







[Scene Graph] Knowledge-Embedded Routing Network for Scene Graph Generation (CVPR 2019) 论文解读
简介
这篇CVPR2019的论文解决的问题是通过一张图像生成相对应的场景图。场景图包括图像中物体区域、区域标签和物体之间的关系。由于作者发现物体和物体之间的关系有些是极为常见的而有些则不是很常见,这种关系分布的不均匀性导致在训练一个完备模型时需要大量的样本,因此将物体共存的统计学意义上的相关信息显式地引入到模型的训练中。这种做法可以有效的使语义空间正则化(即,很少见的物体间关系也可以在预测时凸显出来)并且可以准确的预测物体间的关系。文章中使用的网络模型属于GGNN门控图神经网络(Gated Graph Neural Network)被称为KERN(Knowledge-Embedded Routing Network),使用的数据集是Visual Genome。而且为了衡量该模型对不常见的物体关系的预测性,在常用的Recall@K度量方法基础上提出了一个mean Recall@K方法。
带着问题看论文
- 文章中提到的物体之间的相关性(statistical correlation/co-occurrence)是如何统计出来的?
- 所谓的statistical correlation是如何参与到GGNN模型的训练中并平衡罕见物体关系的训练的?即,如何做到Knowledge Embedding的?
- mean Recall@K的定义和 Recall@K的定义有何不同?为什么mean Recall@K可以更能衡量常见关系和不常见的关系?
- 文章中的实验设置是什么样子的?模型的效果如何呢?
数学模型和网络模型
对于指定的一张图像
I
I
I,最终生成正确场景图的概率为
p
(
G
∣
I
)
p(G|I)
p(G∣I),该概率满足的数学模型如下:
p
(
G
∣
I
)
=
p
(
B
∣
I
)
p
(
O
∣
B
,
I
)
p
(
R
∣
O
,
B
,
I
)
p(G|I)=p(B|I)p(O|B,I)p(R|O,B,I)
p(G∣I)=p(B∣I)p(O∣B,I)p(R∣O,B,I)
其中
B
B
B(Bounding Box)是所有的物体候选区域,
O
O
O(Object Label)是对于候选区域的预测的物体类别标签,
R
R
R(Relationship)是包含标签的物体区域之间的关系。可以看出,最后的场景图就是通过对这三个部分的预测而最终生成的结果。文章提出的网络模型结构如下:
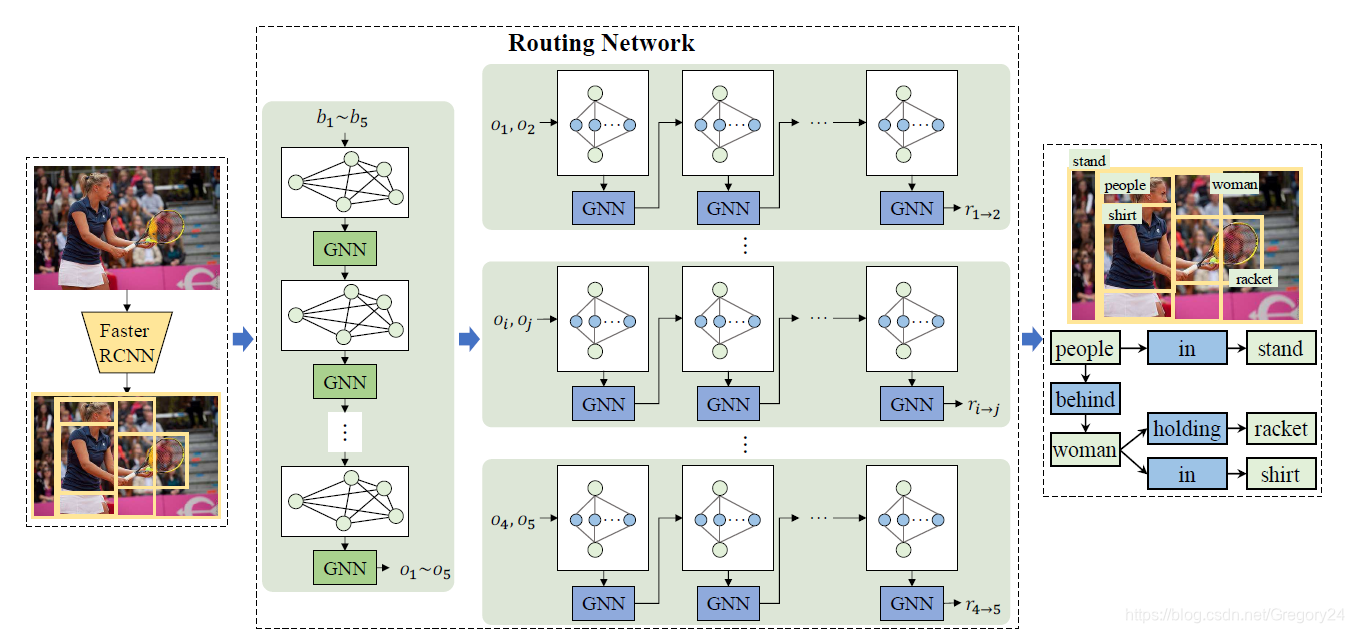
最开始的Faster RCNN物体检测网络模块就是用来做数学模型中
p
(
B
∣
I
)
p(B|I)
p(B∣I)部分的工作的,在Routing Network中左边的GNN迭代结果就是对于每一个物体区域类别标签的预测,即
p
(
O
∣
B
,
I
)
p(O|B,I)
p(O∣B,I)。右边的一系列网络就是针对每一个物体类别选框关系的预测网络,得到的结果即为
p
(
R
∣
O
,
B
,
I
)
p(R|O,B,I)
p(R∣O,B,I)。最终得到的就是这张图像所对应的场景图,这就是用神经网络模型实现数学模型的大致过程。
逐个解决问题
