






测试工具
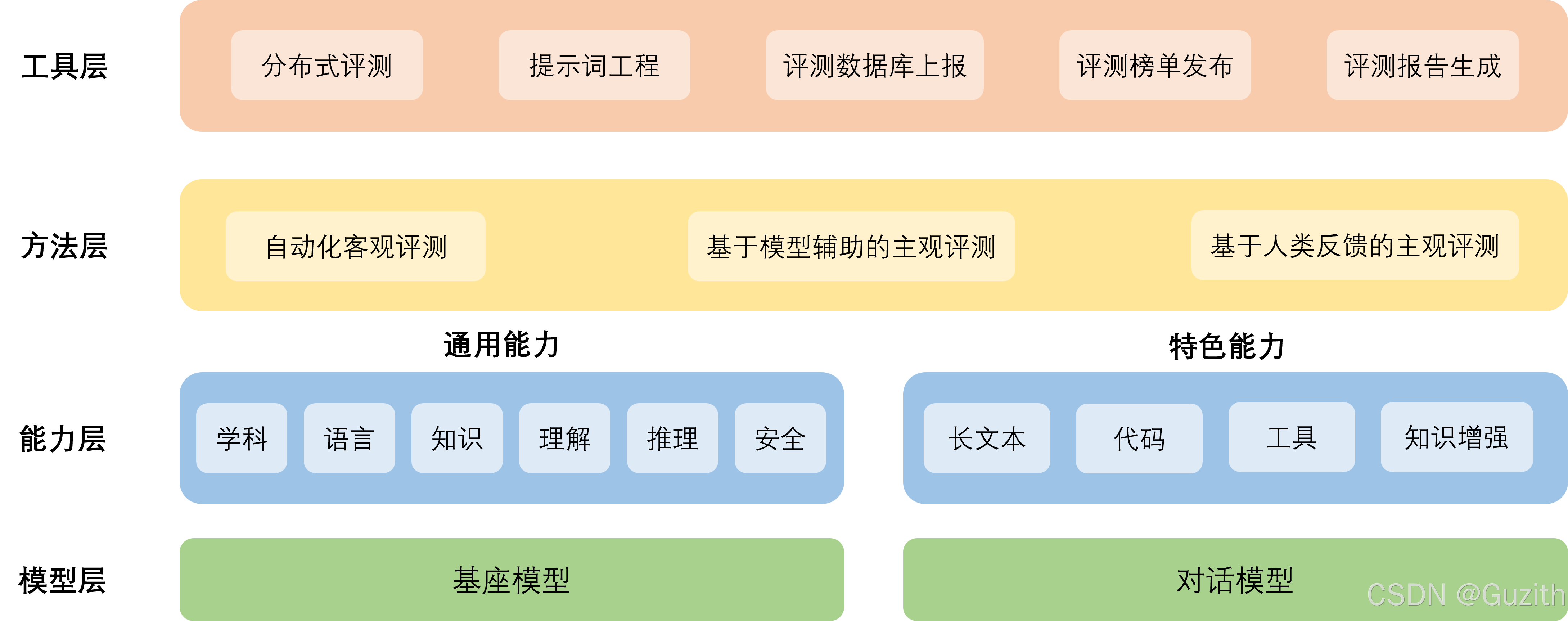
大模型基准评测体系(4/4)
在大模型评测整个过程中,从评测需求分析开始到最后的测试结果展示,或多或少都需要借助工具去实现我们想要的结果。下面按照评测方式,介绍不同类型的评测工具。分别为:评测框架套件、评测平台、及独立评测中需要的工具。
综合测试套件
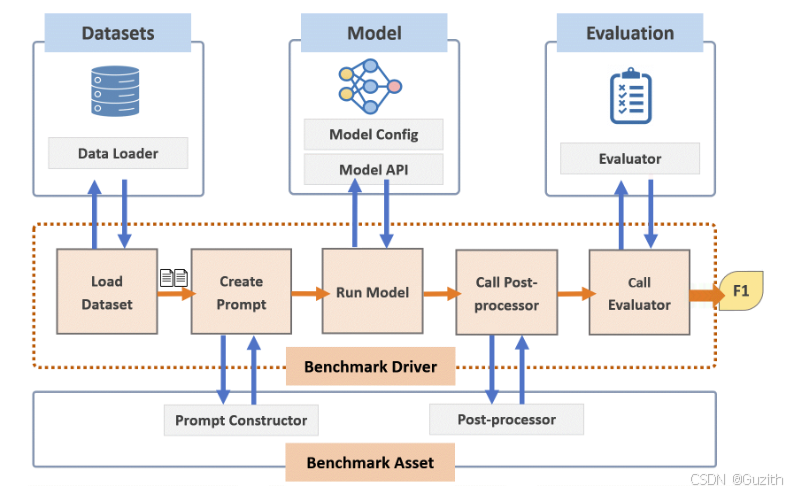
有综合类基准测试套件如,LLMeBench。支持数据集管理、模型库管理、API管理、测试任务分发、测试指标计算、测试结果分析、测试结果展示等多种基础功能。从下方原理图中可以发现其包含数据加载模块、提示工程词模块、模型执行模块、后处理模块和结果评估模块,与大模型的基准测试流程基本一致。
大模型评测平台
以大模型评测平台OpenCompass(司南)为例。司南提供了丰富多样的数据集,有综合类也有特定任务类,同时平台支持多种大模型选择,使用者上传自己的大模型到平台与其他模型做对比。在平台可以完成评测的所有流程。
独立完成大模型评测,过程中使用的部分工具介绍。
一、性能评测工具
1.深度学习框架自带的评测工具
- PyTorch:它提供了如
torchmetrics库,该库包含了一系列用于评估模型性能的指标计算函数。例如,在分类任务中可以方便地计算准确率(Accuracy)、精确率(Precision)、召回率(Recall)和 F1 - score 等。以计算准确率为例,使用torchmetrics.Accuracy()函数,只需将模型的预测结果和真实标签传入,就能快速得到准确率的值。 - TensorFlow:它有
tf.keras.metrics模块,提供了多种用于模型评估的度量指标。比如在评估回归模型时,可以使用MeanSquaredError(均方误差)来衡量预测值与真实值之间的误差;在分类任务中,CategoricalAccuracy用于计算分类准确率。这些工具与模型训练和预测流程紧密结合,方便在模型开发过程中随时进行性能评估。
2.第三方性能评测库
- Scikit - learn:这是一个功能强大的机器学习库,在传统机器学习和部分深度学习模型评测中应用广泛。它提供了众多评估指标计算方法,如用于分类任务的
accuracy_score(准确率)、precision_score(精确率)、recall_score(召回率)、f1_score(F1 - score),用于回归任务的mean_squared_error(均方误差)、r2_score(决定系数)等。这些指标函数简单易用,适用于多种类型的数据和模型架构,并且可以方便地在不同模型之间进行比较。
二、数据处理工具
1.数据收集工具
- 网络爬虫(如 Scrapy):如果需要收集网页数据用于模型评测,例如收集用于训练和测试自然语言处理模型的文本内容,Scrapy 是一个很好的选择。它可以帮助用户有针对性地从互联网上抓取大量文本、图像等数据。用户可以通过定义爬取规则,如指定网站域名、页面结构、数据标签等,高效地获取数据。例如,想要收集新闻网站上的文章用于文本分类模型评测,就可以使用 Scrapy 根据新闻文章的 HTML 标签结构来抓取标题、正文等内容。
