









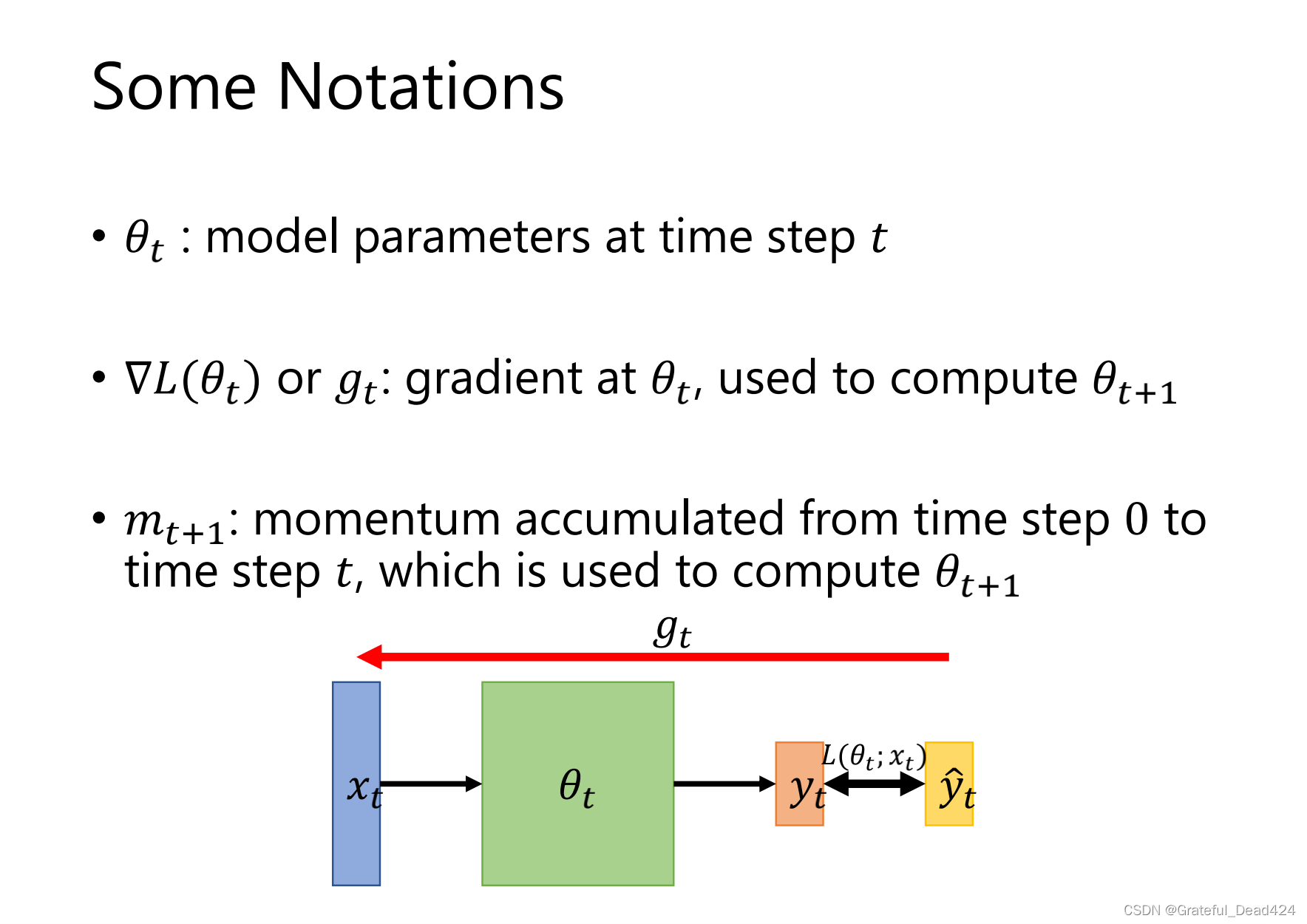
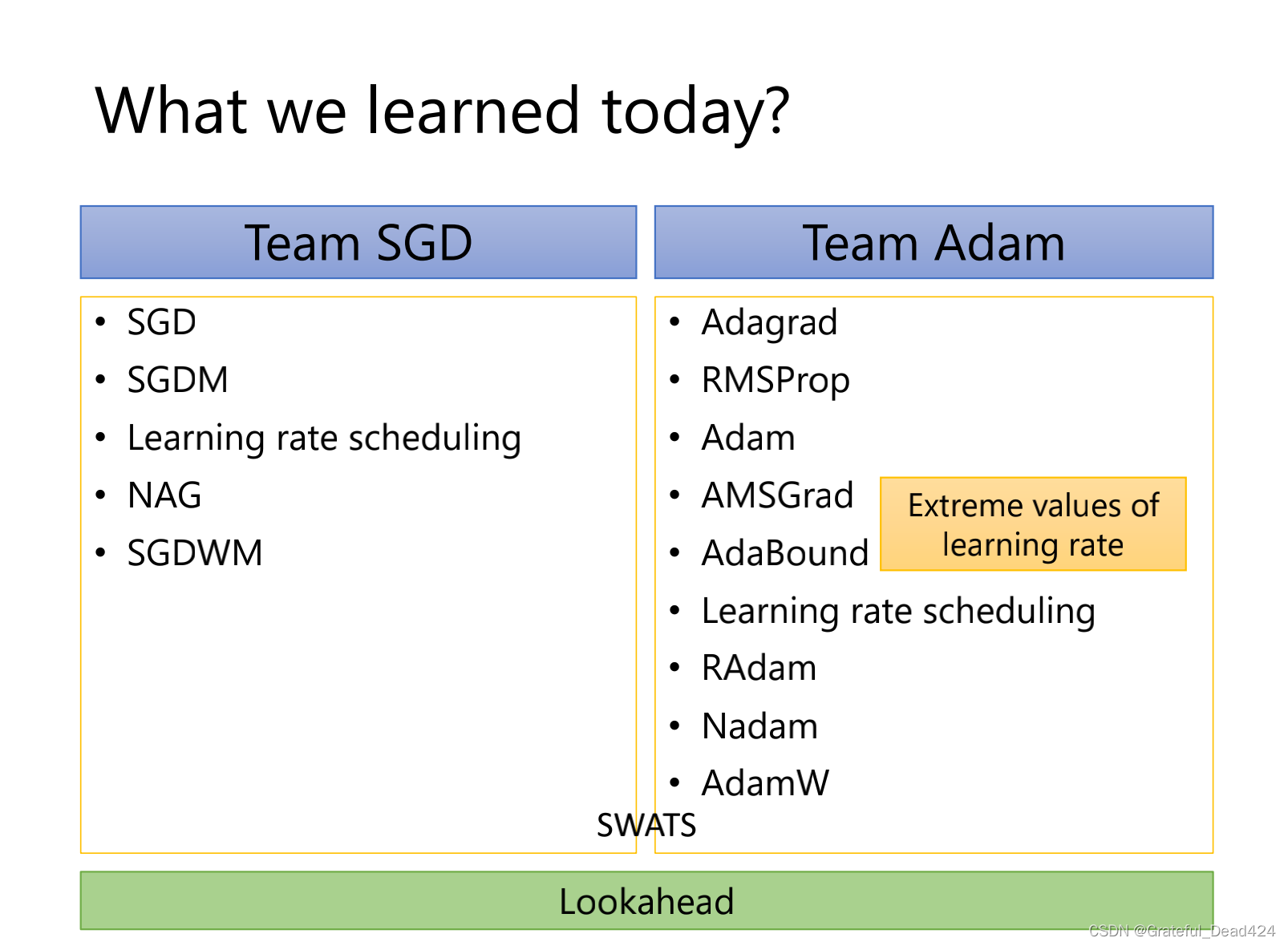
记录了关于梯度的历史
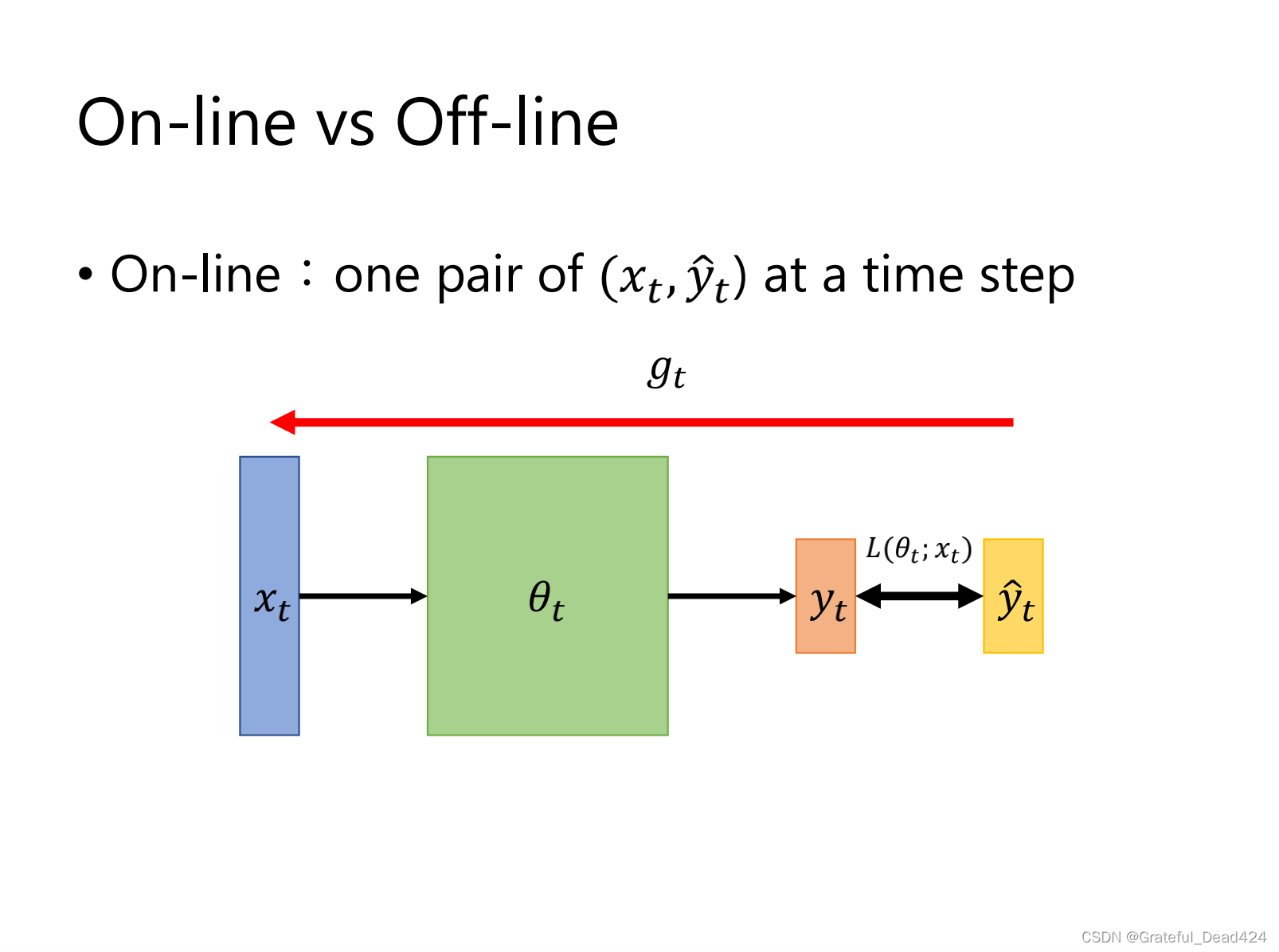
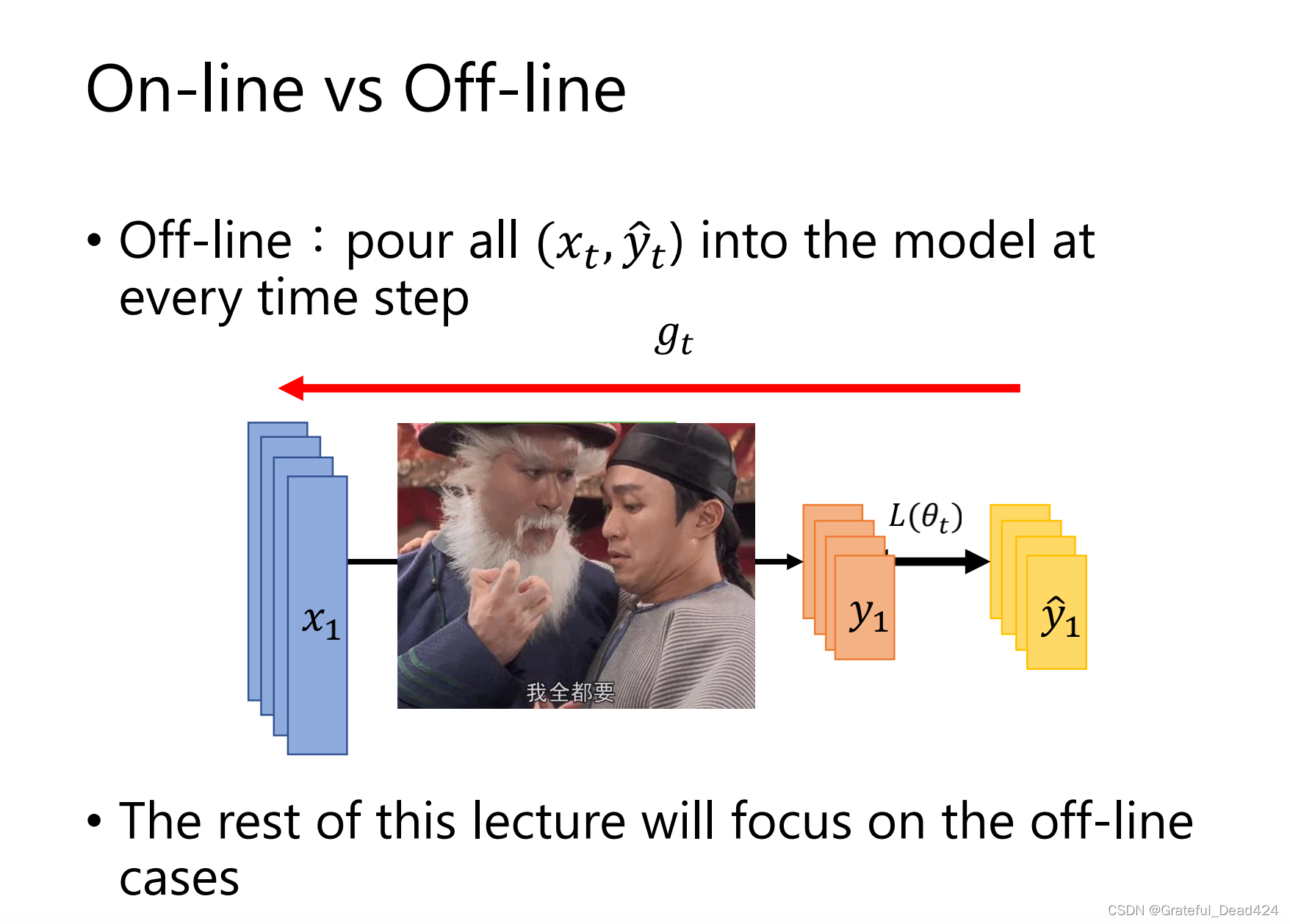
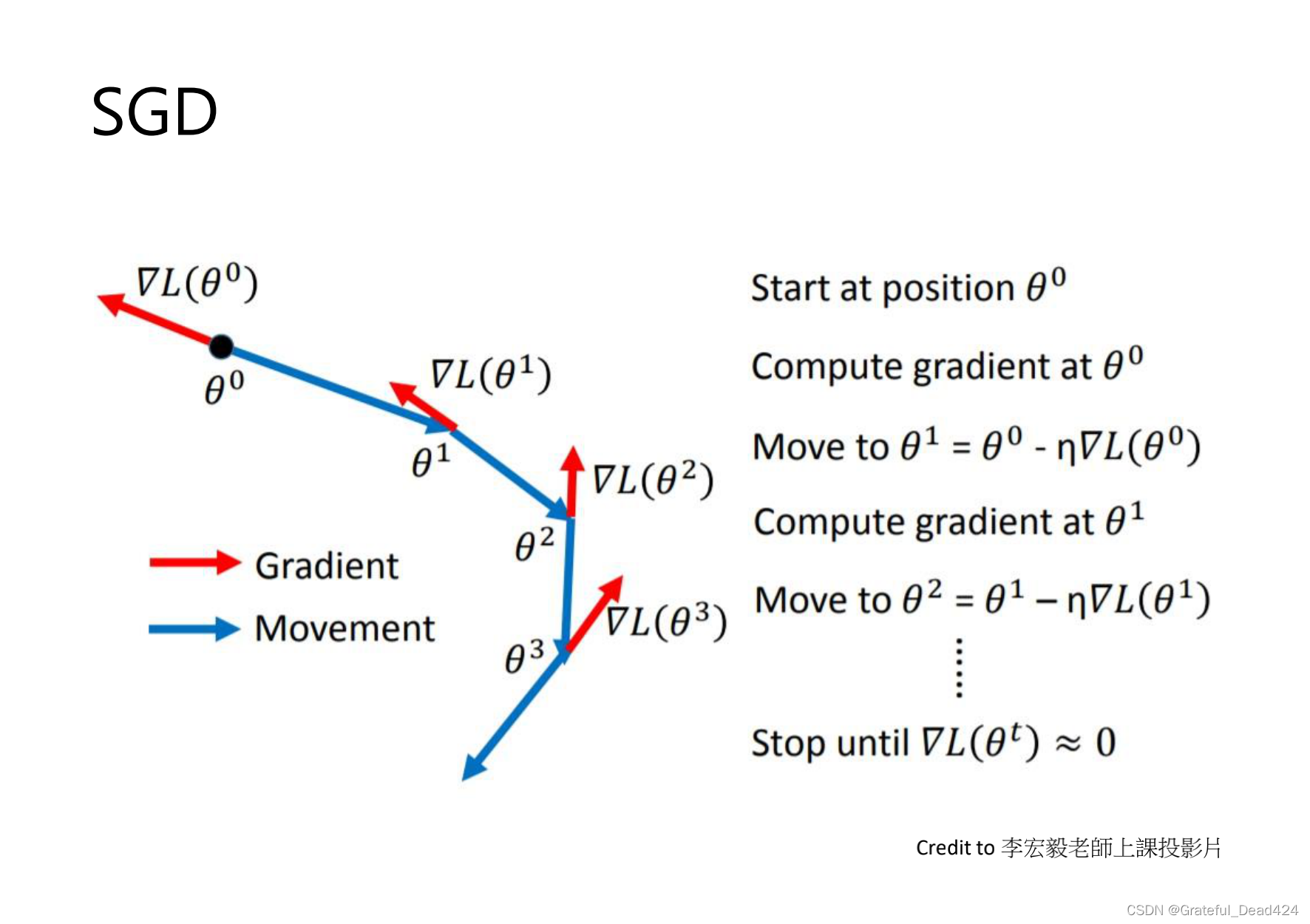
SGD
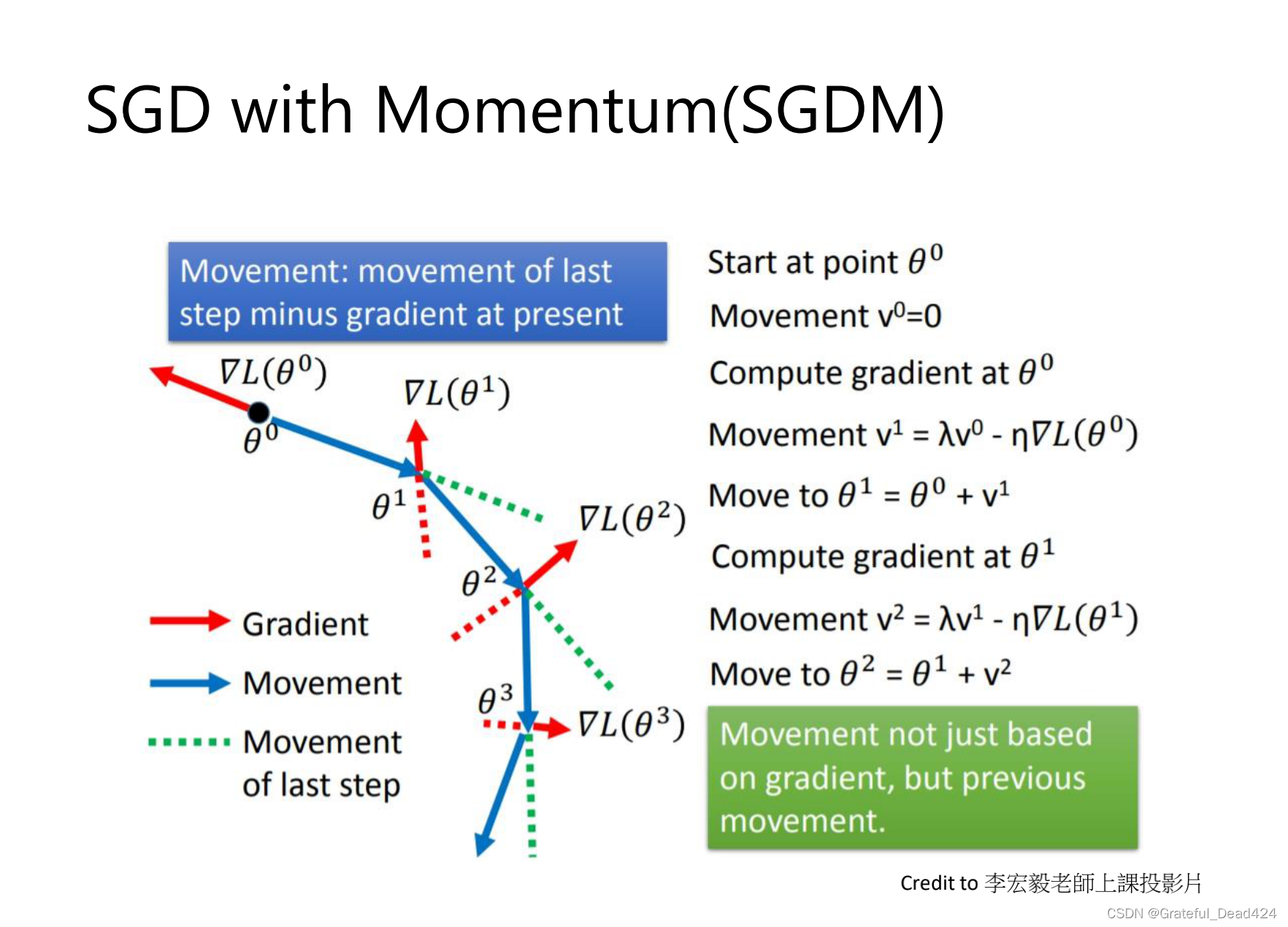
