









目录
限流
-
限流又称为流量控制(流控),通常是指限制到达系统的并发请求数。
-
限流虽然会影响部分用户的使用体验,但是却能在一定程度上报障系统的稳定性,不至于崩溃。
-
互联网上类似需要限流的业务场景也有很多,比如电商系统的秒杀、微博上突发热点新闻、双十一购物节、12306抢票等等。这些场景下的用户请求量通常会激增,远远超过平时正常的请求量,此时如果不加任何限制很容易就会将后端服务打垮,影响服务的稳定性。
-
此外,一些厂商公开的API服务通常也会限制用户的请求次数,比如百度地图开放平台等会根据用户的付费情况来限制用户的请求数等。
限流key
在实施限流时,需要确定一个用于标识和区分不同资源或用户的“key”。
以下是一些常见的限流“key”的示例:
-
IP地址:对于基于网络的服务,可以使用客户端的IP地址作为限流的key。这样可以限制来自同一IP的请求速率。
-
用户ID:如果你的服务需要用户登录,你可以使用用户的唯一标识符(如用户ID或用户名)作为限流的key,以便对每个用户单独进行限流。
-
API密钥:如果你的服务通过API提供访问,可以使用分配给每个开发者或应用程序的唯一API密钥作为限流的key。
-
会话ID:对于Web应用程序,你可以使用会话ID作为限流的key,以限制同一会话中的请求速率。
-
设备ID:对于移动应用或其他设备相关的服务,可以使用设备的唯一标识符作为限流的key。
-
Token或令牌:在一些身份验证流程中,服务器可能会生成一个临时的令牌或者token,可以将其用作限流的key。
-
URL路径或资源路径:如果你想限制对特定资源的访问速率,可以使用资源路径作为限流的key。
-
HTTP方法+URL路径:结合HTTP请求方法(GET、POST等)和URL路径可以更精确地限制特定操作的访问速率。
-
组合键:你也可以结合多个因素来创建一个复合的限流key,以更精确地控制访问速率。
选择限流的key取决于具体场景和需求。需要考虑哪些因素最重要,以及如何在保护系统免受滥用的同时保持合理的访问速率。
针对匿名用户的限流key
对于匿名用户(未登录用户),由于缺乏明确的身份标识,限流策略可能会相对复杂一些,以下是一些常见的方法:
-
IP地址:对于Web应用程序,最简单的方法是使用访问者的IP地址作为限流的key。这可以防止同一IP地址在短时间内发起过多的请求。
-
Cookie或Session ID:如果你的应用程序使用了会话(session)管理或者设置了特定的cookie,你可以使用会话ID或cookie的值作为限流的key。这对于Web应用程序来说是一种有效的方法。
-
User-Agent:User-Agent是HTTP请求头的一部分,包含了客户端的一些信息,如浏览器、操作系统等。尽管可以伪造,但在某些情况下,User-Agent也可以作为一个不太可靠但仍然可以使用的匿名用户限流的key。
-
令牌(Token):即使未登录用户,你也可以为他们分配一个临时的访问令牌,并将其用作限流的key。
-
设备指纹:通过收集有关访问者设备的信息(如浏览器版本、操作系统、屏幕分辨率等),可以创建一个“设备指纹”作为匿名用户的限流key。
-
基于行为的限流:除了基于标识信息的限流,你还可以考虑根据用户的行为模式来进行限流。例如,限制一定时间内的请求频率。
需要注意的是,匿名用户的限流策略可能会相对容易被绕过,因此在设计限流策略时,需要权衡安全性和用户体验,并考虑到可能的滥用情况。最好的方式是采取多层次的安全措施,包括使用一些先进的安全技术来保护应用程序免受滥用。
IP地址做key
python著名框架drf中,对于匿名用户就是采用了IP地址做限流key,以下是源码:
def get_ident(self, request):
"""
如果该字段存在并且代理数量大于0,通过解析 HTTP_X_FORWARDED_FOR 来确定发出请求的机器。
如果不可用,则使用所有的 HTTP_X_FORWARDED_FOR(如果可用),否则使用 REMOTE_ADDR。
"""
xff = request.META.get('HTTP_X_FORWARDED_FOR')
remote_addr = request.META.get('REMOTE_ADDR')
num_proxies = api_settings.NUM_PROXIES
if num_proxies is not None:
if num_proxies == 0 or xff is None:
return remote_addr
addrs = xff.split(',')
client_addr = addrs[-min(num_proxies, len(addrs))]
return client_addr.strip()
return ''.join(xff.split()) if xff else remote_addr
由于django会将headers中的key都大写后并拼接上HTTP_,放到request.META中,所以实际解析的是:X_FORWARDED_FOR,参考:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/X-Forwarded-For
X-Forwarded-For(XFF)请求标头是一个事实上的用于标识通过代理服务器连接到 web 服务器的客户端的原始 IP 地址的标头。
当客户端直接连接到服务器时,其 IP 地址被发送给服务器(并且经常被记录在服务器的访问日志中)。但是如果客户端通过正向或反向代理服务器进行连接,服务器就只能看到最后一个代理服务器的 IP 地址,这个 IP 通常没什么用。如果最后一个代理服务器是与服务器安装在同一台主机上的负载均衡服务器,则更是如此。X-Forwarded-For 的出现,就是为了向服务器提供更有用的客户端 IP 地址。
X-Forwarded-For: 2001:db8:85a3:8d3:1319:8a2e:370:7348
X-Forwarded-For: 203.0.113.195
X-Forwarded-For: 203.0.113.195, 2001:db8:85a3:8d3:1319:8a2e:370:7348
X-Forwarded-For: 203.0.113.195,2001:db8:85a3:8d3:1319:8a2e:370:7348,150.172.238.178
选择一个 IP 地址:
选择地址时,必须使用从所有 X-Forwarded-For 标头生成的完整 IP 列表。
当选择离客户端最近的 X-Forwarded-For IP 地址时(不可信并且不用于安全相关的目地),应该选择最左边的、第一个有效且不是私有/内部地址的 IP 地址。(要求”有效“是因为伪造的值可能根本就不是 IP 地址;要求“不是私有/内部地址”是因为客户端使用的代理服务器可能在它们的内部网络中,在这种情况下代理服务器可能添加了私有 IP 地址空间中的地址。)
当选择第一个可信的 X-Forwarded-For 客户端 IP 地址时,需要进行额外的配置。有两种常用的方法:
受信任代理服务器数量:配置了互联网和服务器之间的反向代理服务器数量。从 X-Forwarded-For IP 列表的最右边开始搜索,第(受信任代理服务器数量 - 1)个地址就是目标地址。(例如,如果只有一个反向代理服务器,这个代理服务器会添加客户端的 IP 地址,因此应该使用最右边的地址。如果有三个反向代理服务器,最后两个 IP 地址将是内部地址。)
受信任代理服务器列表:配置了受信任反向代理服务器的 IP 或 IP 范围。从 X-Forwarded-For IP 列表的最右边开始搜索,跳过受信任代理服务器列表中的所有地址。第一个不匹配的地址就是目标地址。
第一个可信的 X-Forwarded-For IP 地址可能属于一个不受信任的中间代理服务器,而不是实际的客户计算机,但这是唯一一个适用于安全用途的 IP 了。
注意如果从互联网可直接连接到服务器——即使服务器也位于一个受信任的反向代理服务器之后——X-Forwarded-For IP 列表中的任何部分都不能被认为是可信赖的,或者可安全地用于安全相关的用途。
想要使用xff只需要在nginx增加对应配置即可:
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-NginX-Proxy true;
proxy_pass http://127.0.0.1:9009/;
proxy_redirect off;
}
注:wiki百科
IPv4私有地址:
IPv6私有地址:

综上,根据IP限流的方案不太可行:
- 无法取到用户真正的IP地址(内网IP地址),IPV4的设计导致一个小区的用户共用一个网关,服务器取到的很可能是网关和代理的地址。
- 尤其是真正的后端服务隐藏在代理服务器后边时,取到的IP是反向代理服务器的IP地址。
- xff也是可以被篡改的。
API密钥/Token做限流key
无论用户是否登录,服务端都可以签发一个API密钥/Token做限流。
对于未携带该key的request可以直接认为是非法请求,而一旦携带了该key就会被限流。
签发出去的key可以是任何形式,哪怕是一个uuid都可以。
限流策略
常见的限流算法有:令牌桶、漏桶、Redis 计数器。
redis计数器
参考drf的实现方法。(djangorestframework全解)
def allow_request(self, request, view):
"""
Implement the check to see if the request should be throttled.
On success calls `throttle_success`.
On failure calls `throttle_failure`.
"""
if self.rate is None:
return True
# 从redis中获取缓存的key,
# 比如:throttle_phone_12345678900(手机号)
self.key = self.get_cache_key(request, view)
if self.key is None:
return True
# 从redis中获取访问记录
self.history = self.cache.get(self.key, [])
// 获取当前时间(默认python time模块会返回时间戳)
self.now = self.timer()
# 删除历史记录中已超过限制持续时间的所有请求
# duration = {'s': 1, 'm': 60, 'h': 3600, 'd': 86400}
# duration = 60
while self.history and self.history[-1] <= self.now - self.duration:
self.history.pop()
# 如果历史记录的长度大于配置的该接口允许请求的次数就拒绝
# self.num_requests去配置文件读取当前接口的配置,比如:1/60s
# self.num_requests = 1
if len(self.history) >= self.num_requests:
# 返回False
return self.throttle_failure()
# 否则成功
# self.throttle_success():
# 1. 将当前时间放入历史记录列表[time1,time2,time3...]
# self.history.insert(0, self.now)
# 2. 将历史记录存入redis,设置过期时间为配置的时间
# self.cache.set(self.key, self.history, self.duration)
# 3. 返回允许
# return True
return self.throttle_success()
简陋的实现一个GO版本的:
const (
sms = "1/60s"
key = "send_sms_%s"
)
var cache = map[string][]time.Time{}
func ParseThrottle(cfg string) (int, time.Duration) {
countDuration := strings.Split(cfg, "/")
count, duration := countDuration[0], countDuration[1]
c, _ := strconv.Atoi(count)
tmp, _ := strconv.Atoi(duration[:len(duration)-1])
flg := duration[len(duration)-1]
d := time.Duration(tmp)
switch flg {
case 's':
d = d * time.Second
case 'm':
d = d * time.Minute
case 'h':
d = d * time.Hour
default:
panic("invalid throttle config")
}
return c, d
}
func Throttle() bool {
phone := "123456788900"
k := fmt.Sprintf(key, phone)
c, d := ParseThrottle(sms)
// 1 1m0s
// fmt.Println(c, d)
history := cache[k]
now := time.Now()
newList := make([]time.Time, 0)
for index := range history {
// 未过期
if !history[index].Add(d).Before(now) {
newList = append(newList, history[index])
}
}
if len(newList) >= c {
return false
}
newList = append(newList, now)
cache[k] = newList
return true
}
func main() {
//RunServer()
for i := 0; i < 10; i++ {
fmt.Println(Throttle())
}
}
redis zset限流(滑动窗口?)
