









前言:libtorch是pytorch原生支持的生态,理论上只要是pytorch训练的模型都能用libtorch部署,因为他们共用相同的c++代码。
主要参考:Pytorch官网
一. PyTorch模型转为Troch Script
import torch
import torchvision
# An instance of your model.
model = torchvision.models.resnet18()
script_module = torch.jit.script(model)
script_module.save("my_resnet_model.pt")
二. 用c++进行模型推理
#include <torch/script.h>
#include <iostream>
#include <vector>
int main()
{
// 加载模型
torch::jit::script::Module module;
module = torch::jit::load(model_path, torch::kCUDA);
module.to(torch::kCUDA);
module.eval();
// 模型推理
torch::NoGradGuard no_guard;
torch::jit::getProfilingMode() = false;
std::vector<torch::jit::IValue> inputs;
inputs.push_back(torch::ones({1, 3, 224, 224}));
at::Tensor output = module.forward(inputs).toTensor();
std::cout << output.slice(/*dim=*/1, /*start=*/0, /*end=*/5) << '\n';
}
三. cmake构建工程
cmake_minimum_required(VERSION 3.0 FATAL_ERROR)
project(custom_ops)
list(APPEND CMAKE_PREFIX_PATH /home/guopei/workspace/table_libtorch/libtorch_learning/libtorch)
find_package(Torch REQUIRED)
add_executable(example-app example-app.cpp)
target_link_libraries(example-app "${TORCH_LIBRARIES}")
set_property(TARGET example-app PROPERTY CXX_STANDARD 14)
四. 转模型可能遇到的问题
1. 显示指定类型
错误栈:
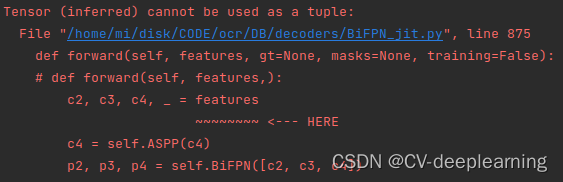
解析:这是由于模型转换过程中默认输入变量为 torch.Tensor 因此需要显示申明其为List[torch.Tensor]
解决方法:
from typing import List
def forward(self, features:List[torch.Tensor], gt=None, masks=None, training=False):
五. 模型推理可能遇到的问题
1. c++ model forword有多个返回值
参考:c++ load pytorch 的数据转换
我的实现:
void My_example::inference(cv::Mat &resize_img) {
torch::Tensor tensor = torch::from_blob(resize_img.data, {1, 640, 640,3}, torch::kFloat);
tensor = tensor.permute({0, 3, 1, 2});
tensor = tensor.add(-1);
tensor = tensor.to(torch::kCUDA);
std::vector<torch::jit::IValue>inputs;
inputs.push_back(tensor);
auto outputs = this->module.forward(inputs).toTuple();
this->out_0 = outputs->elements()[0].toTensor().squeeze();
this->out_1 = outputs->elements()[1].toTensor().squeeze();
this->out_2 = outputs->elements()[2].toTensor().squeeze();
}
2. 图片的预处理操作尽量放到gpu中处理(加快推理速度)
// 修改前
img.convertTo(img, CV_32FC1, 1.0/255, -0.5);
// 修改后
img.convertTo(img, CV_32FC1);
tensort.mut(1.0/255).add(-0.5);
参考:
TorchScript使用的注意事项和常见错误
c++ 部署libtorch时常用操作API
每天进步一点,加油!!!
欢迎技术交流:
















 4401
4401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