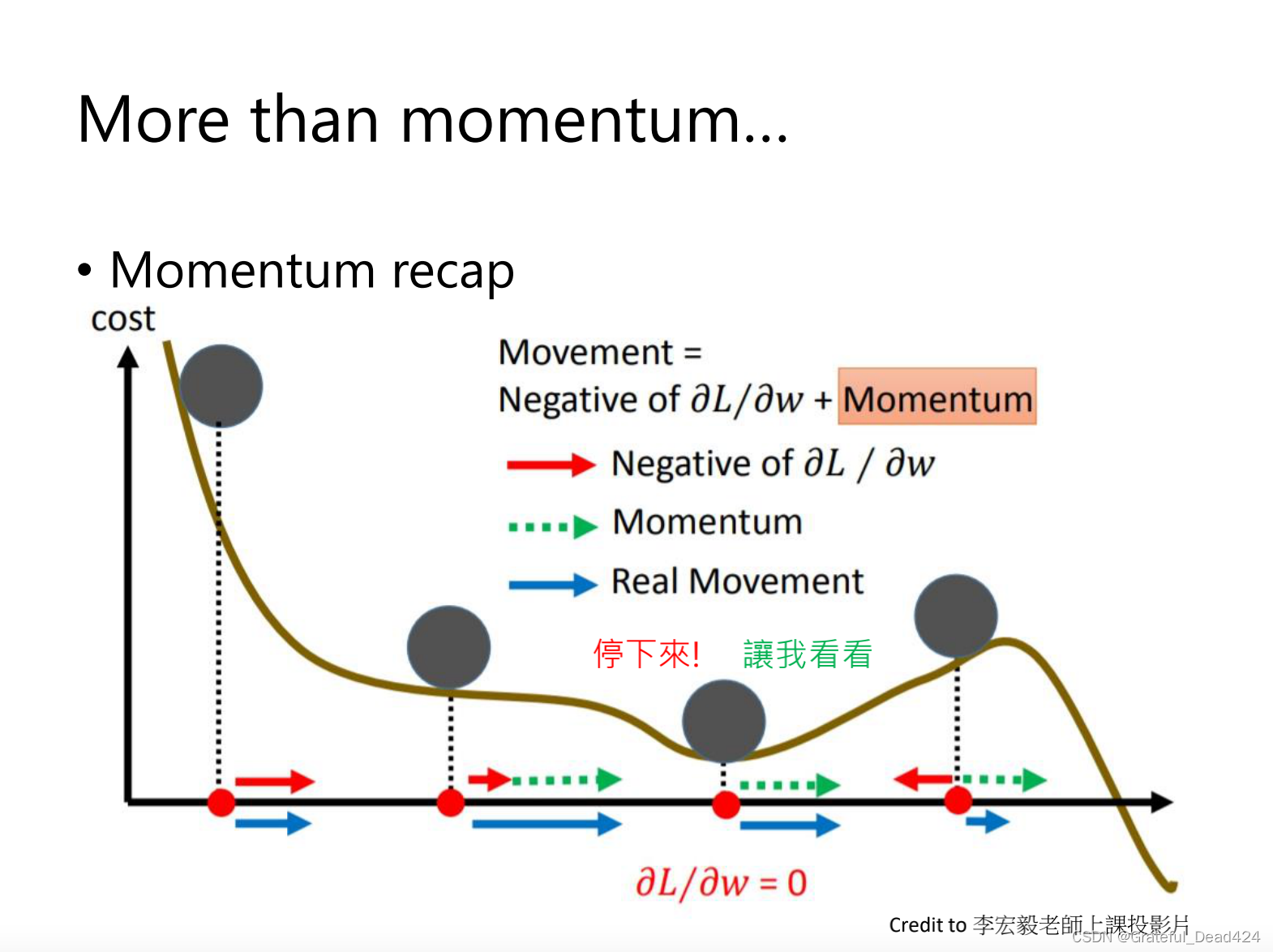
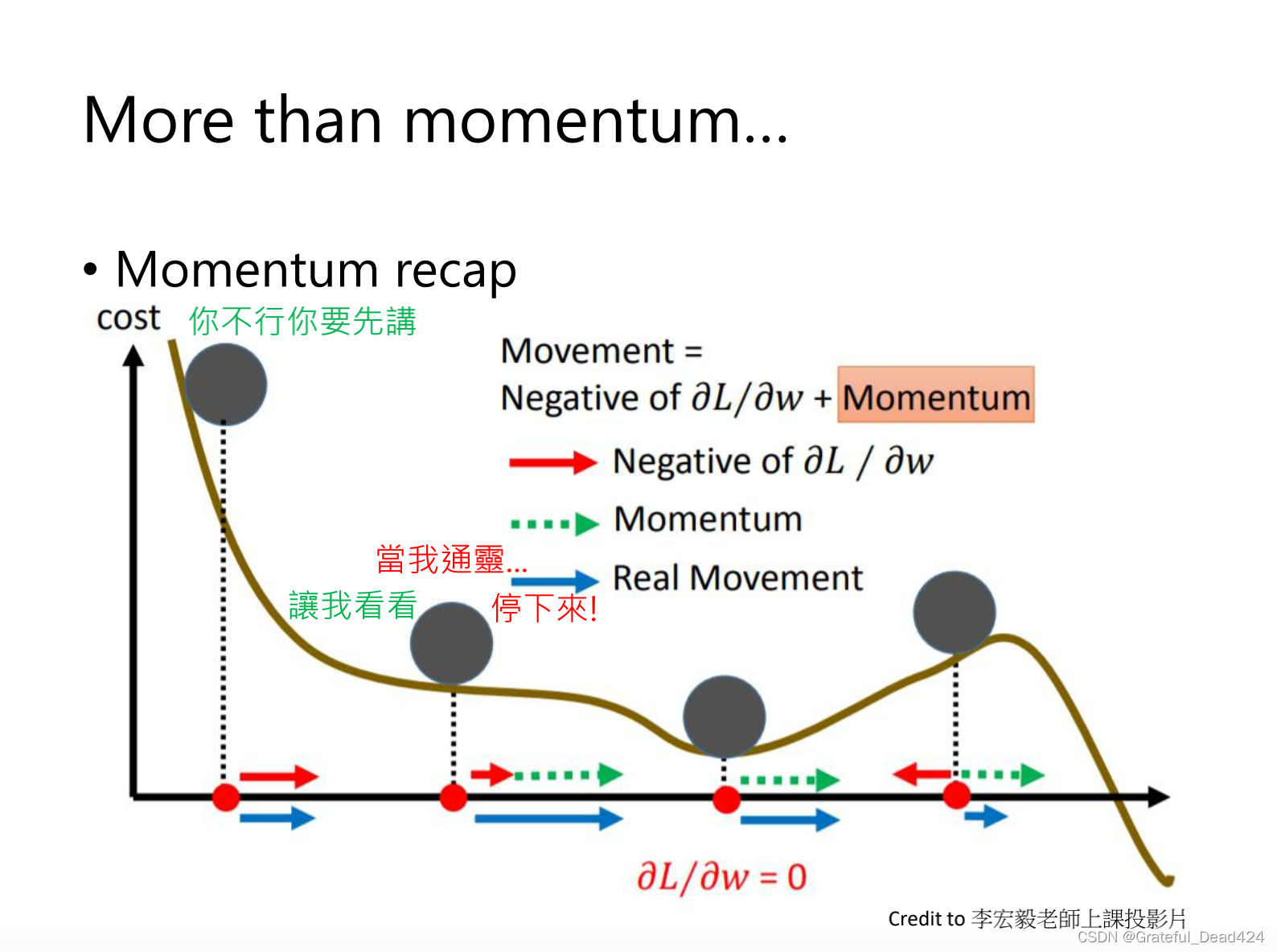
SGD with Momentum
防止gradient为0,SGD停止不动了
sgd with momentum,前面的移动会累加到下一步

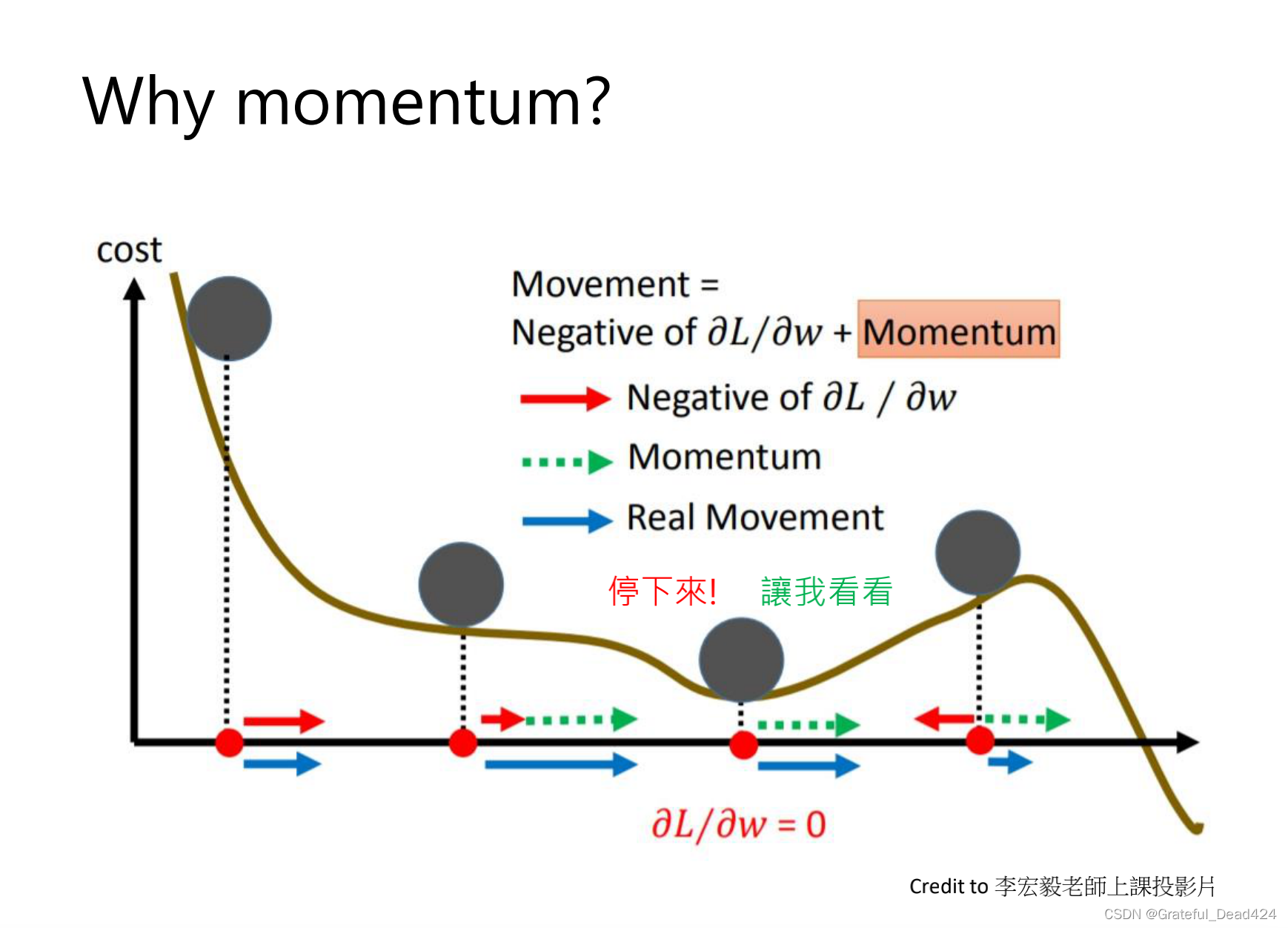
sgd with momentum,前面的移动会累加到下一步,所以小球不会卡在局部的一个最优的位置
Adagrad