先来看一个错误的限流算法:
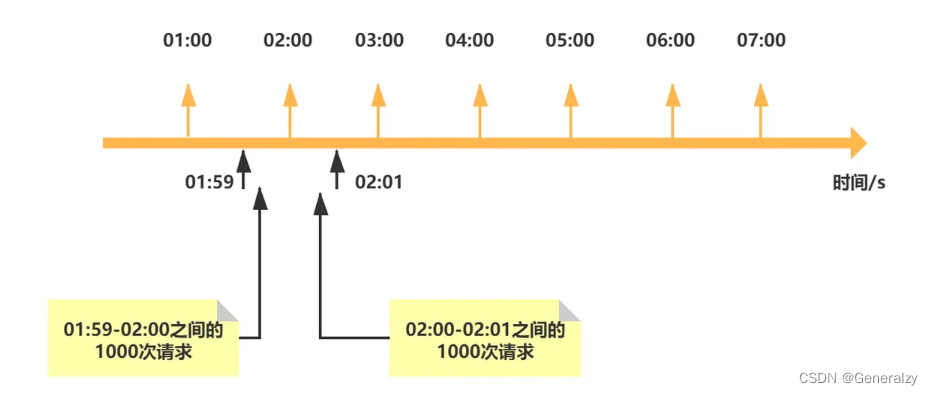
01:00s-02:00s之间只允许访问1000次,这种设计最大的问题在于,请求可能在01:59s-02:00s之间被请求1000次,02:00s-02:01s之间被请求了1000次,这种情况下01:59s-02:01s间隔0.02s之间被请求2000次,很显然这种设计是错误的。
滑动窗口算法:
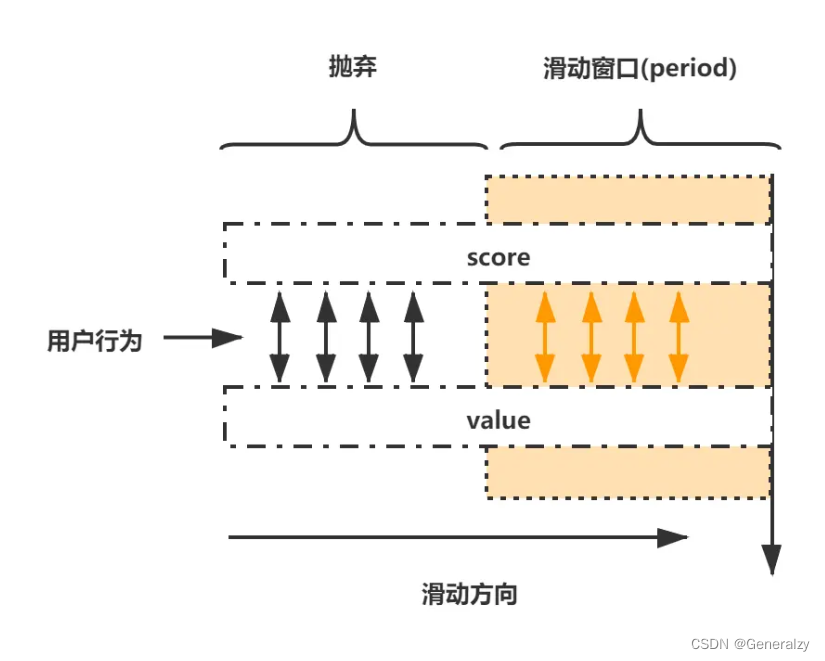
指定时间T内,只允许发生N次。可以将这个指定时间T,看成一个滑动时间窗口(定宽)。采用Redis的zset基本数据类型的score来圈出这个滑动时间窗口。在实际操作zset的过程中,只需要保留在这个滑动时间窗口以内的数据,其他的数据不处理即可。
每个用户的行为采用一个zset存储,score为毫秒时间戳,value也使用毫秒时间戳(比UUID更加节省内存)
只保留滑动窗口时间内的行为记录,如果zset为空,则移除zset(过期),不再占用内存(节省内存)
我们直接使用Lua脚本来控制原子性,否则在高并发下容易有各种意想不到的操作(来自我找bug 6小时,修bug 2分钟的教训)
直接给出lua代码:
-- 首先删除落在区间外的request
redis.call('ZREMRANGEBYSCORE', KEYS[1], 0, tonumber(ARGV[2]))
-- 统计当前区间内的request数量
local count
count = redis.call('ZCARD',KEYS[1])
-- 声明一个布尔值判断是否允许请求接口(在redis是1)
local ok
-- %d是因为我要在代码里渲染一个limit进去
ok = count < %d
-- 当允许请求接口时
-- 1. 将当前request的时间记录
-- 2. 刷新当前zset的存活时间(延长租期)单位为s
if ok then
redis.call('ZADD',KEYS[1],tonumber(ARGV[1]),ARGV[1])
redis.call('EXPIRE', KEYS[1], tonumber(ARGV[2]))
end
-- 返回是否允许访问
return ok;
由于配置限流的策略一般是每秒多少次,每分多少次,每时多少次…,所以直接采用秒做单位,给出解析函数:
# 配置:throttle_{ip}_{api}: 10/m
def parse_throttle_rate(rate:str):
limit,unit = rate.split("/",1)
# 1s
duration = 1
if unit == "h"
duration = duration * 60 * 60
elif unit == "m":
duration = duration * 60
...
