





特别说明:原文链接https://docs.nvidia.com/nim/benchmarking/llm/latest/index.html
概述
摘要
本文说明了 如何对大型语言模型LLMs部署, 常见指标和参数 进行基准测试,以及测试的步骤。
使用本指南,LLM应用程序开发人员和企业系统所有者将能够回答以下问题:
-
测量
LLM推理延迟和吞吐量最重要的指标是什么? -
针对
LLMs应该使用什么基准测试工具?它们之间的主要区别是什么? -
如何使用
NVIDIA GenAI-Perf来测试LLM应用程序的 延迟 和 吞吐量?
LLM推理 基准测试介绍
过去几年见证了生成式人工智能和大型语言模型LLMs的普及,作为更广泛的人工智能革命的一部分。随着越来越多的LLM应用在企业中推广,确保不同服务解决方案的成本效率的基准测试需求变的迫切。LLM应用程序的成本取决于它在响应和吸引用户的同时可以处理多少查询。请注意,所有的成本度量都应该基于达到可接受的准确度度量,如应用程序的用例所定义的。本指南仅关注于成本测量,不包括精度测量。
LLM性能的标准化基准测试可以使用许多工具完成,包括长期存在的工具(如Locust和K6),以及专门用于LLM的新开源工具(如NVIDIA GenAI-Perf和LLMPerf)。这些客户端工具为基于**LLM**的应用程序提供了特定的指标,但在如何定义、度量和计算不同的指标方面并不一致。本指南试图阐明常见的度量标准及其差异和局限性。还提供了一个分步指南,介绍如何使用我们首选的工具GenAI-Perf对LLM应用程序进行基准测试。
值得注意的是,性能基准测试和负载测试是评估大型语言模型部署的两种不同方法。
- 如
K6等工具所示,负载测试侧重于模拟对模型的大量并发请求,以评估其模拟真实世界流量和规模的能力。这种类型的测试有助于识别与服务器容量、自动扩展策略、网络延迟和资源利用率相关的问题。 - 相反,如
NVIDIA的GenAI-Perf工具所示,性能基准测试关注的是测量模型本身的实际性能,如吞吐量、延迟和token-level指标。
本文主要关注这种类型的测试,并帮助识别与模型效率、优化和配置相关的问题。虽然负载测试对于确保模型能够处理大量请求至关重要,但性能测试对于理解模型高效处理请求的能力也至关重要。通过结合这两种方法,开发人员可以全面了解其大型语言模型部署的能力,并确定需要改进的地方。
请注意
服务器端指标也可用于NVIDIA NIM,但超出了本文的范围,请参阅 NIM Observability documentation.
LLM推理 背景
在检查基准指标之前,重要的是要了解LLM推理的工作原理以及相关术语。LLM应用程序通过推理产生结果。对于给定的特定LLM应用,这些是普遍的阶段。
-
用户提供一个查询
prompt, -
查询进入队列,等待轮到它处理,即排队阶段。
-
应用程序的底层
LLM模型处理,即 预填充阶段。 -
