







1、简述
之前在写MFC程序的时候经常会用到CString 字符串类型,自从转到Qt就转为用QString了,自然QString比CString好用多了。最近需要将CString 与 char* 进行互转,在使用过程中遇到了一些问题,在此记录下来。
文章内容比较长,希望读者能够耐心看完,如果不看完我相信你一定会后悔的哦 O(∩_∩)O!
注意:
如果是在MFC工程中可以直接使用CString,而在给MFC工程中我们需要加上头文件(#include“afx.h”)。
2、代码之路
首先在讲解代码之前,我们先了解两种编码格式 ANSI 和 UNICODE。如果不了解这两种编码格式,在字符串转换(包括 CString 、char* 、 wchar_t等)中会出现一些问题。因为对于不同的编码格式,字符串之间相互转换的方法是不一样的。
ANSI
ANSI 在不同的操作系统下代表着不同的编码。在我们正常用的简体中文windows操作系统中,ANSI代表着GBK编码,而在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码。不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。
当然对于ANSI编码而言,0x00~0x7F之间的字符,依旧是1个字节代表1个字符。这一点是ANSI编码与Unicode编码之间最大也最明显的区别。为使计算机支持更多语言,通常使用 0x80~0xFF 范围的多个字节来表示 1 个字符。
UNICODE——宽字节字符集
UNICODE是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
我们先看下面的代码(补充:我的环境是VS2013)
char* 转 CString
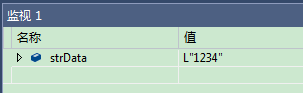
char* pData = "1234";
CString strData(pData);
// 直接赋值 CString strData = pData; / CString strData("1234");我们从图片中看出strData的值为 L”1234” , 这里有L说明当前项目编码是 UNICODE,下面我们将
编码改为 ANSI 。
关于VS中如何修改项目的编码
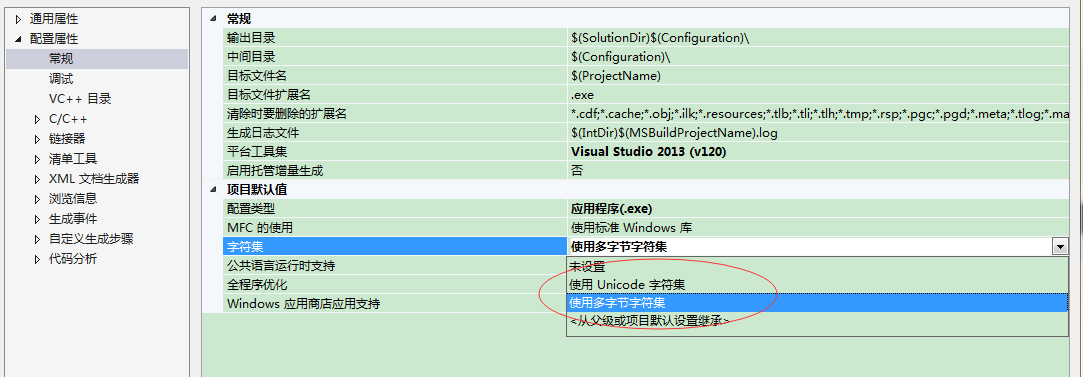
我们在VS中新建一个项目,然后右击项目,弹出菜单选择属性。进入到如下界面,在配置属性–>常规–>字符集,见下图,我们可以选择两种字符集。
- 使用 UNICODE 字符集
- 使用多字节字符集 (即 ANSI字符集 )
我们将字符集改为 “使用多字节字符集”,再看如下代码的结果。
见下图,我们发现strData的值为 “1234” , 而不是 L”1234” , 这就是因为我们修改了编码。
CString strData("1234");
那两种不同的编码对字符串的转换有什么影响呢?请继续往下看。
我们在上面通过直接赋值或者通过CString的构造将char* 的值 直接传递给CString,那么下面我们用另外一种方式就会看出两种编码产生的影响。
——我们将编码设置为 UNICODE
CString strData;
char* pData = "1234";
strData.Format(("%s"), pData ); // 编译提示无法将参数 1 从“const char [3]”转换为“const wchar_t *
//因为我们现在的编码为 UNICODE ,所以 我们不能直接使用("%s"),要进行如下修改
strData.Format(_T("%s"), pData ); // 编译正确
加上 _T 后编译正确了,我们看一下结果:

从上图中我们看到结果并不是我们所想的,因为 UNICODE 为宽字节编码,所以char作为单字节,所以这里结果会显示乱码。
看下面的写法:
CString strData;
wchar_t *data = _T("1234"); // 或者 wchar_t *data = L"1234"; (L 和 _T的区别见下文)
strData.Format(_T("%s"), data);注意:这里对wchar_t赋值必须加上 _T() 或者 L ,否则编译会提示 无法从“const char [5]”转换为“wchar_t *”,因为我们当前的编码为 UNICODE ,而 wchar_t 为宽字节类型。详情见下文。

我们看到图中显示结果正确。
——我们将编码设置为 ANSI
CString strData;
char* pData = "1234";
strData.Format("%s", pData );
这次我们没有加 _T ,编译没报错,结果也显示正确,所以编码的不同,对程序编译或者运行结果都有一定的影响,我在网上查找资料的过程中发现有一部分人用了上面的方法,自己便试了,刚开始编译报错,修改为 strData.Format(_T(“%s”), pData );后 ,解决了编译保存,却结果显示错误,难道是C++的库更新了吗,还是编译环境的问题,想了半天愣是没想明白,后来才知道是编码的问题。
