







学习大数据之路,必不可少的Hadoop、Hive、HBase、Spark,现在前三个在本博客已经有专栏讲解学习。
对初学者来说,如果学习大数据Bug有一石,安装过程则独占八斗。最繁琐的就是全分布式的安装过程,我们已经在Hadoop、Hive、HBase中已经领略过了。这次Spark我们不妨先在Windows下搭建一个Spark的单机环境,可以让我们直接编程见识一下Spark的魅力。
目前Spark官方提供的最新版本3.2.0,是2021年10月份发布,但是该版本搭建Windows下环境,在使用spark-shell时,会报以下错误,尚无解决方案。全网搜索只有Stack Overflow上有个法国马赛的人在3天前咨询同样报错内容,尚无任何响应。


退而求其次,使用Spark3.1.2,则完全正常。经过验证,Spark3.2.0只有在搭建Windows10 Shell版会有问题,后续使用IDEA Maven方式不会有问题,所以本Spark系列教程,会在Windows10 shell(即前两篇中使用Spark3.1.2,后续使用Spark3.2.0。
本次Win10 Spark Shell搭建环境,所使用到的系统为Windows10,JDK1.8,Hadoop3.3.1,Scala2.12(注意,spark3.1.2不支持Scala2.13),Spark为3.1.2
注意过程中,所解压的文件不要放在有空格的文件夹中,CMD使用管理员身份打开。
一、在Windows上搭建Hadoop,请参考:
Windows上搭建Hadoop
成功后,在CMD中输入
hadoop version
会显示:

二、安装Sacla,官网下载,解压到某盘符下文件中,配置环境变量:
注意,本系列后续的Spark已自带Scala,而且将会使用Maven引入Scala的形式开发项目,其实可以不用安装Scala。如果想要使用Scala交互式界面进行Scala学习可以进行本步骤的Scala安装。
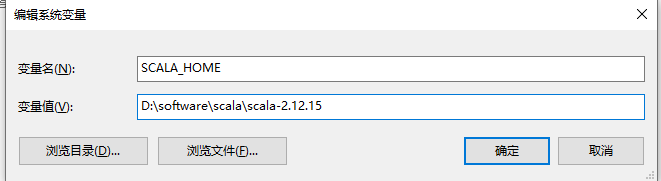
在PATH中,添加
%SCALA_HOME%\bin
在CMD中测试:
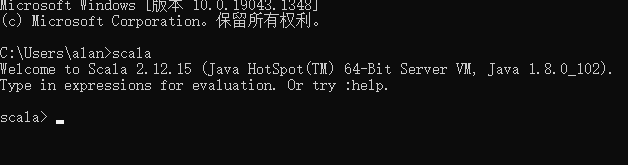
三、官网下载Spark,本次下载使用的是:
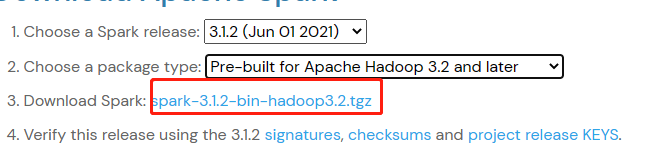
下载后解压到某盘符下文件夹内,并配置环境变量:

并在PATH中添加:
%SPARK_HOME%\bin
在CMD中测试,输入:
spark-shell
可以看到如下画面:

至此,Windows10下搭建Spark3完成。















 1463
1463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