LLM模型输出一个响应,一次一个token,即 生成阶段。
Token是LLM特定的概念,是LLM推理的核心性能指标。它是LLM划分处理自然语言的单位。所有tokens的集合称为词汇表。每个LLM都有自己的tokenizer,从数据中学习,以便有效地表示输入文本。类比来说,对于许多流行的LLMs,每个token大约是0.75个英语单词。
Sequence length 是数据序列的长度。输入序列长度ISL是LLM得到的token数量。它包括用户查询,任何系统提示(如,模型的指令),之前的聊天历史,思维链推理,以及来自检索增强生成(RAG)pipline的文档。
输出序列长度(OSL)是LLM生成的token数量。上下文长度是LLM在每个生成步骤中使用的token数量,包括到目前为止生成的输入和输出token。每个LLM都有一个最大的上下文长度,可以分配给输入和输出tokens。要更深入地了解LLM推理,请参阅博客Mastering LLM Techniques: Inference Optimization.。
Streaming是一个选项,它允许将部分LLM输出返回给用户,以模型到目前为止逐步生成的标记块的形式。这对于聊天机器人应用程序很重要,因为我们希望快速获得初始响应。当用户消化部分内容时,结果的下一部分将到达后台。
相比之下,在non-streaming模式下,会一次性返回完整的答案。
指标
本节介绍一些常见的LLM推理指标。请注意,不同工具之间的基准测试结果可能存在差异。下图说明了一些广泛使用的LLM推理指标。
图1. 常见的LLM推理性能指标概述
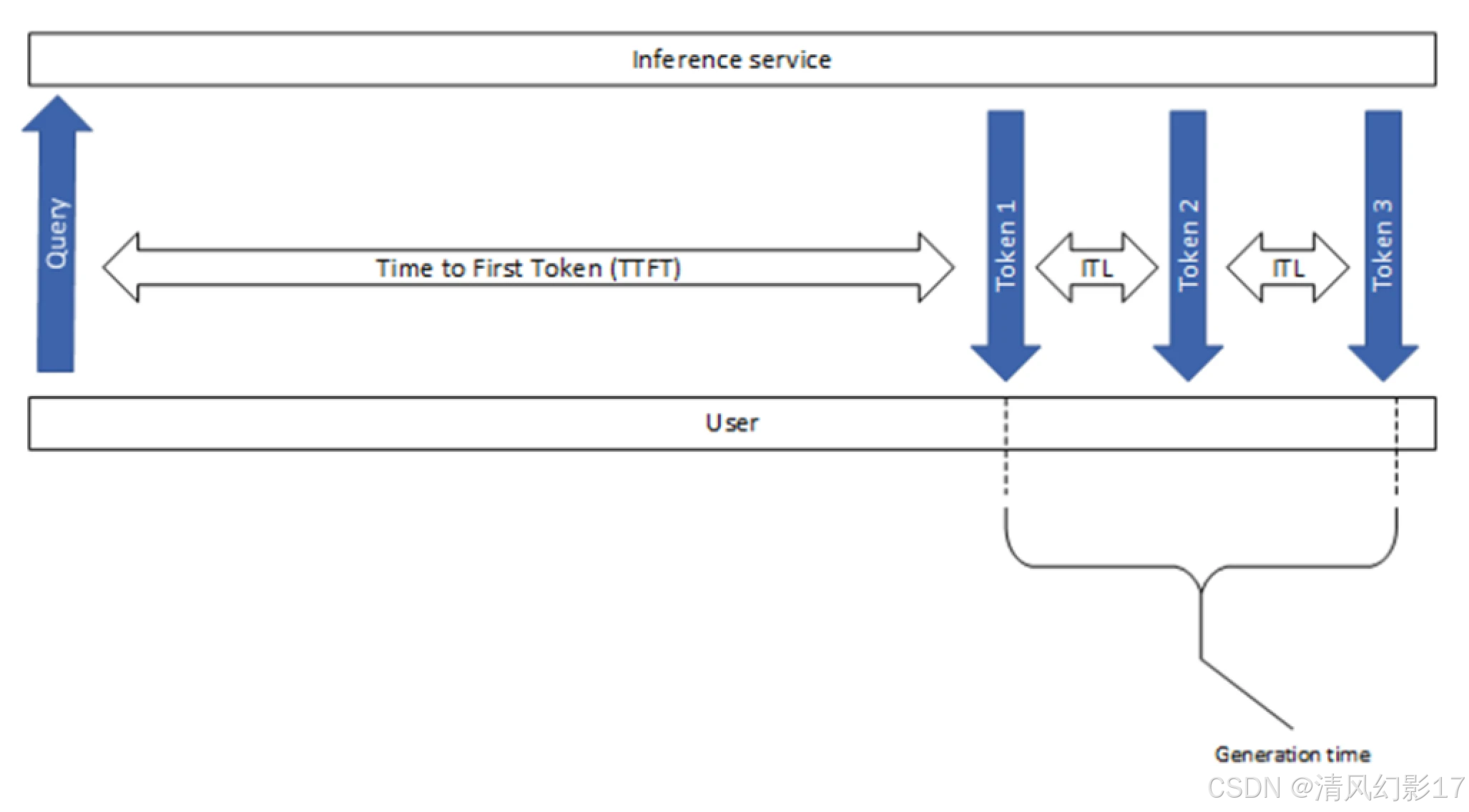
Time to First Token (TTFT)
这个指标显示了用户需要等待多长时间才能看到模型的输出。这是从提交查询到接收第一个token所花费的时间(如果response不为空)。
图2. TTFT,首个token的时间,包括 第一个token标记化和去标记化的步骤。
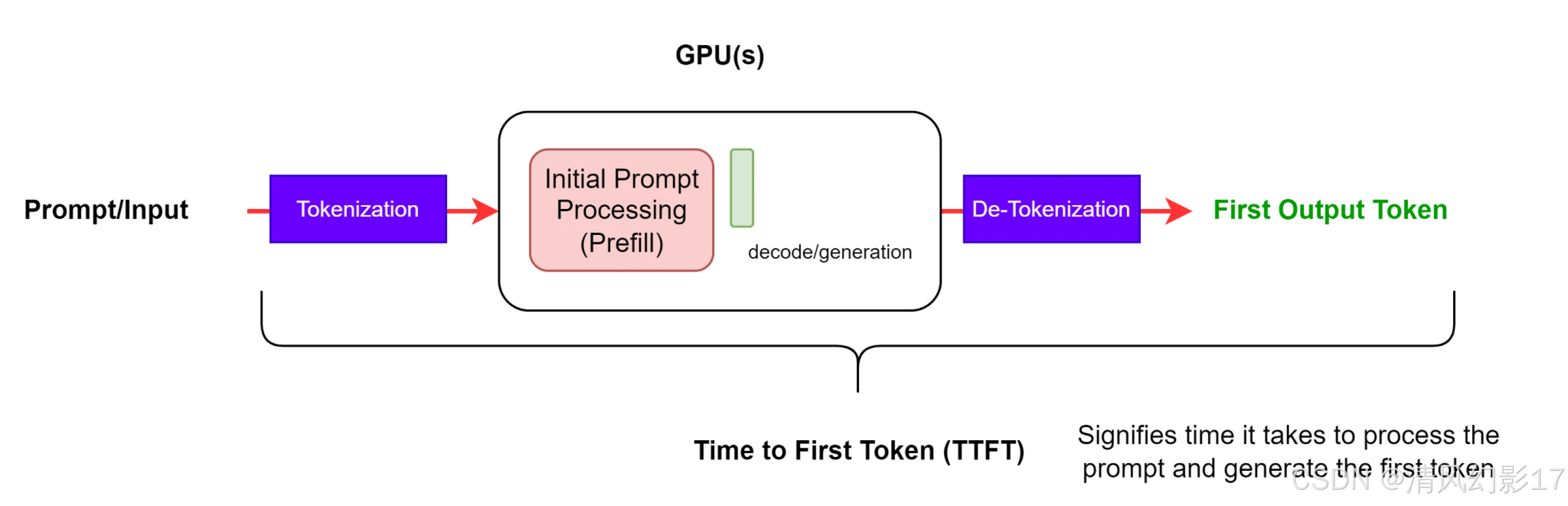
请注意
NVIDIA GenAI-Perf和LLMPerf基准测试工具都会忽略没有内容或内容为空字符串(没有标记)的初始响应。这是因为当第一个响应中没有token时,TTFT测量是无意义的。
获得第一个token的时间通常包括请求排队时间、预填充时间和网络延迟。prompt越长,TTFT越大。这是因为注意力机制需要整个输入序列来计算和创建所谓的键值缓存(又名kv -cache),迭代生成循环可以从这里开始。此外,生产应用程序可能有多个正在处理的请求,因此一个请求的预填充阶段可能与另一个请求的生成阶段重叠。
请注意
传统的web服务基准测试工具(如K6)也可以通过测量HTTP请求中的事件来提供TTFT。
End-to-End Request Latency (e2e_latency)