我们再看看下面的问题:
wchar_t *data = _T("1234"); // 现在的编码为 ANSI ,编译后报错,提示无法从“const char [5]”转换为“wchar_t *”这是为什么呢?我明明加了_T,现在怎么提示错误了,好,既然加上错误,那我去掉试试,结果发现还是一样的错误。我们用下面的代码试试。
wchar_t *data = L"1234"; // 编译正确,结果见下图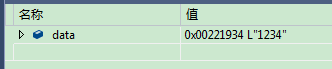
为什么不同编码,我加上 _T 结果却不一样呢,那我们就来看看 _T 和 L
在tchar.h文件中我们可以看到对宏 _T的定义;
#define _T(x) __T(x)
#define _TEXT(x) __T(x)
#define __T(x) L ## x //编码为 UNICODE
#define __T(x) x //编码为 ANSI这里我们可以看到 _T 和 _TEXT 有着一样的定义。而 _T 的作用就是根据当前的编码对字符串进行不同的转换。
如果你的程序为 ANSI编码,_T 实际上不起任何作用。
即为 #define __T(x) x
如果你的程序为 UNICODE编码,_T 相当于 L。
即为 #define __T(x) L ## x
——用代码来说明这两种编码的区别
ANSI编码情况下:
CString str = _T(“12345”); 相当于 CString str = “12345”;
UNICODE编码情况下:
CString str = _T(“12345”); 相当于 CString str = L”12345”;
在程序编译时就已经完成了宏替换。
L表示Unicode编码,L 不管你是以什么方式编译,一律以UNICODE方式保存。
_T可以是UNICODE,也可以是ANSI,这要看编译设置。_T会根据你工程的编码设置自动转换UNICODE和非UNICODE,而L就是转为UNICODE编码方式。
我们看一下wchar_t的定义
typedef wchar_t WCHAR; 并在winnt.h头文件中给出了如下注释
16-bit UNICODE character——16位的UNICODE 编码字符。(在不同系统中或者不同的C或C++库有不同的规定,wchar数据类型一般为16位或32位。)
wchar_t类型介绍
我们知道char类型变量可以存储一个字节的字符,它用来保存英文字符和标点符号是可以的,但是对于汉字、韩文以及日文这样的字符却不可以,因为汉字、韩文以及日文每一个文字都占据两个字节,为了解决这个问题,c++提出了wchar_t类型,称之为双字节类型,又称宽字符类型。
WCHAR //Unicode字符
PWSTR //指向Unicode字符串的指针
PCWSTR //指向一个恒定的Unicode字符串的指针
对应的ANSI数据类型为:CHAR,LPSTR和LPCSTR。
ANSI/Unicode通用数据类型为:TCHAR,PTSTR,LPCTSTR。因为C++支持两种字符串,即常规的ANSI编码(使用”“包裹)和Unicode编码(使用L”“包裹),这样对应的就有了两套字符串处理函数,比如:strlen和wcslen,分别用于处理两种字符串。
微软将这两套字符集及其操作进行了统一,通过条件编译(通过_UNICODE和UNICODE宏)控制实际使用的字符集,这样就有了_T(“”)这样的字符串,对应的就有了_tcslen这样的函数。我们在上面中也看到对于不同的编码_T会转成不同的格式。
为了存储这样的通用字符,就有了TCHAR:
TCHAR 的定义:
1、在UNICODE编码中:
typedef wchar_t TCHAR;
_tcslen = wcslen2、在ANSI编码中:
typedef char TCHAR;
_tcslen =strlen
看一下TCHAR 的定义,再上代码来解释。
// 在UNICODE编码中:
TCHAR tchar;
wchar_t wc;
int size = sizeof(wc); //值为2,表示wchar_t 为宽字符类型
size = sizeof(tchar); //值为2,说明这里使用了UNICODE编码,TCHAR表示wchar_t
// 在ANSI编码中:
TCHAR tchar;
wchar_t wc;
int size = sizeof(wc); //值为2,表示wchar_t 为宽字符类型
size = sizeof(tchar); //值为1,说明这里使用了ANSI编码,TCHAR表示char
有了以上知识的基础,我们再来看看下面这个问题
// 编码设置为 ANSI
CString strData;
wchar_t *data = L"1234"; // 这里我们用 L ,用 _T 编译错误,因为编码为ANSI,_T不起作用
strData.Format(_T("%s"), data); // ANSI编码,这里相当于strData.Format("%s", data);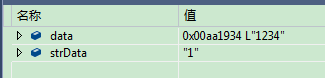
从上面的结果中我们看出strData的值为 “1” ,这是为什么呢?