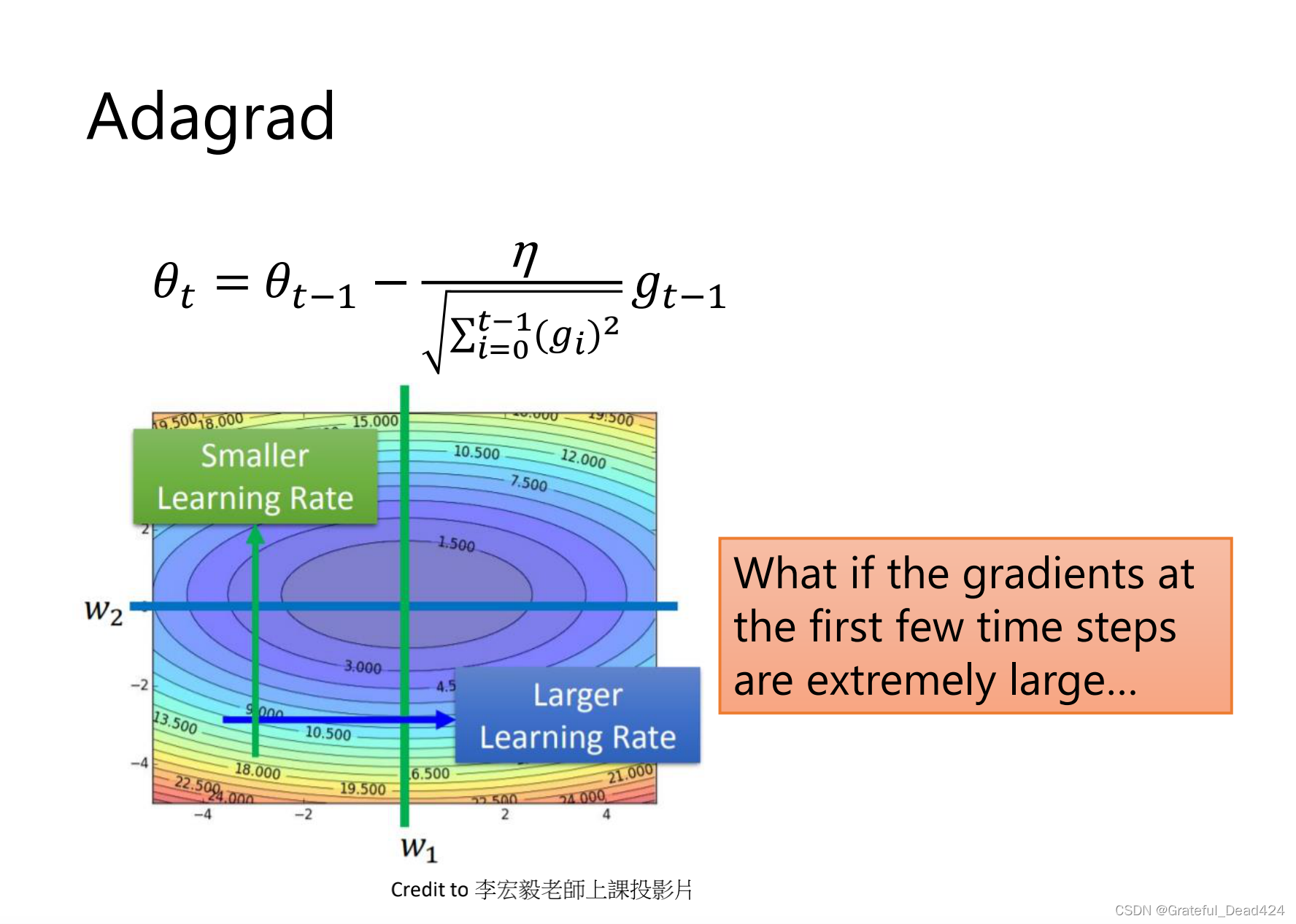 前几个time step如果坡度很大,就会暴走,走到不好的位置上,有个分母就会走小步一点
前几个time step如果坡度很大,就会暴走,走到不好的位置上,有个分母就会走小步一点
RMSProp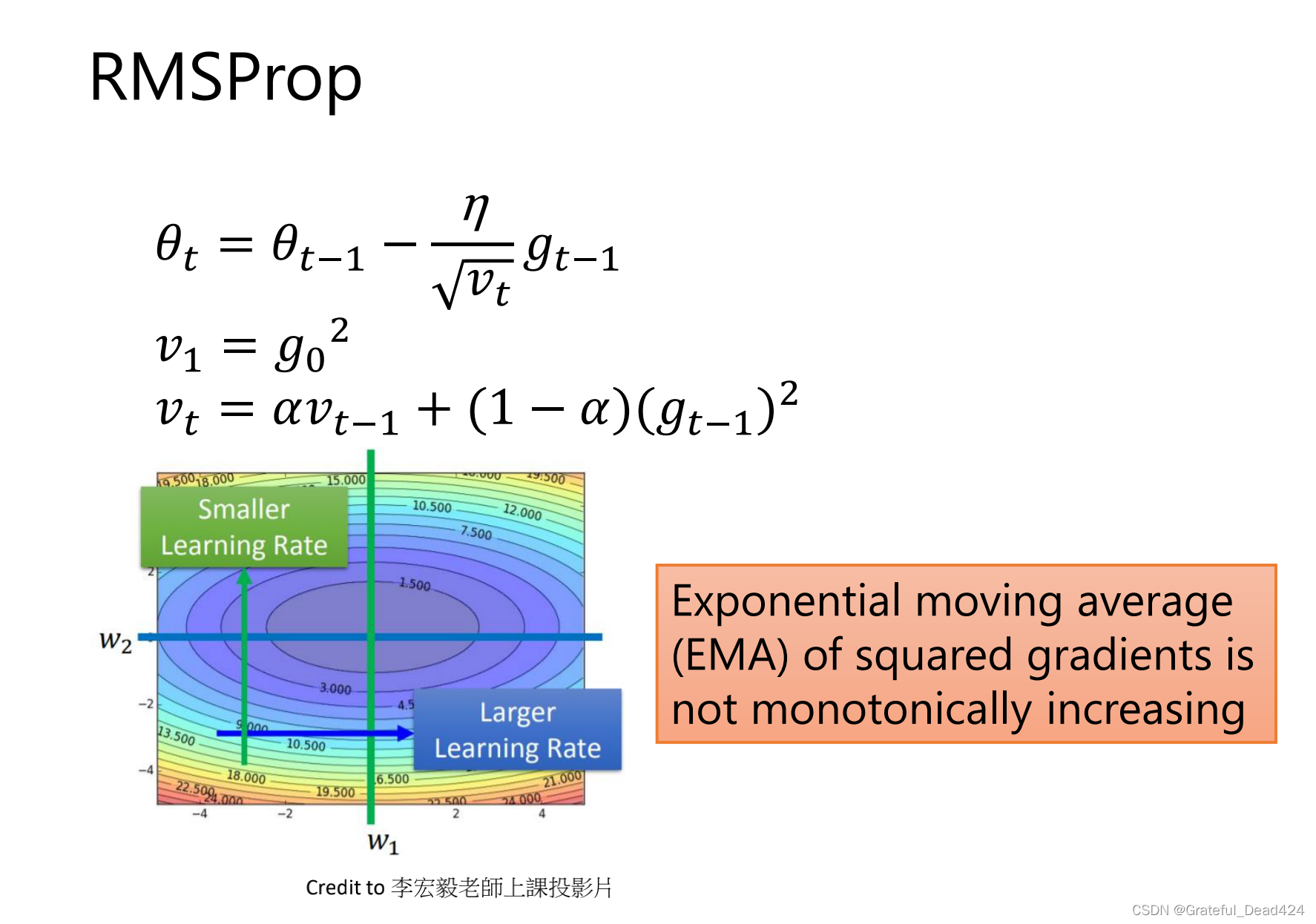
怕使用adagrad时,一开始的坡度很大,那么步幅就会很小,走没几步就停了
RMSProp保证分母不会无止境变大
Adam

一开始,帽等式右边分母小于1,保证
帽一开始不为0,且不会随时间变化变得太大