return limit,duration
我们将限流的粒度控制在api上,基于ip进行限流,所以zset的key就是:throttle_{ip}_{api}
以python为例,利用redis client的eval执行lua脚本:
def ok(redis_client,key,limit,duration)->bool:
from time import time
# 单位为秒
score = int(time())
# 渲染模板
script = lua_script_template%limit
# 分别传入: 脚本,key的数量,分数,区间下限,区间长度
return redis_client.eval(script,1,key,score,score-duration,duration)
真正决定是否可以访问的只有最后一行的原子操作,所以不会有并发问题。
redis操作时单线程的,平常如果想要redis原子性操作的话,可以使用incrBy()和decrBy()方法进行原子性的加减,但是对于事务性的逻辑操作,没有办法实现原子性,Redis 使用单个 Lua 解释器去运行所有脚本,当某个脚本正在运行的时候,不会有其他脚本或 Redis 命令被执行,因此,lua脚本需要运行的使用比较快,不会妨碍其它lua脚本执行。
但要注意“元素覆盖”:
在 Redis 的有序集合(ZSET)中,元素覆盖是指向集合中添加一个已经存在的成员时,新的分数将会覆盖旧的分数。
如果使用 ZADD 命令添加一个已存在的成员,它将更新该成员的分数,并且重新排序以保持有序集的顺序。
例如:
127.0.0.1:6379> ZADD myzset 1 "one"
(integer) 1
127.0.0.1:6379> ZADD myzset 2 "one" # 将 "one" 的分数更新为 2
(integer) 0 # 0 表示更新了现有成员的分数
如果想要在保持成员不变的情况下更新分数,可以使用 ZINCRBY 命令,它会将分数增加特定的值:
127.0.0.1:6379> ZADD myzset 1 "one"
(integer) 1
127.0.0.1:6379> ZINCRBY myzset 2 "one" # 将 "one" 的分数增加 2
"3" # 返回新的分数
总的来说,有序集合提供了方便的方法来管理和更新成员的分数,可以根据需要使用不同的命令来实现你的需求。
因为zset的这个特性,可能会导致在高并发下,出现成员覆盖,导致多次请求只记录了一次,其中一个解决方案是:
- score取请求到达的时间,但value取score的内存地址值,同一次请求中内存地址值很少会重复。
- 每一次请求的value都取一个uuid,重复的概率更低。
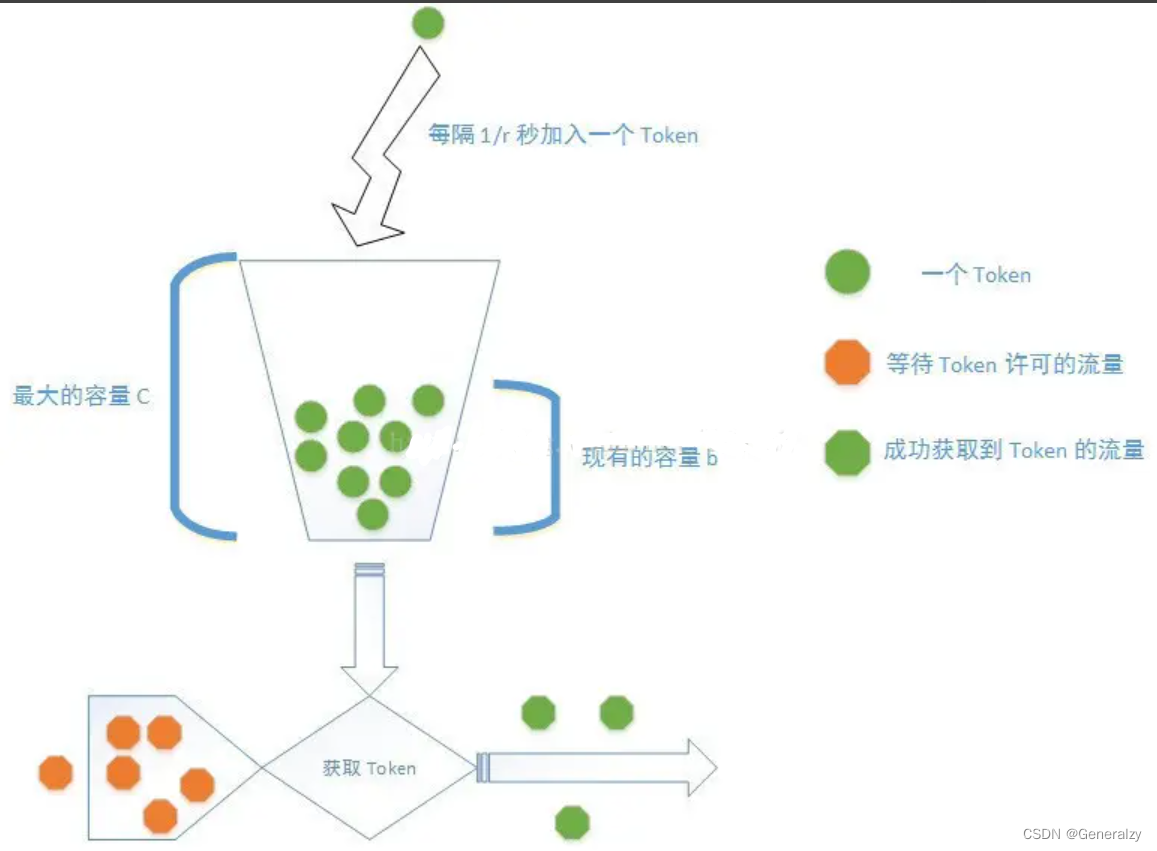
令牌桶算法 (Token Bucket)
-
令牌桶大小固定,系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
-
如果令牌不被消耗,或者被消耗的速度小于产生的速度,令牌就会不断地增多,直到把桶填满。
-
后面再产生的令牌就会从桶中溢出。最后桶中可以保存的最大令牌数永远不会超过桶的大小。
-
对于从桶里取不到令牌的场景,我们可以选择等待也可以直接拒绝并返回。
-
对于令牌桶的Go语言实现,可以参照 github.com/juju/ratelimit (2.5k star)库。这个库支持多种令牌桶模式,并且使用起来也比较简单。
创建令牌桶的方法:
// 创建指定填充速率和容量大小的令牌桶
func NewBucket(fillInterval time.Duration, capacity int64) *Bucket
// 创建指定填充速率、容量大小和每次填充的令牌数的令牌桶
func NewBucketWithQuantum(fillInterval time.Duration, capacity, quantum int64) *Bucket
