算法训练iris数据集 |
| knn_date.ipynb | 约会网站的配对实践 |
| datingTestSet2.txt | 用于knn_date的数据集。 |
knn_date实践描述:
海伦使用约会网站寻找约会对象。经过一段时间之后,她发现曾交往过三种类型的人:
- 不喜欢的人
- 魅力一般的人
- 极具魅力的人
她希望:
- 工作日与魅力一般的人约会
- 周末与极具魅力的人约会
- 不喜欢的人则直接排除掉
现在她收集到了一些约会网站未曾记录的数据信息,这更有助于匹配对象的归类。
总共有 1000 行。海伦约会的对象主要包含以下 3 种特征:
- 每年获得的飞行常客里程数
- 玩视频游戏所耗时间百分比
- 每周消费的冰淇淋公升数
KNN
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(K个邻居),这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
下面举一个简单的例子:
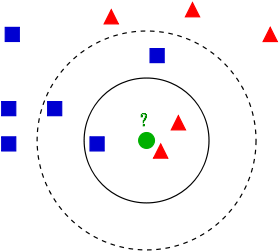
图中的那个绿色的圆所标示的数据则是待分类的数据。KNN就是解决这个分类问题的
-
如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
-
如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
当无法判定当前待分类点是从属于已知分类中的哪一类时,我们可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类。这就是K近邻算法的核心思想。
距离公式
- 欧氏距离:
d ( x , y ) = ( x 1 − y 1 ) 2 + ( x 2 − y 2 ) 2 + … + ( x n − y n ) 2 = ∑ i = 1 n ( x i − y i ) 2 d(x, y)=\sqrt{\left(x_{1}-y_{1}\right)^{2}+\left(x_{2}-y_{2}\right)^{2}+\ldots+\left(x_{n}-y_{n}\right)^{2}}=\sqrt{\sum_{i=1}^{n}\left(x_{i}-y_{i}\right)^{2}} d(x,y)=(x1−y1)2+(x2−y2)2+…+(xn−yn)2=i=1∑n(xi−yi)2
d 12 = ( a − b ) ( a − b ) T ( 向 量 表 示 ) d_{12}=\sqrt{(a-b)(a-b)^{T}}(向量表示) d12=(a−b)(a−b)T(向量表示)
标准化后的欧式距离:
标
准
化
后
的
值
=
(
标
准
化
前
的
值
-
分
量
的
均
值
)
分
量
的
标
准
差
标准化后的值 = \frac{( 标准化前的值 - 分量的均值 )}{分量的标准差}
标准化后的值=分量的标准差(标准化前的值-分量的均值)
d
12
=
∑
k
=
1
n
(
x
1
k
−
x
2
k
s
k
)
2
d_{12}=\sqrt{\sum_{k=1}^{n}\left(\frac{x_{1 k}-x_{2 k}}{s_{k}}\right)^{2}}
d12=k=1∑n(skx1k−x2k)2
- 曼哈顿距离
类似一个十字路口拐弯
∣ x 1 − x 2 ∣ + ∣ y 1 − y 2 ∣ \left|x_{1}-x_{2}\right|+\left|y_{1}-y_{2}\right| ∣x1−x2∣+∣y1−y2∣
对于两个n维向量a,b:
d
12
=
∑
k
=
1
n
∣
x
1
k
−
x
2
k
∣
d_{12}=\sum_{k=1}^{n} \mid x_{1 k}-x_{2 k} \mid
d12=k=1∑n∣x1k−x2k∣
当然还有很多类型的距离公式,有兴趣的读者可以自行查阅相关资料。
K值选择
相信看完上面的简单例子,大家都知道 K K K值的选择对分类的结果是有较大影响的,这里我们探讨一下如何选择 K K K值。
- 如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
- 如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
- K=N,则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的累,模型过于简单,忽略了训练实例中大量有用信息。
在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(一部分样本做训练集,一部分做验证集)来选择最优的K值。
算法过程
- 计算测试样本和训练样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等)。
- 对上面所有的距离值进行排序。
- 选前 k k k个最小距离的样本。
- 根据这 k k k个样本的标签进行投票,得到最后的分类类别。















 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