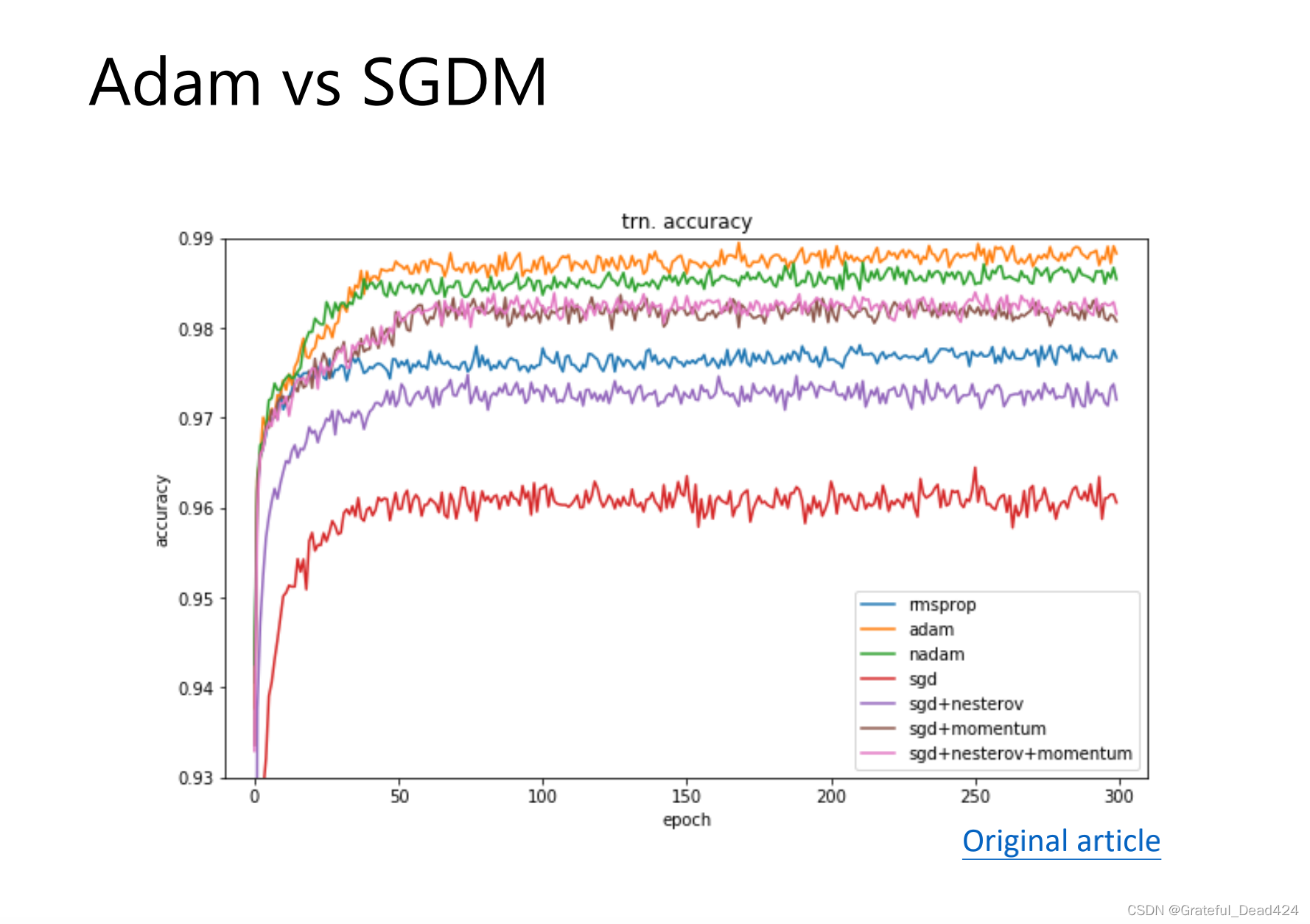
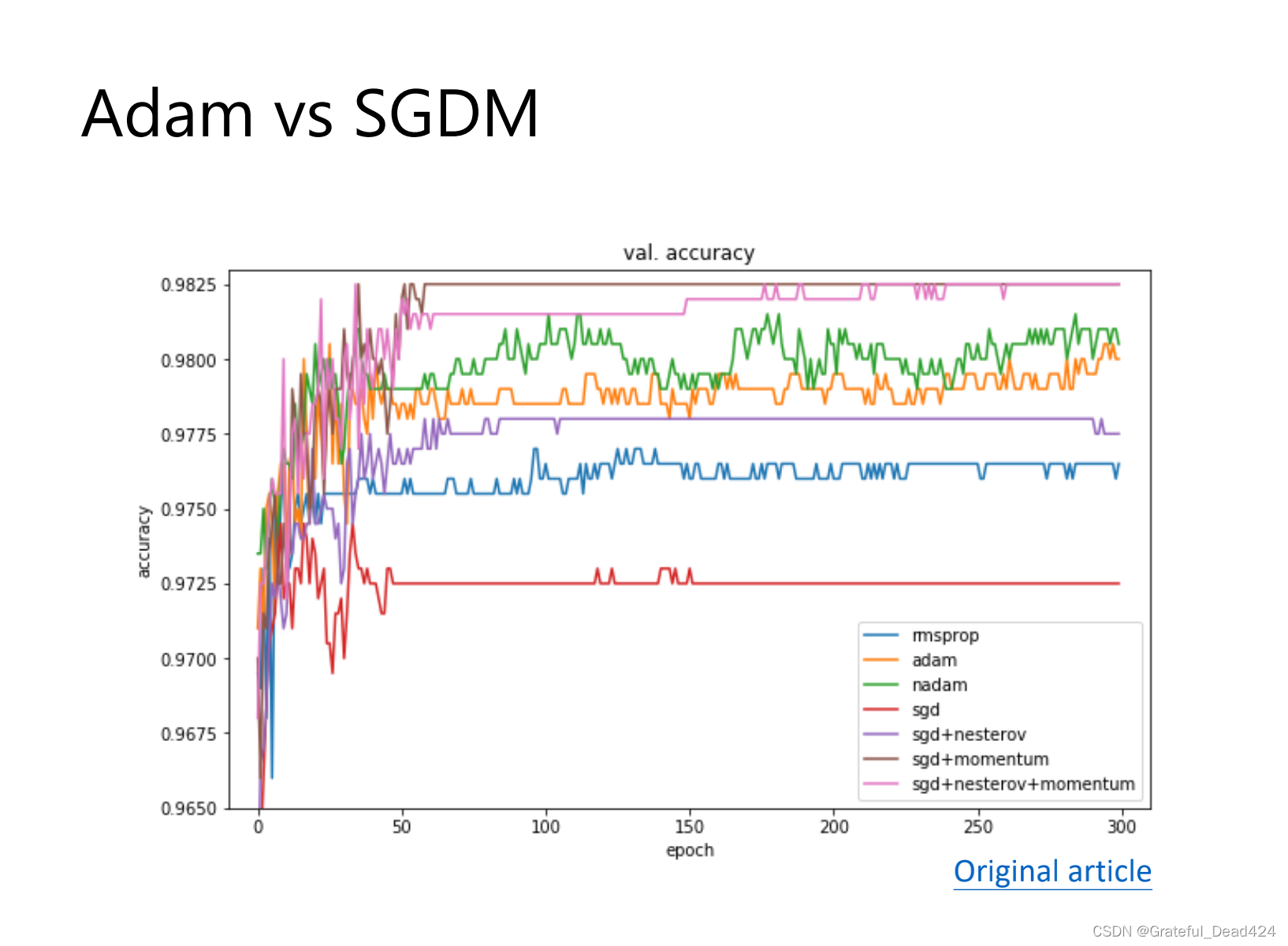
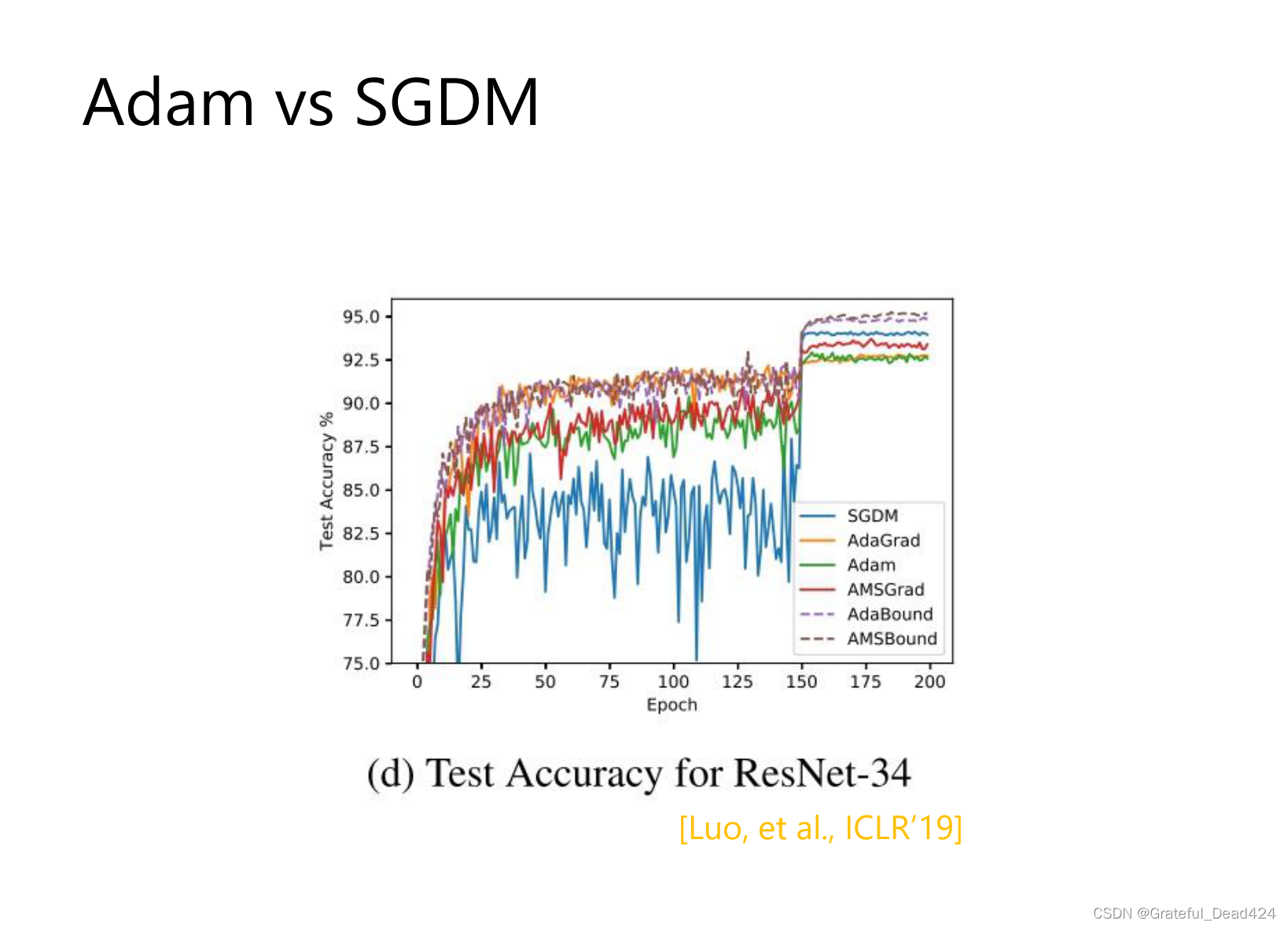
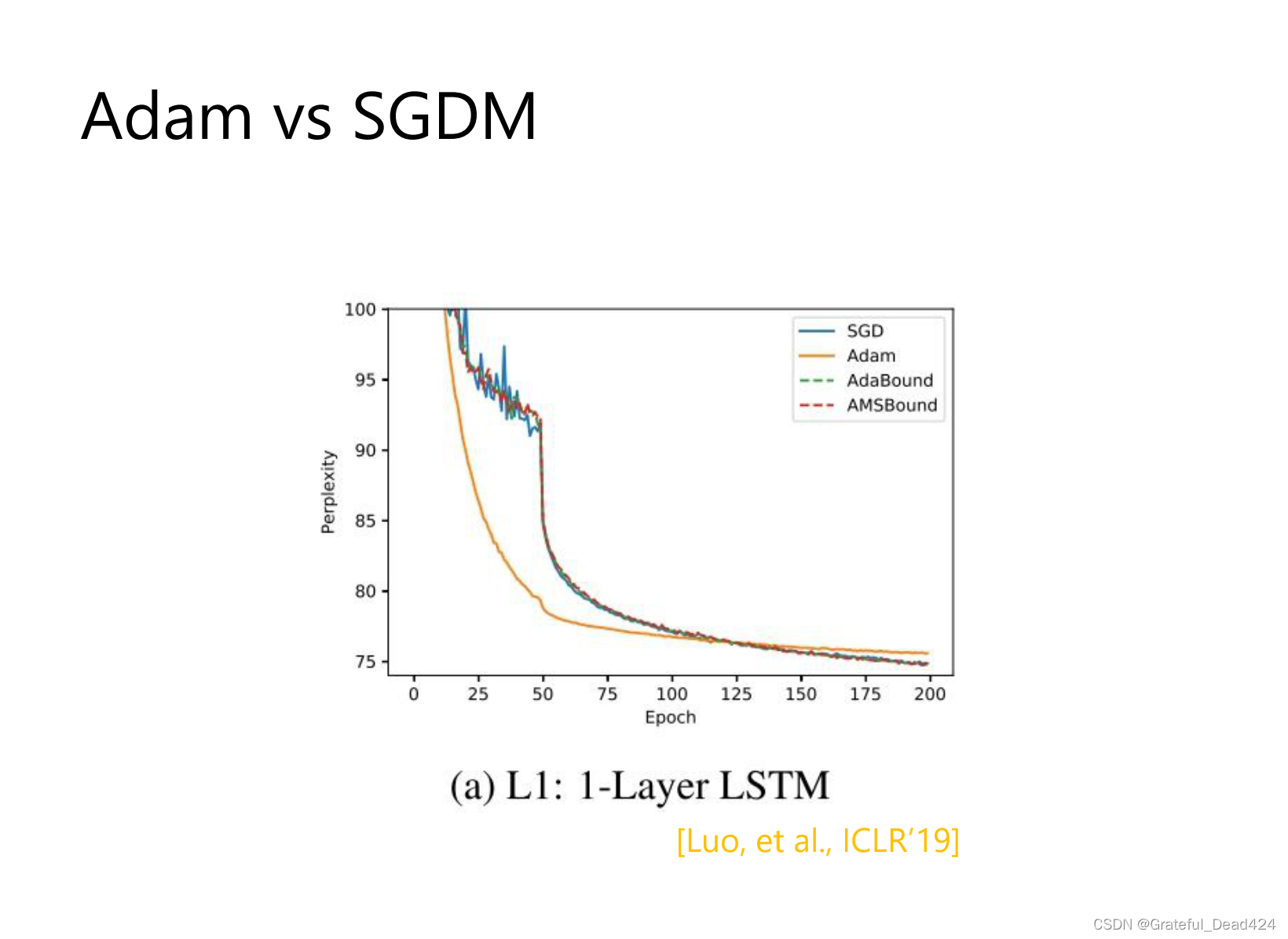
adam:一开始冲的很快
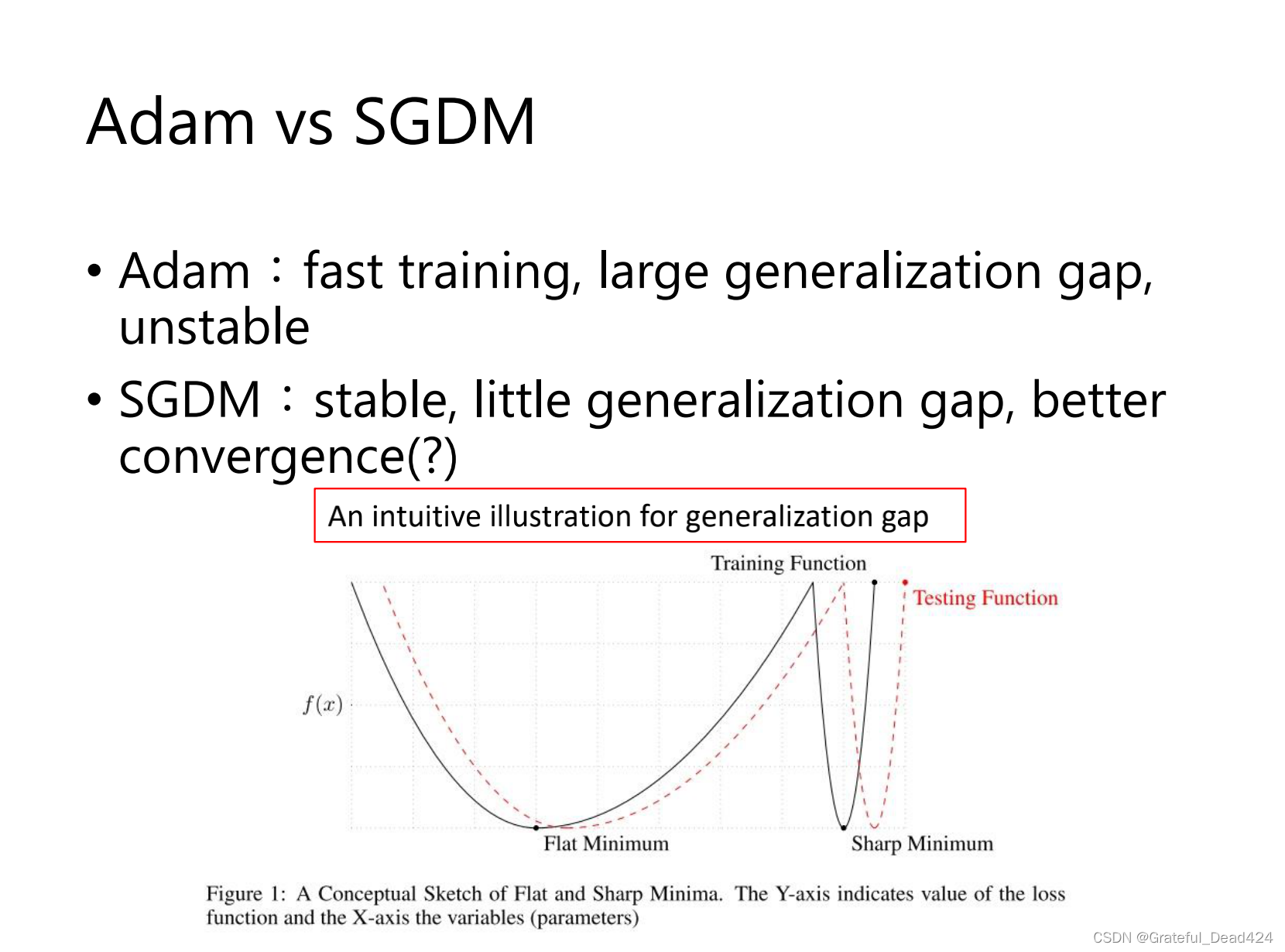
sgdm:冲的不会太快,稳一些,不会有太大的上下起伏的情况