// 创建填充速度为指定速率和容量大小的令牌桶
// NewBucketWithRate(0.1, 200) 表示每秒填充20个令牌
func NewBucketWithRate(rate float64, capacity int64) *Bucket
取出令牌的方法如下:
// 取token(非阻塞)
func (tb *Bucket) Take(count int64) time.Duration
func (tb *Bucket) TakeAvailable(count int64) int64
// 最多等maxWait时间取token
func (tb *Bucket) TakeMaxDuration(count int64, maxWait time.Duration) (time.Duration, bool)
// 取token(阻塞)
func (tb *Bucket) Wait(count int64)
func (tb *Bucket) WaitMaxDuration(count int64, maxWait time.Duration) bool
虽说是令牌桶,但是我们没有必要真的去生成令牌放到桶里,我们只需要每次来取令牌的时候计算一下,当前是否有足够的令牌就可以了,具体的计算方式可以总结为下面的公式:
当前令牌数 = 上一次剩余的令牌数 + (本次取令牌的时刻-上一次取令牌的时刻)/放置令牌的时间间隔 * 每次放置的令牌数
关于令牌数计算的源代码如下:
func (tb *Bucket) currentTick(now time.Time) int64 {
return int64(now.Sub(tb.startTime) / tb.fillInterval)
}
func (tb *Bucket) adjustavailableTokens(tick int64) {
if tb.availableTokens >= tb.capacity {
return
}
tb.availableTokens += (tick - tb.latestTick) * tb.quantum
if tb.availableTokens > tb.capacity {
tb.availableTokens = tb.capacity
}
tb.latestTick = tick
return
}
获取令牌的TakeAvailable()函数关键部分的源代码如下:
func (tb *Bucket) takeAvailable(now time.Time, count int64) int64 {
if count <= 0 {
return 0
}
tb.adjustavailableTokens(tb.currentTick(now))
if tb.availableTokens <= 0 {
return 0
}
if count > tb.availableTokens {
count = tb.availableTokens
}
tb.availableTokens -= count
return count
}
gin框架中使用令牌桶
对于该限流中间件的注册位置,可以按照不同的限流策略将其注册到不同的位置,例如:
- 如果要对全站限流就可以注册成全局的中间件。
- 如果是某一组路由需要限流,那么就只需将该限流中间件注册到对应的路由组即可。
func RateLimitMiddleware(fillInterval time.Duration, cap int64) func(c *gin.Context) {
bucket := ratelimit.NewBucket(fillInterval, cap)
return func(c *gin.Context) {
// 如果取不到令牌就中断本次请求返回 rate limit...
if bucket.TakeAvailable(1) < 1 {
c.String(http.StatusOK, "rate limit...")
