







一.sklearn介绍
sklearn是机器学习领域中比较常用的库,包含了很多常用实用的算法,我的机器学习打算从这个库开始学起。
二.sklearn学习
1.第一个练习
①.首先导入样本数据
# 导入样本数据
from sklearn import datasets
wine = datasets.load_wine()
wine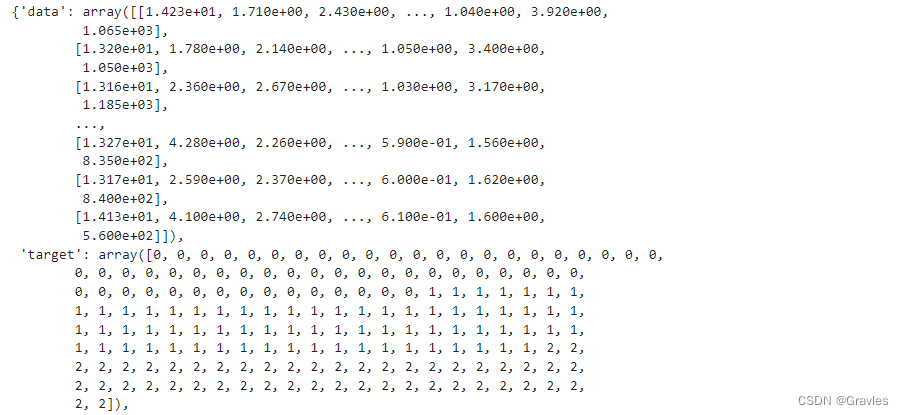
②.打印样本数据及其对应的类别
x = wine.data
y = wine.target
x,y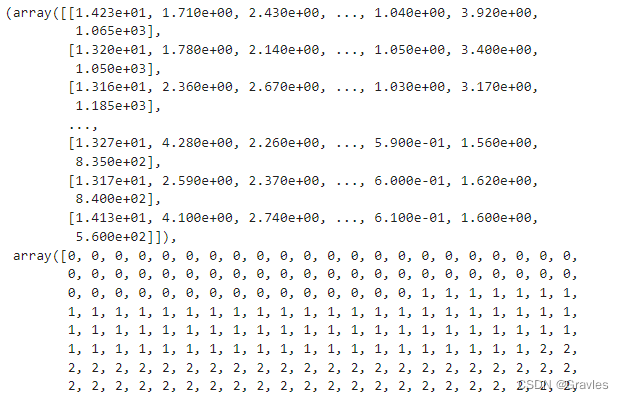
③.打印样本的大小
np.shape(x), np.shape(y)![]()
可以看出X包含178个样本,每个样本有13个特征的二维数组
y为包含178个元素的一维数组
④.把数据分成训练数据和测试数据
因为未来要对实际训练出来的模型进行评估,所以要把所有数据进行拆分,分成训练数据与测试数据。训练数据用于训练模型,测试数据用来评估模型的准确性。
Ⅰ.train_test_split函数
train_test_split 是 scikit-learn 库中 model_selection 模块下的一个函数,用于将数据集划分为训练集和测试集。这个函数对于评估机器学习模型的性能至关重要,因为它允许我们在训练模型时保留一部分数据来进行测试,从而更准确地评估模型在未知数据上的表现。
所以我们导入train_test_split来帮助我们拆分数据。
对应参数:
1.*arrays:这是位置参数,可以接受一个或多个数组作为输入。最常见的用法是传递两个数组:第一个是特征数组(即自变量x),第二个是目标数组(即输出变量y)。如果传入多个特征数组,则它们应该按照(X_train, X_test, y_train, y_test)的顺序返回。
2.test_size:这个参数决定了测试集的大小。它可以是float,表示测试集大小占总数据集的比例(例如,0.2表示20%的数据作为测试集),也可以是int,表示测试集的具体大小。如果没有指定test_size,那么它默认为None,此时会根据train_size来确定测试集的大小。
3.train_size:这个参数决定了训练集的大小。它的用法与test_size类似,可以是float或int。如果没有指定train_size,那么它默认为None,此时会根据test_size来确定训练集的大小。
4.random_state:这个参数用于控制随机状态,以确保代码的可重复性。它可以是一个整数,作为随机数生成器的种子,也可以是np.random.RandomState实例。如果没有指定random_state,那么每次调用train_test_split时都会得到不同的结果。
5.shuffle:这个参数决定了是否在划分之前对数据进行洗牌。默认为True,即洗牌。如果设置为False,则不会洗牌,数据将按照原始顺序进行划分。
6.stratify:这个参数用于分层抽样,确保训练集和测试集中的类别比例大致相同。它通常用于分类问题中,当需要保证每个类别在训练集和测试集中都有足够的代表性时。stratify应该是一个与*arrays中目标变量相同的数组或Series。
# 把数据分成训练数据和测试数据
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
np.shape(x_train), np.shape(x_test)
可以看到训练集上有142个样本,测试集上有36个样本。















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