冲的快会形成sharp mininum,generalization gap 大
冲的不快 flat mininum,generalization gap 小
combine一下,一开始用adam后面用sgdm
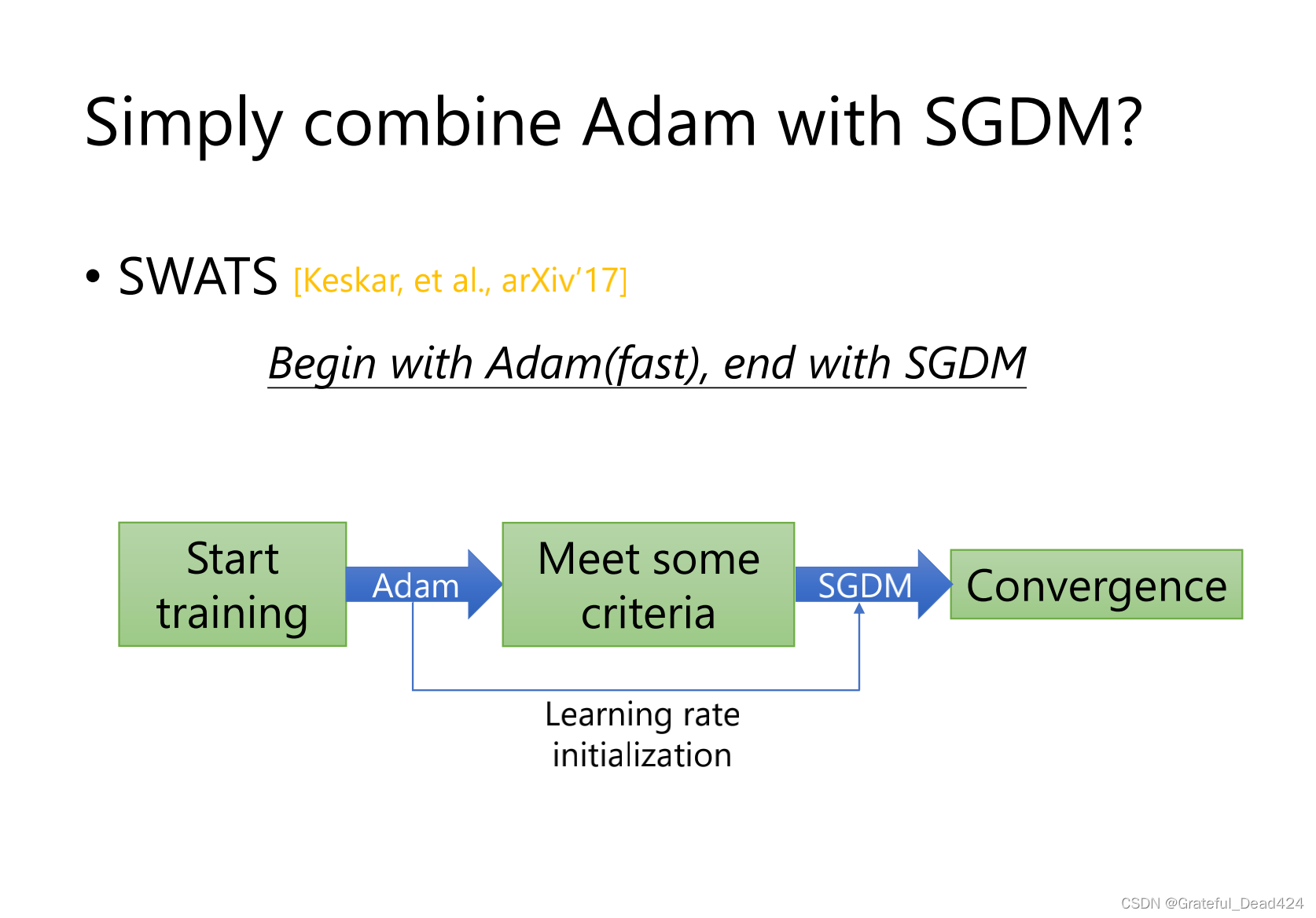
如何让adam像sgdm一样收敛得又快又好

帽等式10的5次方,
等于10^5*10^5*0.001=10^7

前面100998步都是乱走,并且走了很长,100999步才是对的,然而走了很短。

记住以前最大的grad,但是这和adagrad有一样的错误,分母容易变成0