此指标指示从提交查询到接收完整响应所需的时间,包括排队/批处理机制的性能和网络延迟,如图3所示。
图3. 端到端请求延迟
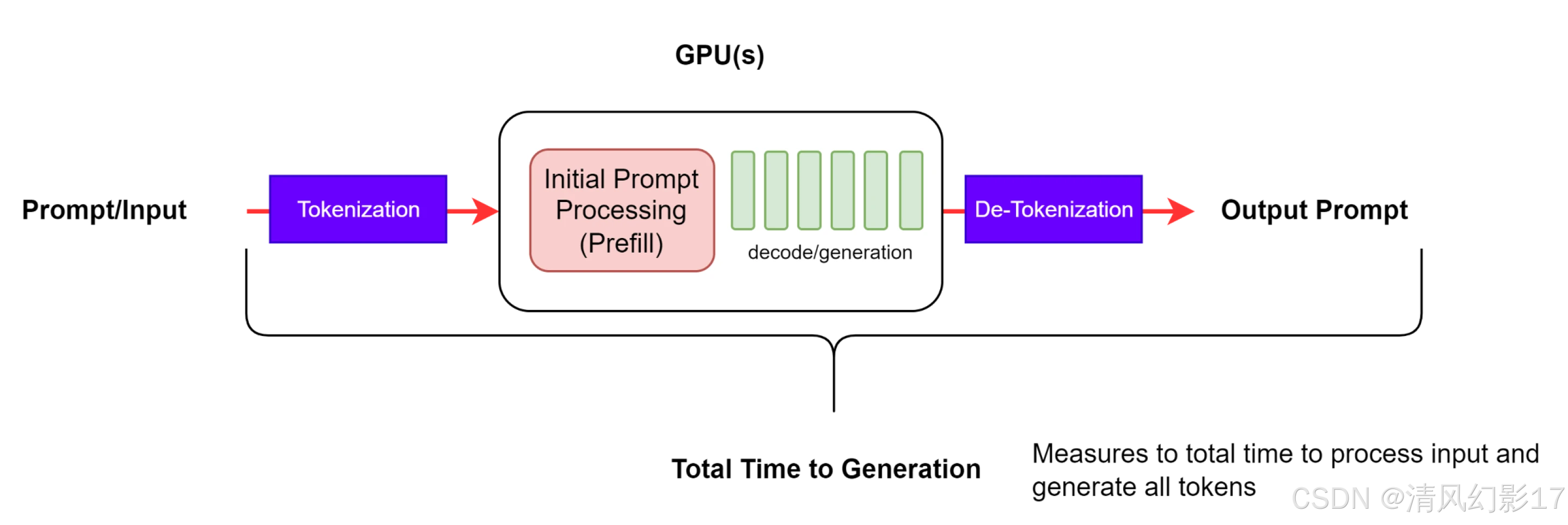
请注意
在streaming模式下,当向用户返回部分结果时,可以多次执行去标记化步骤。
对于单个请求,端到端的请求延迟是发送请求和最终接收令牌之间的时间差。因此:
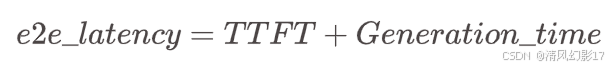
请注意
Generation_time是从接收到第一个令牌到接收到最后一个令牌的持续时间,如图1所示。此外,GenAI-Perf删除了最后一个[done]信号或空响应,因此它们不会包含在端到端延迟中。
Inter-token Latency (ITL)
这被定义为连续标记之间的平均时间,也称为每个输出标记时间time per output token, TPOT。
图4: ITL,连续token 生成之间的延迟。
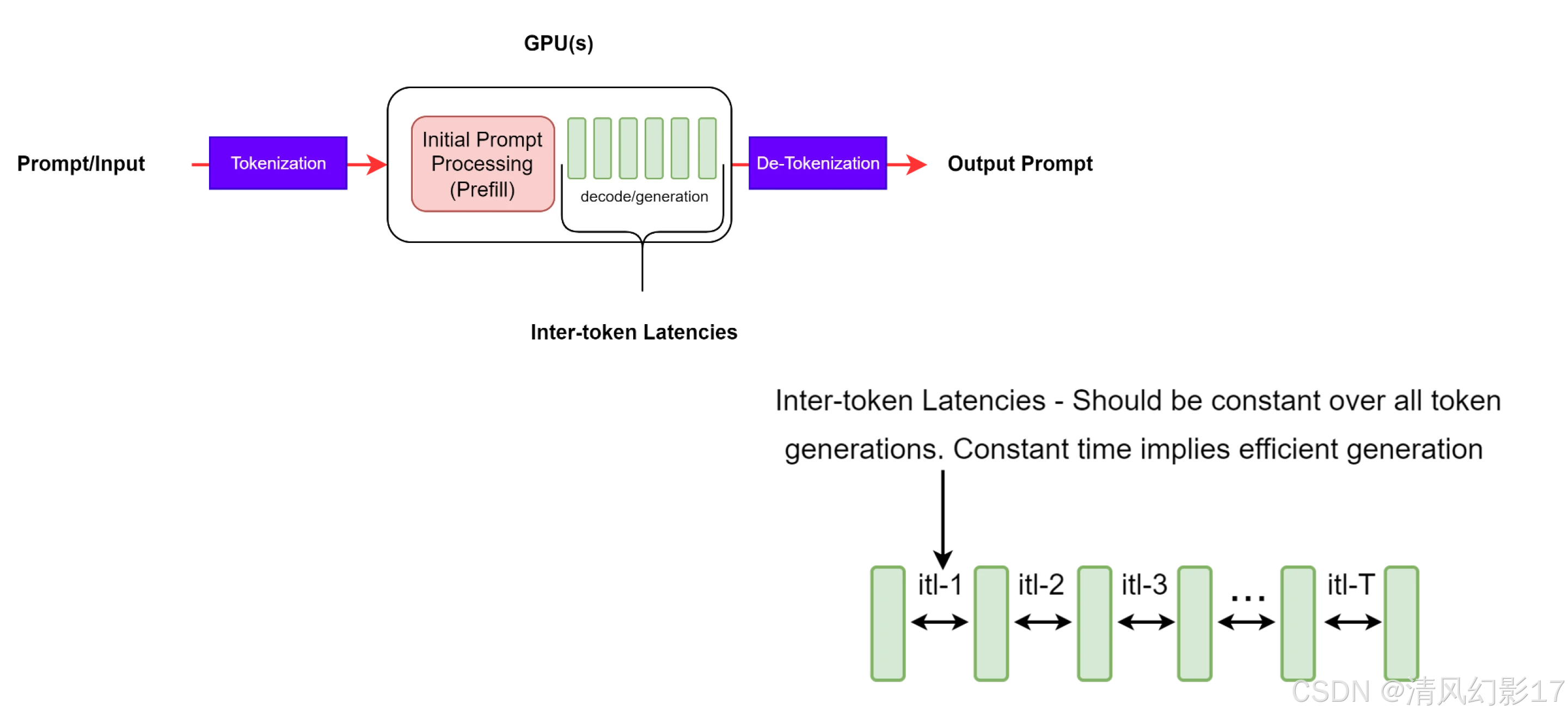
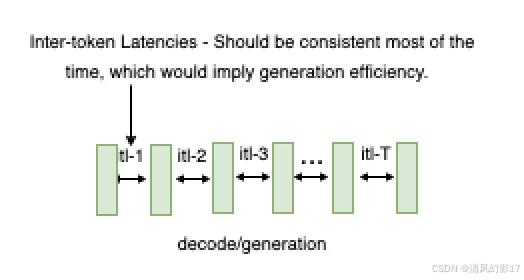
虽然这看起来是一个简单而直接的定义,但在收集指标时,不同的基准测试工具需要考虑一些复杂的决策。例如,这个平均计算是否应该包括第一个token的时间(TTFT) ?
NVIDIA genAI-perf不包含这个数量,而LLMPerf包含这个数量。
GenAI-Perf对ITL的定义如下:
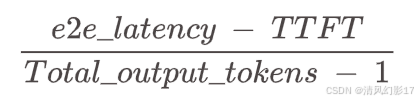
用于此指标的方程不包含第一个token(因此在分母中减去1)。这样做是为了使ITL仅作为请求处理的解码部分的特征。
需要注意的是,输出序列越长,KV缓存就会增长,因此内存开销也会增加。
注意力计算的成本也在增长:对于每个新token,到目前为止,该成本与输入+输出序列的长度是线性的(但这种计算通常不受计算限制)。一致的token间延迟意味着高效的内存管理、更好的内存带宽以及高效的注意力计算。
Tokens Per Second (TPS)
每个系统的总TPS表示每秒吞吐量的总输出token,包括同时发生的所有请求。随着请求数量的增加,每个系统的总TPS也会增加,直到达到所有可用GPU计算资源的饱和点,超过这个饱和点可能会减少。
给定以下整个基准测试的时间线,总共有n个请求。
图5:基准测试运行中的事件时间线

其中
-
Li:第i个请求的 端到端延迟
-
T_start:基准测试的开始
-
Tx:第一次请求的时间戳
-
Ty:上一次请求的最后一次响应的时间戳
-
T_end:基准测试结束
GenAI-perf将TPS定义为总输出token除以第一个请求和最后一个请求的最后响应之间的端到端延迟。
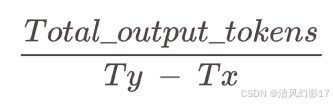
请注意,LLM-perf将TPS定义为总输出token除以整个基准测试持续时间。
