









1. 总体介绍
本文是2018年的一篇CVPR,虽然现在看起来非常简单,但是在当时还是非常突出的,将阴影检测和除去阴影联合起来训练。
论文:https://arxiv.org/abs/1712.02478
代码:https://github.com/IsHYuhi/ST-CGAN_Stacked_Conditional_Generative_Adversarial_Networks (非官方实现)
2. 主要思想
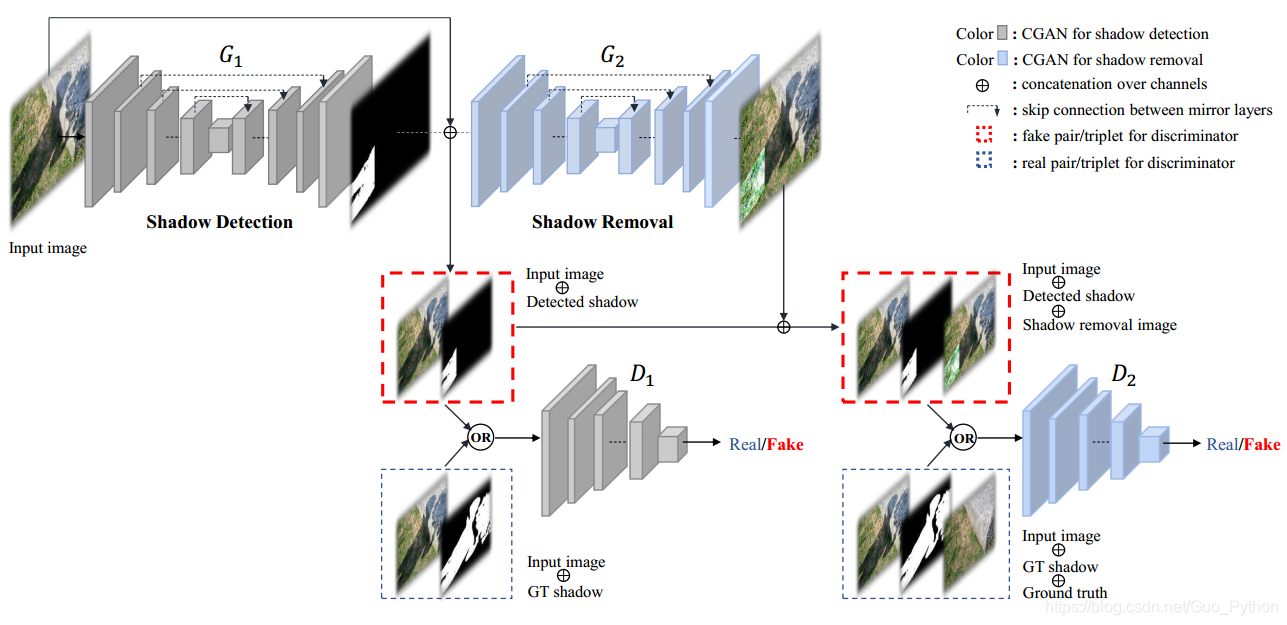
作者提出的框架包含两个生成模型和两个判别模型,并且可以实现端到端的联合训练。
第一个生成模型G1生成阴影的mask,mask和Input image堆叠成四通道作为第二个生成模型G2的输入,生成去除阴影后的图片。
第一个判别模型D1的输入是一个四通道的图,四通道由输入图片和对应mask的堆叠;第二个判别模型D2的输入是一个7通道的图,分别是输入图片、mask和去除阴影后图片的堆叠。
除了上图所示,明显的GAN_Loss, 对于生成的mask和去除阴影后的图片,使用BCE loss和L1_loss进行监督。即整个框架由四个Loss组成的,分别是两个GAN_loss、BCE loss和L1_loss,并且在每个loss前面配置的参数来平衡整体的损失函数。
整体的损失函数如下图所示:
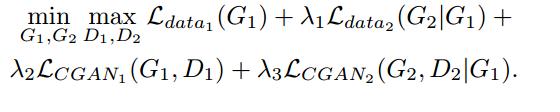
3. 文章分析
(1)D1的输入为什么是用阴影图像+mask?
D1是干什么的?是为了判断网络输出的检测的mask是否为真。那么光有mask可以判断出mas是真的吗?当然不行,加上有阴影图像为什么就可以判断处真假?与有阴影图一对比就知道检测的mask是不是完整了!也就说得有参照。
(2)D2的输入为什么要加上有阴影图像?
有阴影图像是对比的基准,没有有阴影图,判别器仅靠无阴影图并不知道阴影去除的是否正确。仅能让output无阴影图与GT无阴影图特征上相近。如果GT无阴影图有一暗块在左上角,output无阴影图的一个暗块在右上角,判别器可能分不出来。
(3)D2的输入为什么要加上mask?
这是比较亮眼的地方,阴影检测的目的其实是为了阴影去除。检测的好坏影响去除的效果。那么额外加入mask作为输入,梯度回传让第二阶段的去除过程更好的指导mask的生成!
4. 实验部分
下表的评价指标为RMSE,达到了当时最好的效果。

最后的效果图如下:

博主点评:(1) 开源的代码写的很简洁,对于理解GAN Loss很有帮助,其他GAN Loss也都基本上是这样写的。
(2) 从现在的眼光看,作者另外的一个很大贡献就是开源了ISTD数据集,对于去阴影的研究很有帮助。

















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