 让learning_rate自己调整
让learning_rate自己调整

sgdm最后很稳,但是速度太慢了
可以通过调整learning_rate加快速度
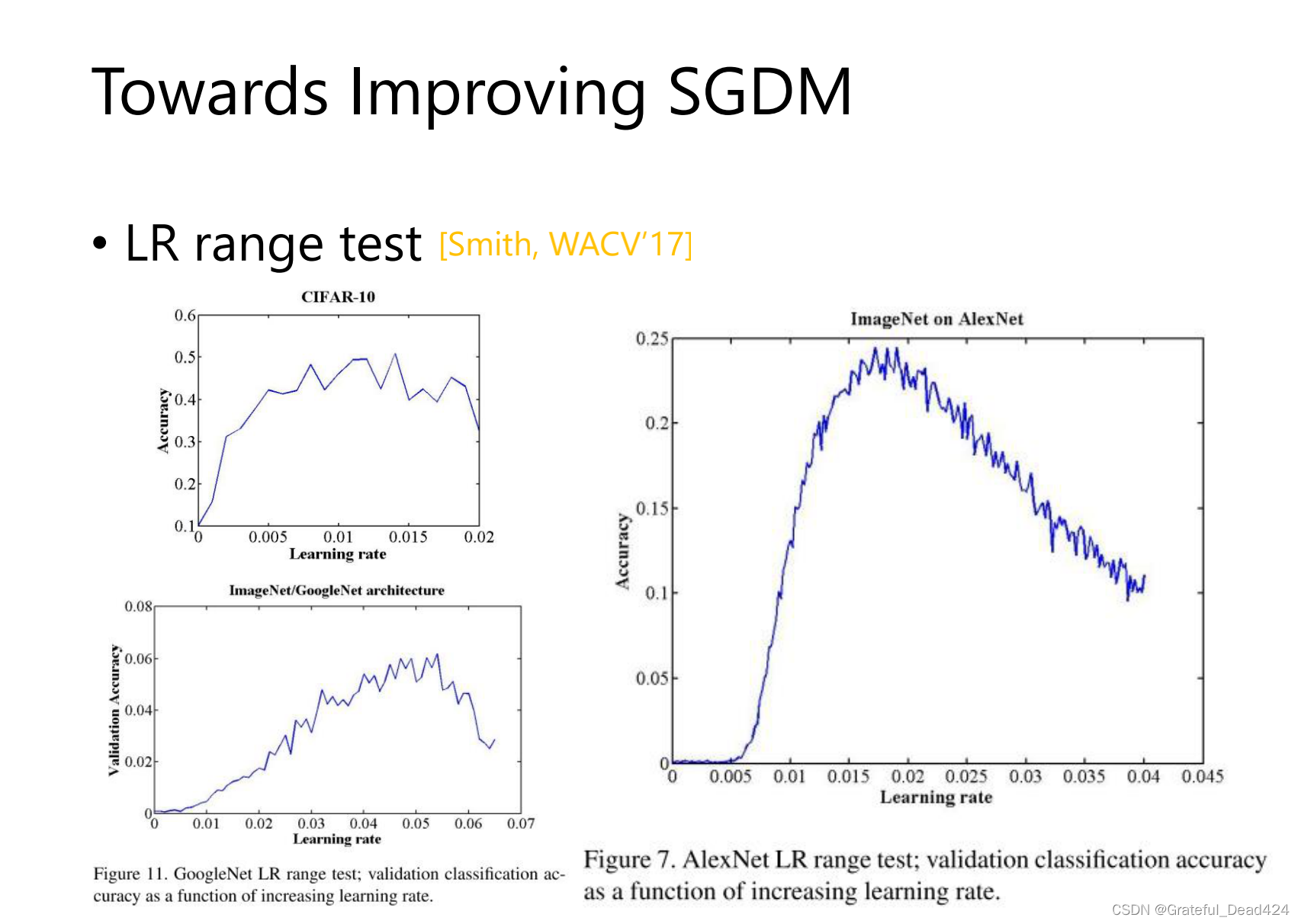
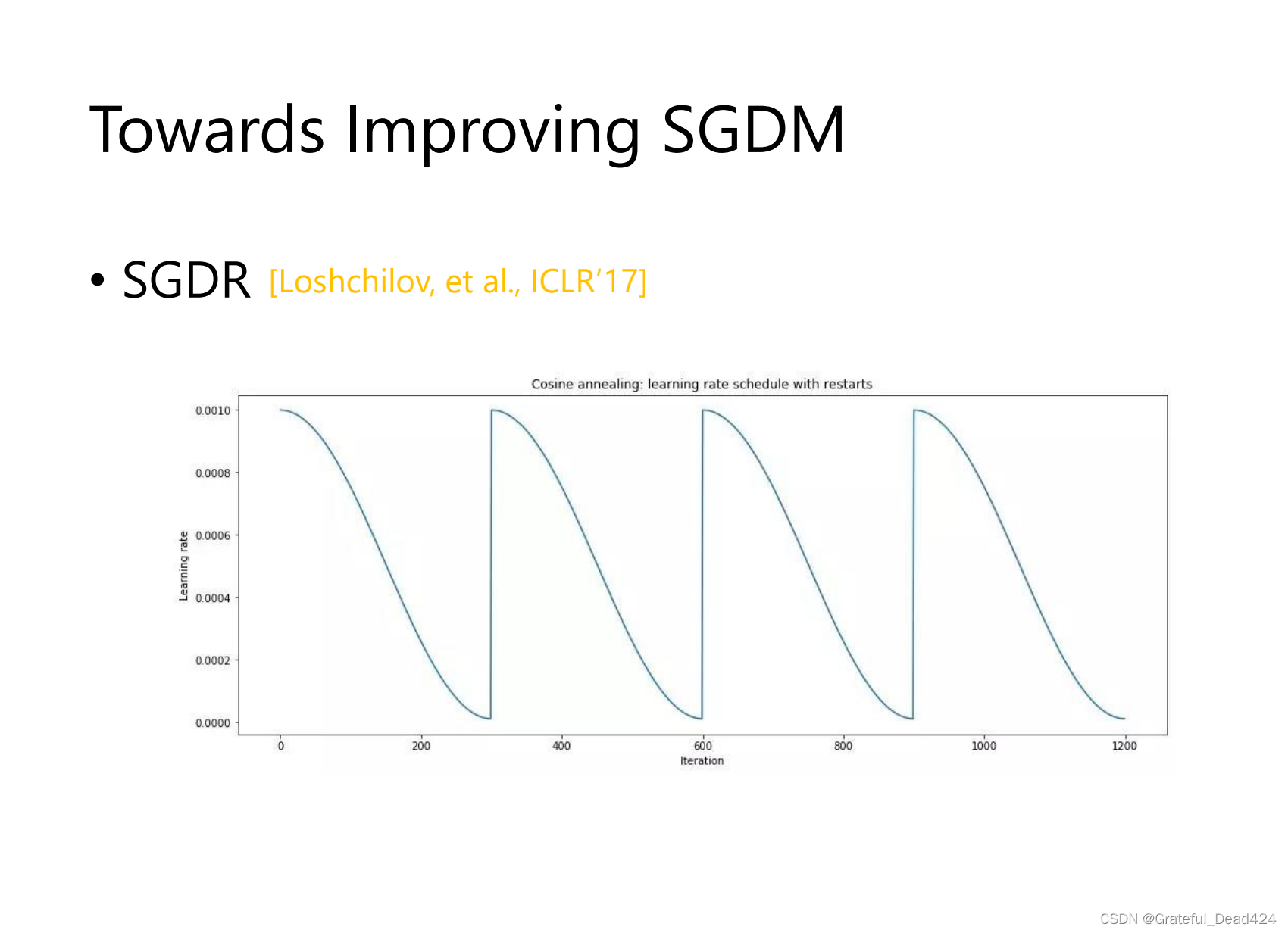
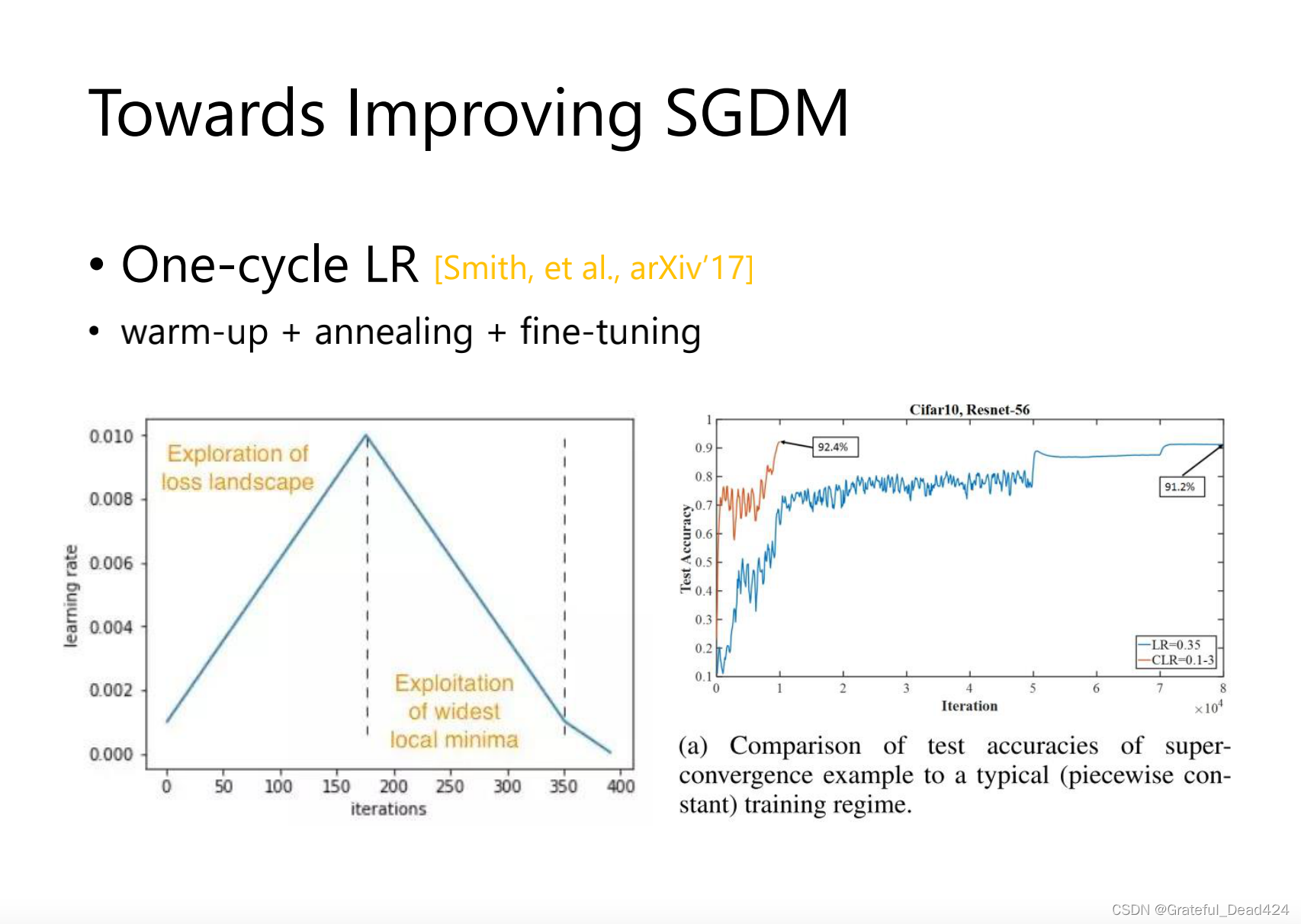
 learning_rate大小大小变化,周期性变化
learning_rate大小大小变化,周期性变化