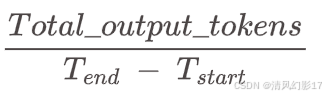
因此,它还包括以下指标的开销:(1)输入提示的生成;(2)请求准备;(3)存储响应。在我们的观察中,在单并发场景下,这些开销有时会占整个基准测试持续时间的33%。
注意,前面的计算是以批处理的方式完成的,并不是实时运行的指标。此外,GenAI-perf使用滑动窗口技术来寻找稳定的测量值。这意味着给定的测量来自完全完成的请求的一个代表性子集,这意味着在计算指标时不包括“预热”和“冷却”请求。
从单用户角度出发,每个用户的TPS表示吞吐量,定义为每个用户请求的(输出序列长度)/(e2e_latency),随着输出序列长度的增加,该值逐渐接近1/ITL。请注意,随着系统中并发请求数量的增加,整个系统的总TPS会增加,而随着延迟的恶化,每个用户的TPS会减少。
Requests Per Second (RPS)
这是系统在一秒钟内成功完成的请求的平均数量。计算公式为:
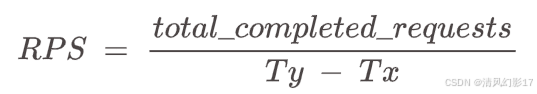
参数和最佳实践
现在我们已经回顾了测量LLM推理延迟和吞吐量的基准指标,让我们讨论一些重要的测试参数及其扫描范围,这些参数确保了有意义的基准测试和质量保证。
用例
应用程序的特定用例会影响序列长度(即ISL和OSL),这又会影响系统消化输入以形成KV-cache并生成输出token的速度。较长的ISL增加了预填充阶段的内存需求,从而增加了TTFT,而较长的OSL增加了生成阶段的内存需求(带宽和容量),从而增加了ITL。您必须了解LLM部署中的输入和输出分布,以最佳优化硬件利用率。常见的用例和可能的ISL/OSL对包括以下内容。
- 翻译
Translation:这包括语言和代码之间的翻译,其特点是具有相似的ISL和OSL,每个大约有500~2000个标记。 - 生成:这包括通过搜索生成代码、故事、电子邮件和一般内容。其特点是OSL为O(1000)个标记,比ISL的O(100)个标记长得多。
- 总结:这包括检索、思维链提示和多轮对话。其特点是ISL为O(1000)个标记,比OSL的O(100)个标记长得多。
如果你有真实的数据,也可以将其作为输入。GenAI-perf支持HuggingFace OpenOrca和CNN Dailymail数据集。
负载控制
关于LLMperf的注意事项:它以N个请求的批次发送请求,但在发送下一批请求之前,有一个等待所有请求完成的消耗周期。因此,在批处理结束时,并发请求的数量逐渐减少到0。这与GenAI-perf不同,后者总是确保在整个基准测试期间有N个活动请求。
并发最常用于描述和控制推理系统的负载。
推理引擎同时处理的一组请求。这可能是并发请求的一个子集。最大批量大小参数定义了推理引擎可以同时处理的最大请求数。