- 关于statistical co-occurrence的信息获得。 在论文中这是一个离线的操作。使用 m c c ′ m_{cc'} mcc′来表示当一个属于类别 c ′ c' c′的物体出现时,属于类别 c c c的物体出现的概率。对于所有类别(总数为 C C C)来说,任何两个物体之间的statistical co-occurrence就可以用一个矩阵 M c M_c Mc来表示,这个矩阵是属于 R C × C \Bbb R^{C×C} RC×C。值得注意的是 M c M_c Mc是一个非对称矩阵哦~
- 关于文章中的knowledge embedding的含义。 这里需要知晓的是,KERN网络的基础模型是GGNN,这里需要回顾一下门控图神经网络中的节点之间的信息传递是如何做到的。GGNN的迭代公式有6个,如下:
(1) h v = [ x v T , 0 ] T {\bf h}_{v}=[{\bf x}_{v}^T, {\bf 0}]^T hv=[xvT,0]T
(2) a v ( t ) = A v : T [ h 1 T . . . h N T ] T + b {\bf a}_{v}^{(t)}={\bf A}_{v:}^{T}[{\bf h}_{1}^T... {\bf h}_{N}^T]^T+{\bf b} av(t)=Av:T[h1T...hNT]T+b
(3) z v t = σ ( W z a v ( t ) + U z h v ( t − 1 ) ) {\bf z}_{v}^t=\sigma({\bf W}^z{\bf a}_{v}^{(t)}+{\bf U}^z{\bf h}_{v}^{(t-1)}) zvt=σ(Wzav(t)+Uzhv(t−1))
(4) r v t = σ ( W r a v ( t ) + U r h v ( t − 1 ) ) {\bf r}_{v}^t=\sigma({\bf W}^r{\bf a}_{v}^{(t)}+{\bf U}^r{\bf h}_{v}^{(t-1)}) rvt=σ(Wrav(t)+Urhv(t−1))
(5) h ~ v t = tanh ( W a v t + U ( r v t ⊙ h v ( t − 1 ) ) ) \tilde {\bf h}_{v}^t=\tanh({\bf W}{\bf a}_{v}^t+{\bf U}({\bf r}_v^t\odot{\bf h}_{v}^{(t-1)})) h~vt=tanh(Wavt+U(rvt⊙hv(t−1)))
(6) h v t = ( 1 − z v t ) ⊙ h v ( t − 1 ) + z v t ⊙ h ~ v t ) {\bf h}_{v}^t=(1-{\bf z}_{v}^t)\odot{\bf h}_{v}^{(t-1)}+{\bf z}_{v}^t\odot \tilde {\bf h}_{v}^t) hvt=(1−zvt)⊙hv(t−1)+zvt⊙h~vt)
这里简单的说一下每个公式的意义,不必纠结具体的运算和下标的含义,不过上标还是要注意一下的。公式(1)的是将图网络中的节点的特征向量映射到隐变量中。公式(2)中的矩阵 A A A就是类似图论中的邻接矩阵了,负责将当前节点周围节点的信息收集到当前节点中,是最重要的一步。公式(3)(4)分别代表着需要网络记住的新产生的信息和需要记住的以前的信息。公式(5)则是新产生的中间信息,最后公式(6)就是完成一步迭代后产生的隐变量的特征。详细理解见论文(Gated Graph Sequence Nerual Network, ICLR 2016)
可以看到,公式(2)是将当前节点和相邻节点之间信息传递的关键,它控制着当前节点和哪些节点传播信息,也同时可以控制需要传播哪些信息。由于GGNN中的运算都是矩阵和向量之间的运算,也就可以理解为什么物体间的statistical co-occurence为什么要表达成矩阵 M c M_c Mc的形式了。在论文中的图网络模型在进行物体类别标签的过程就是将上述公式(2)改写成:
a i c t = [ ∑ j = 1 , j ! = i n ∑ c ′ = 1 C m c ′ c h j c ′ ( t − 1 ) , ∑ j = 1 , j ! = i n ∑ c ′ = 1 C m c c ′ h j c ′ ( t − 1 ) ] {\bf a}_{ic}^t=[{\sum_{j=1,j!=i}^{n}}{\sum_{c'=1}^{C}}m_{c'c}{\bf h}_{jc'}^{(t-1)},{\sum_{j=1,j!=i}^{n}}{\sum_{c'=1}^{C}}m_{cc'}{\bf h}_{jc'}^{(t-1)}] aict=[∑j=1,j!=in∑c′=1Cmc′chjc′(t−1),∑j=1,j!=in∑c′=1Cmcc′hjc′(t−1)]
这一步就是将当前物体标签的统计学相关的物体标签概率联合在一起了,也就是文章中提到的将统计学信息显式的加入到模型中的做法,就算是不常见的物体关系也可以在矩阵 M c M_c Mc中表现出来,而不是需要模型从零开始硬生生训练出来。另外,模型中提到的将环境信息(contextual cue)加入进来的做法也是可以在网络中体现出来的,因为在公式(1)中的特征向量输入就是Faster RCNN中ROI pooling层的区域特征向量。值得注意的是,在预测一个物体区域的标签的时候,是将这个区域标签的所有可能性都列出来,即生成了 C C C个相同位置的节点,最后通过softmax函数选出最有可能的物体标签。对于物体间关系的预测做法和标签预测时的做法基本一致,只是对于两两物体之间的关系进行预测,和其他物体无关。 - 关于Recall@K(以下简称R@K)和 mean Recall@K(以下简称mR@K)的定义。 R@K的定义为关系在ground truth中的物体关在模型预测出来置信度最高的K个关系中出现的比例。也就是说,由于物体关系分布十分不均匀,如果我的模型把经常出现的关系预测的非常准但是罕见的关系预测非常不准,在计算R@K的时候我的数值也会很高的。因此,作者在文章中提出了mR@K,即对于每一个类别分别计算R@K然后再平均一下,这样罕见的物体关系也在衡量模型准确度中具有相同的分量了。
- 关于文章的实验设置。 文章中设置了三个实验:
(1)PredCls:在有Bounding Box和Object Label的情况下对物体间Relation预测实验。
(2)SGCls:在有Bounding Box的情况下,对Object Lable的预测和物体间Relation预测的实验。
(3)SGGen:直接对Bounding Box,Object Label和物体间Relation预测的实验。
在实验的结果上,KERN表现出the state-of-the-art级别的表现,超过了CVPR 18年Neural Motifs Scene Graph Parsing With Global Context这篇文章的结果。而且在实验部分也有去掉statistical co-occurrence信息的对照组,结果显示显式地使用该信息是对scene graph generation是有一定效果的。
以上就是我对这篇文章在阅读时重点内容的理解,如有纰漏请不要吝惜在评论区指教哦~














 7591
7591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