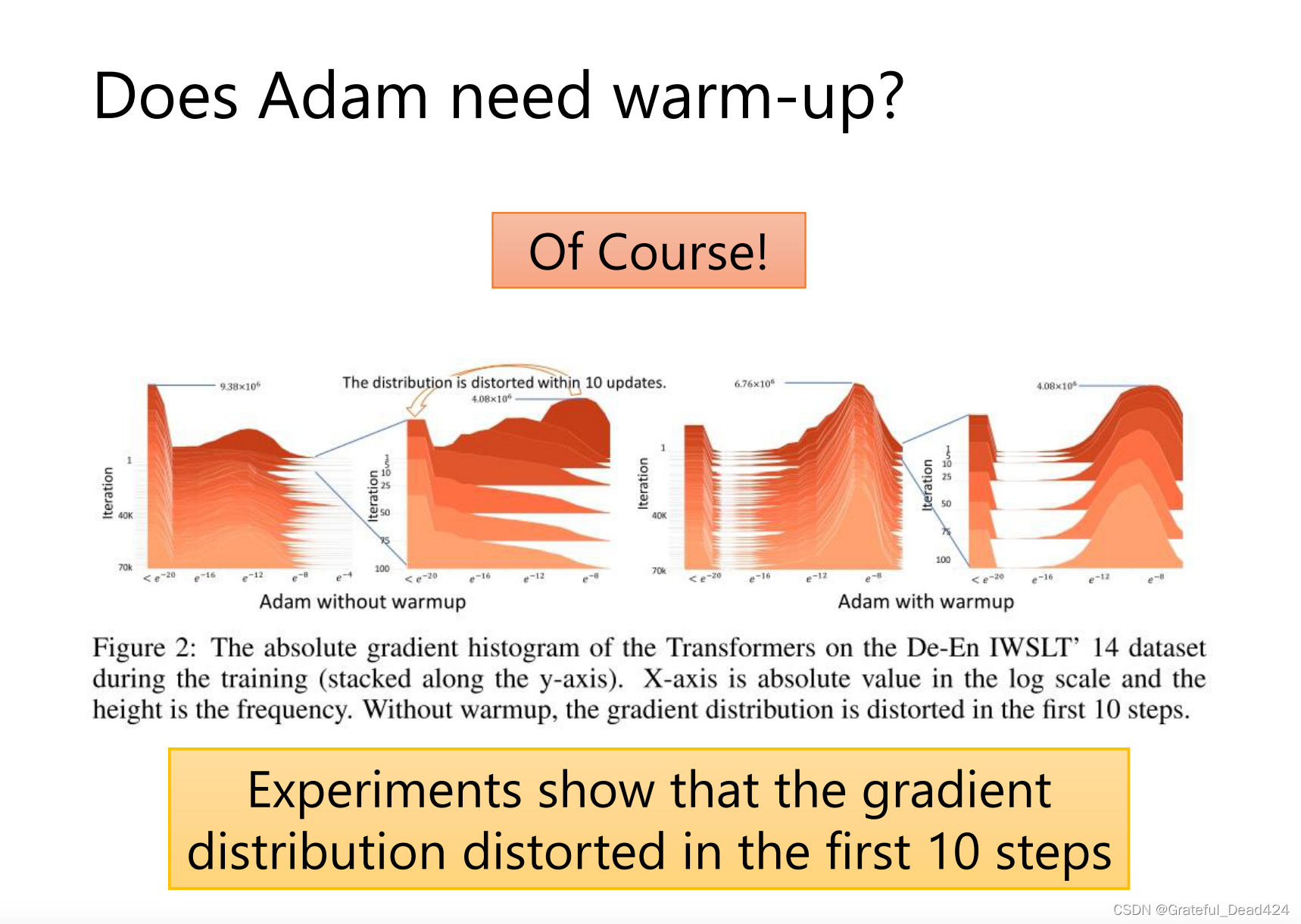
一开始gradient很乱
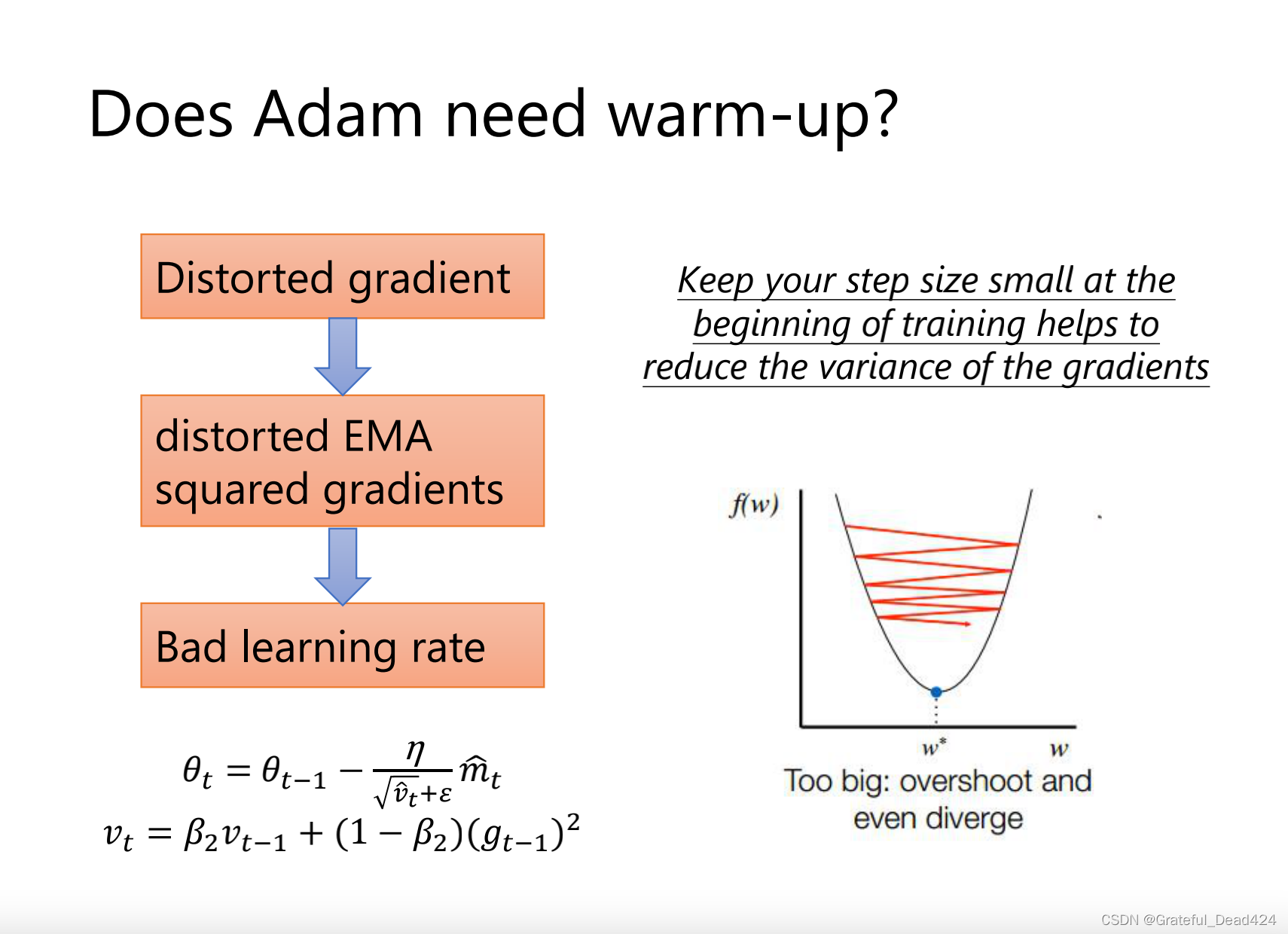
方向比较乱的时候走小步一点,方向不乱的时候走大步一点
一开始用sgdm后面用adam
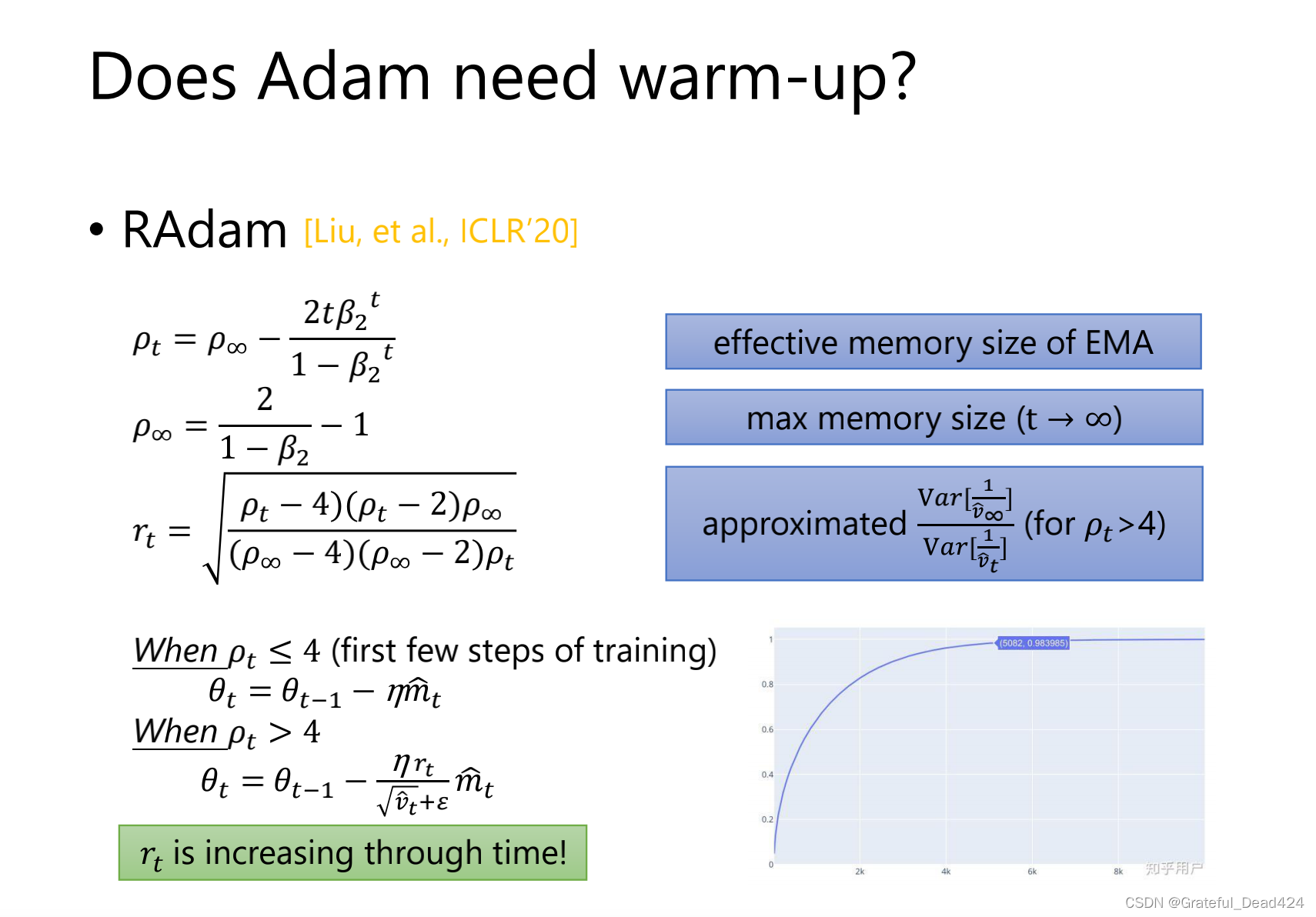
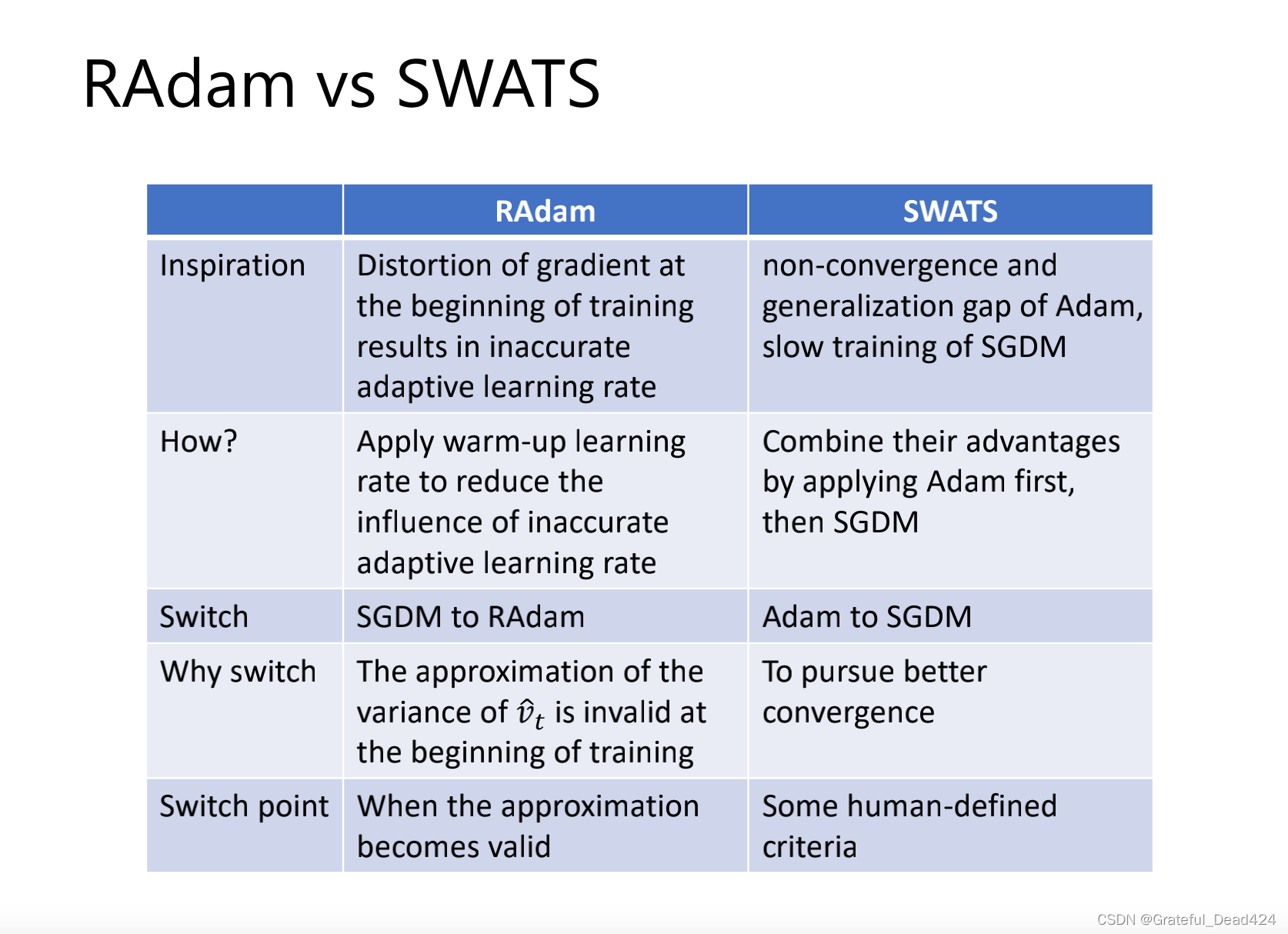 RAdam一开始不用Adam,因为Adam不稳,并且
RAdam一开始不用Adam,因为Adam不稳,并且![]() <4的时候是不能用RAdam