如果并发量超过了最大批量大小乘以活动副本的数量,一些请求将不得不在队列中等待后续处理。在这种情况下,由于等待空位打开的排队效应,您可能会看到第一个token时间值的增加。
另一个用于控制负载的参数,它决定了新请求的发送速率。使用恒定(或静态)的请求速率r意味着每1/r秒发送1个请求,而使用泊松(或指数)的请求速率决定平均到达时间间隔。
GenAI-perf同时支持并发和请求速率,但是我们建议使用并发(与请求速率一样,如果每秒的请求数量超过系统吞吐量,未完成的请求数量可能无限制地增长)。
在指定要测试的并发数时,需要扫描一个范围内的值,从最小值[1~最大批量的最大值)。这是因为当并发量大于引擎的最大批处理大小时,一些请求将不得不在队列中等待。因此,当延迟稳步增加时,系统的吞吐量通常在最大批量大小附近饱和。
其他参数
“ignore_eos”
大多数llm都有一个特殊的结束序列(end-of-sequence, EOS) token,表示一代的结束。它表明LLM已经生成了一个完整的响应,并且应该停止。在一般情况下,LLM推理应该尊重该信号并停止生成进一步的token。ignore_eos参数通常指示LLM推理框架是否应该忽略EOS token并继续生成token,直到达到max_tokens的限制。出于基准测试的目的,这个参数应该设置为True,以便达到预期的输出长度并获得一致的测量结果。
采样vs.贪婪
不同的采样策略可能会影响LLM的生成速度。例如,贪心算法可以简单地通过选择logit最高的标记来实现(不需要对标记的概率分布进行规范化和排序,从而节省计算)。有关不同抽样方法的详细说明,请参阅此blog 。无论选择哪种采样方法,最好在相同的基准测试设置中保持一致。
使用GenAI-Perf进行基准测试
NVIDIA GenAI-Perf是一个以LLM为中心的客户端基准测试工具,提供诸如TTFT、ITL、TPS、RPS等关键指标。它支持任何符合OpenAI API规范的LLM推理服务,OpenAI API是业界广泛接受的事实标准。本节包括一步一步的演练,使用GenAI-Perf对由NVIDIA NIM提供支持的Llama-3模型推理引擎进行基准测试。
Step 1. 获取最新的模型列表
首先需要安装ngc
使用下面的命令以CSV格式列出可用的NIMs。
ngc registry image list --format_type csv nvcr.io/nim/*
这个命令的输出格式如下:
Name,Repository,Latest Tag,Image Size,Updated Date,Permission,Signed Tag?,Access Type,Associated Products
<name1>,<repository1>,<latest tag1>,<image size1>,<updated date1>,<permission1>,<signed tag?1>,<access type1>,<associated products1>
...