仔细想了想,因为wchar_t 是双字节类型,相当于data [0]中保存了“1\0”,data [1]中保存了“2\0”,后面以此类推,而当前编码为ANSI,所以遇到1后面的\0就结束了。
实际上我们可以根据Format函数的第一个参数,因为在不同编码环境下这个参数的类型也不一致,而这个参数的类型由 TCHAR 的定义而定,在ANSI编码中 为char,在 UNICODE编码中 为 wchar_t。
这也是为什么在 ANSI编码中Format的第二个参数为 wchar_t* 导致CString只显示一个字符。
同时也证明了上面文章中,在 UNICODE 编码中Format的第二个参数为char* 导致 CString 显示乱码的问题。
综上所述
在 UNICODE 编码中
使用 CString.Format(_T(“%s”) , wchar_t*) ; 或者 CString.Format(L”%s”, wchar_t*) ;
在 ANSI 编码中
使用 CString.Format(_T(“%s”) , char*) ;或者CString.Format(“%s” , char*)
另外一点需要注意的是,如果在CString 初始化时 直接赋值则使用char* 或者 wchar_t* 都可以
char* pData = "1234";
wchar_t* wData = L"1234";
CString strData(pData ); / CString strData(wData);
或者
CString strData = pData; / CString strData = wData;在 UNICODE 编码中 strData 值为 L“1234”
在 ANSI 编码中 strData 值为“1234”
就编码问题就暂时介绍到这里,下面我们再看看看如何将CStirng转char* 。
CStirng转char*
关于char* 转 CString问题实在是一个头疼的问题,在网上找了很多资料,下面简单介绍一下。
以下 在 ANSI 编码中可以使用 ,在UNICODE编码中无法使用
// 第一种
CString str1 ="123";
char *p =(LPSTR)(LPCSTR)str1;
// 第二种
使用 GetBuffer方法返回 char * 类型
CString str1 ="123";
char *t1 =str1.GetBuffer(str1.GetLength());
str1.ReleaseBuffer();
在 UNICODE编码中
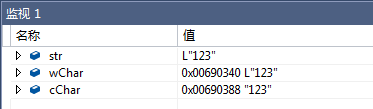
使用 GetBuffer方法返回 wchar_t * 类型,再将得到的wchar* 类型转为 char*类型
CString str = "123";
wchar_t *wChar = str.GetBuffer(str.GetLength());
str.ReleaseBuffer();
// 将得到的wchar* 类型转为 char*类型
size_t len = wcslen(wChar) + 1;
size_t converted = 0;
char *cChar;
cChar = (char*)malloc(len*sizeof(char));
wcstombs_s(&converted, cChar, len, wChar, _TRUNCATE);
结果:
下面是我自己写的方法实现在 UNICODE编码 中 将 CStirng转char* ,但是存在一定的限制,就是CString中的字符串只能为数字或者字符,即在ascii码范围内,不能使用中文或者其他字符。
CString strData = "123456ab?!@c";
char cData[1024];
char *pBuff = (char*)strData.GetBuffer(strData.GetLength());
char one = pBuff[0];
char two = pBuff[1];
int i = 0;
for (; i < strData.GetLength(); i++)
{
cData[i] = pBuff[i * 2];
}
cData[i] = '\0';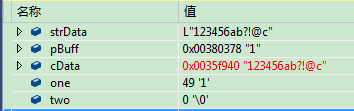
通过GetBuffer方法返回wchar_t* 类型,而现在我们直接用char* 接收,从上图中可以看出,pBuff 的值为“1”, char 型字符 one 的值为 “1”,char型字符 two的值为“\0”,这也证实了上面文章中的论述。故pBuff值为“1”。
网上也有其他方法:
UniCode 下 CString 转 char* 的方法
尾
在最近的工作中,遇到了CString 转 char*的问题,然后上网找了一大堆资料,发现都是在 ANSI 编码中的CString 转 char*的方法,因为项目工程为UNICODE编码,用了网上的方法根本行不通,然后自己就写了一个转化的方法,同时自己也喜欢探讨记录,就将这些知识整理了一下,整理的过程中也发现了很多问题,通过对这些问题的解决,对字符串的转换有了一个新的认识,虽然花了很长的时间去查阅资料、验证代码、整理文章,但是收获颇丰。代码虽然简单,但是都是干货,相信认真看完的读者,也有一个不小的收获。
如果文章中叙述存在问题,欢迎小伙伴们一起交流。O(∩_∩)O!
更多资料:
http://blog.sina.com.cn/s/blog_6da8fb890100r3az.html
http://blog.csdn.net/zyw_anquan/article/details/8556418
http://blog.sina.com.cn/s/blog_51396f890102f11s.html
http://blog.csdn.net/youoran/article/details/8299731
http://blog.sina.com.cn/s/blog_6da8fb890100r3az.html

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