<4的时候是不能用RAdam
SWATS一开始用Adam,因为Adam一开始快,后面用sgdm稳

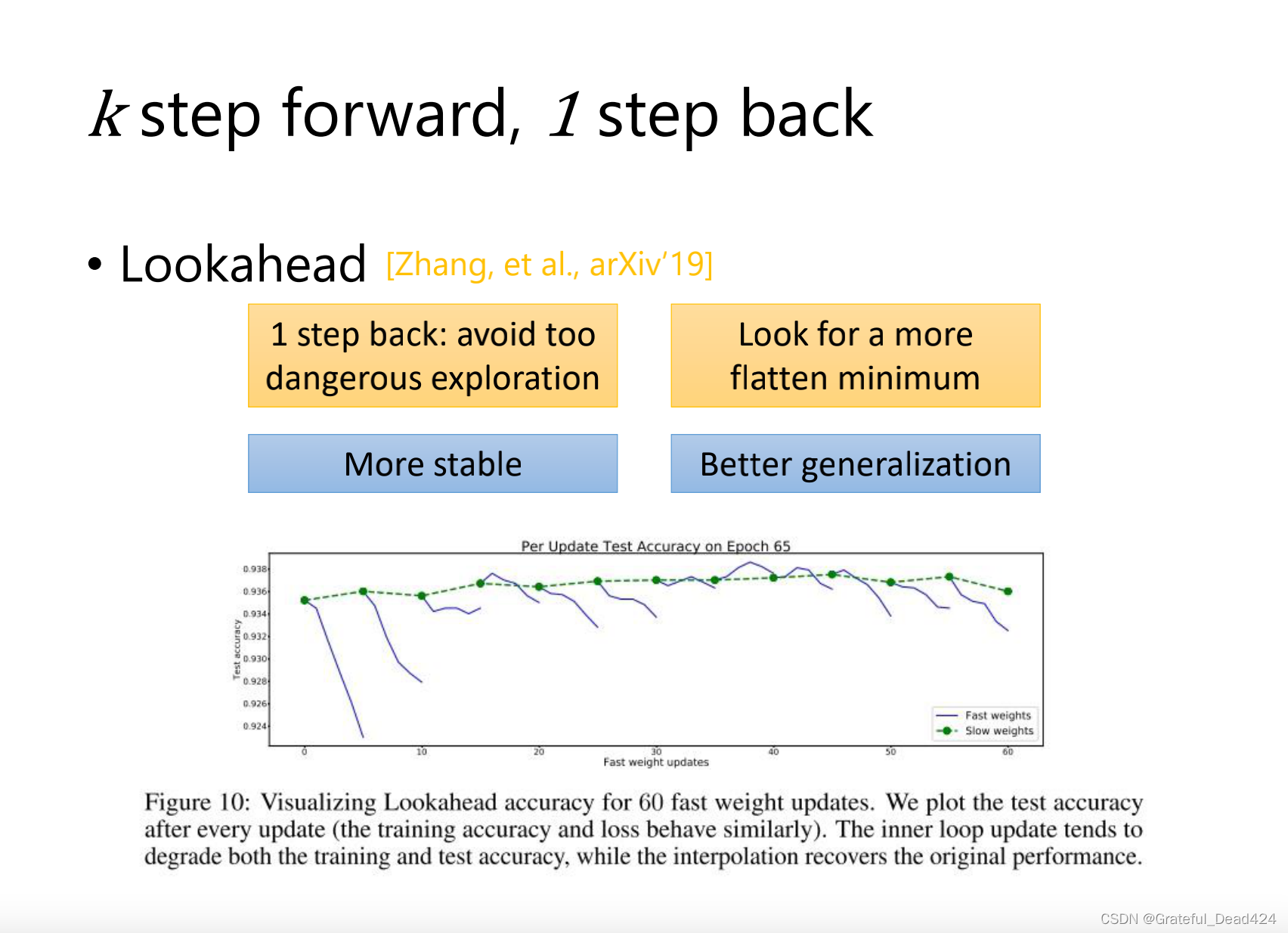




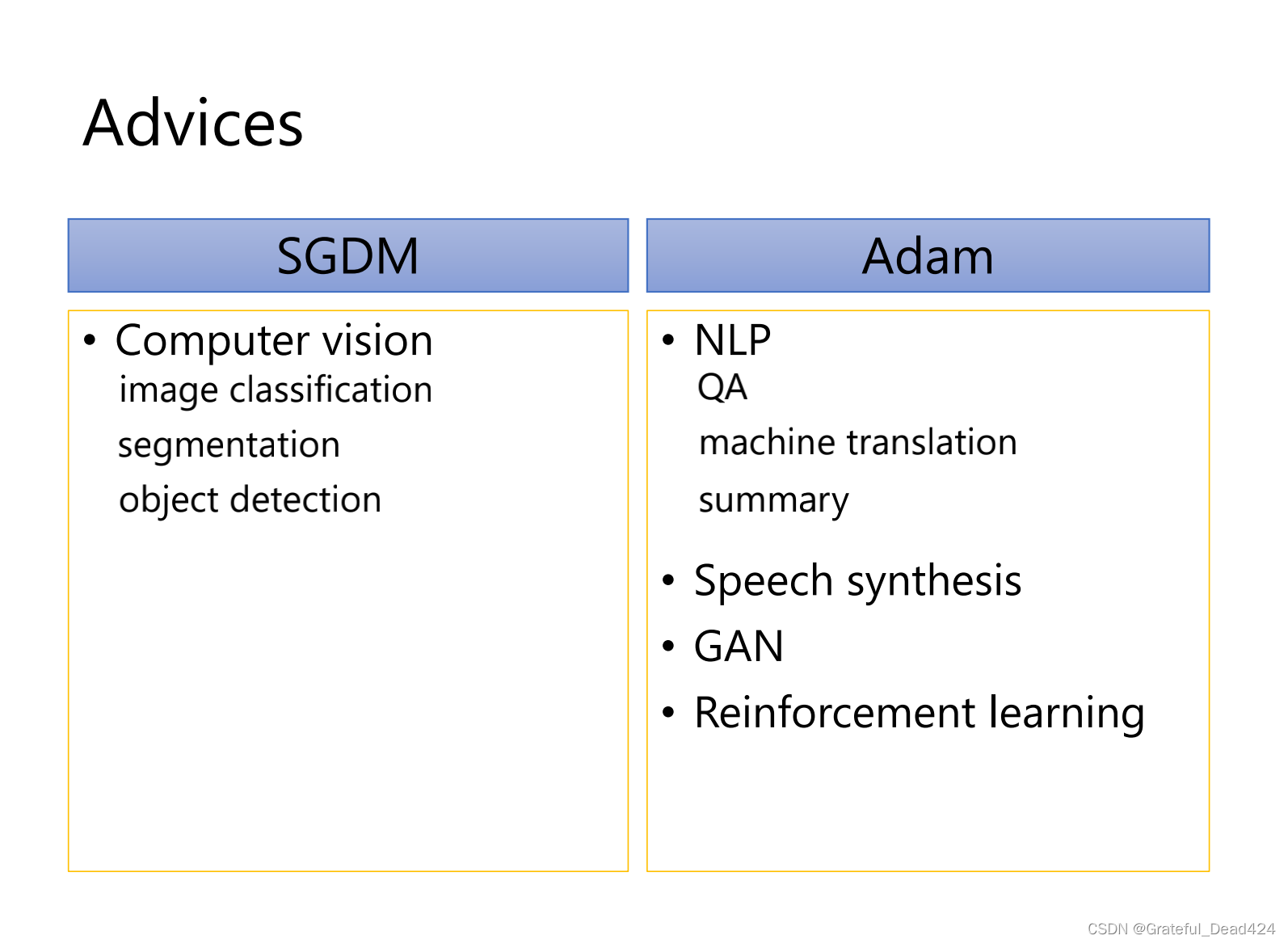
实践中用的最多,用weight decay的效果会比较好





















 2953
2953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