<nameN>,<repositoryN>,<latest tagN>,<image sizeN>,<updated dateN>,<permissionN>,<signed tag?N>,<access typeN>,<associated productsN>
使用docker run命令时,请使用Repository字段。
Step 2. 使用NVIDIA NIM设置与openai兼容的LLama-3推理服务
NVIDIA NIM提供了将LLM投入生产的最简单和最快的方法。请参阅NIM LLM文档以开始,从硬件要求开始,并设置您的NVIDIA NGC API密钥。为方便起见,本文提供了以下命令用于部署NIM和执行入门指南中的推理:
## Set Environment Variables
export NGC_API_KEY=<value>
# Choose a container name for bookkeeping
export CONTAINER_NAME=llama3-8b-instruct
# Choose a LLM NIM Image from NGC
export IMG_NAME="nvcr.io/nim/${REPOSITORY}:latest"
# Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
# Start the LLM NIM
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-e NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8000:8000 \
$IMG_NAME
这些示例使用Meta llama3-8b-instruct模型,并使用该名称作为容器的名称。示例中提到并挂载了一个本地目录作为缓存目录。在启动期间,NIM容器下载所需的资源,并开始为API端点后的模型提供服务。显示如下信息表示启动成功。
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
一旦启动并运行,NIM提供了一个与openai兼容的API,您可以对其进行查询,如下面的示例所示。
from openai import OpenAI
client = OpenAI(base_url="http://0.0.0.0:8000/v1", api_key="not-used")
prompt = "Once upon a time"
response = client.completions.create(
model="meta/llama3-8b-instruct",
prompt=prompt,
max_tokens=16,
stream=False
)
completion = response.choices[0].text
print(completion)
请注意
在我们广泛的基准测试中,我们观察到,通过指定额外的Docker标志,-security-opt seccomp= un(禁用seccomp安全配置文件)或-privileged(授予容器主机几乎所有的功能,包括直接访问硬件、设备文件和某些内核功能),可以进一步提高推理性能,使用NIM TensorRT-LLM v0.10.0后端,最多可提高5%。以及高达20%的OSS vLLM(在v0.4.3上测试)或NIM vLLM后端(在NIM 1.0.0上测试)。这已经在DGX A100和H100系统上得到验证,但也可能广泛适用于其他GPU系统。禁用Seccomp或使用特权模式可以消除与容器化安全措施相关的一些开销,允许NIM和vLLM更有效地利用资源。然而,虽然有性能上的好处,但由于增加了安全漏洞,应该尽可能谨慎地使用这些标志。更多细节请参阅Docker文档。
Step 3. 设置GenAI-Perf并进行预热:对单个用例进行基准测试
一旦NIM LLama-3推理服务运行,您就可以设置基准测试工具。最简单的方法是使用预构建的docker容器。我们建议在与NIM相同的服务器上启动GenAI-perf容器,以避免网络延迟,除非您特别希望将网络延迟作为测量的一部分。
请注意
有关入门的全面指南,请参阅GenAI-Perf文档。
运行以下命令来使用预构建的容器
export RELEASE="24.06" # recommend using latest releases in yy.mm format
export WORKDIR=<YOUR_GENAI_PERF_WORKING_DIRECTORY>
docker run -it --net=host --gpus=all -v $WORKDIR:/workdir nvcr.io/nvidia/tritonserver:${RELEASE}-py3-sdk
进入容器后,您可以启动genAI-perf评估工具,如下所示,它在NIM后端上运行预热负载测试。
export INPUT_SEQUENCE_LENGTH=200
export INPUT_SEQUENCE_STD=10
export OUTPUT_SEQUENCE_LENGTH=200
export CONCURRENCY=10
export MODEL=meta/llama3-8b-instruct
cd /workdir
genai-perf \
-m $MODEL \
--endpoint-type chat \
--service-kind openai \
--streaming \
-u localhost:8000 \
--synthetic-input-tokens-mean $INPUT_SEQUENCE_LENGTH \
--synthetic-input-tokens-stddev $INPUT_SEQUENCE_STD \
--concurrency $CONCURRENCY \
--output-tokens-mean $OUTPUT_SEQUENCE_LENGTH \
--extra-inputs max_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs min_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs ignore_eos:true \
--tokenizer meta-llama/Meta-Llama-3-8B-Instruct \
-- \
-v \
--max-threads=256
此示例指定要测试的输入和输出序列长度和并发性。它还告诉后端忽略特殊的“EOS”token,以便输出达到预期长度。
请注意
这个测试将使用HuggingFace中的llama-3标记器,这是一个受保护的存储库。您需要申请访问,然后使用您的HF凭证登录。
pip install huggingface_hub
huggingface-cli login
请注意
请参阅GenAI-perf文档以获得完整的选项和参数集。