c.Abort()
return
}
c.Next()
}
}
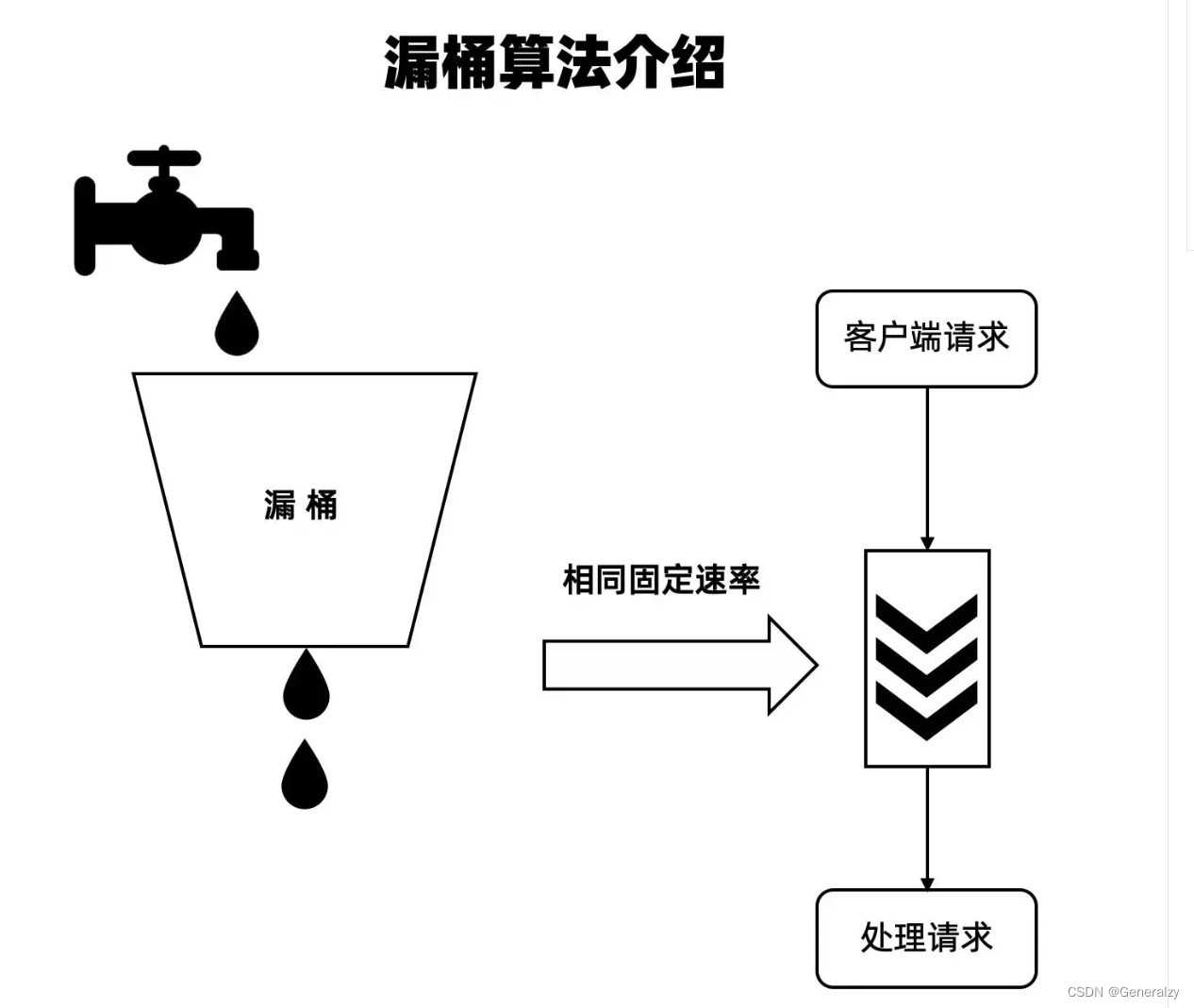
漏桶算法 (Leaky Bucket)
-
水 (请求) 先进入到漏桶里,漏桶以一定的速度出水 (接口有响应速率), 当水流入速度过大会直接溢出 (访问频率超过接口响应速率), 然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率。
-
可见这里有两个变量,一个是桶的大小,支持流量突发增多时可以存多少的水 (burst), 另一个是水桶漏洞的大小 (rate)。
-
因为漏桶的漏出速率是固定的参数,所以,即使网络中不存在资源冲突 (没有发生拥塞), 漏桶算法也不能使流突发 (burst) 到端口速率。因此,漏桶算法对于存在突发特性的流量来说缺乏效率.
-
关于漏桶的实现,uber团队有一个开源的github.com/uber-go/ratelimit库(3.5k star)。 这个库的使用方法比较简单,Take() 方法会返回漏桶下一次滴水的时间。它的源码实现也比较简单。
import (
"fmt"
"time"
"go.uber.org/ratelimit"
)
func main() {
rl := ratelimit.New(100) // per second
prev := time.Now()
for i := 0; i < 10; i++ {
now := rl.Take()
fmt.Println(i, now.Sub(prev))
prev = now
}
// Output:
// 0 0
// 1 10ms
// 2 10ms
// 3 10ms
// 4 10ms
// 5 10ms
// 6 10ms
// 7 10ms
// 8 10ms
// 9 10ms
}
限制器是一个接口类型,其要求实现一个Take()方法:
type Limiter interface {
// Take方法应该阻塞已确保满足 RPS
Take() time.Time
}
实现限制器接口的结构体定义如下
type limiter struct {
sync.Mutex // 锁
last time.Time // 上一次的时刻
sleepFor time.Duration // 需要等待的时间
perRequest time.Duration // 每次的时间间隔
maxSlack time.Duration // 最大的富余量
clock Clock // 时钟
}
limiter结构体实现Limiter接口的Take()方法内容如下:
// Take 会阻塞确保两次请求之间的时间走完
// Take 调用平均数为 time.Second/rate.