- 公开数据集平台(如 Kaggle、UC Irvine Machine Learning Repository、huggingface):这些平台提供了丰富的数据集,涵盖各种领域和任务类型。用户可以根据自己的评测需求,搜索并下载合适的数据集。例如,在图像识别评测中,可以从 Kaggle 上下载包含不同类别图像的数据集,如 CIFAR - 10(包含 10 个不同类别的 6 万张 32x32 彩色图像)或 Caltech 101(101 类加利福尼亚理工学院图像数据库)。
2.数据清洗和预处理工具
- Pandas:这是一个用于数据处理和分析的强大库。它可以方便地进行数据加载、清洗和转换。例如,在处理表格型数据时,Pandas 可以删除含有缺失值的行或列,对数据进行标准化(如归一化处理),以及对文本数据进行简单的预处理,如将文本转换为小写、去除标点符号等。对于一个包含文本和标签的数据集,使用 Pandas 可以轻松地将文本列和标签列分离,便于后续的模型输入和评估。
- NLTK(Natural Language Toolkit)和 spaCy:在自然语言处理领域,NLTK 和 spaCy 是常用的数据预处理工具。NLTK 提供了丰富的语料库和工具,如分词(将文本分割为单词)、词性标注(标注单词的词性,如名词、动词等)、词干提取(获取单词的词干)和停用词去除(去除像 “the”“a”“and” 等在语义分析中不太重要的词)等功能。spaCy 具有高效的语言处理管道,同样可以进行分词、词性标注等操作,并且它的处理速度相对较快,在处理大规模文本数据时具有优势。
三、模型可视化工具
- TensorBoard(适用于 TensorFlow 和 PyTorch 等):它是一个功能强大的可视化工具,可以用于展示模型的训练过程和结构。在模型评测过程中,可以通过 TensorBoard 观察模型的损失函数(Loss Function)随训练轮次(Epochs)的变化情况,以判断模型是否收敛。同时,它还可以展示模型的计算图(Graph),帮助用户理解模型内部的运算流程和参数流动。例如,在评测一个复杂的神经网络模型时,通过 TensorBoard 的可视化界面,可以清晰地看到每层神经网络的输入输出形状、参数数量等信息,从而更好地评估模型的复杂度和性能。
- Netron:这是一个用于可视化深度学习模型结构的工具。它支持多种模型格式,包括但不限于 ONNX(Open Neural Network Exchange)、TensorFlow 的 SavedModel 等。通过将模型文件加载到 Netron 中,可以直观地看到模型的网络架构,如各层之间是如何连接的、每层的类型(如卷积层、全连接层等)和参数数量等细节。这对于评估模型的架构合理性和复杂度非常有帮助,特别是在对比不同架构的大模型时。

















 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