成功执行后,你应该在终端中看到类似下面的结果:
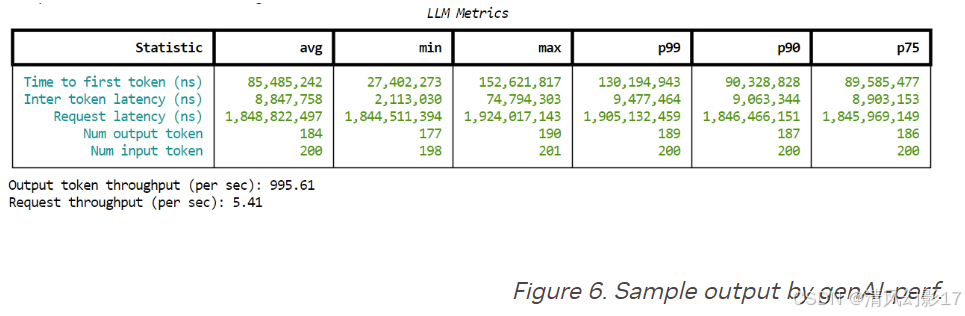
Step 4. 浏览大量的用例
通常,在基准测试中,测试将被设置为扫描许多用例,例如输入/输出长度组合,以及负载场景,例如不同的并发值。使用以下bash脚本定义参数,以便genAI-perf通过所有组合执行。
请注意
在进行基准测试之前,建议先进行热身测试。在我们的例子中,这是在前面的步骤3中执行的。
declare -A useCases
# Populate the array with use case descriptions and their specified input/output lengths
useCases["Translation"]="200/200"
useCases["Text classification"]="200/5"
useCases["Text summary"]="1000/200"
# Function to execute genAI-perf with the input/output lengths as arguments
runBenchmark() {
local description="$1"
local lengths="${useCases[$description]}"
IFS='/' read -r inputLength outputLength <<< "$lengths"
echo "Running genAI-perf for$descriptionwith input length$inputLengthand output length$outputLength"
#Runs
for concurrency in 1 2 5 10 50 100 250; do
local INPUT_SEQUENCE_LENGTH=$inputLength
local INPUT_SEQUENCE_STD=0
local OUTPUT_SEQUENCE_LENGTH=$outputLength
local CONCURRENCY=$concurrency
local MODEL=meta/llama3-8b-instruct
genai-perf \
-m $MODEL \
--endpoint-type chat \
--service-kind openai \
--streaming \
-u localhost:8000 \
--synthetic-input-tokens-mean $INPUT_SEQUENCE_LENGTH \
--synthetic-input-tokens-stddev $INPUT_SEQUENCE_STD \
--concurrency $CONCURRENCY \
--output-tokens-mean $OUTPUT_SEQUENCE_LENGTH \
--extra-inputs max_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs min_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs ignore_eos:true \
--tokenizer meta-llama/Meta-Llama-3-8B-Instruct \
--measurement-interval 10000 \
--profile-export-file ${INPUT_SEQUENCE_LENGTH}_${OUTPUT_SEQUENCE_LENGTH}.json \
-- \
-v \
--max-threads=256
done
}
# Iterate over all defined use cases and run the benchmark script for each
for description in "${!useCases[@]}"; do
runBenchmark "$description"
done
将脚本保存在工作目录下,例如/workdir/benchmark.sh。然后可以使用以下命令执行它。
cd /workdir
bash benchmark.sh
请注意
-measurement-interval 10000是每次测量的时间间隔,单位是毫秒。GenAI-perf测量在指定时间间隔内完成的请求。选择一个足够大的值来完成多个请求。对于更大的网络(例如Llama-3 70B)和更多的并发,例如250,请选择一个更高的值(例如100000,即100s)。
Step 5.输出分析
当测试完成时,GenAI-perf在您挂载的工作目录(在这些示例中为/workdir)下名为“artifacts”的默认目录中生成结构化输出,由模型名称、并发性和输入/输出长度组织。你的结果应该类似于下面这样。
/workdir/artifacts
├── meta_llama3-8b-instruct-openai-chat-concurrency1
│ ├── 200_200.csv
│ ├── 200_200_genai_perf.csv
│ ├── 200_5.csv
│ ├── 200_5_genai_perf.csv
│ ├── all_data.gzip
│ ├── llm_inputs.json
│ ├── plots
│ └── profile_export_genai_perf.json
├── meta_llama3-8b-instruct-openai-chat-concurrency10
│ ├── 200_200.csv
│ ├── 200_200_genai_perf.csv
│ ├── 200_5.csv
│ ├── 200_5_genai_perf.csv
│ ├── all_data.gzip
│ ├── llm_inputs.json
│ ├── plots
│ └── profile_export_genai_perf.json
├── meta_llama3-8b-instruct-openai-chat-concurrency100
│ ├── 200_200.csv
…
genai_fr .csv文件包含主要的基准测试结果。使用以下Python代码片段将给定用例的文件解析为Pandas dataframe。
import pandas as pd
import io
def parse_data(file_path):
# Create a StringIO buffer
buffer = io.StringIO()
with open(file_path, 'rt') as file:
for i, line in enumerate(file):
if i not in [6,7]:
buffer.write(line)
# Make sure to reset the buffer's position to the beginning before reading
buffer.seek(0)