func (t *limiter) Take() time.Time {
t.Lock()
defer t.Unlock()
now := t.clock.Now()
// 如果是第一次请求就直接放行
if t.last.IsZero() {
t.last = now
return t.last
}
// sleepFor 根据 perRequest 和上一次请求的时刻计算应该sleep的时间
// 由于每次请求间隔的时间可能会超过perRequest, 所以这个数字可能为负数,并在多个请求之间累加
t.sleepFor += t.perRequest - now.Sub(t.last)
// 我们不应该让sleepFor负的太多,因为这意味着一个服务在短时间内慢了很多随后会得到更高的RPS。
if t.sleepFor < t.maxSlack {
t.sleepFor = t.maxSlack
}
// 如果 sleepFor 是正值那么就 sleep
if t.sleepFor > 0 {
t.clock.Sleep(t.sleepFor)
t.last = now.Add(t.sleepFor)
t.sleepFor = 0
} else {
t.last = now
}
return t.last
}
上面的代码根据记录每次请求的间隔时间和上一次请求的时刻来计算当次请求需要阻塞的时间——sleepFor,这里需要留意的是sleepFor的值可能为负,在经过间隔时间长的两次访问之后会导致随后大量的请求被放行,所以代码中针对这个场景有专门的优化处理。创建限制器的New()函数中会为maxSlack设置初始值,也可以通过WithoutSlack这个Option取消这个默认值。
func New(rate int, opts ...Option) Limiter {
l := &limiter{
perRequest: time.Second / time.Duration(rate),
maxSlack: -10 * time.Second / time.Duration(rate),
}
for _, opt := range opts {
opt(l)
}
if l.clock == nil {
l.clock = clock.New()
}
return l
}
令牌桶限流之redis-cell
直接下载编译好的动态库so文件:https://github.com/brandur/redis-cell/releases
修改要使用的redis.conf文件,添加一行 “loadmodule /usr/local/redis/redis-stable/libredis_cell.so”,保存后,重启redis即可:

连接进redis,运行命令 module list ,可以查看目前已经启用的module

使用:

如上面简言所述,redis-cell使用很简单,只有一个命令:
命令格式:cl.throttle key名字 令牌桶容量-1 令牌产生个数 令牌产生时间 本次取走的令牌数 (不写时默认1,负值表放入令牌)
返回格式:0成功,1失败
令牌桶的容量
当前桶内剩余的令牌数
成功时该值为-1,失败时表还需要等待多少秒可以有足够的令牌
表预计多少秒后令牌桶会满
FAQ
1. k8s后的服务获取ip通常会获取到反向代理或node的ip。前端如何获取IP?
目前通过浏览器获取IP的方法主要有以下三种:
1、IE浏览器的ActiveX插件运行的情况下,可以利用ActiveObject获取。
2、利用第三方平台的接口返回,比如新浪、天平洋的接口。
3、利用WebRTC技术获取。
方案一:只支持IE,并且需要客户装ActiveX。
方案二:首先需要支持外网,其次第三方接口不在可控范围内,人家改了接口怎么办?
方案三:虽然大多主流浏览器已经支持了WebRTC,但是webRTC只能在https这种安全协议下才能使用。且不兼容IE浏览器。
综合考虑2,3可行:
利用第三方接口获取用户IP公网IP:
curl https://ipinfo.io/ip
效果基本和下图一样:
这个方法只会获取一个区域用户的网关路由器的IP,也就是公网IP。
内网IP的获取相对比较复杂,主要是需要依赖 webRTC 这么一个非常用的API:
WebRTC,名称源自网页即时通信(英语:Web Real-Time Communication)的缩写,是一个支持网页浏览器进行实时语音对话或视频对话的API。它于2011年6月1日开源并在Google、Mozilla、Opera支持下被纳入万维网联盟的W3C推荐标准。
webRTC 是HTML 5 的一个扩展,允许去获取当前客户端的IP地址,可以查看当前网址:net.ipcalf.com/
如果使用 chrome 浏览器打开,此时可能会看到一串类似于:
e87e041d-15e1-4662-adad-7a6601fca9fb.local
的机器码,这是因为chrome 默认是隐藏掉 内网IP地址的,可以通过修改 chrome 浏览器的配置更改此行为:
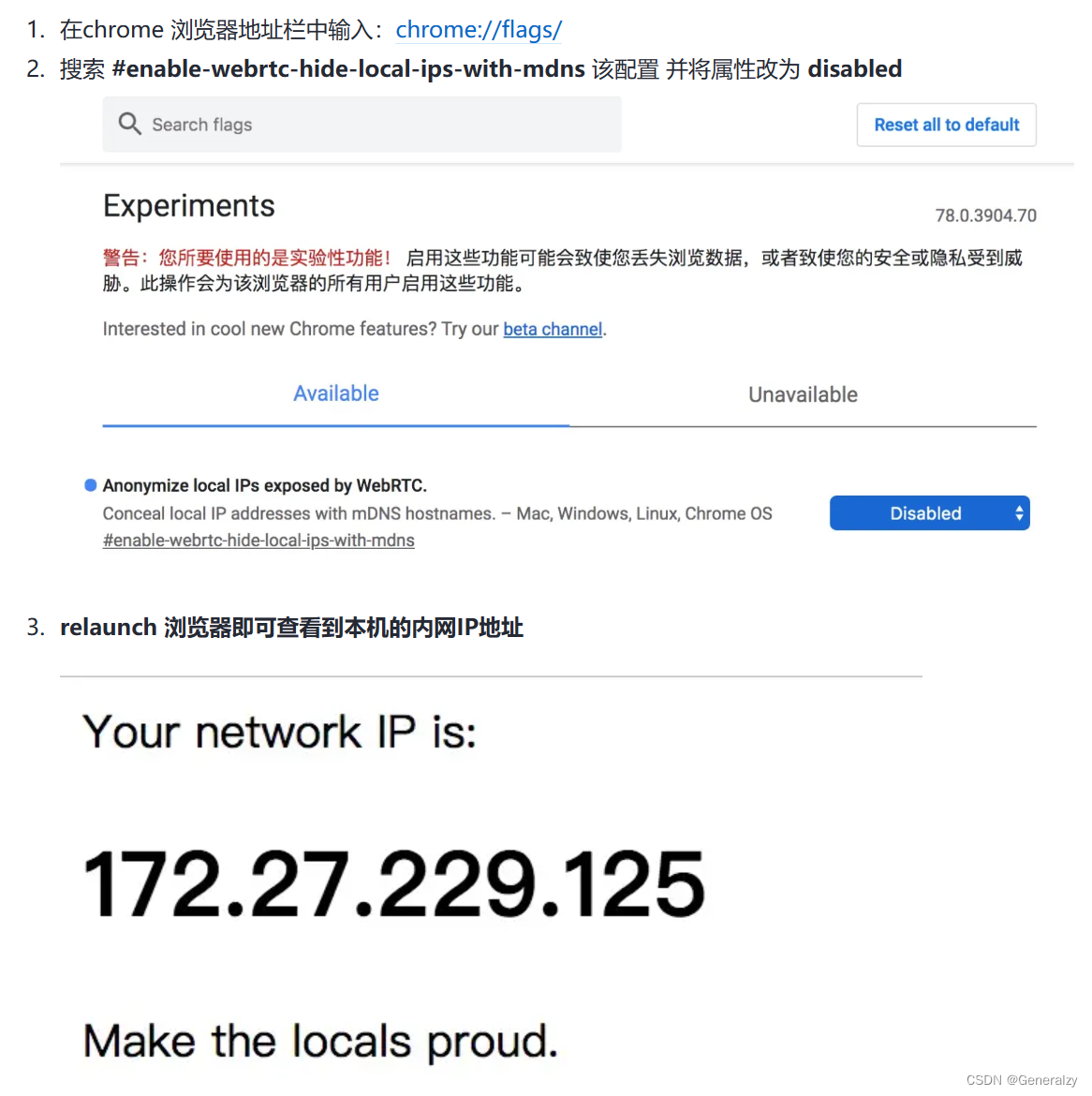
这里贴上代码:
<!DOCTYPE html>
<html>
<head>
<title>get Ip and MAC!</title>
<meta http-equiv=Content-Type content="text/html; charset=gb2312">
</head>
<body>
<script>
function findIP(onNewIP) {
let myPeerConnection = window.RTCPeerConnection || window.mozRTCPeerConnection || window.webkitRTCPeerConnection; // RTCPeerConnection是WebRTC用于构建点对点之间稳定、高效的流传输的组件。兼容火狐、谷歌等
let pc = new myPeerConnection({ // 创建点对点连接的RTCPeerConnection的实例
iceServers: [{"url": "stun:stun.l.google.com:19302"}]
}); // webRTC使用了ICE协议框架,包括STUN 和 TURN两个协议。我这里连接的是STUN协议服务器。STUN Server的作用是接受客户端的请求,并且把客户端的公网IP、Port封装到ICECandidate中。
let noop = function() {};
let localIPs = {}; // 记录有没有被调用到onNewIP这个listener上
let ipRegex = /([0-9]{1,3}(\.[0-9]{1,3}){3}|[a-f0-9]{1,4}(:[a-f0-9]{1,4}){7})/g;
let key;
function ipIterate(ip) {
if (!localIPs[ip]) onNewIP(ip);
localIPs[ip] = true;
}
pc.createDataChannel(""); // 创建数据信道
pc.createOffer().then(function(sdp) {
sdp.sdp.split('\n').forEach(function(line) {
if (line.indexOf('candidate') < 0) return;
line.match(ipRegex).forEach(ipIterate);
});
pc.setLocalDescription(sdp, noop, noop);
});
pc.onicecandidate = function(ice) { //listen for candidate events
if (!ice || !ice.candidate || !ice.candidate.candidate || !ice.candidate.candidate.match(ipRegex)) return;
ice.candidate.candidate.match(ipRegex).forEach(ipIterate);
};
}
let ul = document.createElement('ul');
ul.textContent = 'Your IPs are: '
document.body.appendChild(ul);
function addIP(ip) {
console.log('got ip: ', ip);
var li = document.createElement('li');
li.textContent = ip;
ul.appendChild(li);
}
findIP(addIP);
</script>
</body>
</html>
stun.l.google.com:19302 是一个STUN服务器的地址和端口。
STUN(Session Traversal Utilities for NAT)是一种用于在NAT(Network Address Translation)环境下找到公共IP地址的协议。在NAT环境下,局域网内的设备可能被分配了私有IP地址,这些地址不能直接被公共互联网访问到。
STUN服务器的作用是接收来自客户端的请求,并返回客户端的公共IP地址和端口信息,以便在网络通信中进行正确的路由。在WebRTC中,STUN服务器通常被用来获取本地网络环境的信息,以便建立点对点连接。
stun.l.google.com:19302 是Google提供的一个公共STUN服务器,它是免费可用的,用于WebRTC等应用程序。
参考文档
[1]. 编程宝库:漏桶/令牌桶限流算法 Go语言















 2532
2532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











