







【机器学习技术】高斯过程初探

概述
高斯过程是基于统计学习理论和贝叶斯理论发展起来的一种机器学习方法,适于处理高维度、小样本和非线性等复杂回归问题,且泛化能力强,与神经网络、支持向量机相比,GP具有容易实现、超参数自适应获取、非参数推断灵活以及输出具有概率意义等优点。
在统计学和机器学习两个领域中,一些基本理论和算法是共享通用的,但统计学的一个基本关注点在于对数据和模型关系之间的理解,而机器学习的目标主要是用于更准确的预测和对学习算法行为的理解上。机器学习是一种黑盒算法,而统计学更希望得到模型的理论解释。高斯过程模型在某种层面将统计学和机器学习联系到了一起,我们将看到,高斯过程在数学上等价于很多有名的模型,包括贝叶斯线性模型、样条模型、合适条件下的神经网络,并且其也与支持向量机有密切的联系。
随机过程基本概念
随机过程是一个比随机变量更广泛的概念。在概率论中,通常研究一个或多个这样有限个数的随机变量,即使在大数定律和中心极限定理中考虑了无穷多个随机变量,但也要假设随机变量之间互相独立。而随机过程主要是研究无穷多个互相不独立的、有一定相关关系的随机变量。随机过程就是许多随机变量的集合,代表了某个随机系统随着某个指示向量的变化(把指示向量的时间看成轴),这个指示向量常用的是时间向量。
高斯过程
随机过程可以用一个随机变量簇{X(t,w), t∈T}来表示,而高斯过程区别于其他随机过程的地方(也是一种随机过程)就在于从这个随机变量簇中任意抽取有限个指标(如n个,t1,…tn)所得到的变量构成的向量(X_t1,..., T_tn)的联合分布为多维高斯分布。在一个高斯过程中,输入空间的每一个点都关联了一个服从高斯分布的随机变量,而任意有限个这些随机变量的组合的联合概率也服从高斯分布。当指示向量t是二维或多维时,高斯过程就变成了高斯随机场GRF。对高斯过程的刻画,如同高斯分布一样,也是用均值和方差来刻画。通常在应用高斯过程f~GP(m,K)的方法中,都是假设均值m为零,而协方差函数K则是根据具体应用而定。
线性回归模型和高斯过程模型的关系
在贝叶斯线性回归模型y(x,w) = wT·φ(x)中,先给定w的先验分布p(w)=N(w|0, α^(-1)I),然后得到y(x,w)的对应的先验分布。给定训练数据集,计算w上的后验概率分布,从而得到和回归函数对应的参数的后验概率分布。
得到模型的向量形式是y=Φ·w,这个式子说明y=(y1,...,yn)相当于是高斯变量w的线性组合,因此y也服从高斯分布,进而得到y的期望和方差:E[y]=Φ·E[w]=0,cov[y]=E[y·yT]=Φ·E[w·wT]ΦT=Φ·ΦT/α=K。
所以,线性回归可以看做是高斯过程的一个特殊例子,这里的高斯过程体现在函数y(x)上,对任意给定的n个样本构成的(y1,...,yn)的联合分布都是高斯分布,因此可以认为y(x)就是服从高斯过程分布的。
高斯过程回归
在高斯过程的观点中,抛弃参数模型,直接定义函数上的先验概率分布。乍一看来,在函数组成的不可数的无穷空间中对概率分布进行计算似乎很困难。但是,正如我们将看到的那样,对于一个有限的训练数据集,我们只需要考虑训练数据集合测试数据集的输入xn处的函数值即可,因此在实际应用中我们可以在有限空间中进行计算。
在高斯过程回归中,不用指定f(x)的具体形式,n个训练数据的观测值(y1,…,yn)被认为是从某个多维(n维)的高斯分布中采样出来的一个点(n维),而类似的f(x)也可以认为是从高斯过程中采样得到的一个无穷维的点。
高斯过程回归建模阶段的推导:
给定训练数据x1,...,xn,其对应的函数值是y1,...yn。
假设对观测t建模为某个目标函数y(x),加上高斯噪声:
<a href="http://private.codecogs.com/eqnedit.php?latex=t=y(x)+N(0,{\beta}^{-1})" target="_blank">
t=y(x)+N(0,{\beta}^{-1})</a>
于是目标变量t的联合概率分布为:
<a href="http://private.codecogs.com/eqnedit.php?latex=p(\mathbf{t}|\mathbf{y})=N(\mathbf{t}|\mathbf{y},\beta^{-1}\mathbf{I}_N)" target="_blank">
p(\mathbf{t}|\mathbf{y})=N(\mathbf{t}|\mathbf{y},\beta^{-1}\mathbf{I}_N)</a>
根据高斯过程的定义,p(y)的边缘分布如下,其中协方差由K矩阵定义:
<a href="http://private.codecogs.com/eqnedit.php?latex=p(\mathbf{y})=N(\mathbf{y}|\mathbf{0},\mathbf{K})" target="_blank">
p(\mathbf{y})=N(\mathbf{y}|\mathbf{0},\mathbf{K})</a>
得到p(t)的边缘分布为:
<a href="http://private.codecogs.com/eqnedit.php?latex=p(\mathbf{t})=\int&space;p(\mathbf{t}|\mathbf{y})p(\mathbf{y})d\mathbf{y}=N(\mathbf{t}|\mathbf{0},\mathbf{C})" target="_blank">
p(\mathbf{t})=\int p(\mathbf{t}|\mathbf{y})p(\mathbf{y})d\mathbf{y}=N(\mathbf{t}|\mathbf{0},\mathbf{C})</a>
其中协方差矩阵C的元素为:
<a href="http://private.codecogs.com/eqnedit.php?latex=C(x_n,x_m)=k(x_n,x_m)+\beta^{-1}\delta_{nm}" target="_blank">
C(x_n,x_m)=k(x_n,x_m)+\beta^{-1}\delta_{nm}</a>
高斯过程回归预测阶段的推导:
预测的任务就是给定新的输入x*,得到预测变量t*的分布。
首先我们得到t_(N+1)={t1,...,tn,t*}的联合分布:
<a href="http://private.codecogs.com/eqnedit.php?latex=p(\mathbf{t}_{N+1})=N(\mathbf{t}_{N+1}|\mathbf{0},\mathbf{C}_{N+1})" target="_blank">
p(\mathbf{t} {N+1})=N(\mathbf{t}{N+1}|\mathbf{0},\mathbf{C}_{N+1})</a>
其协方差矩阵是:
<a href="http://private.codecogs.com/eqnedit.php?latex=\mathbf{C}_{N+1}=\begin{pmatrix}&space;\mathbf{C}_N&space;&&space;\mathbf{k}\\&space;\mathbf{k}^T&space;&&space;c&space;\end{pmatrix}" target="_blank">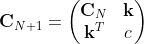
\mathbf{C}_{N+1}=\begin{pmatrix} \mathbf{C}_N & \mathbf{k}\ \mathbf{k}^T & c \end{pmatrix}</a>
根据多维高斯分布的条件分布公式,可以得到p(t*|t):
<a href="http://private.codecogs.com/eqnedit.php?latex=p(t^*|\mathbf{t})=N(\mathbf{k^TC_N^{-1}t},c-\mathbf{k^TC_N^{-1}k})" target="_blank">
p(t^*|\mathbf{t})=N(\mathbf{k^TC_N^{-1}t},c-\mathbf{k^TC_N^{-1}k})</a>
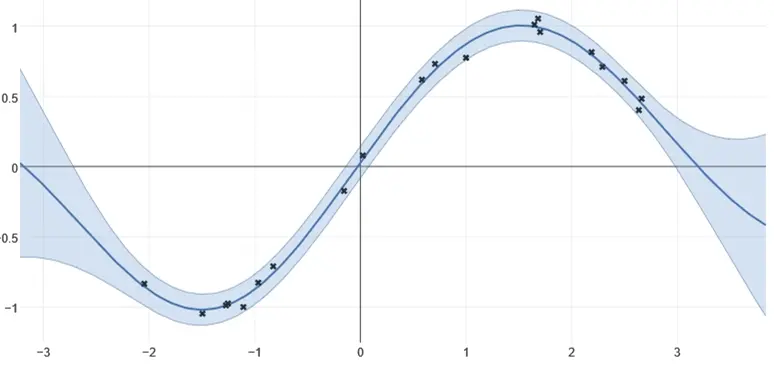
于是我们就用该分布的均值来作为估计值。
参考资料
- 说说高斯过程回归
- 高斯过程参考资料网站
- 高斯过程回归方法综述,何志昆、刘光斌、赵曦晶、王明昊,第二炮兵工程大学 控制工程系
转载请注明作者Jason Ding及其出处
Github博客主页(http://jasonding1354.github.io/)
GitCafe博客主页(http://jasonding1354.gitcafe.io/)
CSDN博客(http://blog.csdn.net/jasonding1354)
简书主页(http://www.jianshu.com/users/2bd9b48f6ea8/latest_articles)
Google搜索jasonding1354进入我的博客主页

















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