# Read the buffer into a pandas DataFrame
df = pd.read_csv(buffer)
return df
还可以使用下面的bash脚本读取给定用例下所有并发的每秒token数和TTFT指标。
import os
root_dir = "./artifacts"
directory_prefix = "meta_llama3-8b-instruct-openai-chat-concurrency"
concurrencies = [1, 2, 5, 10, 50, 100, 250]
TPS = []
TTFT = []
for con in concurrencies:
df = parse_data(os.path.join(root_dir, directory_prefix+str(con), f"200_200_genai_perf.csv"))
TPS.append(df.iloc[5]['avg'])
TTFT.append(df.iloc[0]['avg']/1e9)
最后,我们可以使用下面的代码使用收集到的数据绘制和分析延迟-吞吐量曲线。这里,每个数据点对应一个并发值。
import plotly.express as px
fig = px.line(x=TTFT, y=TPS, text=concurrencies)
fig.update_layout(xaxis_title="Single User: time to first token(s)", yaxis_title="Total System: tokens/s")
fig.show()
使用genAI-perf测量数据绘制的结果如下所示。
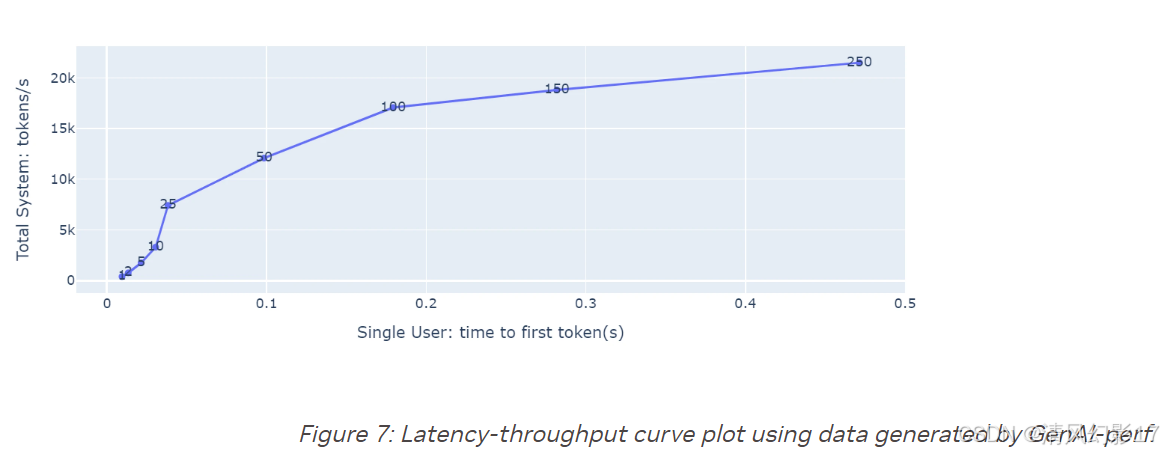
Step 6. Interpreting the Results
上面的图显示了TTFT在x轴上,系统总吞吐量在y轴上,并发数在每个点上。有两种使用该图形的方式:
- LLM应用程序所有者拥有延迟预算,其中可以接受的最大TTFT,将该值用于x,并查找匹配的y值和并发数。这显示了在延迟限制和相应的并发值下可以达到的最高吞吐量。
- LLM应用程序所有者可以使用并发值来定位图上的点。匹配的x和y值表示该并发级别的延迟和吞吐量。
该图还显示了延迟快速增长但吞吐量几乎没有增加的并发数。例如,在上面的图中,并发数=100就是这样一个值。
类似的图可以使用ITL、e2e_latency或TPS_per_user作为x轴,显示系统总吞吐量和单个用户延迟之间的权衡。
LoRA模型的基准测试
参数高效微调(PEFT)方法允许对大型预训练模型进行高效微调。NIM目前支持低秩自适应(LoRA),这是为特定领域和用例定制LLM的一种简单有效的方法。使用NIM,用户可以加载和部署多个LoRA适配器。按照参数高效微调部分中的说明,在一个目录中加载HuggingFace或Nemo训练过的适配器,并将该目录作为环境变量的值传递给NIM。
一旦添加了适配器,您就可以像查询基本模型一样查询LoRA模型,方法是将基本模型ID替换为LoRA模型名称,如下面的例子所示。
curl -X 'POST' \
'http://0.0.0.0:8000/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "llama3-8b-instruct-lora_vhf-math-v1",
"prompt": "John buys 10 packs of magic cards. Each pack has 20 cards and 1/4 of those cards are uncommon. How many uncommon cards did he get?",
"max_tokens": 128
}'
使用GenAI-perf,您可以通过使用“-m”参数传递LoRA模型的id来对LoRA模型的部署度量进行基准测试,如下面的示例所示。
下面的示例将对两个LoRA模型进行基准测试,前提是您遵循了参数高效微调中的说明来部署llama3-8b-instruct-lora_vnemo-math-v1和llama3-8b-instruct-lora_vhf-math-v1。此外,“-model-selection-strategy {round_robin,random}”指定了应该以轮询方式还是随机方式调用这些适配器。
genai-perf -m llama3-8b-instruct-lora_vnemo-math-v1 llama3-8b-instruct-lora_vhf-math-v1 \
--model-selection-strategy random \
--endpoint-type completions \
--service-kind openai \
--streaming \
多lora部署性能基准测试的最佳实践
评估这种多lora部署的延迟和吞吐量性能并非易事。本节介绍在对LLM LoRA推理框架进行性能基准测试时的几个因素。
小型和大型模型,例如[[Llama 3 8B](https://build.nvidia.com/meta/llama3-8b)和Llama 3 70B ,都可以用作LoRA微调和推理的基础模型。较小的模型在许多任务中表现出色,特别是传统的非生成式NLP任务,如文本分类,而较大的模型在复杂的推理任务中表现出色。LoRA的优势之一是,即使是大型70B模型也可以在单个NVIDIA DGX H100或带有FP16的A100节点上进行调优,甚至单个NVIDIA H100或NVIDIA A100具有4位量化的GPU上进行调优。
用户通常更喜欢实验和选择产生最佳精度的尺寸的灵活性。另一方面,系统操作人员可能更喜欢强制执行固定大小,因为统一的LoRAs可以实现更好的批处理和性能。LoRA排名的常见选择是8、16、32和64。
基准测试需要考虑的其他几个测试参数包括:
输出长度控制:ignore_eos参数指导推理框架继续生成文本,直到达到max_token_length限制。这确保满足用例OSL(输出序列长度)规范。该参数越来越受到LLM推理框架的支持,并大大简化了基准的设置。值得注意的是,使用ignore_eos,您不必在实际任务上进行训练来执行分析。
系统负载:并发(并发用户的数量)通常用于驱动负载进入系统。这个参数值应该反映真实的用例,同时还要考虑系统可以有效并发处理的最大批处理大小。对于一个GPU上的8B模型,考虑高达250个并发用户作为真实的服务器负载。
任务类型:应该同时考虑生成任务和非生成任务。它们在ISL(输入序列长度)和OSL上有所不同。在200到2000 token范围内的ISL和1到2000 token范围内的OSL反映了LLM的广泛应用:从文本分类和摘要到翻译和代码生成。

















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









